

Разработка модели предсказания сахара
В статистике хорошо известно интуитивное соображение, согласно которому усреднение результатов наблюдений может дать более устойчивую и надежную оценку, поскольку ослабляется влияние случайных флуктуаций в отдельном измерении. На аналогичной идее было основано развитие алгоритмов комбинирования моделей, в результате чего построение их ансамблей оказалось одним из самых мощных методов машинного обучения, нередко превосходящим по качеству предсказаний другие методы. Например, чистый регрессионный анализ применяется для описания линейных зависимостей и снижает свою эффективность, если между рассматриваемыми параметрами возникает значимая корреляция. Как уже раньше упоминалось, мы используем систему градиентного бустинга (библиотека xgboost) для повышения качества модели случайного леса (random forest). Случайный лес в свою очередь является алгоритмом машинного обучения, использующим ансамбли деревьев регрессии, каждое из которых само по себе даёт очень невысокую точность, но за счёт их большого количества результат получается хорошим. Заключение принимается по итогу «голосования» деревьев (рис. 7).
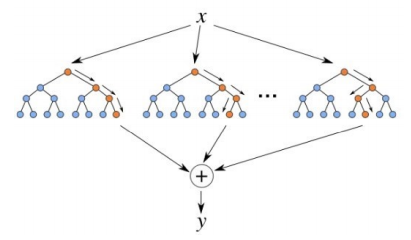
Рисунок 6 – Ансамбли случайного леса
Бустинг (boosting) заключается в итеративном процессе последовательного построения частных моделей. Каждая новая модель обучается с использованием информации об ошибках, сделанных на предыдущем этапе, а результирующая функция представляет собой линейную комбинацию всего ансамбля моделей с учетом минимизации любой штрафной функции.
Каждое дерево строится по набору данных X,r, который на каждом шаге модифицируется определенным образом. На первой итерации по значениям исходных предикторов строится дерево f1(x) и находится вектор остатков r1. На последующем этапе новое регрессионное дерево f2(x) стоится уже не по обучающим данным X, а по остаткам r1 предыдущей модели. Линейная комбинация прогноза по построенным деревьям дает нам новые остатки
 и этот процесс повторяется
B
раз. Благодаря
построению неглубоких деревьев по
остаткам, прогноз отклика медленно
улучшается в областях, где одиночное
дерево работает не очень хорошо. Такие
деревья могут быть довольно небольшими,
лишь с несколькими конечными узлами.
Параметр сжатия
и этот процесс повторяется
B
раз. Благодаря
построению неглубоких деревьев по
остаткам, прогноз отклика медленно
улучшается в областях, где одиночное
дерево работает не очень хорошо. Такие
деревья могут быть довольно небольшими,
лишь с несколькими конечными узлами.
Параметр сжатия
 регулирует скорость этого процесса,
позволяя создавать комбинации деревьев
более сложной формы для анализа остатков.
Итоговая модель бустинга представляет
собой ансамбль
регулирует скорость этого процесса,
позволяя создавать комбинации деревьев
более сложной формы для анализа остатков.
Итоговая модель бустинга представляет
собой ансамбль
 .
.
Модель градиентного бустинга на основе деревьев регрессии (GBDT) была выбрана в качестве модели для прогнозирования PPGR из-за ее высокой точности прогнозирования с разнородными наборами данных и способности работать с отсутствующими данными. Коэффициент корреляции Пирсона, средняя абсолютная ошибка (MAE), а также среднеквадратичная ошибка (MSE) были выбраны в качестве ключевых показателей для оценки модели с помощью тестового набора. Окончательная точность будет оцениваться по данным новых пациентов (25% от всех пациентов).
Экспорт и последующее представление данных
Преимуществом разработки мобильного приложения является упрощенная процедура синхронизации данных через облачные хранилища со всеми подключенными к одному аккаунту устройствами, однако, далеко не каждый пользователь может беспрепятственно извлечь и переслать в каком бы то ни было виде собранную браслетами/смартфонами информацию через общедоступные средства связи, такие как почта или социальные сети. Более того существующие методы, например, у Samsung Health подразумевают наличие у пользователя некоторого предыдущего опыта использования подобных систем или сноровки в самостоятельном освоении современных технологий, т.е. рассчитаны на представителей среднего возраста и младше, упуская из виду потребность в обеспечении медицинского контроля у пожилых людей. Напомним себе, что в связи с пандемией именно этот срез населения наиболее нуждается в сфере услуг удаленного мониторинга.
Изучим подробнее способ экспорта данных пользователя, предложенный Samsung Health на рисунке 2. Первое, что бросается в глаза, – данные скачиваются в виде папки, включающей в себя подпапку jsons и огромное количество неочевидно названных csv файлов, формат широко распространенный среди людей, работающих с таблицами и базами данных, однако, ни мобильная, ни десктопная русскоязычная версия Microsoft Office 365 при открытии не справляется с автоматическим определением кодировки и форматом представления данных. Для успешного прочтения необходимо выполнить специализированную процедуру импорта текстовых csv строк в новый лист Excel, см. рисунок 6. Полученная таблица крайне безлика: часть наименований не переведена, массивы данных не сгруппированы по дням, формат даты и времени отличается от привычного, отсутствует цветовое разделение приемов пищи по дням или гликемической нагрузке.
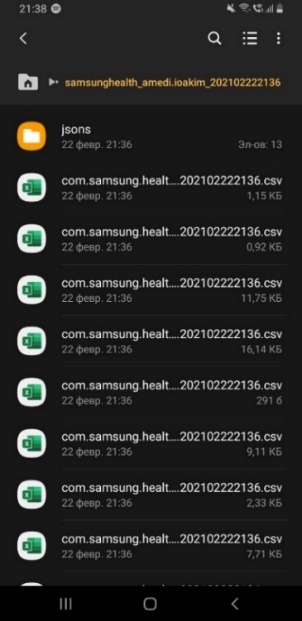
Рис. 7 – Экранная форма скачанных данных
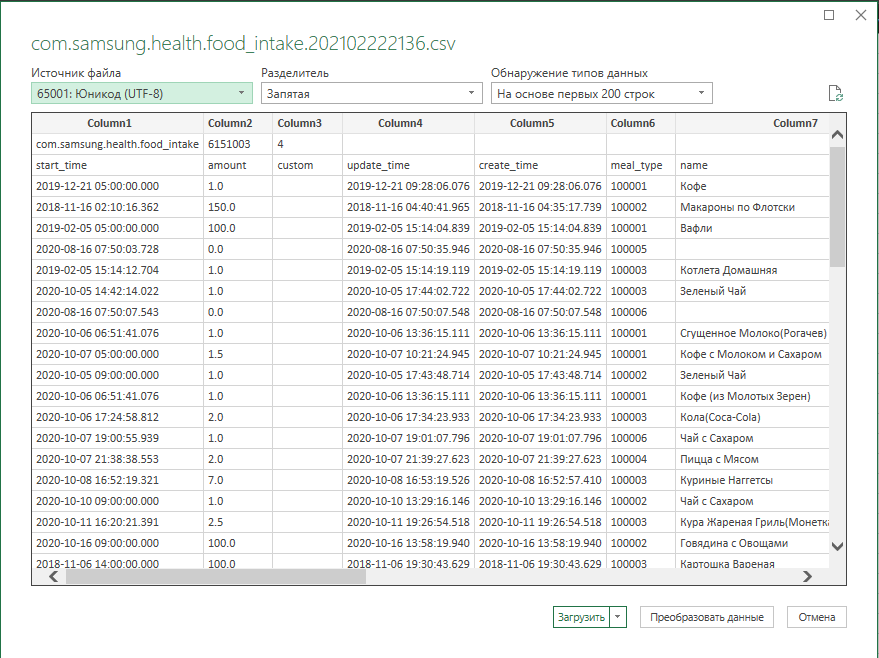
Рис. 8 – Преобразование импортированных данных
Иными словами, способ импортирования данных и их последующее представление должны быть удобны не только разработчикам, но и самим пользователям, а также врачам. Для достижения поставленной задачи в своем веб-приложении мною был написан программный скрипт, импортирующий данные по почте в виде «никнейм_пользователя».xlsx файла, содержащего в себе листы, названные по заполняемым в ходе использования веб-приложения разделам: приемы пищи, физическая нагрузка и сон, предсказание сахара, список полных дней, удаленные записи. Помимо этого, реализована возможность скачать итоговый файл на собственный ПК или мобильное устройство с возможностью последующего открытия средствами мобильного просмотра, MS Office 365/Liber Office или отправки файла в мессенджере, например, по WhatsApp. Внешний вид таблицы и ее функциональные особенности разрабатывались в соответствии врачами Института Эндокринологии НМИЦ им. В.А. Алмазова.
Аналогично своему конкуренту Apple Health предлагает экспортировать данные из приложения напрямую в формате xml, также требующим дополнительных манипуляций с файлом перед просмотром. Для большинства пользователей наиболее простым методом будет использовать стороннее приложение (оператор) QS Access для формирования и отправки читаемой сводки данных. Все операторы, в том числе занимающиеся, автоматизированной обработкой персональных данных, т.е. обработкой персональных данных с помощью средств вычислительной техники; должны следовать условиям и принципам обработки персональных данных согласно гл. 2 Федерального закона от 27 июля 2006 г. N 152-ФЗ «О персональных данных» [11]. Хотя проверить честность каждого отдельно взятого приложения-компаньона к Apple Health нельзя, можно с уверенностью утверждать, что усложнение системы и наращивание большого числа внутренних связей в системах реального времени пагубно отразится на надежности хранения и передачи информации пользователя. В связи с этим было решено реализовать в веб-приложении полный внутренний цикл обработки и передачи данных.