

Файлы с неплотным индексом
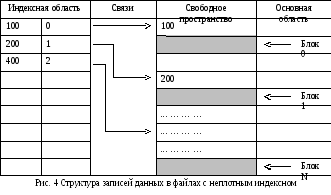
При такой организации файловой структуры процессы добавления новых записей отличаются от аналогичных действий в файлах с плотным индексом. Каждая новая запись заносится в соответствующий блок на место, определенное значением ключевого поля. В этом случае выполняется следующая последовательность действий:
определяется номер блока основной области, в который необходимо поместить новую запись;
найденный блок считывается в оперативную память;
в оперативной памяти производится корректировка блока;
откорректированный блок записывается на диск на прежнее место.
В этом случае число обращений к диску при внесении новой записи равно числу обращений к диску при поиске блока плюс одно обращение, которое необходимо выполнить при записи откорректированного блока на прежнее место. В данном случае не принимается во внимание время записи блока в оперативную память, которое несопоставимо со временем обращения к диску.
Следовательно, число обращений к дисковому пространству при такой организации файловой структуры будет на единицу меньше, чем у файлов с плотным индексом для каждой записи, что при значительном числе записей не только существенно сокращает время обработки данных, но и повышает надежность работы дисковых устройств.
Иерархическая организация памяти
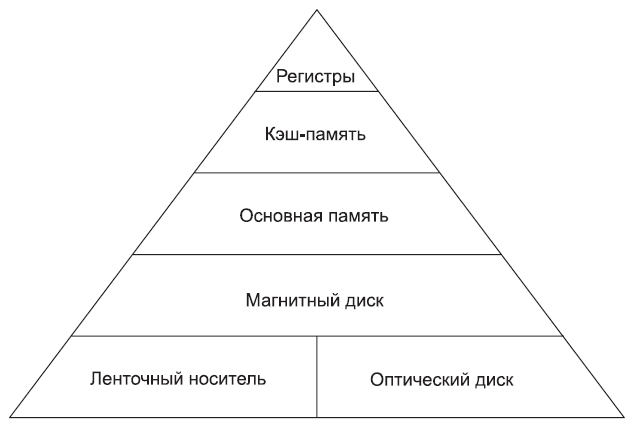 Иерархическая
организация памяти современных
компьютеров строится на нескольких
уровнях, причем более высокий уровень
меньше по объему, быстрее и имеет большую
стоимость в пересчете на байт, чем более
низкий уровень. Уровни иерархии
взаимосвязаны: все данные на одном
уровне могут быть также найдены на более
низком уровне, и все данные на этом более
низком уровне могут быть найдены на
следующем лежащем ниже уровне и так
далее, пока мы не достигнем основания
иерархии.
Иерархическая
организация памяти современных
компьютеров строится на нескольких
уровнях, причем более высокий уровень
меньше по объему, быстрее и имеет большую
стоимость в пересчете на байт, чем более
низкий уровень. Уровни иерархии
взаимосвязаны: все данные на одном
уровне могут быть также найдены на более
низком уровне, и все данные на этом более
низком уровне могут быть найдены на
следующем лежащем ниже уровне и так
далее, пока мы не достигнем основания
иерархии.
Успешное или неуспешное обращение к более высокому уровню называются соответственно попаданием (hit) или промахом (miss). Попадание есть обращение к объекту в памяти, который найден на более высоком уровне, в то время как промах означает, что он не найден на этом уровне. Доля попаданий (hit rate), или коэффициент попаданий (hit ratio), есть доля обращений, найденных на более высоком уровне. Иногда она выражается в процентах. Доля промахов (miss rate) есть доля обращений, которые не найдены на более высоком уровне.
Организация кэш памяти
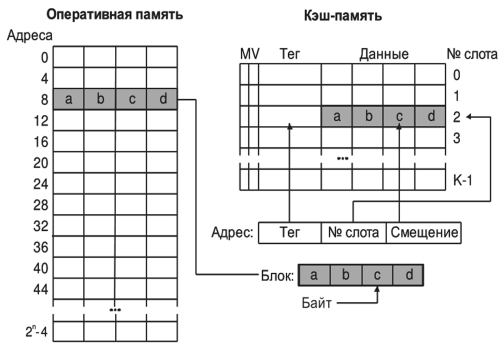
Кэш-память состоит из блоков фиксированного размера, называемых кэш-строками. Каждая кэш-строка имеет индивидуальный номер (индекс или спотовый номер), строка хранит один блок кода или данных из оперативной памяти. Для отображения адресов оперативной памяти в адреса кэш-памяти (рисунок выше), оперативная память, состоящая из 2" адресуемых байт, разбивается на блоки размером, равным размеру кэш-строки. Между блоками оперативной памяти и кэш-строками устанавливается соответствие. Поскольку строк в кэш-памяти меньше, чем блоков в оперативной памяти, индекс строки не может однозначно принадлежать одному блоку оперативной памяти. Поэтому каждая строка кэш-памяти кроме блока хранит старшую часть его адреса в оперативной памяти, называемую тегом. Тег идентифицирует блок оперативной памяти, который записан в строку кэш-памяти в данный момент времени. Таким образом, адрес ячейки памяти включает в себя три компонента: тег, номер слота и смещение, которое указывает номер байта в блоке.
Каждая строка кэш-памяти содержит дополнительную информацию о кэшированном блоке. Типичный набор атрибутов содержит бит модификации и бит присутствия.
• Бит модификации указывает, модифицировался ли блок, лежащий в данной кэш-строке, и имеет два состояния: модифицированное и немодифицированное.
• Бит присутствия отражает присутствие блока в кэш-строке и характеризуется двумя состояниями: действительным и недействительным. Недействительное состояние означает, что данная кэш- строка не содержит копии какого-либо блока из оперативной памяти.