

Учебное пособие 835
.pdfязыков, принимаемых недетерминированной машиной Тьюринга, заканчивающими свою работу за время, не превосходящее f(n). Отметим, что ограничения на память при определении данных классов отсутствуют.
Аналогично иерархии по времени вводится иерархия по памяти. Класс DSPACE(f(n)) обозначает класс языков, принимаемых детерминированными машинами Тьюринга, использующих не более f(n) ячеек памяти на рабочих лентах. Класс NSPACE(f(n)) определяют, как класс языков, принимаемых недетерминированными машинами Тьюринга, использующих не более f(n) ячеек памяти на рабочих лентах. Временные ограничения при определении данных классов отсутствуют.
Аналогично определяются и другие подобные рассмотренным выше классы. Приведем использующиеся сокращения:
D – детерминированный (детерминистический); N – недетерминированный;
R – вероятностный с ограниченной односторонней ошибкой;
B – вероятностный с ограниченной двусторонней ошибкой;
BQ – квантовый с ограниченной двусторонней ошиб-
кой.
1.4. О-сложность алгоритмов
 Большинство операций в программе выполняются
Большинство операций в программе выполняются
только раз или только несколько раз. Алгоритмами константной сложности. Любой алгоритм, всегда требующий независимо от размера данных одного и того же времени, имеет константную сложность [1].
 Время работы программы линейно обычно когда
Время работы программы линейно обычно когда
каждый элемент входных данных требуется обработать лишь линейное число раз.
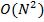 ,
, 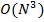 ,
,  Полиномиальная сложность. О(N2)-квадратичная сложность, О(N3)- кубическая сложность.
Полиномиальная сложность. О(N2)-квадратичная сложность, О(N3)- кубическая сложность.
9
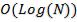 Когда время работы программы логарифми-
Когда время работы программы логарифми-
ческое, программа начинает работать намного медленнее с увеличением N. Такое время работы встречается обычно в программах, которые делят большую проблему в маленькие и решают их по отдельности.
 Такое время работы имеют те алгорит-
Такое время работы имеют те алгорит-
мы, которые делят большую проблему в маленькие, а затем, решив их, соединяют их решения.
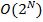 Экспоненциальная сложность. Такие алгоритмы
Экспоненциальная сложность. Такие алгоритмы
чаще всего возникают в результате подхода, именуемого метод грубой силы.
Вид управляющей структуры |
Сложность |
Присваивание |
О(1) |
Простое выражение |
О(1) |
S1 |
доминанта для О(Выч1) и |
S2 |
О(Выч2) |
If Условие THEN |
доминанта для |
S1 |
О(Выч1) и О(Выч2) и |
ELSE |
О(ВычУслов) |
S2 |
(*это наихудший случай*) |
FOR l:=1 TO N DO |
О(N*Выч1) |
S1 |
|
END |
|
Замечание: О(Выч1) и О(Выч2) и О(ВычУслов) обозначают Соответственно сложность вычислений для S1, S2 и для Условие.
Алгоритмы без циклов и рекурсивных вызовов имеют константную сложность. Если нет рекурсии и циклов, все управляющие структуры могут быть сведены к структурам константной сложности. Следовательно, и весь алгоритм также характеризуется константной сложностью. Определение сложности алгоритма в основном сводится к анализу циклов и рекурсивных вызовов [4].
10
Например, рассмотрим алгоритм обработки элементов массива.
For i:=1 to N do Begin
...
End;
Сложность этого алгоритма O(N), т.к. тело цикла выполняется N раз, и сложность тела цикла равна O(1).
Если один цикл вложен в другой и оба цикла зависят от размера одной и той же переменной, то вся конструкция характеризуется квадратичной сложностью.
For i:=1 to N do For j:=1 to N do Begin
...
End;
Сложность этой программы О(N2).
Давайте оценим сложность программы «Тройки Пифагора». Существуют два способа анализа сложности алгоритма: восходящий (от внутренних управляющих структур к внешним) и нисходящий (от внешних и внутренним).
11

О(Н) = О(1)+О(1)+О(1)=О(1);
O(I) = O(N)*(O(F)+O(J)) =
= O(N)*O(доминанты условия) = O(N);
O(G) = O(N)*(O(C)+O(I)+O(K)) = = O(N)*(O(1)+O(N)+O(1)) = O(N2);
O(E) = O(N)*(O(B)+O(G)+O(L)) = O(N)*O(N2) = O(N3);
O(D) = O(A)+O(E) = O(1)+ O(N3) = O(N3).
Сложность данного алгоритма O(N3).
Существуют два способа анализа сложности алгоритма: восходящий (от внутренних управляющих структур к внешним) и нисходящий (от внешних и внутренним).
12
Как правило, около 90% времени работы программы требует выполнение повторений и только 10% составляют непосредственно вычисления. Анализ сложности программ показывает, на какие фрагменты выпадают эти 90% -это циклы наибольшей глубины вложенности. Повторения могут быть организованы в виде вложенных циклов или вложенной рекурсии.
Суть алгоритма: идем к середине массива и ищем соответствие ключа значению срединного элемента. Если нам не удается найти соответствия, мы смотрим на относительный размер ключа и значение срединного элемента и затем перемещаемся в нижнюю или верхнюю половину списка. В этой половине снова ищем середину и опять сравниваем с ключом. Если не получается, снова делим на половину текущий интервал.
Несколько важных причин такого рода анализа:
1.Программы, написанные на языке высокого уровня, транслируются в машинные коды, и понять сколько времени потребуется для выполнения того или иного оператора может быть трудно.
2.Многие программы очень чувствительны к входным данным, и их эффективность может очень сильно от них зависеть. Средний случай может оказаться математической фикцией, не связанной с теми данными на которых программа используется, а худший случай маловероятен.
Лучший, средний и худший случаи очень большое влияние играют в сортировке. Объем вычислений при сортировке (см. таблицу)
|
|
|
|
Таблица |
Объем вычислений при сортировке |
|
|||
|
В лучшем |
В среднем |
|
В худшем |
|
случае |
|
|
случае |
Пузырьковая |
O(N) |
O(N2) |
|
O(N2) |
Выборками |
O(N2) |
O(N2) |
|
O(N2) |
Быстр. Сорт. |
O(N+log2(N)) |
O(N+log2(N)) |
|
O(N2) |
13
O-анализ сложности получил широкое распространение во многих практических приложениях. Тем не менее необходимо четко понимать его ограниченность.
К основным недостаткам подхода можно отнести следующие:
1)для сложных алгоритмов получение O-оценок, как правило, либо очень трудоемко, либо практически невозможно;
2)часто трудно определить сложность «в среднем»;
3)O-оценки слишком грубые для отображения более тонких отличий алгоритмов;
4)O-анализ дает слишком мало информации (или вовсе
еене дает) для анализа поведения алгоритмов при обработке небольших объемов данных.
Определение сложности в O-обозначениях – далеко нетривиальная задача. В частности, эффективность двоичного поиска определяется не глубиной вложенности циклов, а способом выбора каждой очередной попытки.
Еще одна сложность – определение «среднего случая». Обычно сделать это достаточно трудно из-за невозможности предсказания условий работы алгоритма. Иногда алгоритм используется как фрагмент большой, сложной программы. Иногда эффективность работы аппаратуры и/или операционной системы, или некоторой компоненты компилятора существенно влияет на сложность алгоритма. Часто один и тот же алгоритм может использоваться в множестве различных приложений.
Из-за трудностей, связанных с проведением анализа временной сложности алгоритма «в среднем», часто приходится довольствоваться оценками для худшего и лучшего случаев. Эти оценки по сути определяют нижнюю и верхнюю границы сложности «в среднем». Собственно, если не удается провести анализ сложности алгоритма «в среднем», остается следовать одному из законов Мерфи, согласно которому оценка, полученная для наихудшего случая, может служить хорошей аппроксимацией сложности «в среднем» [2].
14
Все три формы сложности обычно взаимосвязаны. Как правило, при разработке алгоритма с хорошей временной оценкой сложности приходится жертвовать его пространственной и/или интеллектуальной сложностью. Например, алгоритм быстрой сортировки существенно быстрее, чем алгоритм сортировки выборками. Плата за увеличение скорости сортировки выражена в большем объеме необходимой для сортировки памяти. Необходимость дополнительной памяти для быстрой сортировки связана с многократными рекурсивными вызовами.
Алгоритм быстрой сортировки характеризуется также и большей интеллектуальной сложностью по сравнению с алгоритмом сортировки вставками. Если предложить сотне людей отсортировать последовательность объектов, то вероятнее всего, большинство из них используют алгоритм сортировки выборками. Маловероятно также, что кто-то из них воспользуется быстрой сортировкой. Причины большей интеллектуальной и пространственной сложности быстрой сортировки очевидны: алгоритм рекурсивный, его достаточно трудно описать, алгоритм длиннее (имеется в виду текст программы), чем более простые алгоритмы сортировки [3].
15
2. СОДЕРЖАНИЕ ПРОЕКТА
На защиту студент представляет расчетнопояснительную записку в электронном и бумажном виде. Пояснительная записка должна содержать постановку задач, подробное описание выполняемых расчетов. Отдельные части кода должны быть озаглавлены.
Расчетно-пояснительная записка объемом от 20 до 50 страниц содержит:
1)Титульный лист;
2)Задание на курсовую работу (проект);
3)Лист «Замечания руководителя»;
4)Содержание;
5)Введение;
6)Основная часть (теоретическое введение, оценка и обоснование эффективности алгоритма, код программы);
7)Заключение;
8)Список используемой литературы;
9)Приложения (при необходимости).
В списке используемой литературы обязательно должны быть отмечены книги и пособия, которые использованы именно в этом курсовом проекте.
16
3.ЗАДАНИЕ НА ПРОЕКТИРОВАНИЕ
1.Разработать программу, реализующую сжатие изображений по алгоритму JPEG. (задание для двух студентов).
2.Реализовать программу, использующую B- дерево для нахождения записей в файле по идентификатору. Оценить эффективность поиска записей.
3.Реализовать класс очереди с приоритетом и на его базе реализовать алгоритм пирамидальной сортировки.
4.Реализовать класс динамической хеш-таблицы. Оценить эффективность поиска в ней по мере роста количества элементов.
5.Разработать программу-архиватор, осуществляющую сжатие файлов с помощью алгоритма Хаффмана.
6.Реализовать класс ассоциативного контейнера, хранящий пары элементов «ключ-значение». Ключи хранить в сбалансированном двоичном дереве поиска. Предусмотреть в нем функции добавления и удаления пар элементов, а также операции поиска по ключу.
7.Разработать программу, сравнивающую эффективность следующих алгоритмов поиска подстроки в строке при различных входных данных и длинах алфавита: алгоритм грубой силы, алгоритм Алгоритм Кнута-Морриса-Пратта, алгоритм Боуэра-Мура.
8.Разработать программу, осуществляющую синтаксический разбор и вычисление выражений с заданным списком допустимых операций и функций. К допустимым операциям могут относиться +, -, *, / к фукциям cos, sin, log и т.п. Предусмотреть возможность расширения списка операций
ифункций.
17
9.Реализовать класс «множество», хранящий элементы в сбалансированном двоичном дереве поиска. Предусмотреть в нем функции добавления и удаления элементов, а также операции сложения и пересечения множеств.
10.Разработать класс, который можно использовать для генерации случайных связных графов с заданным количеством ребер, для вычислительных экспериментов. Оценить сложность алгоритмов Дейкстры и Флойда с помощью обектов данного класса.
11.Разработать класс, позволяющий хранить разряженные матрицы эффективными способами (с помощью линейного списка, массива указателей и двоичного дерева). Предусмотреть в данном классе основные операции над матрицами. Сравнить эффективность способов по быстродействию и расходу памяти.
12.Разработать класс, позволяющий производить нечеткий поиск подстроки в строке, используя алгоритм Ландау-Вишкина.
18