

1. Классы, как основа архитектурных решений в программных системах. Отношение (зависимости) между классами. Слабые связи. Реализация зависимостей на UML и языке JAVA (код : агрегация, композиция). НАСТЯ
Класс – множество(совокупность) объектов, связанных общностью структуры и поведения. Класс содержит описание данных и операций над ними. Объект - именованная модель реальной сущности, обладающая конкретными значениями свойств и проявляющая свое поведение. Объект - обладающий именем набор данных (полей и свойств объекта), физически находящихся в памяти компьютера, и методов, имеющих доступ к ним. Имя используется для работы с полями и методами объекта. Объект – экземпляр класса.
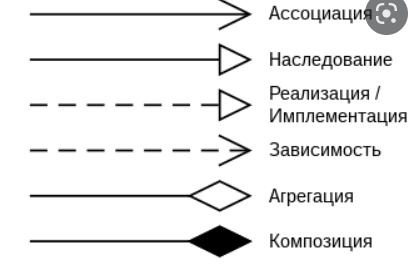
Отношение (зависимости) между классами:
Ассоциация (Association) - структурное отношение, описывающее множество связей между объектами классификаторов, где связь (Link) - это соединение между объектами, которое описывает связи между их экземплярами. Без ассоциаций мы имели бы просто некоторое количество классов, не способных взаимодействовать друг с другом. Менеджер может выписать Счёт. Соответственно возникает ассоциация между Менеджером и Счётом.
Наследование (inheritance) - процесс, посредством которого один класс может наследовать свойства другого класса и добавлять к ним свойства и методы, характерные только для него. Наследование бывает двух видов: одиночное наследование - подкласс (производный класс) имеет один и только один суперкласс (предок); множественное наследование - класс может иметь любое количество предков (в Java запрещено).
Реализация (Realization) — отношение между спецификацией и ее программной реализацией; указание на то, что поведение наследуется без структуры.
Зависимость (Dependency) - это семантическое отношение между двумя сущностями, при котором изменение одной из них (независимой сущности) может отразиться на семантике другой (зависимой).
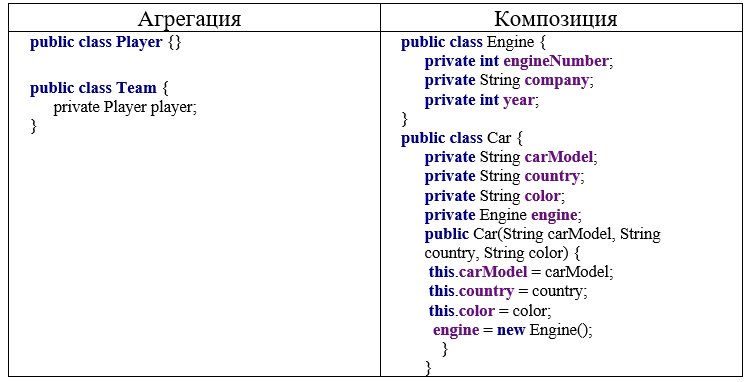
Агрегация и композиция являются частными случаями ассоциации. Это более конкретизированные отношения между объектами.
Отношение агрегации имеет место между несколькими классами в том случае, если один из классов представляет собой некоторую сущность, включающую в себя в качестве составных частей другие сущности. Эта взаимосвязь так же называется "часть-целое". Раскрывая внутреннюю структуру системы, отношение агрегации показывает, из каких компонентов состоит система и как они связаны между собой.
Отношение композиции служит для выделения специальной формы отношения "часть-целое", при которой составляющие части в некотором смысле находятся внутри целого. Специфика взаимосвязи между ними заключается в том, что части не могут выступать в отрыве от целого, т. е. с уничтожением целого уничтожаются и все его составные части.
Сильная связь возникает между типами сущностей в случаях, когда существование одного типа сущности невозможно без другого типа сущности.
Слабая связь возникает между двумя типами сущностей в случае, когда между ними нет прямой зависимости. В таком случае связь есть необязательный, то есть могут быть ситуации, когда связи между сущностями не нужны. Типы сущностей способны существовать автономно друг без друга.(Слабая связь реализуется обычно в агрегации вроде как)
Унифицированный язык моделирования (Unified Modeling Language - UML) это язык для специфицирования, визуализации, конструирования и документирования программных систем, а также бизнес моделей и прочих не программных систем. Словарь UML включает три вида строительных блоков: - Диаграммы; - Сущности; - Связи.
1.Первая из них – зависимость – семантически представляет собой связь между двумя элементами модели, в которой изменение одного элемента (независимого) может привести к изменению семантики другого элемента (зависимого). Графически представлена пунктирной линией, иногда со стрелкой, направленной к той сущности, от которой зависит еще одна; может быть снабжена меткой.
![]()
2.Отношение
реализации
- дополнительное отношение на диаграмме
классов,которое отображается только
между классами и интерфейсами. В тексте
на языке Java данное отношение обозначается
ключевым словом "implements".![]()
Агрегация Композиция
![]()
![]()
3.Отношения агрегации и композиции являются частными случаями ассоциации.
При агрегации реализуется слабая связь, то есть в данном случае объекты Car и Engine будут равноправны. В конструктор Car передается ссылка на уже имеющийся объект Engine. И, как правило, определяется ссылка не на конкретный класс, а на абстрактный класс или интерфейс, что увеличивает гибкость программы.
Композиция.Похоже на агрегацию только более сильная связь. Поэтому закрашенный ромб. Например: если уничтожается композитор, то его объекты классов на которые он ссылается также перестают существовать.
4. связь - обобщение – выражает специализацию или наследование, в котором специализированный элемент (потомок) строится по спецификациям обобщенного элемента (родителя). Потомок разделяет структуру и поведение родителя. Графически обобщение представлено в виде сплошной линии с пустой стрелкой, указывающей на родителя.
![]()
2. Отношение (зависимости) между классами. Слабые связи. Реализация зависимостей на UML и языке JAVA (код : ассоциация, наследование, реализация/имплементация, зависимость,). ПОЛИНА
Отношение (зависимости) между классами:
Ассоциация (Association) - структурное отношение, описывающее множество связей между объектами классификаторов, где связь (Link) - это соединение между объектами, которое описывает связи между их экземплярами. Без ассоциаций мы имели бы просто некоторое количество классов, не способных взаимодействовать друг с другом. Менеджер может выписать Счёт. Соответственно возникает ассоциация между Менеджером и Счётом.
Наследование (inheritance) - процесс, посредством которого один класс может наследовать свойства другого класса и добавлять к ним свойства и методы, характерные только для него. Наследование бывает двух видов: одиночное наследование - подкласс (производный класс) имеет один и только один суперкласс (предок); множественное наследование - класс может иметь любое количество предков (в Java запрещено).
Реализация (Realization) — отношение между спецификацией и ее программной реализацией; указание на то, что поведение наследуется без структуры.
Зависимость (Dependency) - это семантическое отношение между двумя сущностями, при котором изменение одной из них (независимой сущности) может отразиться на семантике другой (зависимой).
Агрегация и композиция являются частными случаями ассоциации. Это более конкретизированные отношения между объектами.
Отношение агрегации имеет место между несколькими классами в том случае, если один из классов представляет собой некоторую сущность, включающую в себя в качестве составных частей другие сущности. Эта взаимосвязь так же называется "часть-целое". Раскрывая внутреннюю структуру системы, отношение агрегации показывает, из каких компонентов состоит система и как они связаны между собой.
Отношение композиции служит для выделения специальной формы отношения "часть-целое", при которой составляющие части в некотором смысле находятся внутри целого. Специфика взаимосвязи между ними заключается в том, что части не могут выступать в отрыве от целого, т. е. с уничтожением целого уничтожаются и все его составные части.
Сильная связь возникает между типами сущностей в случаях, когда существование одного типа сущности невозможно без другого типа сущности.
Слабая связь возникает между двумя типами сущностей в случае, когда между ними нет прямой зависимости. В таком случае связь есть необязательный, то есть могут быть ситуации, когда связи между сущностями не нужны. Типы сущностей способны существовать автономно друг без друга.(Слабая связь реализуется обычно в агрегации вроде как)
Унифицированный
язык моделирования (Unified Modeling Language - UML)
это язык для специфицирования,
визуализации, конструирования и
документирования программных систем,
а также бизнес моделей и прочих не
программных систем. Словарь UML включает
три вида строительных блоков: - Диаграммы;
- Сущности; - Связи.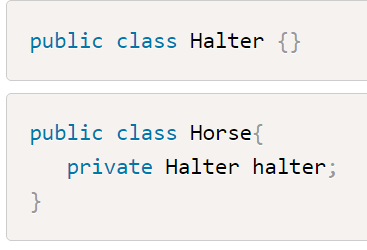
Ассоциация
Ассоциация в java описывает отношения между двумя классами. Он устанавливает отношения через их объекты. Ассоциация может представлять отношения «один к одному», «один ко многим», «многие к одному» или «многие ко многим».
Наследование
class Calculator { public class My_Calculator extends Calculator {
public static void main(String args[]) {
int c; int a = 10, b = 20;
My_Calculator cal = new My_Calculator();
cal.addition(a, b);
public void addition(int a, int b) { cal.subtraction(a, b);
c = a + b; cal.multiplication(a, b);
System.out.println("Сумма чисел: " + c); }}
}
}
Наследование (inheritance) — механизм, который позволяет описать новый класс на основе существующего (родительского). При этом свойства и функциональность родительского класса заимствуются новым классом.
Реализация/имплементация
Реализация – это семантическая связь между классами, когда один из них (поставщик) определяет соглашение, которого второй (клиент) обязан придерживаться. Это связи между интерфейсами и классами, которые реализуют эти интерфейсы. Это, своего рода, отношение «целое-часть». Поставщик, как правило, представлен абстрактным классом. В графическом исполнении связь реализации – это гибрид связей обобщения и зависимости: треугольник указывает на поставщика, а второй конец пунктирной линии – на клиента.
public interface Swimmable {
public void swim();
}
public class Duck implements Swimmable {
public void swim() {
System.out.println("Уточка, плыви!");
}
public static void main(String[] args) {
Duck duck = new Duck();
duck.swim();}
}
Зависимость
Зависимость – семантически представляет собой связь между двумя элементами модели, в которой изменение одного элемента (независимого) может привести к изменению семантики другого элемента (зависимого). Графически представлена пунктирной линией, иногда со стрелкой, направленной к той сущности, от которой зависит еще одна; может быть снабжена меткой.
Зависимость – это связь использования, указывающая, что изменение спецификаций одной сущности может повлиять на другие сущности, которые используют ее.
Когда класс А использует класс или интерфейс B, тогда А зависит от B. А не может выполнить свою работу без B, и А не может быть переиспользован без переиспользования B. В таком случае класс А называют «зависимым», а класс или интерфейс B называют «зависимостью».
3. Паттерны проектирования: определение, назначение, основные идеи использования. Порождающие, Структурные паттерны и Паттерны поведения. Примеры реализации архитектуры на UML и JAVA(по одному из каждой приведенной классификации). ЛИЗА
Шаблоны проектирования GoF - это многократно используемые решения широко распространенных проблем, возникающих при разработке программного обеспечения. Паттерн не является законченным образцом проекта, который может быть прямо преобразован в код. Типы паттернов проектирования: - порождающие; - структурные; - поведенческие.
Порождающие паттерны предоставляют механизмы инициализации, позволяя создавать объекты удобным способом.
Singleton. Гарантирует, что у класса есть только один экземпляр, и предоставляет к нему глобальную точку доступа. Существенно то, что можно пользоваться именно экземпляром класса, так как при этом во многих случаях становится доступной более широкая функциональность.
Factory (Фабрика) - используется, когда у нас есть суперкласс с несколькими подклассами и на основе ввода, нам нужно вернуть один из подкласса.
Abstract Factory (Абстрактная фабрика) - используем супер фабрику для создания фабрики, затем используем созданную фабрику для создания объектов.
Builder (Строитель) - используется для создания сложного объекта с использованием простых объектов. Постепенно он создает больший объект от малого и простого объекта.
Prototype (Прототип) - помогает создать дублированный объект с лучшей производительностью, вместо нового создается возвращаемый клон существующего объекта
public class Singleton {
private static final
Singleton INSTANCE = new Singleton();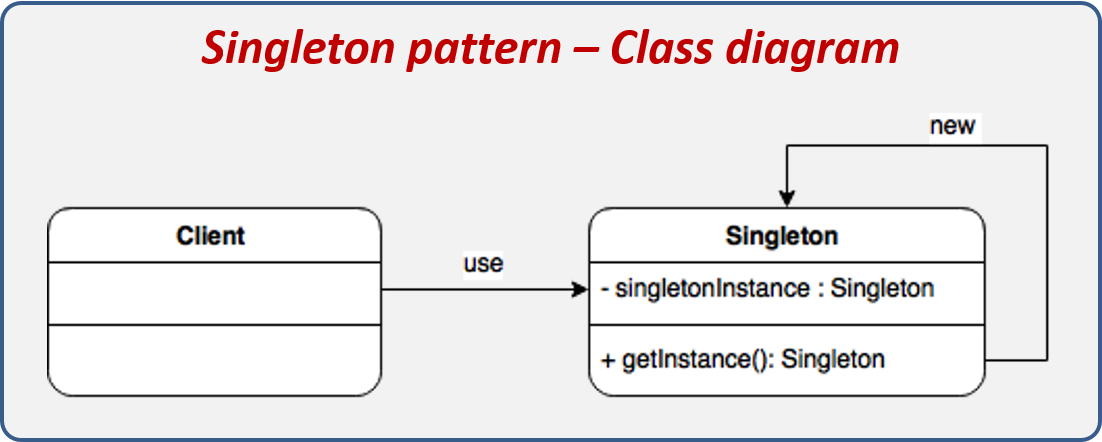
private Singleton() {
}
public static Singleton getInstance() {
return INSTANCE;
}
}
Структурные паттерны определяют различные сложные структуры, которые изменяют интерфейс уже существующих объектов или его реализацию, позволяя облегчить разработку и оптимизировать программу.
Adapter (Адаптер) - это конвертер между двумя несовместимыми объектами. Используя паттерн адаптера, мы можем объединить два несовместимых интерфейса.
Адаптер предусматривает создание класса-оболочки с требуемым интерфейсом.
Composite (Компоновщик) - использует один класс для представления древовидной структуры.
Proxy (Заместитель) - представляет функциональность другого класса.
Flyweight (Легковес) - вместо создания большого количества похожих объектов, объекты используются повторно.
Facade (Фасад) - обеспечивает простой интерфейс для клиента, и клиент использует интерфейс для взаимодействия с системой.
Bridge (Мост) - делает конкретные классы независимыми от классов реализации интерфейса.
Decorator (Декоратор) - добавляет новые функциональные возможности существующего объекта без привязки его структуры.
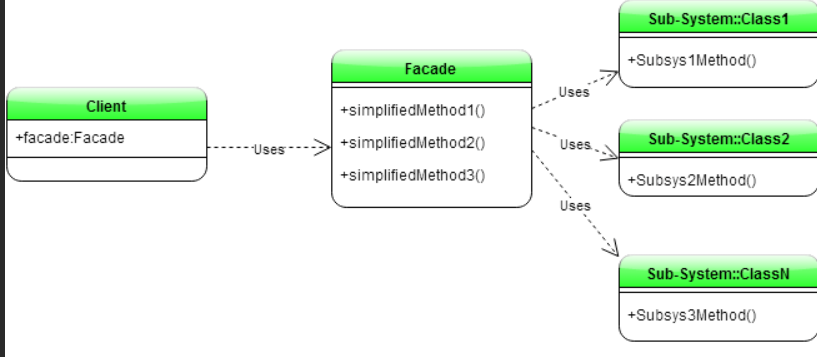
Поведенческие паттерны определяют взаимодействие между объектами, увеличивая таким образом его гибкость.:
Template Method (Шаблонный метод) - определяющий основу алгоритма и позволяющий наследникам переопределять некоторые шаги алгоритма, не изменяя его структуру в целом.
Mediator (Посредник) - предоставляет класс посредника, который обрабатывает все коммуникации между различными классами.
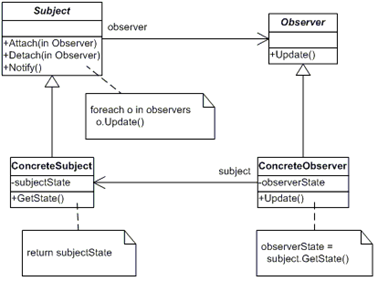
Observer (Наблюдатель) - позволяет одним обьектам следить и реагировать на события, происходящие в других объектах.
Strategy (Стратегия) - алгоритм стратегии может быть изменен во время выполнения программы.
Command (Команда) - интерфейс команды объявляет метод для выполнения определенного действия.
State (Состояние) - объект может изменять свое поведение в зависимости от его состояния.
Visitor (Посетитель) - используется для упрощения операций над группировками связанных объектов.
Interpreter (Интерпретатор) - определяет грамматику простого языка для проблемной области.
Iterator (Итератор) - последовательно осуществляет доступ к элементам объекта коллекции, не зная его основного представления.
Memento (Хранитель) - используется для хранения состояния объекта, позже это состояние можно восстановить.
Наблюдатель
4. Язык XML, назначение, синтаксис, особенности использования. Назначение, язык структура и базовые конструкции DTD и XSD схем, назначение и применение XSD схем. КСЮША
XML — расширяемый язык разметки. Важной особенностью XML также является применение так называемых пространств имён.
Язык называется расширяемым, поскольку он не фиксирует разметку, используемую в документах: разработчик волен создать разметку в соответствии с потребностями к конкретной области, будучи ограниченным лишь синтаксическими правилами языка.
Основное назначение языка XML — облегчить работу с документами в Web.
Первая строка листинга представляет собой заголовок, или так называемый пролог XML-документа. Согласно спецификации языка заголовок подчиняется следую им правилам синтаксиса:
• заголовок должен начинаться с символов <?;
• перед начальными символами заголовка не должно быть других символов;
• заголовок должен заканчиваться символами ?> ;
• после начальных символов должно стоять слово xml;
• указание версии обязательно;
• номер версии должен быть заключен в кавычки.
Помимо номера версии заголовок XML может включать в заголовок объявление кодировки документа. Например: <?xml version="1.0" encoding="UTF-8"?>.
Элемент представляет собой логические скобки, в которые помещается информация, выделенная из общего контента документа.
Сначала идет «<», затем название тега и «>»: <tag_name>
В случае закрывающего тега после открывающей скобки ставится прямой слеш (/): </tag_name>
Если элемент не содержит внутри себя никаких данных, то он называется пустым. Он записывается, как и закрывающий тег, только слеш ставится перед закрывающей скобкой: <tag_name/>
Элементы документа должны быть правильно вложены: любой элемент, начинающийся внутри другого элемента (любой, кроме корневого), должен заканчиваться внутри элемента, в котором он начался.
Объявления, инструкции обработки и элементы могут иметь связанные с ними атрибуты. Атрибуты используются для связывания с логической единицей текста пар имя-значение.
Язык схем DTD — искусственный язык, который используется для записи фактических синтаксических правил метаязыков разметки текста XML. С момента его внедрения другие языки схем для спецификаций, такие как XML Schema, выпускаются с дополнительной функциональностью.
Цель DTD состоит в определении допустимых строительных блоков XML документа.
DTD описывает схему документа для конкретного языка разметки посредством набора объявлений, которые описывают его класс (или тип) с точки зрения синтаксических ограничений этого документа. Также DTD может объявлять конструкции, которые всегда необходимы для определения структуры документа, но, зато, могут влиять на интерпретацию определенных документов.
DTD определяет структуру документа со списком допустимых элементов (!ELEMENT ) и атрибутов (!ATTLIST). “--“ - комментарии в DTD
XSD — это язык описания структуры XML документа. Его также называют XML Schema. При использовании XML Schema XML парсер может проверить не только правильность синтаксиса XML документа, но также его структуру, модель содержания и типы данных.
Основные типы элементов XSD - это определение элементов (element), их атрибутов (attribute), а также сложный тип (complexType), который описывает составные элементы и простой тип (simpleType), определяющий элементарные типы данных.
Элемент имеет простой тип (simpleType), если он не имеет атрибутов, а его содержимое (данные между открывающим и закрывающим тэгом) соответствует элементарному типу данных или просто отсутствует. Соответственно, все остальные элементы имеют сложный тип (complexType). Значения всех атрибутов также соответствуют простым типам. Для описания элемента простого типа достаточно определить его имя (атрибут name), а в качестве типа (атрибут type) указать любой простой тип данных, например строковый (string).
Сложный тип (complexType) определяет сложное содержимое (complexContent) или простое содержимое (simpleContent) элемента. Сложное содержимое – это список атрибутов и набор дочерних элементов. Простое содержимое – это также список атрибутов и простой тип содержимого элемента.
Индикаторы контролируют, каким образом элементы должны использоваться в XML документах. Всего 7 индикаторов: очерёдности (all, choice, sequence), частотности (minOccurs, maxOccurs), группирования (group name, attributeGroup name).
Индикатор <all> устанавливает, что дочерние элементы могут появляться в документах в любом порядке, и что каждый из этих дочерних элементов должен появляться всего один раз. Индикатор <choice> устанавливает, что появляться в документах может либо один дочерний элемент, либо другой.
Индикатор <sequence> устанавливает, что дочерние элементы должны появляться в документах в заданном порядке.
Чтобы разрешить использовать какой-то элемент неограниченное число раз, используется выражение maxOccurs="unbounded".
Индикатор <group name> определяет группу элементов, которые должны появляться точно в указанном порядке.
5. Семейство рекомендаций XSL (eXtensible Stylesheet Language): XSLT, XSL-FО XPath. Примеры кода преобразований. ЯНА
XSL-документ представляет собой совокупность правил построения, каждое из которых выделено в отдельный блок, ограниченный тэгами <rule> и </rule>. Правила определяют шаблоны, по которым каждому элементу XML ставится в соответствие последовательность HTML-тэгов, т.е. внутри них содержатся инструкции, определяющие элементы XML-документа и тэги форматирования, применяемые к ним.
XSLT (eXtensible Stylesheet Language for Transformations) - это язык для преобразования структуры XML документа. Язык XSLT (XSL Transformations) разработан как часть XSL.
XSLT используется для преобразования XML документа в другой XML документ или в другой тип документа, распознаваемый браузером, например, HTML и XHTML. Обычно, XSLT делает это преобразовывая каждый XML элемент в (X)HTML элемент.
Расширяемый язык стилевых таблиц (extensible Stylesheet Language, XSL) состоит из двух частей: языка для трансформации XML-документов и из XML-словаря, определяющего семантику форматирования. Стилевая таблица XSL определяет представление класса XML-документов, описывая, как представитель класса, трансформируемый в XML-документ, использует словарь форматирования.
Представление данных – это отображение их в определенном формате или среде. Т.е. Стиль оформления данных.
Трансформация данных – это представление входного документа в виде дерева узлов (в дальнейшем node), и затем преобразование входного дерева (input tree) в выходное дерево (result tree). Т.е. этот процесс можно представить, как преобразование/обмен данных.
Объявление правил относительно друг друга в файле таблицы стилей не имеет значения.
В самом общем виде это сводится к тому, что XSLT процессор принимает на входе XML документ и XSLT таблицу стилей – как данные на входе и код, который надо применить к этим данным и после этого начинает применять шаблонные правила (template rules) для получения нужных данных на выходе. Задача XSL процессора – получение из исходных документов их представление в виде деревьев с вершинами элементов и атрибутов. Задача XSLT процессора работа с этими представлениями деревьями. XSLT используется как замена разметки XML разметкой HTML. Также используется для сортировки содержания элементов. Таблицы преобразуются в графический вид.
XSL-FO(eXtensible Stylesheet Language Formatting Objects - объекты форматирования языка таблиц стилей для XML) – рекомендованный Консорциумом Всемирной паутины язык разметки типографских макетов и иных предпечатных материалов. XSL-FO является частью XSL, наряду с XSLT и XPath. XSL-FO — это унифицированный язык представления. Он не имеет семантической разметки в том смысле, в каком она используется в HTML. В отличие от CSS, который модифицирует представление по умолчанию для внешнего HTML или XML-документа, XSL-FO сохраняет все данные документа внутри себя. Документ XSL-FO — это XML файл, в котором хранятся данные для печати или вывода на экран (например, просто текст). Эти данные находятся внутри тегов fo:block, fo:table, fo:simple-page-master и др., где указаны отступы, переводы строк и т.д.
XPath (XML Path Language) — язык запросов к элементам XML-документа. Разработан для организации доступа к частям документа XML в файлах трансформации XSLT и является стандартом консорциума W3C. XPath призван реализовать навигацию по DOM в XML.
Два основных подходах к обработке XML документов: DOM и SAX.
6. Язык XPath, назначение, синтаксис и применение языка. Выражения и предикаты языка. Определение пути, абсолютный и относительный путь, Оси понятие и примеры использование. САША
XPath — используется для произвольного выбора узлов из документов XML.
XPath — язык запросов к элементам XML-документа. Разработан для организации доступа к частям документа XML в файлах трансформации XSLT и является стандартом консорциума W3C. XPath призван реализовать навигацию по DOM в XML. В XPath используется компактный синтаксис, отличный от принятого в XML.
Для реализации этой первоочередной цели он также предоставляет основные средства оперирования строками, числами и логическими значениями. XPath обладает компактным, отличным от XML синтаксисом для облегчения его применения в идентификаторах URI и значениях атрибутов XML. XPath работает с абстрактной, логической структурой XML-документа, а не с его внешним синтаксисом. XPath получил свое имя благодаря тому, что для навигации по иерархической структуре XML-документа в нем используется нотация пути (path), как в идентификаторах URL.
<?xml-stylesheet type="text/xsl" href="example.xsl"?>
<Article>
<Title>My Article</Title>
<Authors>
<Author>Mr. Foo</Author>
<Author>Mr. Bar</Author>
</Authors>
<Body>This is my article text.</Body>
</Article>
Predicate – это функциональный интерфейс. Это означает, что мы можем передавать лямбда-выражения везде, где ожидается предикат. Например, одним из таких методов является метод filter() из интерфейса Stream.
Мы можем принять поток в качестве механизма для создания последовательности элементов, поддерживающих последовательные и параллельные агрегатные операции. Это означает, что можем в любое время собрать и выполнить некоторые операции всех элементов, присутствующих в потоке, за один вызов.
Путь (англ. path) — набор символов, показывающий расположение файла или каталога в файловой системе.
Технически Path — это не класс, а интерфейс. Так сделано для того, чтобы можно было под каждую операционную (и файловую) систему писать свой класс-наследник Path.
Пути бывают двух типов: абсолютные и относительные. Абсолютный путь начинается с корневой директории. Для Windows это может быть папка c:\, для Linux — директория /.
Относительный путь считается относительно какой-то директории. Т.е. это как бы конец пути, но только без начала. Относительный путь можно превратить в абсолютный и наоборот. Метод boolean isAbsolute() проверяет, является ли текущий путь абсолютным.
7. Обработки XML документов, DOM и SAX модели, преимущества и недостатки моделей. Примере представлений и обработки файлов. НАСТЯ
Два основных подходах к обработке XML документов: DOM и SAX.
DOM (Document Object Model) – это технология, основанная на формировании в оперативной памяти иерархических структур данных, соответствующих всему XML документу. DOM, как следует из самой аббревиатуры - это построение объектной модели документа (все элементы и их атрибуты представляются в памяти отдельными объектами). Является древовидной моделью. Данные не могут использоваться, пока не будет разобран весь документ. Состоит из узлов.
Согласно DOM:
· все, что содержится внутри XML документа, является узлом;
· весь документ представляется узлом документа;
· каждый XML элемент – узел элемента;
· текст внутри XML элементов - текстовый узел;
· каждый атрибут - узел атрибута;
· комментарии - узлы комментариев.
Преимущества XML DOM:
· Простота. Все узлы XML документа доступны сразу. Легко выполнять поиск узлов с использованием XPath.
· Можно добавлять, удалять, перемещать узлы, выполнять прочие операции редактирования, будучи уверенным, что результатом будет well-formed XML документ.
Когда нужно применять XML DOM:
· Вы используете XML для хранения кэша данных.
· Объемы документов XML, с которыми вы имеете дело, невелики. Вам важна прозрачность и наглядность программного кода формирования XML документов.
· Вам необходимо сформировать отчет небольших размеров с последующей его XSL-трансформацией в оперативной памяти.
DOM-обработчик устроен так, что он считывает сразу весь XML и сохраняет его, создавая иерархию в виде дерева, по которой мы можем спокойно двигаться и получать доступ к нужным нам элементам. Таким образом, мы можем, имея ссылку на верхний элемент, получить все ссылки на его внутренние элементы. В DOM есть множество интерфейсов, которые созданы, чтобы описывать разные данные. Все эти интерфейсы наследуют один общий интерфейс – Node (узел). У каждого Node есть следующие полезные методы для извлечения информации:
getNodeName – получить имя узла.
getNodeValue – получить значение узла.
getNodeType – получить тип узла.
getParentNode – получить узел, внутри которого находится данный узел.
getChildNodes – получить все производные узлы (узлы, которые внутри данного узла).
getAttributes – получить все атрибуты узла.
getOwnerDocument – получить документ этого узла.
getFirstChild/getLastChild – получить первый/последний производный узел.
getLocalName – полезно при обработка пространств имён, чтобы получить имя без префикса.
getTextContent – возвращает весь текст внутри элемента и всех элементов внутри данного элемента, включая переносы строчек и пробелы.
DocumentBuilderFactory. Рассмотрим методы фабрики:
· newInstance() — создает фабрику. Этот метод является статическим;
· setNamespaceAware(f) — включает или выключает поддержку пространств имен;
· newDocumentBuilder() — создает новый построитель. В случае ошибки выбрасывает исключение ParserConfigurationException.
Построитель представлен абстрактным классом DocumentBuilder. Рассмотрим методы построителя:
· parse(s) — разбирает текст XML-документа и создает в процессе этого разбора объект документа.
· newDocument() — создает пустой объект документа.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setNamespaceAware(true);
factory.setIgnoringComments(true);
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse("file://c:/data/test.xml");
SAX (Simple API for XML) - прикладной программный интерфейс для парсера с последовательным доступом к XML. Этот интерфейс предоставляет механизм чтения данных из XML документа.
SAX-обработчик устроен так, что он просто считывает последовательно XML файлы и реагирует на разные события, после чего передает информацию специальному обработчику событий.
SAX-парсер является поточным и управляемым событиями. Задачей пользователя SAX API заключается в описании методов, вызываемых событиями, возникающими при анализе документа.
Такими событиями могут быть следующие:
· текстовый узел;
· узел элемента XML;
· инструкция обработки XML;
· комментарий XML.
startDocument - начало документа endDocument - конец документа
startElement - открытие элемента endElement - закрытие элемента
characters - текстовая информация внутри элементов.
Анализ документа является однонаправленным (т.е. без возвратов по дереву).
+ Затраты памяти существенно меньше (зависит от максимальной глубины дерева документа и количества атрибутов в узле элемента), чем в случае DOM (требуется хранить в памяти все дерево документа).
+ Скорость работы выше за счет сокращения затрат времени на выделение памяти для элементов дерева в случае DOM.
+ Потоковое чтение данных с диска в случае DOM невозможно. Если для размещения всего документа в памяти недостаточно места, то использование SAX является безальтернативным.
- Процедура проверки правильности предполагает доступ ко всему документу одновременно.
- Это также требуется и в случае XSLT преобразования
SAXParserFactory. Рассмотрим методы фабрики:
·newInstance() — создает фабрику. Этот метод является статическим;
·setNamespaceAware(f) — аналогичен одноименному методу фабрики построителей;
·newSAXParser() — создает новый разборщик. В случае ошибки выбрасывает исключение ParserConfigurationException.
Разборщик представлен абстрактным классом SAXParser. Рассмотрим методы разборщика:
·parse(s, h) — разбирает текст XML-документа, вызывая в процессе разбора обработчик h.
SAXParserFactory factory = SAXParserFactory.newInstance();
factory.setNamespaceAware(true);
SAXParser parser = factory.newSAXParser();
parser.parse("file://c:/data/test.xml", myHandler);
8. Совместная разработка проектов, Системы контроля версий (скв). Непрерывная интеграция - Continuous Integration (ci) Методы, средства, инструменты и механизмы разработки и сборки проектов. Полина
Для совместной разработки программных проектов используются системы версионного контроля (subversion. git). Системы контроля версий (СКВ) — это система, регистрирующая изменения в одном или нескольких файлах с тем, чтобы в дальнейшем была возможность вернуться к определённым старым версиям этих файлов. Системы контроля версий можно разделить на 3 группы: локальные, централизованные, распределенные. Инструменты для сборки проектов (ant, maven).
Одной из наиболее популярных СКВ локального типа является RCS (Revision Control System, Система контроля ревизий). Система позволяет хранить версии только одного файла, таким образом управлять несколькими файлами приходится вручную. Основные недостатки: работа только с одним файлом, каждый файл должен контролироваться отдельно; неудобный механизм одновременной работы нескольких пользователей с системой, хранилище просто блокируется, пока заблокировавший его пользователь не разблокирует его; риск потерять все данные.
ЦСКВ (централизованная СКВ) представляют собой приложения типа клиент-сервер, когда репозиторий проекта существует в единственном экземпляре и хранится на сервере. Доступ к нему осуществлялся через специальное клиентское приложение. Такой подход имеет ряд преимуществ, особенно над локальными СКВ - все знают, кто и чем занимается в проекте, администрировать ЦСКВ намного легче, чем локальные базы на каждом клиенте. Один из важнейших недостатков — централизованный сервер является уязвимым местом всей системы, так как, если на этом сервере пропадут все данные и не будет резервных копий, то все, кто работал с этим проектом, потеряют все файлы.
В случае распределенных систем набор версий может быть полностью, или частично распределен между различными хранилищами, в том числе и удаленными. Распределенные системы контроля версий (Distributed Version Control System, DVCS) позволяют хранить репозиторий (его копию) у каждого разработчика, работающего с данной системой. При этом можно выделить центральный репозиторий (условно), в который будут отправляться изменения из локальных и, с ним же эти локальные репозитории будут синхронизироваться. При работе с такой системой, пользователи периодически синхронизируют свои локальные репозитории с центральным и работают непосредственно со своей локальной копией. После внесения достаточного количества изменений в локальную копию они (изменения) отправляются на сервер. При этом сервер, чаще всего, выбирается условно.
Для распределенных систем контроля версий ветки разработки являются одной из основополагающих концепций — в большинстве случаев каждая копия хранилища версий является веткой разработки.
Непрерывная интеграция (Continuous Integration) — это практика разработки программного обеспечения, которая заключается в выполнении частых автоматизированных сборок проекта для скорейшего выявления и решения интеграционных проблем. С практической точки зрения это значит, что в любой момент времени у вас должна быть «живая актуальная версия продукта», которую можно протестировать или продемонстрировать. В обычном проекте, где над разными частями системы разработчики трудятся независимо, стадия интеграции является заключительной. Она может непредсказуемо задержать окончание работ. Переход к непрерывной интеграции позволяет снизить трудоемкость интеграции и сделать её более предсказуемой за счет наиболее раннего обнаружения и устранения ошибок и противоречий, но основным преимуществом является сокращение стоимости исправления дефекта, за счёт раннего его выявления. Непрерывная интеграция является одним из основных приёмов экстремального программирования.
При непрерывной интеграции построение проекта должно выполняться с наименьшим допустимым интервалом. Этим интервалом чаще всего берут время между двумя соседними коммитами в систему контроля версий, т.е. построение проекта проходит после каждого коммита. Это позволяет найти те ошибки и проблемы, на которые разработчик не обратил внимания при локальном запуске. Чаще всего проявляются ошибки компиляции или сломанные тесты.
Преимущества непрерывной интеграции:
Повышение уверенности – после сотни успешных построений легче быть уверенным в успешности 101-го построения.
Экономия времени за счет автоматизации повторяемых действий.
Развертываемость программного обеспечения – использование подхода непрерывной интеграции позволяет осуществить полное построение проекта с развертыванием, если иметь на входе папку с исходниками и нажать лишь одну кнопку.
9. RMI и RPC. Основные отличия RMI от RPC. Интерфейсы и классы и механизма RMI. Архитектура и конфигурирование RMI. Пример реализации клиентского кода RMI на JAVA. ЛИЗА
RMI-технология позволяет выполнять прозрачный запуск методов объектов Java, которые расположены на удаленных машинах, таким образом, как если бы они располагались на локальных машинах. RMI – позволяет строить приложения, работа которых распределена между несколькими машинами в архитектуре клиент-сервер.
Интерфейсы: основа RMI. На основе использования интерфейсов было достигнуто разделения описания поведения (интерфейс) и реализации этого поведения(классы). Такое разделение соответствует принятой практике, в которой клиенты знают об определениях служб, а серверы предоставляют эти службы. В RMI интерфейсы определяют поведение, а классы – реализацию.
RMI поддерживает два класса, реализующих один и тот же интерфейс: первый реализует поведения и исполняется на сервере, второй класс работает как промежуточный интерфейс для удаленной службы и исполняется на клиентской машине.
Отличия от RPC:
RPC основан на C, и он имеет структурированную семантику программирования, с другой стороны, RMI - это технология на основе Java и объектно-ориентированная.
С RPC вы можете просто вызывать удаленные функции, экспортируемые на сервер, в RMI вы можете иметь ссылки на удаленные объекты и вызывать их методы, а также передавать и возвращать более удаленные ссылки на объекты, которые могут быть распределены между многими экземплярами JVM, поэтому гораздо более мощный.
Уровни архитектуры RMI:
первый - уровень заглушки и скелета, обслуживающий пользователя. Этот уровень перехватывает вызовы методов, произведенные клиентом при помощи переменной - ссылки на интерфейс, и переадресует их в удаленную службу RMI. используется пользователем. Скелет понимает, как взаимодействовать с заглушкой при RMI-соединении.
второй – уровень удаленной ссылки. Предоставляет объект RemoteRef , который обеспечивает соединение с объектами, реализующими удаленные службы.
третий - Транспортный уровень, основанный на соединениях TCP/IP между сетевыми машинами. Он обеспечивает основные возможности соединения и некоторые стратегии защиты от несанкционированного доступа. Суть: При вызове метода удаленного объекта на самом деле вызывается обычный метод языка Java, инкапсулированный в специальном объекте-заглушке (stub), который является представителем серверного объекта. Заглушка находится на клиентском компьютере, а не на сервере. Она упаковывает параметры удаленного метода в блок байтов.
Пример реализации клиентского кода
public interface Calculator extends Remote {
int multiply(int x, int y) throws RemoteException;
}
Теперь нам надо создать класс-сервер, который будет реализовывать наш интерфейс Calculator.
public class RemoteCalculationServer implements Calculator {
@Override
public int multiply(int x, int y) throws RemoteException {
return x*y;
}}
public class ClientMain {
public static final String NAME = "server.calculator";
public static void main(String[] args) throws RemoteException, NotBoundException {
final Registry registry = LocateRegistry.getRegistry(2732);//получаем доступ к регистру удаленных объектов
Calculator calculator = (Calculator) registry.lookup(NAME);//получаем из регистра нужный объект(приводим полученный объект к интерфейсу Calculator,а не к конкретному классу)
int multiplyResult = calculator.multiply(20, 30);// удаленно вызываем метод multiply()
System.out.println(multiplyResult); }}
10. Этапы (шаги) разработки RMI приложений. Соглашения о передаче данных. Пример реализации серверного кода на JAVA. КСЮША
1. Удаленный интерфейс должен быть public . В противном случае клиенты будут получать ошибку при попытке загрузки объекта, реализующего удаленный интерфейс.
2. Удаленный интерфейс должен расширять интерфейс java.rmi.Remote. Каждый метод удаленного интерфейса должен объявлять java.rmi.RemoteException в своем предложении throws вдобавок к любым другим исключениям.
public interface IAddServer extends Remote {
double add (double d1, double d2) throws RemoteException;}
3. Серверный модуль, реализующий задачу клиента. Все удаленные классы должны расширять класс UnicastRemoteObject.:
public class AddServerImpl extends UnicastRemoteObject implements IAddServer {
public AddServerImpl throws RemoteException{ }
public double add(double d1, double d2) throws RemoteException {return d1+d2;}}
4. Консольная main программа сервера, которая должна обновить RMI-реестр на машине-сервере при помощи метода rebind класса Naming, пакета java.rmi.. Он связывает имя сервера с объектной ссылкой.
public class AddServer{
public static void main(String args[]){
try {
AddServerImpl addServerImpl=new AddServerImpl();
Naming.rebind(AddServer, addServerImpl);}
catch Exception e {
System.out.println(Exception: +e);}}}
4. Клиент. IP - адрес 1-й параметр или имя сервера и аргументы для инициализации входных параметров метода, выполняющегося на сервере второй и третий параметр, задаваемый через пробел, передаются в командной строке.
11. Реестр RMI, регистрация службы RMI. Организация доступа и вызова удаленных метод в RMI. Пример реализация цепочки операций для доступа к удаленным методам в коде JAVA. ЯНА
RMI-технология позволяет выполнять прозрачный запуск методов объектов Java, которые расположены на удаленных машинах, таким образом, как если бы они располагались на локальных машинах. RMI – позволяет строить приложения, работа которых распределена между несколькими машинами в архитектуре клиент-сервер.
RMI включает в себя простую службу, называемую реестром RMI, rmiregistry. Реестр RMI работает на каждой машине, содержащей объекты удаленных служб и принимающей запросы на обслуживание, по умолчанию используя порт 1099. На хосте программа сервера создает удаленную службу, предварительно создавая локальный объект, реализующий эту службу. Затем она экспортирует этот объект в RMI. Как только объект экспортирован, RMI создает службу прослушивания, ожидающую соединения с клиентом и запроса службы. После экспорта, сервер регистрирует объект в реестре RMI, используя общедоступное имя. На стороне клиента к реестру RMI доступ обеспечивается через статический класс Naming. Он предоставляет метод lookup(), который клиент использует для запросов к реестру. Метод lookup() принимает URL, указывающий на имя хоста и имя требуемой службы. Метод возвращает удаленную ссылку на обслуживающий объект. URL принимает следующий вид: rmi://<host_name> [:<name_service_port>] /<service_name>
где host_name - это имя, распознаваемое в локальной сети (LAN), или DNS-имя в сети Internet.
Для организации службы необходимо только указать name_service_port (1099 по умолчанию).
public class PrimeNumbersSearchServer implements ClientRegister {
public static void main(String[] args) {
PrimeNumbersSearchServer server = new PrimeNumbersSearchServer();
try { ClientRegister stub = (ClientRegister)UnicastRemoteObject.exportObject(server, 0);
Registry registry = LocateRegistry.createRegistry(12345);
registry.bind("ClientRegister", stub);
server.startSearch();
} catch (Exception e) {
System.out.println ("Error occured: " + e.getMessage());}}}
public class PrimeNumbersSearchClient implements PrimeChecker {
public static void main(String[] args) {
PrimeNumbersSearchClient client = new PrimeNumbersSearchClient();
try {
Registry registry = LocateRegistry.getRegistry(null, 12345);
ClientRegister server = (ClientRegister)registry.lookup("ClientRegister");
PrimeChecker stub = (PrimeChecker)UnicastRemoteObject.exportObject(client, 0);
server.register(stub);
} catch (Exception e) {
System.out.println ("Error occured: " + e.getMessage());}}}