

Планируемые результаты работы
Клиент-серверная архитектура схематично изображена на рис. 1. Со стороны клиента поступает HTTPS запрос, SSL сертификат Let’s Encrypt был предварительно получен c помощью certbot. Его обрабатывает Nginx Server ретранслирующий запросы клиентов из внешней сети на один или несколько серверов, логически расположенных во внутренней сети. В нашем случае за внутренний локальный сервер отвечает WSGI server Gunicorn. Среди поддерживаемых им фреймворков есть и используемый в ходе работы Python Flask. За бесперебойную работу на сервере отвечает Supervisor.
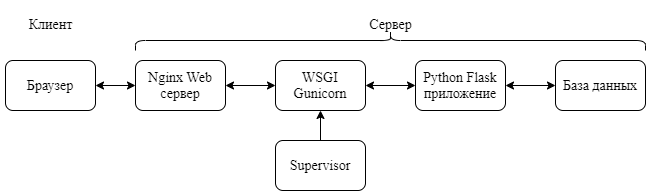
Рис. 1 – Клиент-серверная структура приложения
Интерфейс веб-приложения сделан, как и предполагалось, с использованием CSS фреймворка Bootstrap 4, на рис. 2 представлена произвольно заполненная в демонстрационных целях неделя, с указанием съеденного продукта, даты и времени. Структура разработанного веб-приложения изображена на рис. 2. С любой страницы возможно осуществить переход на другую, за исключением тех, что обозначены двойными стрелками – на них переадресация выполняется автоматически.
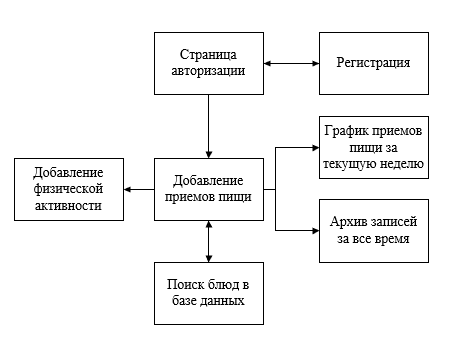
Рис. 2 – Структура веб-приложения
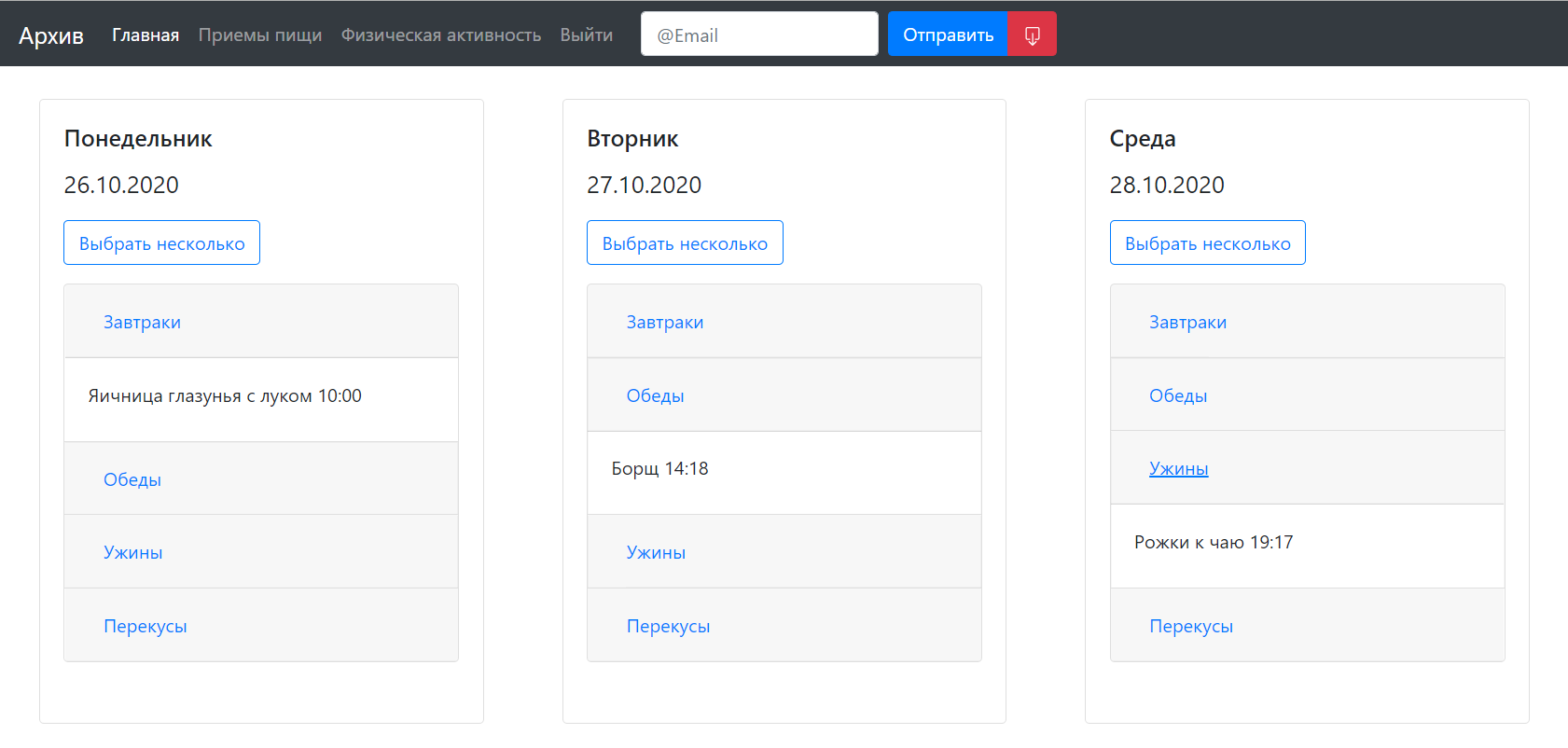
Рис. 3 – Экранная форма дневника приемов пищи пользователя
В то время как на рис. 3 отображена таблица, структурирующая ежедневные нагрузки и сон.
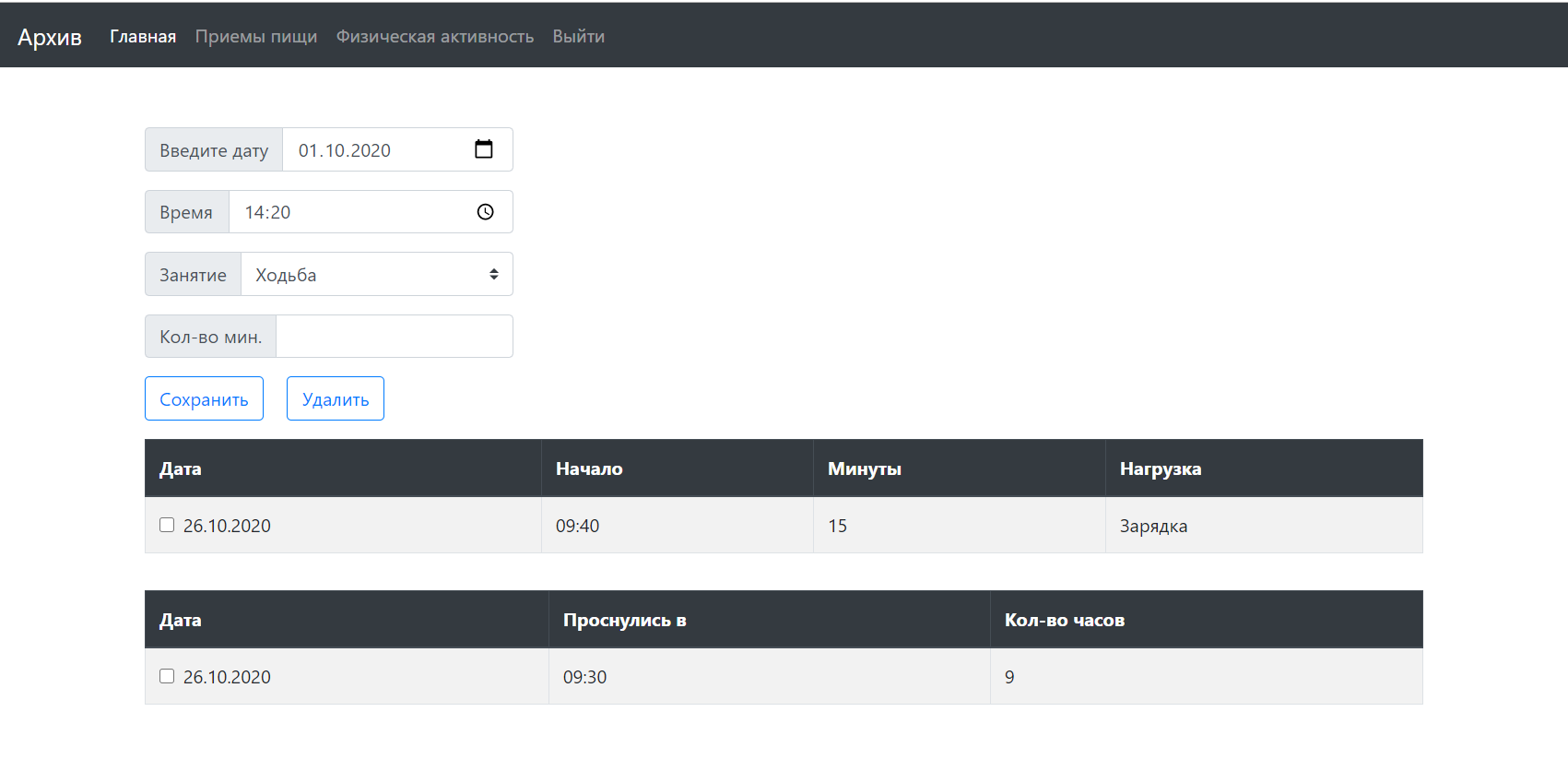
Рис. 4 – Экранная форма дневника физической активности пользователя
Для создания базы данных и операций над ней была использована система SQLite. Поскольку база данных SQLite не требует администрирования, она хорошо работает на устройствах, которые должны работать без квалифицированной поддержки оператора. С ростом количества пользователей и расширением функционала веб-приложения планируется переход на MySQL. За шифрование пользовательских паролей внутри базы данных отвечает алгоритм SHA256.
Функционал приложения планируется опробировать совместно с врачами Института Эндокринологии НМИЦ им. В.А. Алмазова. Ожидаемый результат должен представлять собой веб-приложение, формирующее отчет по потребелленным человеком продуктам, нутриентам, входящих в них, а также физической активности и сна. Помимо этого приложение реализует предостерегающую функцию. Например, можно добавить будущий прием пищи и оценить УКС – скрипт выдаст предостережение, если уровень сахара после приема пищи превысит 7 ммоль/л, а продукты в корзине подсветятся разыми цветами: красный – высокая гликемическая нагрузка, желтый – средняя, зеленый – в норме.
Предложенный проект можно интегрировать в медицинских исследовательских центрах. Помимо этого, планируется реализовать систему обмена сообщениями для прямой связи между пациентом и врачом/исследователем, также планируется интеграция баз данных с мобильным приложением для информационной поддержки больных сахарным диабетом ДиаКомпаньон.
Подходы к решению задач
Для формирования набора входных данных будет составлена сводная Excel таблица, в которой перечислим все параметры пищи из найденной в свободном доступе базы данных, единицы измерения и общее количество нутриентов. На другом листе подобным образом опишем разработанную нами базу данных и сравним показатели. Самая частая проблема при объединении баз данных, взятых из разных источников – разные единицы измерения. Перед нами стоит задача удалить все отличающиеся параметры и привести единицы измерения к системе СИ. Наиболее простым способом решения будет использование MS Access, где подобные операции давно автоматизированы.
Разработка алгоритма работы приложения будет выполнена в соответствии с выданным техническим заданием в среде MS Visio в виде блок-схемы. К ней необходимо разработать клиент-серверную структуру приложения и протестировать отдельные ее блоки в облачном конструкторе Heroku.
Разработка структуры SQLite базы данных (diacompanion.db) будет осуществляться в приложении DB Browser. Формат выбран не случайно. Поскольку база данных SQLite не требует администрирования, она хорошо работает на устройствах, которые должны работать без квалифицированной поддержки человека. С ростом количества пользователей и расширением функционала веб-приложения планируется переход на MySQL. За шифрование пользовательских паролей внутри базы данных отвечает алгоритм SHA256. Покажем структуру базы данных в виде сводной таблицы 1. Можно заметить, что для удобства организации используется первичный ключ (user_id). С его помощью можно провести одновременный поиск по разным таблицам.
Таблица 1 – Предварительная структура базы данных
Название таблицы |
Заполняемые поля |
Назначение |
activity |
user_id, date, time, min, type |
Здесь хранится информация о физической активности пользователя |
favourites |
user_id, week_day, date, time, class, food |
Дневник приемов пищи |
full_days |
user_id, date |
Список полных дней |
sleep |
user_id, date, time, hour |
График сна |
user |
user_id, username, surname, email, password, BMI |
Личная информация, сохраняемая при регистрации |
food |
food_id, name, category, carbo, prot, fat, ec, gi, water, nzhk, hol, pv, zola, na, k, ca, mg, p, fe, a, b1, b2, rr, c, re, kar, mds, kr, te, ok, ne |
Уникальный идентификатор, наименование, категория (молочные продукты, колбасы, фрукты, овощи и другие) и набор нутриентов по каждому доступному продукту или блюду |
Для формирования пользовательского интерфейса можно использовать готовые CSS фреймворки Bootstrap или Materialize. Анимации переходов, выпадающих меню и кнопок можно прописать через Anime.js и JQuery. Шаблоны формируются на языке разметки HTML5.
В настоящее время самым часто используемым модулем обработки данных на Python является Pandas. Это библиотека, включающая в себя множество отдельных модулей поменьше, таких как Numpy. Он отвечает за матричное представление данных, операции над ячейками, с ее помощью Pandas работает с данными, приводя их к табличному виду. Типы используемых объектов: DataFrame (таблица) или DataSeries (один столбец/вектор). Таким образом объект DataFrame стал бы промежуточным звеном, между базой данных и MS Excel. При выгрузке данных был выбран встроенный по умолчанию генератор (engine = ‘xlsxwriter’). Также необходимо было перевести данный из текстового формата, в котором они изначально хранились, в численный ('strings_to_numbers') и определить формат даты ('default_date_format'). Цель заключается в том, чтобы конечный пользователь, избегая проблем с совместимостью форматов, мог использовать функционал MS Office для произвольного анализа, например, построил график суточного уровня глюкозы.
Пример кода:
writer = pd.ExcelWriter(
filename = table,
engine = 'xlsxwriter',
options = {'strings_to_numbers': True, 'default_date_format': 'dd/mm/yy'})
Следующий этап – вывести скользящее среднее. Python легко реализует математические вычисления, но зачастую неправильно определяет тип числовых данных, кодируя большим числом битов то, что могло бы весить меньше. Для наших целей это небольшая проблема, и все же было решено использовать встроенный SQL метод avg(). Это повышает читаемость кода и незначительно увеличивает скорость обработки.
Пример кода:
cur.execute('''SELECT avg(carbo), avg(prot), avg(fat)
FROM food
WHERE user_id = ?
AND date = ? ''', (session['user_id'], date[0]))
Завершающим этапом обработки данных является модель предсказания сахара после приема пищи. Постпрандиальный гликемический ответ является важной характеристикой эффективности контроля глюкозы в крови и метаболизма глюкозы у пациентов со всеми типами диабета. Клинические испытания показали важность контроля уровня глюкозы в крови после еды в пределах нормы. Модели градиентного бустинга обеспечивают эффективное решение для прогнозирования уровня глюкозы в крови после приема пищи. В предыдущем пункте мы уже обосновали выбор параметров машинного обучения, теперь просто будем называть их метриками (core_features). Для запуска модели нам необходимо получить табличный набор данных (dataset), как маску (срез слоя в таблице, функция iloc) от исходного DataFrame. Подключим модель с помощью еще одной сторонней библиотеки xgboost через load_model() и выведем результат в переменную predicred.
Пример кода:
xgboost = xgb.Booster()
xgboost.load_model(‘model.model’)
core_features = ["BG0", "gl", "carbo",
"prot_b6h", "types_food_n", "kr", "BMI"]
dataset = [tb.iloc[i, 1:7].values.tolist()]
predicted = best_model.predict(xgb.DMatrix(np.array(dataset)))
Последней разобранной задачей станет деплой приложения на сервере. В настоящее время существует множество «готовых» серверов, вроде Python Anywhere или Linode с предустановленным Python и Flask фреймворком, однако лучше использовать «чистые» сервера на Linux. К таким относятся, например, Amazon Lightsail. Они на порядок дешевле, проще в управлении, т.к. на них нет абсолютно ничего, а следовательно, нет и ограничений. Все порты подключений, кроме HTTPS (порт 443), по умолчанию открыты. Для предпросмотра приложения до основного деплоя можно провести тест работы приложения, в особенности портов почты через Heroku.