

Лабораторные работы / intel_lab3
.pdfОтчет по лабораторной работе № 3
по дисциплине «Интеллектуальные системы»
на тему «Распознавание изображений»
Цель работы
Получить практические навыки создания, обучения и применения сверточных нейронных сетей для распознавания изображений. Познакомиться с классическими показателями качества классификации.
Задание 1
1) В среде Google Colab создадим новый блокнот. Импортируем необходимые для работы библиотеки и модули.
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/IS_LR3')
# импорт модулей
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
2) Загрузим набор данных MNIST, содержащий размеченные изображения рукописных цифр.
# загрузка датасета
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
1

3) Разобьем набор данных на обучающие (train) и тестовые (test) данные в соотношении 60000:10000 элементов. При разбиении параметр random_state выберем равным (4*22 – 1) = = 87. Выведем размерности полученных обучающих и тестовых массивов данных.
# создание своего разбиения датасета
from sklearn.model_selection import train_test_split
# объединяем в один набор
X = np.concatenate((X_train, X_test)) y = np.concatenate((y_train, y_test))
# разбиваем по вариантам
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 10000,
train_size = 60000, random_state = 87)
# вывод размерностей
print('Shape of X train:', X_train.shape) print('Shape of y train:', y_train.shape) print('Shape of X test:', X_test.shape) print('Shape of y test:', y_test.shape)
Результат:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step 11501568/11490434 [==============================] - 0s 0us/step
Shape of X train: (60000, 28, 28) Shape of y train: (60000,)
Shape of X test: (10000, 28, 28) Shape of y test: (10000,)
4) Проведем предобработку данных: приведем обучающие и тестовые данные к формату, пригодному для обучения сверточной нейронной сети. Входные данные должны принимать значения от 0 до 1, метки цифр должны быть закодированы по принципу «one-hot encoding». Выведем размерности предобработанных обучающих и тестовых массивов данных.
# Зададим параметры данных и модели
2

num_classes = 10 input_shape = (28, 28, 1)
#Приведение входных данных к диапазону [0, 1] X_train = X_train / 255
X_test = X_test / 255
#Расширяем размерность входных данных, чтобы каждое изображение имело
#размерность (высота, ширина, количество каналов)
X_train = np.expand_dims(X_train, -1) X_test = np.expand_dims(X_test, -1)
print('Shape of transformed X train:', X_train.shape) print('Shape of transformed X test:', X_test.shape)
# переведем метки в one-hot
y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) print('Shape of transformed y train:', y_train.shape) print('Shape of transformed y test:', y_test.shape)
Результат:
Shape of transformed X train: (60000, 28, 28, 1)
Shape of transformed X test: (10000, 28, 28, 1)
Shape of transformed y train: (60000, 10)
Shape of transformed y test: (10000, 10)
5) Реализуем модель сверточной нейронной сети и обучим ее на обучающих данных с выделением части обучающих данных в качестве валидационных. Выведем информацию об архитектуре нейронной сети.
# создаем модель model = Sequential()
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=input_shape)) model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(64, kernel_size=(3, 3), activation="relu")) model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Dropout(0.5))
3

model.add(layers.Flatten()) model.add(layers.Dense(num_classes, activation="softmax")) model.summary()
Результат:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) |
(None, 26, 26, 32) |
320 |
|
|
max_pooling2d (MaxPooling2D (None, 13, 13, 32) |
0 |
|||
) |
|
|
|
|
conv2d_1 (Conv2D) |
(None, 11, 11, 64) |
18496 |
||
max_pooling2d_1 (MaxPooling (None, 5, 5, 64) |
|
0 |
||
2D) |
|
|
|
|
dropout (Dropout) |
(None, 5, 5, 64) |
0 |
|
|
flatten (Flatten) |
(None, 1600) |
0 |
|
|
dense (Dense) |
(None, 10) |
16010 |
|
|
=================================================================
Total params: 34,826 Trainable params: 34,826 Non-trainable params: 0
_________________________________________________________________
# компилируем и обучаем модель batch_size = 128
epochs = 15
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
4

Результат:
Epoch 15/15
422/422 [==============================] - 37s 87ms/step - loss: 0.0206 - accuracy: 0.9934 - val_loss: 0.0283 - val_accuracy: 0.9913
6) Оценим качество обучения на тестовых данных. Выведем значение функции ошибки и значение метрики качества классификации на тестовых данных.
# Оценка качества работы модели на тестовых данных scores = model.evaluate(X_test, y_test)
print('Loss on test data:', scores[0]) print('Accuracy on test data:', scores[1])
Результат:
313/313 [==============================] - 3s 8ms/step - loss: 0.0337 - accuracy: 0.9900 Loss on test data: 0.033651165664196014
Accuracy on test data: 0.9900000095367432
7) Подадим на вход обученной модели два тестовых изображения. Выведем изображения, истинные метки и результаты распознавания.
# вывод тестового изображения и результата распознавания n = 87
result = model.predict(X_test[n:n+1]) print('NN output:', result)
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray')) plt.show()
print('Real mark: ', np.argmax(y_test[n])) print('NN answer: ', np.argmax(result))
Результат:
NN output: [[1.8994561e-09 9.9997437e-01 1.9214222e-06 1.4394224e-11 1.0481855e-05 3.1840541e-10 2.4228148e-09 1.0422922e-05 2.8613138e-06 1.3936267e-09]]
5

Real mark: 1
NN answer: 1
# вывод тестового изображения и результата распознавания n = 86
result = model.predict(X_test[n:n+1]) print('NN output:', result)
plt.imshow(X_test[n].reshape(28,28), cmap=plt.get_cmap('gray')) plt.show()
print('Real mark: ', np.argmax(y_test[n])) print('NN answer: ', np.argmax(result))
Результат:
NN output: [[1.3139387e-15 3.7731544e-15 3.4353822e-09 1.2818173e-09 2.6459586e-16 2.9080759e-11 2.0733557e-14 2.0914493e-16 1.0000000e+00 1.4831038e-10]]
Real mark: 8
NN answer: 8
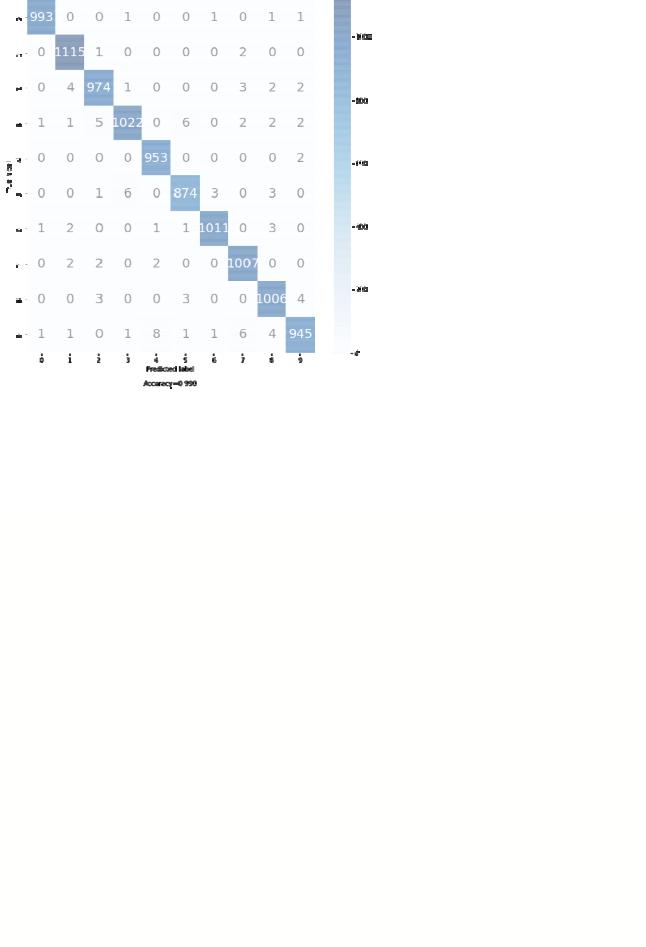
8) Выведем отчет о качестве классификации тестовой выборки и матрицу ошибок для тестовой выборки.
# истинные метки классов true_labels = np.argmax(y_test, axis=1)
# предсказанные метки классов
predicted_labels = np.argmax(model.predict(X_test), axis=1)
# отчет о качестве классификации print(classification_report(true_labels, predicted_labels))
6

# вычисление матрицы ошибок
conf_matrix = confusion_matrix(true_labels, predicted_labels)
# красивая отрисовка матрицы ошибок в виде "тепловой карты" make_confusion_matrix(conf_matrix, percent=False, figsize=(10,10))
Результат:
precision recall f1-score support
0 |
1.00 |
1.00 |
1.00 |
997 |
||
1 |
0.99 |
1.00 |
0.99 |
1118 |
||
2 |
0.99 |
0.99 |
0.99 |
986 |
||
3 |
0.99 |
0.98 |
0.99 |
1041 |
||
4 |
0.99 |
1.00 |
0.99 |
955 |
||
5 |
0.99 |
0.99 |
0.99 |
887 |
||
6 |
1.00 |
0.99 |
0.99 |
1019 |
||
7 |
0.99 |
0.99 |
0.99 |
1013 |
||
8 |
0.99 |
0.99 |
0.99 |
1016 |
||
9 |
0.99 |
0.98 |
0.98 |
968 |
||
accuracy |
|
|
0.99 |
|
10000 |
|
macro avg |
0.99 0.99 |
0.99 |
10000 |
|||
weighted avg |
0.99 |
0.99 |
|
0.99 |
10000 |
|
7
9) Загрузим, предобработаем и подадим на вход обученной нейронной сети собственное изображение, созданное при выполнении лабораторной работы №1. Выведем изображение и результат распознавания.
#загрузка собственного изображения from PIL import Image
file_data = Image.open('test.png')
file_data = file_data.convert('L') # перевод в градации серого test_img = np.array(file_data)
#вывод собственного изображения
plt.imshow(test_img, cmap=plt.get_cmap('gray')) plt.show()
# предобработка test_img = test_img / 255
test_img = np.reshape(test_img, (1,28,28,1))
# распознавание
result = model.predict(test_img) print('I think it\'s ', np.argmax(result))
Результат:
8

I think it's 3
10) Сравним обученную модель сверточной сети и наилучшую модель полносвязной сети из лабораторной работы №1.
• Количество настраиваемых параметров:
1)сверточной сети: 34826;
2)наилучшей полносвязной сети (100 нейронов в первом слое, 300 нейронов во втором слое): (784 + 1)*100 + (100 + 1)*300 + (300 + 1)*10 = 111810.
Следовательно, у наилучшей полносвязной сети примерно в 3,2 раза больше настраиваемых параметров, чем у сверточной сети.
• Количество эпох обучения:
1)сверточной сети: 15 эпох;
2)наилучшей полносвязной сети: 100 эпох.
Следовательно, для качественного обучения наилучшей полносвязной сети потребовалось примерно в 6,7 раз больше эпох обучения, чем сверточной сети.
• Качество классификации тестовой выборки:
1) у сверточной сети:
метрика качества = 0,990;
ошибка на тестовых данных = 0,034.
2) у наилучшей полносвязной сети:
метрика качества = 0,962;
ошибка на тестовых данных = 0,140.
9
Сверточная сеть верно распознала тестовые изображения и собственное изображение цифры, поданное на ее вход. Наилучшая полносвязная сеть верно распознала одно из двух тестовых изображений и собственное изображение цифры, поданное на ее вход.
Для сверточной сети значения параметров Precision, Recall, F1-score, рассчитанные для каждого из 10 классов, близки к идеальному значению, равному единице. Невзвешенное среднее и взвешенное среднее значения этих параметров также близки к идеальным.
Таким образом, можно сделать вывод, что для сверточной сети требуется меньше настраиваемых параметров и эпох обучения, чем для полносвязной сети, при этом значение метрики качества у нее выше, а ошибка на тестовых данных меньше, чем у полносвязной сети. Для распознавания изображений цифр целесообразно применять сверточную нейронную сеть.
10