

32
60 82
29 |
54 |
|
67 75 |
|
91 97 |
|
|
|
|
|
|
18 |
28 |
|
37 |
54 |
|
59 |
60 |
|
61 67 |
|
68 70 |
|
77 80 |
|
83 91 |
|
93 96 |
|
98 |
99 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
указатели на страницы, где находятся данные
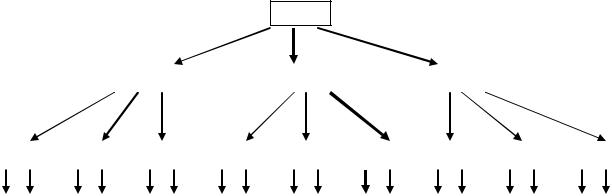
Рис. 5. Индекс в виде B-дерева
Реальные данные, для которых строится многоуровневый индекс, часто не позволяют непосредственно получить сбалансированное дерево, построенное на рис. 5. В таких случаях для его создания применяются специальные алгоритмы, рассмотренные, например, в работе [ 2 ].
Недостатком индексирования является необходимость выделения во внешней памяти дополнительного места для хранения индексов. Существуют оценки, что файл, в котором созданы индексы для всех полей размещенной в нем таблицы, занимает практически вдвое больше места на внешнем носителе по сравнению с исходным файлом [ 12 ]. Кроме того, наличие индексов затрудняет обновление информации, хранящейся в базе данных, и требует дополнительных затрат времени на данный процесс.
Поэтому не рекомендуется индексировать все поля таблиц или поля, данные в которых часто изменяются. Наиболее эффективным является создание индексов для первичных и внешних ключей, для полей, по которым в основном выполняются запросы.
3.5. Хеширование
Хеширование (Hashing) – алгоритмическое преобразование значений некоторого поля записей (первичного ключа или любого другого поля) в адреса их размещения на внешнем носителе.
При вводе данных СУБД вычисляет адрес страницы, на которой будет храниться запись, и заносит запись на эту страницу. При выполнении запросов реа-
33
лизуются аналогичные расчеты адреса страницы с последующим чтением записей с этой страницы. Достоинством такого метода является быстрый прямой доступ к данным. При этом время доступа практически не зависит от количества хранимых записей.
Рассмотрим технологию хеширования на примере данных, приводимых в табл. 3.1. Используем для вычисления адресов страниц значения данных в поле первичного ключа таблицы Номер накладной: 18, 28, 37, 54, 60, 74, 80. Предположим, что на каждой странице внешней памяти можно разместить только одну запись.
Номера накладных представляют собой целые двузначные числа. Поэтому если использовать номера накладных в качестве адресов страниц, для организации хранения информации потребуется 99 страниц с адресами от 01 до 99. Очевидно, что это нерационально, так как записей в исходной таблице всего семь и абсолютное большинство страниц останутся пустыми (приводимые рассуждения будут более убедительными, если значения данных, используемые для хеширования, пятизначные или шестизначные числа).
По указанной причине адреса страниц вычисляются с помощью специальной хеш-функции. Используем в качестве адресов страниц остаток от деления каждого значения номера накладной на простое натуральное число (например, 11), называемое сверткой ключа (обычно хеш-функции имеют более сложный вид) (табл. 3.6):
Таблица 3.6
Сведения о поставках товаров в магазин
Номер |
Название |
Артикул |
Количество |
Дата |
Адрес (номер |
накладной |
товара |
|
|
поставки |
страницы) |
|
|
|
|
|
|
37 |
Костюм |
500 |
50 |
10.12.05 |
4 |
|
|
|
|
|
|
54 |
Сапоги |
200 |
75 |
10.12.05 |
10 |
|
|
|
|
|
|
18 |
Туфли |
100 |
120 |
11.12.05 |
7 |
|
|
|
|
|
|
60 |
Костюм |
500 |
35 |
11.12.05 |
5 |
|
|
|
|
|
|
28 |
Костюм |
300 |
20 |
12.12.05 |
6 |
|
|
|
|
|
|
74 |
Костюм |
400 |
50 |
12.12.05 |
8 |
|
|
|
|
|
|
80 |
Туфли |
100 |
100 |
12.12.05 |
3 |
|
|
|
|
|
|
С помощью выполненного хеширования записи размещаются на семи страницах внешней памяти с адресами от 00 до 10.
34
Рассмотренный пример иллюстрирует и недостатки хеширования:
1.Страницы с записями во внешней памяти могут располагаться неравномерно, с различным количеством пустых страниц между ними.
2.Возможно совпадение рассчитанных адресов страниц для двух или нескольких записей (например адреса, вычисленные для номеров накладных 18, 29, 40, будут равны одному числу – семи).
Совпадение вычисленных адресов называется коллизией, значения данных, для которых получены одинаковые адреса – синонимами.
Существует много стратегий разрешения коллизий, но основные из них две: а) с областью переполнения; б) свободного замещения.
Стратегия разрешения коллизий с помощью области переполнения Область хранения разбивается на две части: основную область и область пе-
реполнения (рис. 6).
При вводе в базу данных новой записи вычисляется значение хеш-функции, которое используется для определения места расположения страницы в основной области памяти. Например, если номер накладной равен 12, запись будет размещена на странице с адресом 1 (см. обозначения курсивом на рис. 6).
Когда страница с полученным адресом занята и возникает коллизия, новая запись заносится на первое свободное место в области переполнения. Например, запись с номером накладной 29, следовательно, значением хеш-функции, равным 7, будет размещена по адресу 500. В записи-синониме, которая находится в основной области, делается ссылка на адрес записи, размещаемой в области переполнения. В ситуациях повторения коллизий (номер накладной равен 40, значение хеш-функции – 7) вновь вводимая запись помещается на свободное место
вобласти переполнения (например, если страница с номером 501 занята, по адресу 502). Она становится второй в цепочке синонимов (этим обеспечивается сокращение времени на размещение новых записей) с помощью изменения ссылок на адреса синонимов (см. рис. 6).
При поиске нужной записи вычисляется значение ее хеш-функции, указывающее на адрес страницы в основной памяти. Если эта запись не является искомой, последовательно просматривается цепочка синонимов до получения необходимого результата. Очевидно, что скорость поиска существенно зависит от длины цепочки синонимов. Считается, что в цепочке не должно быть более 10 синонимов [ 4 ].

35
При удалении записи в основной области памяти на ее место перемещается вторая запись в цепочке синонимов, при этом все ссылки на синонимы в цепочке сохраняются. Если удаляется запись в области переполнения, изменяется адрес ссылки на следующий синоним в записи, предшествующей удаляемой записи.
Основная область
|
Адрес |
Номер |
Название |
Арти- |
Коли- |
|
Дата |
Ссылка |
|
|
|
|||||
|
(номер |
накладной |
товара |
кул |
чество |
|
поставки |
на |
|
|
|
|||||
|
страницы) |
|
|
|
|
|
|
|
|
|
синонимы |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
12 |
|
Сапоги |
150 |
|
150 |
13.12.05 |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 |
|
80 |
|
Туфли |
100 |
|
100 |
12.12.05 |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4 |
|
37 |
|
Костюм |
500 |
|
50 |
10.12.05 |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
|
60 |
|
Костюм |
500 |
|
35 |
11.12.05 |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6 |
|
28 |
|
Костюм |
300 |
|
20 |
12.12.05 |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
7 |
|
18 |
|
Туфли |
100 |
|
120 |
11.12.05 |
502 |
|
|
|
|
||
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8 |
|
74 |
|
Костюм |
400 |
|
50 |
12.12.05 |
501 |
|
|
|
|
||
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
|
54 |
|
Сапоги |
200 |
|
75 |
10.12.05 |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Область переполнения |
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Адрес |
|
Номер |
|
Название |
|
Арти- |
|
Коли- |
|
Дата |
Ссылка |
|
|
|
|
|
(номер |
|
накладной |
|
товара |
|
кул |
|
чество |
|
поставки |
на |
|
|
|
|
|
страницы) |
|
|
|
|
|
|
|
|
|
|
синонимы |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
500 |
|
29 |
|
Брюки |
|
750 |
|
90 |
|
13.12.05 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
501 |
|
96 |
|
Сапоги |
|
220 |
|
120 |
|
13.12.05 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
502 |
|
40 |
|
Костюм |
|
300 |
|
35 |
|
14.12.05 |
500 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
503 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
504 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
505 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 6. Пример хеширования с областью переполнения
36
Стратегия разрешения коллизий с помощью свободного замещения В рамках данной стратегии память не разделяется на отдельные области. Ес-
ли в базу данных вводится новая запись и значение хеш-функции соответствует адресу пустой страницы, запись помещается на этой странице и становится первой в цепочке синонимов. Когда возникает коллизия, новая запись размещается на первом свободном месте в памяти. С помощью ссылок создается цепочка синонимов, при этом используются те же принципы, что и в стратегии с областью переполнения.
Технологии поиска и удаления записей в обеих стратегиях также аналогичны.
При реализации стратегии разрешения коллизий с помощью свободного замещения может возникнуть ситуация, когда запись, размещаемая на первой свободной странице в памяти, занимает место, на которое позднее будет претендовать запись, значение хеш-функции которой соответствует адресу этой страницы. В такой ситуации запись, занимающая свое место «незаконно», перемещается на другую страницу, при этом изменяются ссылки в цепочке синонимов.
Основной проблемой хеширования является сложность выбора оптимальной хеш-функции. При выполнении данной работы анализируются размеры записей и страниц внешней памяти, вероятное распределение получаемых адресов. Неудачно выбранная хеш-функция может вызвать неравномерное распределение записей в памяти или формирование слишком длинных цепочек синонимов.
Весьма сложной является ситуация, когда количество запоминаемых записей больше, чем предполагалось, и необходимо увеличить место в памяти для их хранения или размеры таблицы хеширования. В этой ситуации потребуется выполнить полное повторное хеширование.
Следует иметь в виду, что хеширование позволяет организовать быстрый поиск информации только по одному полю, данные которого использовались для хеширования. Нельзя хранить записи в порядке, определяемом несколькими хеш-функциями.
Несмотря на отмеченные недостатки хеширования, данный способ организации хранения и быстрого извлечения необходимых данных широко применяется, в первую очередь в объектно-ориентированных базах данных [ 12 ].