

МИНОБРНАУКИ РОССИИ
Санкт-Петербургский государственный
электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
Кафедра математического обеспечения и применения ЭВМ
Отчет по лабораторной работе №1
по дисциплине «Алгоритмы и структуры данных»
Студент гр. 930 |
|
Преподаватель |
Колинько П.Г. |
Тема: Множества
Содержание
Введение ........................................................................................................ 3
Задание ........................................................................................................... 3
Постановка задачи и описание решения ..................................................... 3
Временная сложность выполнения алгоритмов.......................................... 4 Контрольные тесты ...................................................................................... 5
Вывод ............................................................................................................. 7
Список использованных источников........................................................... 8
Текст программы ........................................................................................... 9
Цель работы
Исследование четырех способов хранения множеств в памяти ЭВМ
Задание Инициализировать множество е, содержащее шестнадцатеричные цифры, имеющиеся в а или в, но отсутствующие в с и в d
E = A+B – С - D
Постановка задачи и описание решения
Задача заключается в том, чтобы образовать объединение множеств А и В и вычесть из него С и D.
Для реализации задачи используется 4 способа хранения множеств: массивы, списки, массивы битов и машинное слово.
Для генерации тестов сперва инициализируются случайные размеры массивов, а потом они заполняются уникальными символами (если размер массива меньше универсума, то оставшаяся часть заполняется нулями-терминаторами). Затем информацией из массивов заполняются списки, массивы битов и машинные слова.
Замеряемое время указывается в тиках: чем меньше тиков приходится на исполнение алгоритма, тем он эффективнее. Каждый алгоритм прогоняется 1000000 раз. Между замерами времени отсутствуют функции и операторы вывода.
Временная сложность выполнения алгоритмов
В теории в массивах временная сложность доступа к элементу О(1), однако временная сложность копирования данных и их удаления занимает уже О(n). В списках временная сложность чтения O(n), так как к требуемому элементу надо обращаться через указатели предыдущих элементов, однако временная сложность удаления – O(1), так как требуется только перенаправить указатели и очистить память под элемент. В массиве битов временная сложность двуместной операции будет O(n), что при фиксированном n равно O(1), то есть не зависит от мощности этих множеств. Операции над множествами в форме машинного слова выполняются за один шаг алгоритма независимо от мощности множеств, то есть имеют временную сложность O(1). В теории алгоритм с машинным словом выполняется в (O(n)/O(1)) раз быстрее, чем со списком
Контрольные тесты
Задаются 4 массива со случайными размерами и уникальными символами.
Каждое задание отделяется друг от друга. Первый алгоритм проводился над массивами, второй – над списками, третий – над массивами битов, четвертый – над машинными словами
В четвертой задаче ответ предоставляется в виде машинного слова (для проверки используется ответ из третьего алгоритма)
В моей программе алгоритм с массивом реализуется за время O(n^2), так как внутри цикла стоит еще один цикл для избегания дубликатов, со списком – за время O(n^2) по аналогичной причине, с массивом битов – за O(n), а с машинным словом – за O(1)
В
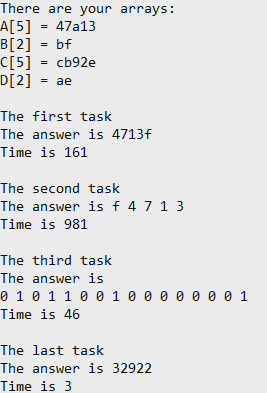 первом примере сгенерировались массивы,
размером гораздо меньше универсума.
Поэтому было затрачено гораздо меньше
времени, чем в следующем примере.
Алгоритм
с машинным словом выполняется в 327 раз
быстрее, чем со списком
первом примере сгенерировались массивы,
размером гораздо меньше универсума.
Поэтому было затрачено гораздо меньше
времени, чем в следующем примере.
Алгоритм
с машинным словом выполняется в 327 раз
быстрее, чем со списком
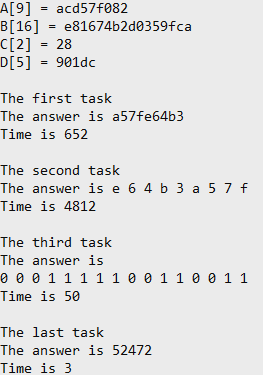
Здесь было затрачено больше времени, так как обрабатывались бОльшие массивы (ответ тоже получился большим) Алгоритм с машинным словом выполняется в 1604 раза быстрее, чем со списком

В этом примере ответом является пустое множество. Ответ меньше предыдущего, однако он обрабатывался гораздо больше из-за бОльшего объема входных_данных. Алгоритм с машинным словом выполняется в 7145 раз быстрее, чем со списком Таким образом, наблюдается прямо пропорциональная зависимость времени обработки от размера данных.
Вывод
Таким образом, самым эффективным способом хранения данных является машинное слово. После него идет массив битов, потом обычный массив, а на последнем месте список.
Достоинство массивов заключается в мгновенном доступе к элементу множества, а недостаток – требуется заранее знать размер структуры данных и дорогостоящая операция удаления или добавления элемента. Их стоит использовать, когда заранее известно число элементов и часто требуется считывать информацию.
Достоинство списков заключается в мгновенном удалении или добавлении элемента, неограниченности размера структуры данных, а недостаток – чтение элемента за время O(n). Их стоит использовать, когда заранее неизвестно число элементов и часто требуется удалять или добавлять информацию.
Достоинство массивов битов заключается в устранении дубликатов и быстрой операции над множествами, однако он может быть представлен в более компактной форме. Их стоит использовать для устранения дубликатов и быстрых побитовых операций.
Достоинства у машинного слова такие же, как и у массива битов, однако для универсума> 64 надо использовать несколько слов, и отсутствует удобный доступ к каждому биту машинного слова, как к элементу массива (требуется наличие простой функции для превращения номера бита в число и наоборот). Их стоит использовать для тех же целей, что и массивы битов.
Список использованных источников
Стивен Прата: Язык программирования С++. Лекции и упражнения. - 2012. – 1248 с.
Колинько П.Г.: Методические указания по дисциплине “Алгоритмы и структуры данных, часть 1”. – 2020. – 64 с.
Текст программы
#include <iostream>
#include <time.h>
#include <cstring>
using namespace std;
const int SIZE = 16;
const int TIMES=1000000;
struct Node
{
char ch;
Node *next;
Node(char ch, Node* n=nullptr): ch(ch), next(n){}
~Node(){delete next;}
};
void GenArr(char Arr[]);
void ForArray(char A[], char B[], char C[], char D[]);
void forList(Node *HeadA, Node *HeadB, Node *HeadC, Node *HeadD);
int main()
{
srand(time(0));
clock_t start, stop;
char A[SIZE+1]{}, B[SIZE+1]{}, C[SIZE+1]{}, D[SIZE+1]{};
int i;
bool key=0;
GenArr(A);
GenArr(B);
GenArr(C);
GenArr(D);
cout << "There are your arrays:\n";
cout << "A["<<strlen(A)<<"] = "<<A<<endl;
cout << "B["<<strlen(B)<<"] = "<<B<<endl;
cout << "C["<<strlen(C)<<"] = "<<C<<endl;
cout << "D["<<strlen(D)<<"] = "<<D<<"\n\n";
cout << "The first task\n";
ForArray(A, B, C, D);
cout << "\nThe second task\n";
Node *HeadA=nullptr, *HeadB=nullptr, *HeadC=nullptr, *HeadD=nullptr;
for (i=0; A[i]; i++) HeadA=new Node(A[i], HeadA);
for (i=0; B[i]; i++) HeadB=new Node(B[i], HeadB);
for (i=0; C[i]; i++) HeadC=new Node(C[i], HeadC);
for (i=0; D[i]; i++) HeadD=new Node(D[i], HeadD);
forList(HeadA, HeadB, HeadC, HeadD);
cout << endl << "The third task\n";
bool boolA[SIZE]{}, boolB[SIZE]{}, boolC[SIZE]{}, boolD[SIZE]{};
for (i=0; i<SIZE; i++)
{
boolA[(A[i] <= '9')? A[i]-'0' : A[i]-'a'+10] = 1;
boolB[(B[i] <= '9')? B[i]-'0' : B[i]-'a'+10] = 1;
boolC[(C[i] <= '9')? C[i]-'0' : C[i]-'a'+10] = 1;
boolD[(D[i] <= '9')? D[i]-'0' : D[i]-'a'+10] = 1;
}
bool boolE[SIZE]{false};
start = clock();
key=boolE[0];
for(int q=0; q<TIMES; q++) for (i=0; i<SIZE; i++) boolE[i] = (boolA[i]||boolB[i])&&(!(boolC[i]||boolD[i]));//combined
boolE[0]=key;
key=0;
stop = clock();
for (i=0; i<SIZE; i++) if (boolE[i]) key=1;
cout << "The answer is ";
if (key)
{
cout << endl;
for (i=0; i<SIZE; i++) cout << boolE[i]<< " "; cout << endl;
}
else cout << "None\n";
cout << "Time is "<< stop-start<< endl;
cout << endl << "The last task\n";
int wordA=0, wordB=0, wordC=0, wordD=0, wordE=0;
for (i=0; A[i]; i++) wordA |= (1 << ((A[i] <= '9')? A[i]-'0' : A[i]-'a'+10));
for (i=0; B[i]; i++) wordB |= (1 << ((B[i] <= '9')? B[i]-'0' : B[i]-'a'+10));
for (i=0; C[i]; i++) wordC |= (1 << ((C[i] <= '9')? C[i]-'0' : C[i]-'a'+10));
for (i=0; D[i]; i++) wordD |= (1 << ((D[i] <= '9')? D[i]-'0' : D[i]-'a'+10));
start = clock();
for (int q=0; q<TIMES; q++) wordE=(wordA|wordB)&(~wordC)&(~wordD);
stop = clock();
cout <<"The answer is " <<wordE<< endl;
cout << "Time is "<< stop-start<< endl;
return 0;
}
void GenArr(char Arr[])
{
bool flagsame;
char buf;
int sArr=rand()%SIZE+1;
for (int i=0; i<sArr; i++)
{
do
{
flagsame=false;
if (rand()%2)
buf=rand()%10+ '0';
else buf=rand()%6+ 'a';
for (int j=0; j<sArr; j++)
if (buf == Arr[j]) flagsame=true;
}
while(flagsame);
if (!flagsame) Arr[i]=buf;
}
}
void ForArray(char A[], char B[], char C[], char D[])
{
clock_t start, stop;
char E[SIZE+1], P[SIZE+1];
int i, j, k=0;
bool flagsame;
start = clock();
for (int q=0; q<TIMES; q++)
{
for (i=0; A[i]; i++)
P[i]=A[i];
for (j=0; B[j]; j++)
{
flagsame=false;
for (k=0; A[k]; k++)
if (B[j] == A[k]) flagsame=true;
if (!flagsame)
P[i++]=B[j];
}
P[i]='\0';
k=0;
for (i=0; P[i]; i++)
{
flagsame=false;
for (j=0; C[j]; j++)
if (P[i] == C[j]) flagsame=true;
for (j=0; D[j]; j++)
if (P[i] == D[j]) flagsame=true;
if (!flagsame)
E[k++]=P[i];
}
E[k]='\0';
}
stop=clock();
cout<<"The answer is ";
if (E[0]=='\0') cout << "None\n";
else cout << E << endl;
cout << "Time is "<< (stop-start)<< endl;
}
void forList(Node *HeadA, Node *HeadB, Node *HeadC, Node *HeadD)
{
clock_t start, stop;
bool flagsame=false;
Node* HeadE=nullptr;
start = clock();
for (int q=0; q<TIMES; q++)
{
HeadE=nullptr;
for (auto x=HeadA; x; x=x->next)
HeadE=new Node(x->ch, HeadE);
for (auto y=HeadB; y; y=y->next)
{
flagsame=false;
for (auto x=HeadE; x; x=x->next)
if (x->ch == y->ch) flagsame=true;
if (!flagsame)
HeadE=new Node(y->ch, HeadE);
}
for (auto x=HeadE; x; x=x->next)
{
flagsame=false;
for (auto y=HeadC; y; y=y->next)
if (y->ch == x->ch) flagsame=true;
for (auto y=HeadD; y; y=y->next)
if (y->ch == x->ch) flagsame=true;
if (flagsame)
{
Node *temp=HeadE;
Node *buf;
if(HeadE && HeadE != x)
{
while ( temp && temp->next != x) temp = temp->next;// Находим элемент, предшествубщий удаляемому
if (temp)
{
buf = temp->next;
temp->next = temp->next->next;
delete buf;
}
else cout << "Deleting error\n";
}
else if(HeadE == x)
{
temp = HeadE;
HeadE=HeadE->next;
delete temp;
}
}
}
}
stop=clock();
cout << "The answer is ";
if (HeadE)
for (auto x=HeadE; x; x=x->next) cout << x->ch<<" ";
else cout << "None";
cout << "\nTime is "<<(stop-start)<<endl;
}
Санкт-Петербург
2020