

Самостоятельная работа по курсу «Практикум на эвм»
1 Цель самостоятельной работы – научиться использовать теоретический материал изложенный в курсах «Системы программирования» и «Языки программирования» для решения прикладных задач, используя современные системы программирования.
2 Краткие методические указания. Для успешного выполнения самостоятельной работы необходимо использовать методические материалы, рекомендованные в курсах «Системы программирования» и «Языки программирования». При выполнении самостоятельного задания необходимо разработать и отладить прикладную программу на языках С++, С# и Java используя системы программирования Visual Studio и Eclipse (Индиго). Для реализации программы должны использоваться средства ООП, многопотокового программирования и компонентного программирования. Прикладная программа должна формировать поток символов введенных с клавиатуры, анализировать поток символов поступающих с клавиатуры и выделять из этого потока слова заданного языка, печатать полученные слова (лексемы) языка. Описание языка задается в словесной форме. В процессе выполнения самостоятельной работы необходимо разработать формальное описание грамматики заданного языка, на основании полученного формального описания разработать блок схему решения поставленной задачи с указанием внутренних состояний процесса решения. На основании полученной блок схемы решения задачи разработать и отладить прикладную программу решения задачи в консольном режиме и с использованием оконных компонент. В консольном режиме процесс решения должен быть представлен тремя потоками выполнения (процессами): формирование потока символов, анализа потока символов, обработки (печати) полученных слов. Отчет о выполнении самостоятельной работы должен содержать постановку задачи, описание процесса решения задачи и описания контрольного примера. Ниже приведен пример решения поставленной задачи.
2.1 Пример выполнения самостоятельной работы.
2.1.1 Постановка задачи. Разработать синтаксический анализатор слов заданного языка L в алфавите символов ASCII, которые поступают с клавиатуры. Языку L принадлежат все слова алфавита ASCII, состоящие из пар строчных латинских букв ab и ba. Пример языка заимствован из [1-стр 23]. Для упрощения реализации алфавит расширен до всего множества символов ASCII.
2.1.2 Описание грамматики и схемы реализации процесса решения задачи. Слова языка L могут быть описаны леволинейной грамматикой следующим образом:
SC~a&~b :Слово обнаружено, если в С получено не а и не b (~a,~b)
CAb|Ba :В С попадаем из А, если получили b или из В, если а
Aa|Ca :В А попадаем если в Н пришло а или из С, если а
Bb|Cb :В В попадаем если в Н пришло b или из С, если b
Полученное описание недостаточно для описания процесса анализа слов языка средствами ООП. Используя это описание можно описать граф дискретного автомата, работа которого соответствует алгоритму решения поставленной задачи. Граф переходов такого автомата изображен на рисунке 1.
 .
.
Рис 1. Граф переходов дискретного автомата, описывающего анализатор языка L.
В соответствии с описанием грамматики автомат должен иметь четыре состояния, которые обозначены буквами Н,А,В и С. Причем Н это начальное состояние. Стрелки выходящие из вершин графа описывают функцию переходов автомата. Символы до значка / определяют условие перехода, а символы указанные после / определяют изменение внутреннего состояния, стрелка ребра, кроме этого указывает обозначение нового состояния. Используя описание автомата, изображенного на рисунке 1 можно разработать программу, которая будет распознавать в потоке символов, поступающих с клавиатуры, слова языка L. Блок схема программы анализа показана на рисунке 2.

Рис 2. Блок схема анализа слов заданного языка.
В алгоритме синтаксического анализа, который изображен на рисунке 2, овалы, имеющие надпись «Ждать s» обозначают состояния процесса анализа. Процесс анализа обрабатывает последовательность поступающих символов и помещает обнаруженные слова в буфер bf. При получении слова запускается процесс обработки слова.
Процессом будем называть данные и последовательность операторов, выполнение которых приводит к получению результата. Значение данных и оператор, который надо выполнить следующим определяют текущее состояние процесса. Это текущее состояние процесса называют контекстом процесса. Схема, изображенная на рисунке 2, показывает, какие операторы надо выполнить, и в какое состояние перейти, в зависимости от последовательности поступивших символов.
Решаемая задача может быть представлена тремя процессами. Процесс получения последовательности символов, процесса синтаксического анализа и процесса обработки полученных слов. Процесс получения последовательности символов ждет нажатия кнопки клавиатуры, получает код нажатой кнопки s и передает его процессу анализа. Процесс анализа выделяет из последовательности символов слова языка и передает их процессу обработки слов. Схема взаимодействия процессов показана на рисунке 3.

Рис 3. Взаимодействие процессов получения слов языка.
Процесс получения символов с клавиатуры, переключаясь на процесс синтаксического анализа передает ему полученный символ s. После обработки полученного символа процесс анализа переключается на выполнение процесса получения символов. Поэтому взаимодействие процессов обозначено двунаправленной стрелкой, а передача кода символа одинонаправленной.
2.2 Реализация решения задачи процессами на языке С++. В языке С и С++ существуют функции библиотеки <csetjmp> (для С++) [Ш-606,608], которые позволяют выполнять переклчения процессора от выполнения операторов одного процесса к выполнению операторов другого процесса с сохранением и восстановлением контекстов процесса. Для использования этих функций необходимо для каждого процесса создать свой контекст, в котором, при переключении на другой процесс, будут сохраняться данные необходимые для возобновления прерванного процесса. Контекст представляет собой область данных типа jmp_buf. Для переключения процессов используются две функции: setjmp(jmp_buf from) и longjmp(jmp_buf to, int vlm).
Функция setjmp(jmp_buf from), выполняемая в текущем процессе, сохраняет в области from контекст выполняемого процесса ( указатель на этот оператор setjmp) и возвращает 0. Функция longjmp(jmp_buf to, int vlm) переключает процессор на выполнение функции setjmp, указанной в контексте to, и передает функции setjmp, указанной в контексте to целое значение vlm. Функция setjmp, указанная в to восстанавливает контекст, и возвращает, полученное от функции longjmp значение vlm. Причем нулевое значение vlm заменяется на значение 1. Иными словами, функция setjmp, вызванная при восстановлении контекста функцией longjmp, возвращает не нулевое значение. Схема применения функций setjmp и longjmp для переключения процессов показана на рисунке 4.
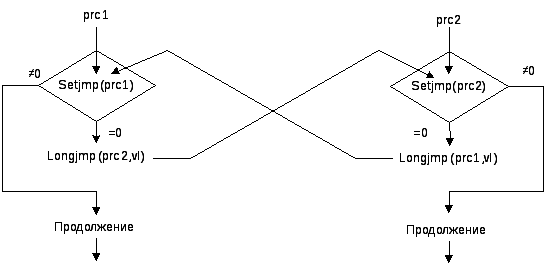
Рис 4 Переключение процессов.
На рисунке 4 показана схема применения функций setjmp и longjmp для переключения между двумя процессами, которые имеют контексты prc1 и prc2. Пусть выполняются операторы процесса prc1, и пришло время выполнения оператора setsjmp с параметром, который указывает на контекст prc1. Так как функция setsjmp выполняется из текущего процесса, то она сохраняет контекст текущего процесса в области prc1 и возвращает 0. Возвращаемое значение этой функции является аргументом условного оператора, поэтому выполняется следующий оператор, который является функцией longjmp(prc2,vl) с параметрами prc2 и vl. Эта функция выполняет функцию setjmp, указанную контекстом prc2, с параметром vl. Так как эта функция setjmp выполняется из другого процесса (prc1), то она возвращает значение vl отличное от нуля. Поэтому в процессе prc2 происходит переход на оператор «продолжение», следующий за условным оператором.
Если при выполнении операторов «продолжение» prc2 встретится конструкция показанная на Рис 4, то произойдет переключение на выполнение операторов «продолжение» процесса prc1. Описанный порядок применения функций setjmp и longjmp, позволяет организовать взаимодействие процессов и обмен информацией между ними показанные на рисунках 2 и 3. Программа Анализ_0 (Приложение) демонстрирует применение функций setjmp и longjmp для реализации трех процессов: ввода последовательности символов, анализа последовательности символов и обработки полученных слов. В этой программе процесс получения символов описан главной функцией _tmain и использует для сохранения своего состояния (контекста) область prc1. Процесс синтаксического анализа последовательности символов, соответствующий схеме на рисунке 2, реализован методом anlz(), который для сохранения своего состояния использует область prc2. Процесс обработки слов реализован функцией prnt_wd(), который для сохранения своего состояния использует область prc3. На рисунке 5 показана схема взаимодействия и начальной установки процессов prc1 и prc2.

Рис 5. Взаимодействие процессов prc1 и prc2.
Для установки начального состояния процесса prc2 выполняется переключение, показанное на рисунке 3, однако вместо функции longjmp выполняется обращение к функции anlz(), реализующей prc2. При этом обращении сбрасывается буфер bf и происходит переключение на головную функцию, контекст которой сохранен в prc1. При переключении контекст функции anlz() сохраняется в prc2, Этот контекст содержащий указатель на следующий оператор функции anlz() будет использоваться для возвращения к анализу символов после его получения в головной функции. Таким образом, контекст процесса сохраняет текущее состояние процесса и позволяет реализовать взаимодействие процессов показанное на рисунках 2 и 3.
В приложении представлена программа, реализующая алгоритм анализа изображенный на рисунке 2. После запуска программы и ввода контрольной последовательности символов получен следующий результат.
Вводите символы до Esc
111abbas
Получили слово abba
1111111111111111111111babaabt
Получили слово babaab
←Для продолжения нажмите любую клавишу . . .
Программа обнаруживает во введенной последовательности слова заданного языка и завершает выполнение после ввода символа Esc.
2.2 Реализация решения задачи с использованием компонент Windows Form в С++. Порядок создания приложений, использующих компоненты Windows Form описан в ПЗ_02 и [3]. Для решения поставленной задачи необходимо на форме разместить два окна. Одно окно использовать для ввода символов, а другое для печати полученных слов заданного языка. Система программирования Visual Studio разбивает задачу на отдельные потоки выполнения. Используя абстрактные классы и виртуальные функции предоставляет разработчику оконные компоненты ОС Windows и обработчики событий происходящих с компонентами. Например, если в окно ввода текста поместить курсор, то будут обрабатываться события при нажатии кнопок на клавиатуре. Шаблон обработчика событий клавиатуры поставляет информацию о нажатой кнопке. Эту информацию можно использовать для анализа последовательности нажатых кнопок и выделять в этой последовательности слова заданного языка. Пример решения поставленной задачи с использованием компонент Windows Form показан в программе Син_Анализ, которая приведена в приложении. В обработчике прерываний нажатой кнопки (KeyPress) для определения состояний процесса используется закрытая переменная stt перечислимого типа Stat, описанием которой доопределен класс Form1. Мы не можем использовать взаимодействие сопрограмм (setjmp и longjmp) так как не имеем доступа к компонентам Windows. Поэтому компоненты Windows взаимодействуют с прикладной программой при помощи вызова виртуальных функций обработки событий.
2.3 Реализация решения задачи процессами на языке С#. Взаимодействие процессов в языке C# реализуется при помощи функций обратного вызова (делегатов) [4 Ш-769] или классов для реализации потоков вычислений, которые реализованы в библиотеке System.Threading, описаннов в разделе многопоточное программирование [4 Ш-833]. При использовании потоков решаемую задачу разделим на четыре части: главный поток, реализуемый методом Main прикладной программы, поток получения последовательности символов, реализованный статическим методом Get_s, поток анализа последовательности символов Anlz_Pt, реализованный статическим методом Anlz_Pt и поток обработки полученных слов Prt_wd, реализованный статическим методом Prt_wd. Для организации взаимодействия потоков используются глобальные статические переменные класса прикладной программы, представляющие очередной символ потока символов s и буфер для сохранения полученных слов bfwd. Для синхронизации использования процессора потоками используются семафоры [Ш-867].
Главный поток создает и запускает потоки Get_s, Anlz_Pt и Prt_wd. После запуска этих потоков главный поток приостанавливает свою работу выполняя функцию WaitOne(). Готовым к выполнению оказывается только поток ввода символов. Для получения символа он выполняет функцию ReadKey(). Получив символ от клавиатуры, поток ввода устанавливает семафор sma процесса анализа и снова ждет символ от клавиатуры. Но мы не можем очень быстро нажать новую кнопку, и поэтому процессор предоставляется потоку анализа. Если вводить не посимвольно, а целой строкой, то для правильной работы потоков необходимо изменить их приоритеты. В этом случае приоритет потока анализа должен быть больше чем приоритет потока получения символов.
Если поток анализа обнаруживает слово языка, то он устанавливает семафор процесса обработки, а сам переходит в режим ожидания сигнала (установки семафора sma) процессом ввода символов. Так как он не может быстро дождаться символа от потока ввода, то готовым оказывается только процесс обработки, который печатает полученное слово.
Процесс получения потока символов получает символы кнопок нажатых на клавиатуре помещает их коды в глобальную переменную s и анализирует эти символы. Если нажата кнопка с кодом End_smb, то устанавливается семафор sms. Это значение семафора запускает приостановленный раннее главный поток, который функциями Abort() останавливает потоки и завершает прикладную программу.
Следует обратить внимание, что в потоке анализа последовательности символов используется оператор goto, который при умелом использовании позволяет получать понятные и компактные описания.
2.4 Реализация решения задачи с использованием компонент Windows Form в C#. Методика разработки прикладных программ с использованием Windows Form описана в [5]. Процесс реализации поставленной задачи с использованием компонент Windows Form в языке C# почти не отличается от процесса создания таких программ в языке С++. Пример решения задачи демонстрируется программой Син_Анализ из директории С# приложения. Обратите внимание, что для языка C# испольлуется квалификатор доступа «.».
2.5 Реализация решения задачи с использованием потоков на языке Java. Методика разработки многопоточных программ на языке Java описана в [6] [Ш-263]. Программа Anlz_Pt в приложении JV_ANLZ демонстрирует процесс анализа потока символов с использованием потоков средствами языка Java. В этой программе главный поток на базе классов создает три потока, используя интерфейс Rannable.
Калcc Get_smb в методе run описывает ввод потока символов. В языке Java не удобно вводить отдельные символы. Поэтому используется стандартное окно для ввода строк. Функция JOptionPane.showInputDialog("Введите строку символов") из библиотеки javax.swing.JOptionPane позволяет вводить, в том числе и пустые, строки символов. Функция run, описывающая ввод символов представляет собой цикл ввода строк, в теле которого из строки извлекаются символы. Эти символы помещаются в открытое поле s. После этого производиться переключение на поток анализа, который извлекает их из этого поля. Темп извлечения символов слишком большой. Поток обработки может не успеть напечатать полученные слова. Поэтому темп выдачи символов замедлен выполнением функции sleep(1).
Класс Anlz описывает процесс (поток выполнения операторов) анализа последовательности символов, которые он получает от потока ввода символов Get_smb. Этот поток описан как цикл, который завершается присбросе флага ont. Этот флаг устанавливается в конструкторе класса, а сбрасывается методом tstp(), который вызывается из головного потока при завершении выполнения потока ввода символов. Головной поток обнаруживает завершение потока ввода, опрашивая его состояние методом isAlive(). После создания и запуска поток анализа в описанном выше цикле ждет получения очередного символа, выполняя функцию wait(). После этого используется оператор switch для реализации блок схемы, показанной на рисунке 2. При обнаружении слова языка поток анализа поток анализа переключается на поток обработки полученных слов.
Класс Prt_wd описывает процесс (поток выполнения) обработки слов. Обработка слов реализована как цикл, который ждет получения слова, печатает слово из буфера bfwd описанного как доступный контейнер в классе анализа. После печати поток обработки вновь ждет от процесса анализа сигнал о получении слова.
2.6 Реализация решения задачи с использованием оконных компонент языка Java. Методика разработки программ с использованием оконных компонент описано во второй части [6, Ш=829] и в [7]. Для разработки программ с использованием графических компонент используется библиотека avt swing. Для создания приложения, которое использует эти компоненты этих библиотек класс прикладной программы должен наследовать класс JFrame. Этот класс описывает контейнер для размещения компонент. Базовый класс JFrame доопределяется в конструкторе производного класса. В листинге 1 приведен пример такого доопределения.
public class Anlz_Frm1 extends JFrame{
Anlz_Frm1(String ttl,int w,int h){//Конструктор программы
super(ttl); //Вызов базового конструктора
setDefaultCloseOperation(EXIT_ON_CLOSE);//При закрытии окна - выход
setSize(w,h);//Устанвка размеров окна
setVisible(true); //Делаем форму видимой
}// Anlz_Frm1
public static void main(String[] args) {//Головной метод программы
new Anlz_Frm1("Простое окно",500,300);//Создаем безимянный объект с формой
System.out.println("Головная программа завершена!");
}
Конструктор программы вызывает метод super(String str), который вызывает конструктор базового класса и своим аргументом определяет заголовок контейнера. Затем определяем действия после нажатия кнопки завершения в заголовке контейнера – завершить выполнение программы. Метод setSize устанавливает размеры контейнера, а метод setVisible делает контейнер видимым. Головной метод создает безымянный экземпляр контейнера и завершает выполнение.
После запуска на экране появляется окно с тремя стандартными кнопками, одну из которых мы доопределили в конструкторе класса нашей программы. Обратите внимание, что метод main завершает работу, а окно контейнера продолжает работать. Очевидно потоки выполнения у них разные. Методика размещения в контейнере нужных компонент описана в рекомендованной литературе. В листинге 2 показана программа синтаксического анализа, которая использует два окна для отображения введенной последовательности символов и отображения обнаруженных слов языка.
Листинг 2. Анализатор, использующий графические компоненты swing.
import javax.swing.JFrame;
import java.awt.*;//Компоненты AWT
import java.awt.event.KeyEvent;
import java.awt.event.KeyListener;
public class Anlz_Frm1 extends JFrame implements KeyListener{
TextField pss;//Окно ввода данных
TextArea memo;//Окно отображения данных
String Lstr="";//Буфер полученного слова
enum Stat {H,A,B,C};//Перечисление для обозначения состояний
private Stat stt;//Объявление переменной для обозначения переменной
Anlz_Frm1(String ttl,int w,int h){//Конструктор программы
super(ttl); //Вызов базового конструктора
setDefaultCloseOperation(EXIT_ON_CLOSE);//При закрытии окна - выход
setSize(w,h);//Устанвка размеров окна
add(new Label("Вводите символы"));//Создание обозначения окна ввода
setLayout(new FlowLayout());//Автоматическое размещение компонент
pss = new TextField(60);//Создание контейнера для отображения
add(pss);//Подключение области ввода к окну.
//формирование свойств области отображения
add(new Label("Полученные слова"));//Создание обозначения окна вывода
memo = new TextArea("",10,60,TextArea.SCROLLBARS_VERTICAL_ONLY);//Окно вывода
add(memo);//подключение окна вывода к форме
pss.addKeyListener(this);//Подключение обработчиков событий от клавиатуры
memo.setFocusable(false);//Запрещаем перевод фокуса в поле вывода
stt=Stat.H;//Начальное состояние
setVisible(true); //Делаем форму видимой
}//Anlz_Frm1
public static void main(String[] args) {//Головной метод программы
new Anlz_Frm1("Синтаксический анализатор",500,300);//Создаем безимянный объект с формой
System.out.println("Головная программа завершена!");
}
public void keyPressed(KeyEvent s){//Обработка события нажатия клавиши
char smb;//Полученный символ
smb=(char)(s.getKeyCode()|0x20);//Сохранение и преобразование символа
switch (stt){
case H://Переходы из начального состояния
Lstr="";//Сброс слова языка
Lstr=Lstr+String.valueOf(smb);//Сохранение полученного символа в слове языка
switch (smb){//Если s равен
case 'a': stt=Stat.A;break;//а, то переходим в А
case 'b': stt=Stat.B;break;//b, то переходим в В
}//иначе (не а и не b) остаемся в Н
break;
case A://Переходы из состояния А
Lstr=Lstr+String.valueOf(smb);//Сохранение полученного символа в слове языка
if(smb=='b')stt=Stat.C;//Если получен символ b, то переходим в С
else stt=Stat.H;//иначе не b переходим в Н
break;
case B://Переходы из состояния В
Lstr=Lstr+String.valueOf(smb);//Сохранение полученного символа в слове языка
if(smb=='a')stt=Stat.C;//Если получен симво а, то переходим в С
else stt=Stat.H;//иначе не а переходим в Н
break;
case C://Переходы из состояния С
Lstr=Lstr+String.valueOf(smb);//Сохранение полученного символа в слове языка
switch (smb){//Если s равен
case 'a': stt=Stat.A;break;//а, то переходим в А
case 'b': stt=Stat.B;break;//b, то переходим в В
default://иначе (не а и не b)
stt=Stat.H;//переходим в Н
memo.append(Lstr.substring(0,Lstr.length()-1)+"\n");//переписываем текст в memo и
}
break;
}//switch (stt){
}//void keyPressed
public void keyReleased(KeyEvent arg0){}//Эти события
public void keyTyped(KeyEvent arg0){} //не обрабатывам
}//class Anlz_Frm1