

Основы администрирования Linux и Apache. Рындин Н.А., Амоа К.А
.pdfПримеры использования shar для того чтобы заархивировать папку linux:
Создаем shar архив:
shar file_name.extension > filename.shar
Распаковываем shar архив:
./filename.shar AR
ar — утилита для создания и управления архивами. В основном используется для архивации статических библиотек, но может быть использована для создания любых архивов. Раньше использовалась довольно часто но была вытеснена утилитой tar. Сейчас используется только для создания и обновления файлов статических библиотек.
Опции Ar:
▪— d — удалить модули из архива
▪— m — перемещение членов в архиве
▪— p — напечатать специфические члены архива
▪— q — быстрое добавление
▪— r — добавить члена к архиву
▪— s — создать индекс архива
▪— a — добавить новый файл к существующему архиву Теперь рассмотрим примеры использования. Создадим
статическую библиотеку libmath.a из объектных файлов substraction.o и division.o:
ar cr libmath.a substraction.o division.o
Теперь извлечем файлы из архива: ar x libmath.a
Таким образом, можно распаковать любую статическую библиотеку.
CPIO
cpio — означает Copy in and out (скопировать ввод и вывод). Это еще один стандартный архиватор для Linux. Активно используется в менеджере пакетов Red Hat, а также для создания initramfs. Архивация в Linux для обычных файлов с помощью этой программы не применяется.
151
Опции утилиты:
▪-a — сбросить время обращения к файлам после их копирования
▪-A — добавить файл
▪-d — создать каталоги при необходимости
Пример использования. Создаем cpio архив: ls
file1.o file2.o file3.o
ls | cpio -ov > /path/to/output_folder/obj.cpio
Распаковываем архив:
cpio -idv < /path/to folder/obj.cpio
Архивирование папки linux выполняется также само. СЖАТИЕ АРХИВОВ В LINUX
Как создать архив в linux рассмотрели. Теперь давайте поговорим о сжатии. Как я говорил, для сжатия используются специальные утилиты. Рассмотрим кратко несколько из них
GZIP
Чаще всего применяется Gzip. Это стандартная утилита сжатия в Unix/Linux. Для декомпрессии используется gunzip или gzip -d Сначала рассмотрим ее синтаксис:
$ gzip опции файл $ gunzip опции файл
Теперь разберем опции:
▪-c — выводить архив в стандартный вывод
▪-d — распаковать
▪-f — принудительно распаковывать или сжимать
▪-l — показать информацию об архиве
▪-r — рекурсивно перебирать каталоги
▪-0 — минимальный уровень сжатия
▪-9 — максимальный уровень сжатия
Примеры использования вы уже видели в описании утилиты tar. Например, выполним сжатие файла:
gzip -c файл > архив.gz
А теперь распакуем: gunzip -c архив.gz
152
Но чтобы сжать папку в Linux вам придется сначала заархивировать ее с помощью tar, а уже потом сжать файл архива с помощью gzip.
BZIP
bzip2 — еще одна альтернативная утилита сжатия для Linux. Она более эффективная чем gzip, но работает медленнее. Для распаковки используйте утилиту bunzip2.
Описывать опции bzip2 я не буду, они аналогичны gzip. Чтобы создать архив в Linux используйте:
bzip2 file
В текущем каталоге будет создан файл file.bz2 LZMA
Новый и высокоэффективный алгоритм сжатия. Синтаксис и опции тоже похожи на Gzip. Для распаковки используйте unlzma.
XZ
Еще один высокоэффективный алгоритм сжатия. Обратно совместимый с Lzma. Параметры вызова тоже похожи на Gzip.
ZIP
Кроссплатформенная утилита для создания сжатых архивов формата zip. Совместимая с Windows реализациями этого алгоритма. Zip архивы очень часто используются для обмена файлами в интернете. С помощью этой утилиты можно сжимать как файлы, так и сжать папку linux.
Синтаксис утилиты: $ zip опции файлы $ unzip опции архив Опции утилиты:
▪-d удалить файл из архива
▪-r — рекурсивно обходить каталоги
▪-0 — только архивировать, без сжатия
▪-9 — наилучший степень сжатия
▪-F — исправить zip файл
▪-e — шифровать файлы
153
Чтобы создать Zip архив в Linux используйте: zip -r /path/to/files/*
А для распаковки: unzip archive.zip
Как видите архивирование zip в Linux не сильно отличается от других форматов.
10.5.Контрольные вопросы
1.Резервное копирование. Основные сведения.
2.Резервное копирование, инициируемое
клиентом.
3.Резервное копирование, инициируемое
сервером.
4.Использование утилиты tar.
5.Возможности утилиты tar. Основные команды.
6.Синхронизация и передачи файлов.
7.Устройство DRBD
154
11.ВЕБ-СЕРВЕР APACHE
Понятие Веб-сервер может относится как к железу, так и
кпрограммному обеспечению (ПО).
Сточки зрения железа, Веб-сервер - это компьютер который хранит ресурсы сайта (HTML документы, CSS стили, JavaScript файлы и другое) и доставляет их на устройство конечного пользователя (веб-браузер и т.д.). Обычно подключен к сети Интернет и может быть доступен через, доменное имя, например mozilla.org.
Сточки зрения ПО, Веб-сервер включает в себя некоторые вещи, которые контролируют доступ Вебпользователей к размещенным на сервере файлам, это минимум HTTP сервера. HTTP сервер это часть ПО которая понимает URL’ы (веб-адреса) и HTTP (протокол который использует ваш браузер для просмотра веб-станиц).
Простыми словами, когда браузеру нужен файл, размещенный на веб-сервере, браузер запрашивает его через HTTP. Когда запрос достигает нужного веб-сервера (железо), сервер HTTP (ПО) передает запрашиваемый документ обратно, также через HTTP.
Чтобы опубликовать веб-сайт, нужно либо статический, либо динамический веб-сервер.
Статический веб-сервер, или стек, состоит из компьютера (железо) с сервером HTTP (ПО). Мы называем это «статикой», потому что сервер посылает размещенные на нем файлы в браузер «как есть».
Динамических веб-сервер состоит из статического вебсервера плюс дополнительного программного обеспечения, наиболее часто сервером приложений и базы данных. Мы называем его «динамический», потому что сервер приложений изменяет исходные файлы перед отправкой в ваш браузер по HTTP.
Например, для получения итоговой страницы, которую вы видите в браузере, сервер приложений может заполнить
155
HTML шаблон данными из базы данных. Такие сайты, как
MDN (Mozilla Developer Network) или Википедия состоят из тысяч веб-страниц, но они не являются реальными HTML документами, лишь несколько HTML шаблонов и гигантские базы данных. Эта структура упрощает и ускоряет сопровождение веб-приложений и доставку контента.
Чтобы загрузить веб-страницу, как мы уже говорили, ваш браузер отправляет запрос к веб-серверу, который приступает к поиску запрашиваемого файла в своем собственном пространстве памяти. Найдя файл, сервер считывает его, обрабатывает как ему это необходимо, и направляет его в браузер. Давайте посмотрим на эти шаги более подробно.
Во-первых, веб-сервер хранит файлы веб-сайта, а именно все HTML документы и связанные с ними ресурсы, включая изображения, CSS стили, JavaScript файлы, шрифты и видео.
Технически, вы можете разместить все эти файлы на своем компьютере, но гораздо удобнее хранить их на выделенном веб-сервере, который: всегда запущен и работает, постоянно в сети Интернет, имеет то же IP адрес все время (не все провайдеры предоставляют статический IP адрес для домашнего подключения), обслуживается на стороне.
По всем этим причинам, поиск хорошего хостингпровайдера является ключевой частью создания вашего сайта. Рассмотрите различные предложения компаний и выберите то, что соответствует вашим потребностям и бюджету (предложения варьируются от бесплатных до тысяч долларов
вмесяц).
11.1.Мультипроцессорные модели
На протяжении всей истории развития вычислительной техники делались попытки найти какую-то общую классификацию, под которую подпадали бы все возможные
156
направления развития компьютерных архитектур. Ни одна из таких классификаций не могла охватить все разнообразие разрабатываемых архитектурных решений и не выдерживала испытания временем. Тем не менее в научный оборот попали и широко используются ряд терминов, которые полезно знать не только разработчикам, но и пользователям компьютеров.
Любая вычислительная система (будь то супер-ЭВМ или персональный компьютер) достигает своей наивысшей производительности благодаря использованию высокоскоростных элементов и параллельному выполнению большого числа операций. Именно возможность параллельной работы различных устройств системы (работы с перекрытием) является основой ускорения основных операций.
Параллельные ЭВМ часто подразделяются по классификации Флинна на машины типа SIMD (Single Instruction Multiple Data - с одним потоком команд при множественном потоке данных) и MIMD (Multiple Instruction Multiple Data - с множественным потоком команд при множественном потоке данных). Как и любая другая, приведенная выше классификация несовершенна: существуют машины прямо в нее не попадающие, имеются также важные признаки, которые в этой классификации не учтены. В частности, к машинам типа SIMD часто относят векторные процессоры, хотя их высокая производительность зависит от другой формы параллелизма - конвейерной организации машины. Многопроцессорные векторные системы, типа Cray Y-MP, состоят из нескольких векторных процессоров и поэтому могут быть названы MSIMD (Multiple SIMD).
Одной из отличительных особенностей многопроцессорной вычислительной системы является сеть обмена, с помощью которой процессоры соединяются друг с другом или с памятью. Модель обмена настолько важна для многопроцессорной системы, что многие характеристики производительности и другие оценки выражаются отношением времени обработки к времени обмена,
157
соответствующим решаемым задачам. Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, другая - на использовании общей памяти. В многопроцессорной системе с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти. Чтобы обеспечить согласованность данных и синхронизацию процессов, обмен часто реализуется по принципу взаимно исключающего доступа к общей памяти методом "почтового ящика".
Вархитектурах с локальной памятью непосредственное разделение памяти невозможно. Вместо этого процессоры получают доступ к совместно используемым данным посредством передачи сообщений по сети обмена. Эффективность схемы коммуникаций зависит от протоколов обмена, основных сетей обмена и пропускной способности памяти и каналов обмена.
Часто, и притом необосновано, в машинах с общей памятью и векторных машинах затраты на обмен не учитываются, так как проблемы обмена в значительной степени скрыты от программиста. Однако накладные расходы на обмен в этих машинах имеются и определяются конфликтами шин, памяти и процессоров. Чем больше процессоров добавляется в систему, тем больше процессов соперничают при использовании одних и тех же данных и шины, что приводит к состоянию насыщения. Модель системы с общей памятью очень удобна для программирования и иногда рассматривается как высокоуровневое средство оценки влияния обмена на работу системы, даже если основная система в действительности реализована с применением локальной памяти и принципа передачи сообщений.
Всетях с коммутацией каналов и в сетях с коммутацией пакетов по мере возрастания требований к обмену следует учитывать возможность перегрузки сети. Здесь
158
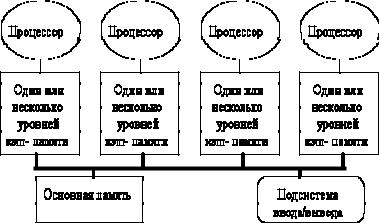
межпроцессорный обмен связывает сетевые ресурсы: каналы, процессоры, буферы сообщений. Объем передаваемой информации может быть сокращен за счет тщательной функциональной декомпозиции задачи и тщательного диспетчирования выполняемых функций.
Рис. 11.1. Типовая архитектура мультипроцессорной системы с общей памятью
HTTP-сервер Apache был разработан как мощный и гибкий веб-сервер, который может работать на самых разных платформах и в рамках различного окружения. Различные платформы и окружения часто требуют и различных возможностей или могут предоставлять различные пути реализации одной и той же возможности наиболее эффективно. Apache всегда мог работать в различных средах окружения за счёт своей модульной архитектуры, позволяющей вебмастеру выбрать всю необходимую функциональность, которая будет реализовываться сервером после компиляции, при помощи компилируемых или подключаемых модулей.
159
В Apache 2.0 модульная архитектура была расширена наиболее общими функциями веб-сервера. Теперь сервер поставляется с набором мульти-процессных модулей (МПмодулей), ответственных за соединение с сетевыми портами компьютера, за приём запросов и за координацию их обработки дочерними процессами.
Расширение модульной архитектуры до этого уровня даёт два важных преимущества:
Apache может более аккуратно и эффективно работать в самых разных операционных системах. В частности, версия Apache для Windows теперь работает намного более эффективно, благодаря тому, что МП-модуль mpm_winnt может использовать собственные сетевые функции Windows взамен сетевых функций уровня POSIX. Это касается и других операционных систем, для которых разработаны специальные МП-модули.
Сервер может быть настрен более оптимально для нужд конкретного сайта. Например, для сайтов, требующих значительной масштабируемости, может быть выбран многопоточный МП-модуль, такой как worker, а для сайтов, требующих большей стабильности или совместимости со старым ПО, может быть использован prefork. Кроме того, также предоставляются специальные возможности, такие как обслуживание различных хостов процессамми с привилегиями различных пользователей (perchild).
На уровне пользователя МП-модули почти не отличаются от всех остальных модулей Apache. Основное различие состоит в том, что с сервером может быть скомпилирован один и только один МП-модуль. Список доступных МП-модулей можно посмотреть в каталоге модулей.
160