

Методическое пособие 828
.pdfинформации на заданном терминологическом портрете(4.41), позволяет составлять ответы на запросы более гибко с учетом неопределенности описания, как документов, так и запросов по сравнению с простой распределенной -ин формационной подсистемой, а также перераспределять нагрузку на локальные информационные подсистемы в зависимости от значимости обслуживаемых терминов.
Рассмотрим синтез структуры распределенной информационной системы.
4.3. Определение структуры распределенной информационной системы
Пусть Sj = (Tj, Dj, Mj, d j ), j = 1,n - локальные информационные системы, предназначенные для обеспечения функционирования сложной управляющей системы, состоящей из совокупности К = {1, …,j } объектов. Информация с каждой локальной информационной системы поступает в центр сбора информации для дальнейшей передачи ее управляющему органу. Одна локальная информационная система может обслуживать несколько объектов.
Распределенная информационная система S = (T, D, M, d ) определяется
через локальные составляющие: |
|
|
||
1) |
T =U Tj ; R j |
= R Ç (Tj ´Tj ) ; |
K j = K Ç (T0 j ´T0 j ) ; |
(4.7) |
|
j |
|
|
|
2) |
D = U Dj ; |
|
|
(4.8) |
|
j |
|
|
|
3) |
(K É U K j ) Ù (< = < Ç (M j |
´ M j )) ; |
(4.9) |
|
|
j |
~ j ~ j |
|
|
4) |
"m Î M j |
d (m) = {d : d Î D Ù m < t(d ) . |
(4.10) |
|
|
|
|
~ |
|
Распределенная информационная система выступает в роли центра сбора и обработки информации, т. е. обработки ответов на запросы управляющих органов.
Для формализации задачи введем обозначения: c jl - стоимость сбора ин-
формации об l-м объекте j-й локальной информационной системой; b jl - стои-
мость передачи единицы информации об1-м объекте в центр изj-й информационной локальной системы; x jl — булева переменная, равна 1, если l-й объект
обслуживается j –й локальной информационной системой, и равна 0 в противном случае.
Описание состояния каждого объекта представляется в виде своейин формационной модели:
S lj |
= (Tjl , Dlj , M lj ,d jl ), l Î K, j Î{1,K,n}, |
(4.11) |
где T jl - тезаурус |
с дескрипторным множествомT0l j , |
описывающий со- |
стояние l-го объекта; D lj - коллекция возможных документов, которые требуют-
ся органам управления для принятия решения; M lj - множество допустимых за-
просов со стороны органов управления; d jl : M lj ® 2D lj отображение, сопостав-
ляющее каждому вопросу множество документов.
151
Индекс j указывает, что информационная модель 1-го объекта сформирована в j -й локальной информационной системе.
Если локальная система обслуживает несколько объектов, то она формально является распределенной системой "точечного" типа.
Информация об объектах представляется независимыми информационными моделями и вместе с тем, она сосредоточена в одном месте, в одной "точке". Таким образом, информационные модели объектов являются подсистемами глобальной информационной модели. Это дает возможность формулировать ответы на запросы в виде:
d j |
ì |
Ù m < |
ü |
, |
(4.12) |
(m) = íd : d Î D j |
t(d )ý |
||||
|
î |
~ j |
þ |
|
|
где m Î M j .
Правильность ответа гарантируется свойствами распределенной системы, представленной в п. 4.3.
Для запросов сложного типа, включающих в себя несколько дескрипторов, выражение (4.12) имеет вид:
|
|
|
|
k p |
l |
|
|
|
k p ì |
l |
|
l |
ü |
|
||||
|
|
d j |
(m) |
Ù m j < |
, (4.13) |
|||||||||||||
|
|
(m) = Ç Èd j |
= Ç Èíd : d Î D j |
|
t(d )ý |
|||||||||||||
|
|
|
|
i =1 l =1 |
|
|
|
|
i =1 l =1î |
|
~ j |
þ |
|
|||||
где |
|
={m1,Kmk } , |
|
i ={mi}; число объектов, обслуживаемых любой систе- |
||||||||||||||
m |
m |
|||||||||||||||||
мой. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Объем передаваемой информации на запрос |
|
из j-й локальной инфор- |
||||||||||||||||
m |
||||||||||||||||||
мационной системы равен: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
a |
|
= |
F ( d j ( |
|
)) , |
|
|
|
|
(4.14) |
||||
|
|
|
|
|
m |
|
|
|
|
|||||||||
|
|
|
|
m |
|
|
|
|
||||||||||
где F – оператор преобразования информации к виду, предназначенному |
||||||||||||||||||
для передачи в каналы связи. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Сформулируем задачу распределения объектов по |
локальным |
информа- |
||||||||||||||||
ционным подсистемам при множестве допустимых запросов в распределенной системе M = {m1,Kmr } , на которые ответы формируются последовательно без повторения запросов. Для удобства положим, что каждый запрос описывается одним дескриптором.
Требуется найти:
min{x } |
ååc jl x jl + åååbjl F (d lj (mi ))x jl , |
(4.15) |
||
jl |
j |
l |
i j l |
|
при ограничениях: |
|
åx jl |
= 1, "l Î K ; |
(4.16) |
|
|
|||
å x jl |
j |
|
|
|
³ (£)N j , "j Î{1,Kn} . |
(4.17) |
|||
l |
|
|
|
|
Ограничение (4.16) требует обслуживания каждого объекта только одной информационной системой. Условие (4.17) ограничивает количество объектов, подлежащих обслуживанию локальными подсистемами, либо, напротив, требует, чтобы их было не меньше заданного числа.
152
Усложним требования к распределенной системе. Потребуем, чтобы органы управления получали ответы на запросы даже в случае, если любая локальная информационная система перестанет функционировать.
Иначе говоря, возникает потребность в дублировании информации об объектах.
Постановка задачи меняется только в части, касающейся изменения ограничения (4.16). Оно принимает вид:
åx jl = 2, "l Î K |
(4.18). |
j |
|
Модифицируем еще раз постановку задачи. Будем считать, что после закрепления объектов за локальными информационными системами в задаче (4.15) - (4.17) перераспределения объектов не происходит.
Однако органам управления необходимо иметь информацию о предыдущих состояниях объектов даже после прекращения функционирования любой из локальных подсистем. Это означает, что происходит дублирование информационных моделей об объектах постоянно в процессе их функционирования и информация локальных информационных систем перераспределяется между ними.
Упростим ситуацию, полагая, что перераспределение информации осуществляется один раз. Хотя в реальной ситуации информация о состоянии объектов передается по мере ее поступления на всем интервале времени функционирования локальных информационных систем, указанное ограничение не снижает общих рассуждений, так как полная постановка задачи потребует просто дополнительного суммирования по дискретным моментам времени.
Введем следующие обозначения: a js - стоимость передачи единицы информации из j-й локальной информационной системы вs-ю; y jsl - булева пере-
менная, равна 1, если информация об l-м объекте перераспределяется из j-й локальной информационной системы в s-ю.
Окончательно задача синтеза структуры распределенной информационной системы формулируется так: необходимо найти:
{xmin, y } |
ååc jl x jl |
+ åååbjl F (d jl (mi ))x jl |
+ åååa js [F (Tjl , Dlj , M lj ,d jl )x jl ]y jsl |
,(4.19) |
||
jl isl |
j l |
i j |
s |
j s |
l |
|
при ограничениях: |
åx jl = 1, "l Î K ; |
|
(4.20) |
|||
|
|
|
|
|||
|
|
å x jl |
j |
|
|
|
|
|
³ ( £ ) N j , " j Î {1, Kn } |
(4.21) |
|||
|
|
l |
å y jsl = 1, "l Î K j |
|
=1}, "j Î{1,Kn} . |
(4.22) |
|
|
|
= {l : x jl |
|||
|
|
|
s |
|
|
|
Ограничение (4.22 требует перераспределения информации об l-м объекте из j-й локальной информационной системы.
На основе задачи (4.19)-(4.22) можно сформулировать ряд задач, учитывающих те или иные требования относительно структуры распределенной системы. Для этого необходимо сформулировать требования в виде ограничений и
153

ввести их в описание задачи.
Разработанная модель учитывает распределение информации по дескрипторам, описывающим документ. Это позволяет органам управления оценивать неопределенность ответов на запросы.
Пусть документы в локальных информационных системах представляются в виде:
t(d l |
) = {< t l j , w >, < tl j , w |
>,K, < tl j , w >} , |
(4.23) |
|
j |
1 1 |
2 2 |
k k |
|
d lj Î Dlj , S lj = (Tjl , Dlj , M lj ,d lj ) .
В реальных ситуациях при описании состояния объектов, разные локальные информационные системы, обеспеченные различными техническими средствами измерения и наблюдения за состоянием объектов, представляют не совпадающие между собой описания одних и тех же объектов. В формализованном виде это означает, что при запросе m органов управления о состоянии некоторого объектаl локальные информационные системы дадут ответы с точностью подобия r :
d lj ( |
|
, r) = {(d lj ,a lj ) : d lj Î D j Ù |
|
Ñr t(dlj ) Ùa lj = m( |
|
, t(dlj ))}, "l Î K , |
j = |
|
. (4.24) |
m |
m |
m |
1,n |
||||||
Очевидно, что показатели a lj - могут быть использованы |
для уточнения |
||||||||
структуры распределенной системы, т. е. выбора такой структуры, которая бы обеспечивала получение ответов с максимальной мерой корреляции или с мерой корреляции не менее заданной. Последнее требование эквивалентно условию передачи информации с отвечающей запросу содержательной частью не менее заданной. Формализация этого условия применительно к постановке задачи (4.19)-(4.22) состоит во введении дополнительных ограничений:
a lj = m( |
m |
, t(dlj )) ³ a +j , "l Î K , "j : x jl = 1 . |
(4.25) |
В интересах практической реализации терминологического поиска на основе разработанных моделей и синтезированной структуры распределенной информационной системы, необходимо рассмотреть технологические аспекты решаемой задачи. Первый из них состоит в разработке алгоритма идентификации текстовой информации заданному терминологическому портрету.
4.4. Идентификация текстовой информации
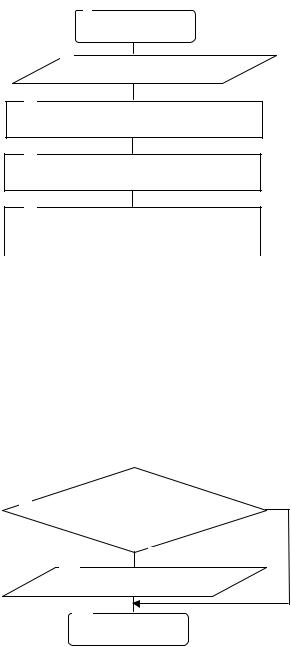
Терминологический портрет может быть построен как для отдельного текста (терминологический портрет текста(ТПТ), так и для некоторой предметной области. Владельцем терминологического портрета предметной области может быть как пользователь, так и СППИР. Считая пользователя и СППИР единым целым будем называть последний терминологическим портретом информационной системы (ТПИС). Пример ТПИС в виде иерархической структуры предметной области формирования и управления портфелем ЦБ приведен на рис.1.14 п. 1.8. Он является своеобразным фильтром, через который «пропускается» множество тематических текстов, поступающих из различных источников информации. Блок-схема алгоритма идентификации некоторого текста приведена на рис. 4.3.
154
1
Начало
2
Ввод текста
3
Формализация текста
4
Выделение терминов
5Преобразование терминов
кканоническому виду
|
|
|
|
|
|
|
|
|
6 |
|
|
|
|
|
|
|
Фильтрация терминов |
|||
|
|
|
|
|
||
|
|
|
|
|
||
|
|
|
|
|
по стоп-словарю |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
7 |
|
|
|
|
|
|
Накопление частот |
|||
|
|
|
|
|
||
|
|
|
|
|
встречаемости используемых |
|
|
|
|
|
|
терминов |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
Формирование ТПТ |
|||
|
|
|
|
|
||
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9 |
Идентификация |
Нет |
|
|
|
ТПТ |
|
|
10 |
Да |
|
|
|
|
|
|
Вывод результатов |
|
|
|
11 |
|
|
Конец
Рис. 4.3. Блок-схема алгоритма идентификации текста
Блоки 1, 11 реализуют начало и окончание процесса идентификации тек-
ста. |
|
|
|
|
|
|
Блок 2 обеспечивает ввод исходного текста. |
|
|
|
|||
В |
блоке 3 |
осуществляется |
формализация |
текста |
на |
основе |
соответсвующей модели - многоуровневой иерархической схемы текстовых |
||||||
данных (см. рис. 4.1) [37], реализованной в ряде информационных систем[71, |
|
|||||
77, 87, 110, 150]. В |
ней используется 5 уровней иерархии: дискурс (связный |
|
||||
текст); предложение; словосочетание; слово; морфема. Уровни с 6 по 8 предназначены для звукового анализа и в данной работе не рассматриваются.
В блоке 4 реализовано выделение терминов. Для выделения терминов и построения терминологического портрета текста используется специальный
155
иерархический терминопостроитель, содержащий соответствующую систему моделей и алгоритмов терминологического поиска. Его детализация приведена в п. 4.5.
Блок 5 используется для преобразования выделенных терминов к каноническому виду с целью определения их морфологических форм(отрицательная форма, нестандартная ситуация, существительное, сравнительная степень прилагательного, краткое прилагательное, краткая форма прилагательного или причастия, прилагательное или причастие, наречие или сложное прилагательное с дефисом, деепричастие от глагола совершенного вида, деепричастие от глагола несовершенного вида, повелительное наклонение глагола, неправильный глагол, глагол, прошедшее время глагола, возвратная форма глагола).
Блок 6 обеспечивает фильтрацию выделенных терминов по стоп–
словарю |
для |
исключения |
из |
рассмотрения |
заведомо |
не перспективных |
||||
терминов (предлоги, частицы, союзы, местоимения и др). |
|
|
|
|||||||
В |
блоке 7 |
реализовано |
накопление |
и |
анализ |
частот |
встречаемости |
|||
выявленных терминов с целью определения их весов. |
|
|
|
|
||||||
Блок 8 формирует |
ТПТ, |
представляющий |
|
собой |
вектор |
весов |
||||
информационных |
признаков (v1,…,vк), где vi |
– |
вес |
i-го |
признака i=1,…,k |
в |
||||
тексте, k –число признаков. Вес i-го информационного признака соответствует частоте встречаемости терминов из которых он состоит и определяется в соответствии с выражением (4.61):
|
vi = |
ni |
, |
(4.26) |
|
|
|||
|
|
N |
|
|
где ni - |
число терминов i-го признака |
в данном тексте; N - общее |
||
количество терминов. |
|
|||
В блоке 9 реализована идентификация ТПТ. Для принятия решения о |
||||
соответствии |
данного текста исследуемой |
предметной областиТПИС, |
||
рассчитывается значение косинуса угла между весовыми векторами ТПТ и ТПИС. Порядок проведения расчетов следующий.
Рассмотрим в n – мерном пространстве два произвольных вектора АВ и
CD с координатами ai , bi , ci , d i |
: |
|
|
r |
|
,L,b - a } |
(4.27) |
AB = {b -a ,b -a |
|||
r |
1 1 2 2 |
n n |
|
CD ={d1 - c1 ,d2 - c2 ,L,dn - cn }. |
(4.28) |
||
Координаты ai , bi , ci , d i |
являются координатами случайных величин А= |
||
{a1 , a2 ,L, an }, В = {b1 , b2 ,L, bn }, С = {c1 , c2 ,L, cn } и D = {d1 , d 2 ,L, d n }. На всей области определения [- ¥, + ¥] они имеют нормальное распределение.
Введем систему прямоугольных координат. Тогда случайные величины X и Y равные A – B и C – D соответственно, будут представлять собой те же вектора, которые проведены из начала координат. Формально это записывается следующим образом:
xi = bi - ai
156
4.5. Описание иерархического текстового терминопостроителя
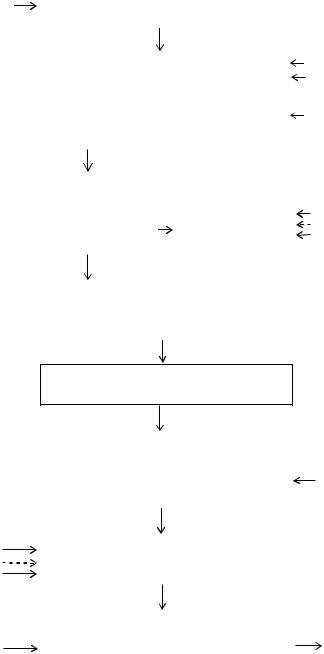
Иерархический текстовый терминопостроитель (ИТТ) предназначен для формирования терминологического портрета исследуемого текста. Он базируется на системе моделей и алгоритмов формализации и проведения различных видов анализа текста (морфологического, синтаксического и семантического). Впервые подобная система моделей и алгоритмов была обоснована в [64, 128] и прошла практическую апробацию [76, 77] в интересах рубрицирования текстов. Ее структурная схема приведена на рис. 4.4.
Обрабатывае- |
Алгоритм графематической об- |
|
работки текста |
||
мый текст |
||
|
|
Алгоритм морфологического |
|
Набор лемм |
|
||
|
анализа текста |
|
Набор имён собствен- |
|
||
|
|
ных |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
Набор географических |
|
|
|
|
|
|
имён собственных |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Алгоритм |
|
Алгоритм син- |
Синтаксические |
пра- |
|
|
фрагментаци- |
|
таксической |
|||
|
|
вила объединения слов |
||||
онной обработ- |
|
обработки тек- |
||||
|
и словосочетаний |
|
||||
|
ки текста |
|
ста |
|
||
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
Алгоритм объединения результа- |
|
|
|||
|
тов фрагментационной и синтак- |
|
|
|||
|
сической обработки текста |
|
|
|||
Модель семантической обработки текста
|
|
Алгоритм формирования терми- |
|
Перечень эталон- |
|
|
|
нологического портрета текста |
|
ных |
малоинфор- |
|
|
|
мативных слов |
||
|
|
|
|
||
Терминологи- |
|
|
|
|
|
|
|
|
|
|
|
|
Алгоритм рубрицирования тек- |
|
|
|
|
ческие портре- |
|
|
|
|
|
|
ста |
|
|
|
|
ты рубрик |
|
|
|
|
|
|
|
|
|
|
|
Содержание теку- |
|
|
Дополнительные дан- |
||
Алгоритм извлечения дополни- |
|||||
щей информации по |
тельных данных |
ные извлечённые из |
|||
данной тематике |
|
|
текста |
|
|
Рис. 4.4. Система моделей и алгоритмов формализации и анализа текста в интересах рубрицирования
158
Как видно из схемы, исходный текст поступает на вход алгоритма графематической обработки. Данный алгоритм предназначен для разбивки текста на абзацы и предложения, а также выделения аббревиатур, личных имён с инициалами, цифровой и символьной информации (даты, формулы и др.). Преобразованный в соответствии с данным алгоритмом текст в табличной формепо ступает на вход алгоритма морфологического анализа текста.
Алгоритм морфологического анализа текста обеспечивает разбор слов в предложениях по частям речи и выделение специфических форм, получающих их статус, в зависимости от окончаний и структуры слов. Текст, прошедший морфологический анализ поступает на вход алгоритма фрагментационной -об работки текста.
Алгоритм фрагментационной обработки текста используется в интересах выделения в предложениях неразрывных синтаксических единств(фрагментов), больших или равных словосочетанию(синтаксической группе) и их иерархическому упорядочиванию. Применение данного алгоритма позволяет повысить эффективность проведения синтаксической обработки текста.
Алгоритм синтаксического анализа обеспечивает построение синтаксических структур предложений, учитывающих данные морфологического анализа и синтаксические правила объединения слов и словосочетаний. Синтаксическая структура отражает связи, существующие между словами предложения.
С целью сохранения смысловой целостности текста, необходимой для семантической обработки текста, иерархически упорядоченные фрагменты и синтаксические структуры предложений поступают на вход алгоритма объединения результатов фрагментационной и синтаксической обработки текста.
Алгоритм объединения результатов фрагментационной и синтаксической обработки текста предназначен для построения дерева зависимостей, узлами которого являются отдельные слова или так называемые“жёсткие” группынаборы слов, связанные синтаксическими отношениями. Дерево зависимостей используется в качестве основы для построения семантического графа текста, составляющего суть модели семантической обработки текста.
Модель семантической обработки текста обеспечивает формирование семантической сети, представляющей собой совокупность взаимосвязанных понятий (слов и словосочетаний) несущих основную смысловую нагрузку и наиболее часто встречающихся в тексте. Исходный текст, преобразованный в семантическую сеть, поступает на вход алгоритма формирования терминологического портрета-текста.
Алгоритм формирования терминологического портрета текста позволяет построить массив его статистических наиболее значимых параметров в виде вектора проранжированных весов информационных признаков. Терминологический портрет текста поступает на вход алгоритма рубрицирования текста.
Назначение алгоритма рубрицирования текста заключается в отнесении терминологического портрета к соответствующей рубрике. Поэтому на вход данного алгоритма поступают также терминологические портреты рубрик. В
159
случае принадлежности исследуемого текста данной рубрике, последний поступает на вход алгоритма извлечения дополнительных данных.
Алгоритм извлечения дополнительных данных реализует сравнение -со держания аннотированного текста с содержанием текущей информации, ви случае новизны её вывод. Содержание текущей информации выделяется из терминологического портрета рубрики.
Входе дальнейшего развития системы моделей и алгоритмов формализации и анализа текста ее ядро, содержащее пять первых алгоритмов обработки текста, практически не изменялось, а модифициовались модель семантического анализа текста и алгоритмы формирования терминологического портрета текста и извлечения дополнительных данных. Так в интересах аннотирования текстов [110] в алгоритме формирования терминологического портрета текста, основной упор был сделан на определение частот встречаемости слов[139] и применение шинглов [123].
Вданной работе модификация модели семантического анализа текста заключалась в следующем.
4.6.Текстовый анализ на основе семантической матрично-лексической модели
Целевое назначение данной модели заключается в выделении терминов
заданного текста на основании смысла. Ее основу составляют лексемы.
Под лексемой (лексической единицей) будем понимать элементарную семантичеcки значимую единицу языка, представляющую собой слово, устойчивое словосочетание или другую языковую конструкцию, способную обозначать предметы, явления, их признаки и др. [229].
Лексемы имеют ряд свойств.
Свойство 1. Две лексемы равны в том случае, если равно число составляющих их символов и символы в одинаковых позициях совпадают.
Свойство 2. Частота лексемы есть число ее повторений в различных фразах. Лексемы с единичной частотой встречаемости называются уникальными.
Свойство 3. Повторяющиеся лексемы составляют лексическое множество связей текста.
Свойство 3 показывает, что для каждого текста может быть построена своя матрица лексических связей (МЛС). Данная матрица строится следующим образом.
Пусть имеется текст, в котором присутствует множество лексем{L} º {l1,…,li,…,lNk}. Они упорядочены последовательностью появления в тексте. Общее число лексем связи в тексте составляетNk. Выявлены частоты встречаемости лексем F º {f1 ,K, fi ,K, fN k }. При этом fi > 1 при любом i £ Nk, поскольку уникальные лексемы удалены.
Предложениям текста Pn , n Î {1,…,Jp} соответствует множество входящих в них лексем li Î M.
Введем двоичный параметр qin , определяемый в соответствии с выражением:
160