

Лаб 36 Эффективное кодирование на примере кода Хаффмана
.docxФедеральное агентство связи
Ордена Трудового Красного Знамени федеральное государственное бюджетное образовательное учреждение высшего образования
«Московский технический университет связи и информатики»
Кафедра СИТиС
Отчет по лабораторной работе №36
«Эффективное кодирование на примере кода Хаффмана»
по дисциплине «Информационные технологии»
Выполнили: студенты гр. БСТ
Проверил: асист. Комкова М. Г.
Москва, 2021 г.
Цель работы:
Изучение принципов эффективного кодирования источников дискретных сообщений.
Функциональная схема лабораторной установки:
Функциональная схема изображена на рисунке 1
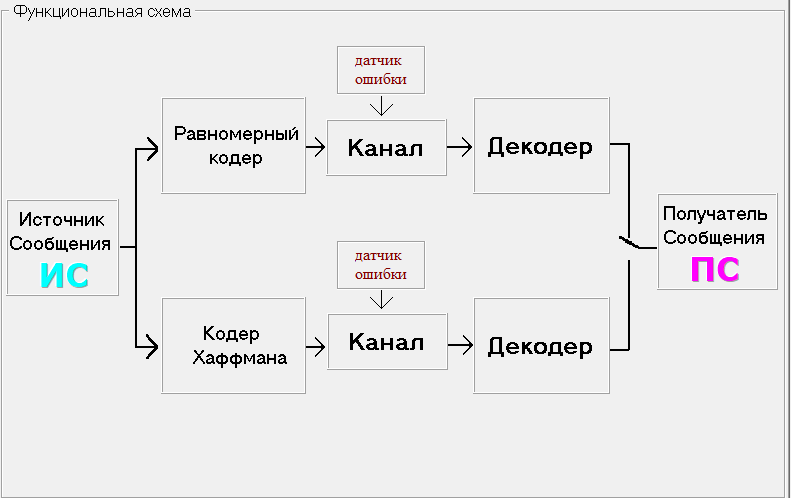
Рисунок 1- Функциональная схема
Индивидуальное задание.
Изучить принцип эффективного кодирования алфавита источника дискретных сообщений (ИДС) по методу Хаффмана.
Сформировать кодовые комбинации для передачи заданной последовательности знаков алфавита
при кодировании алфавита ИДС равномерным кодом;
при кодировании алфавита ИДС кодом Хаффмана.
Определить значения Нmax , Нреал и nсред для анализируемого варианта.
Оценить значение Коэ и Ксж.
p(z1)=0.18
p(z2)=0.14
p(z3)=0.03
p(z4)=0.24
p(z5)=0.05
p(z6)=0.36
Закодируем этот алфавит равномерным кодом.
N=6 ![]() ,
нам потребуются 3-х разрядные кодовые
комбинации.
,
нам потребуются 3-х разрядные кодовые
комбинации.
Допустим:
z1->001
z2->010
z3->011
z4->100
z5->101
z6->110
Слово алфавита z1z2z3z4z5z6 будет кодировано следующим образом:
001010011100101110
Найдем значение энтропии.
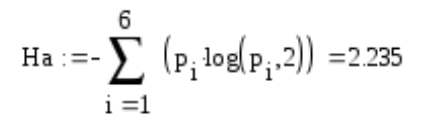
Найдем значение максимальной энтропии (при вероятности появления символа 1/N)
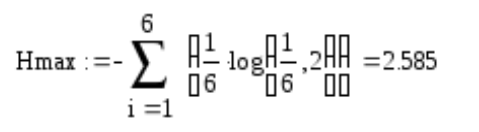
Избыточность источника равна:

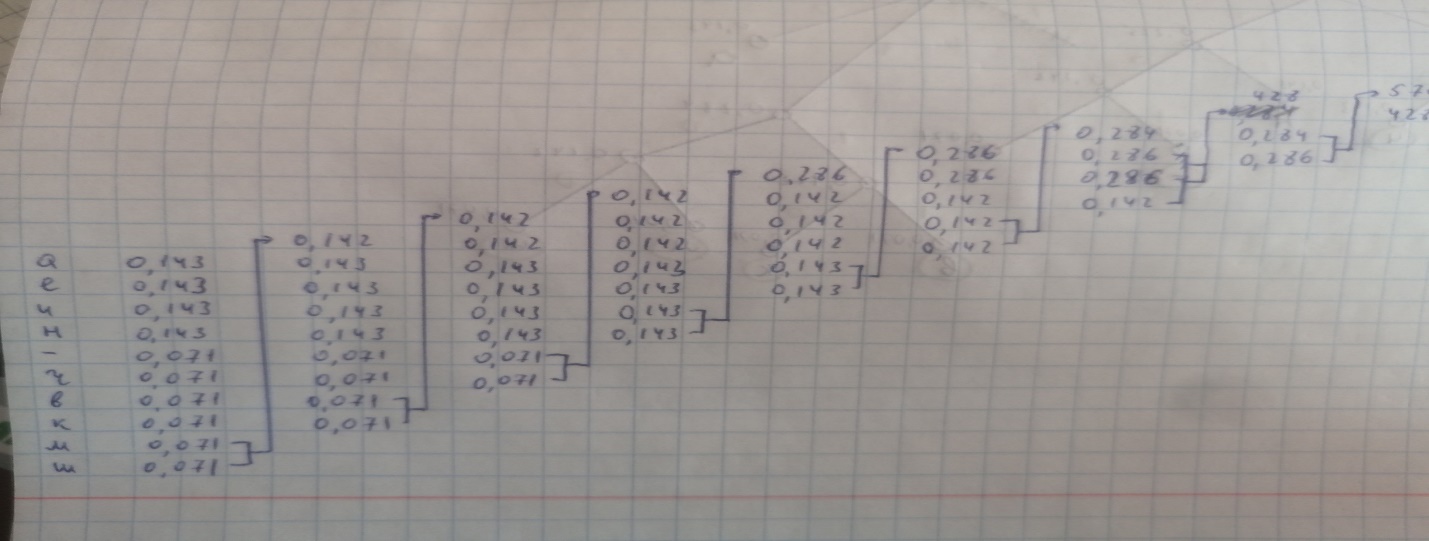
Найдем кодовые комбинации для того же алфавита по методу Хаффмана.
Построим таблицу перехода вероятностей.
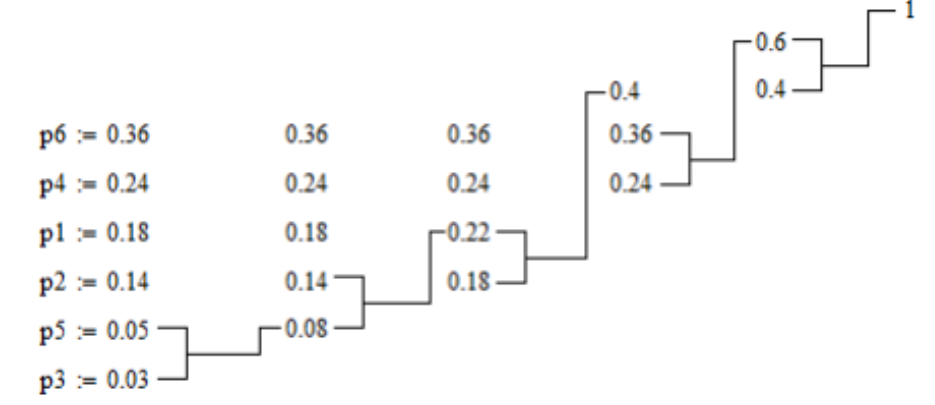
Далее построим дерево кодовых слов:
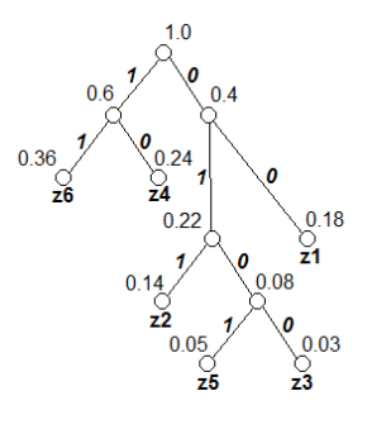
В соответствии с ним находим кодовые комбинации для каждого символа алфавита.
z1->00 n1=2
z2->011 n2=3
z3->0100 n3=4
z4->10 n4=2
z5->0101 n5=4
z6->11 n6=2
Выбранный код обладает свойством префиксности. Комбинация z1z2z3z4z5z6 кодируется:
00011010010010111
Найдем среднее число двоичных символов на знак алфавита:
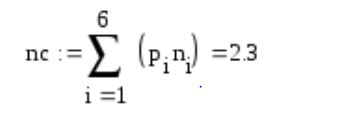
Очевидно, неравномерный код Хаффмана более компактен, чем равномерный код. Найдем коэффициенты относительной эффективности и сжатия.
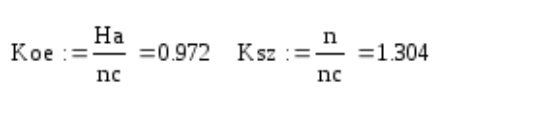
Распечатка №1. Статистика и кодирование - декодирование:
Расчет формул:
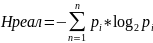
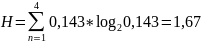
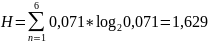
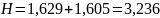

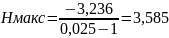
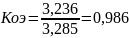
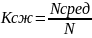

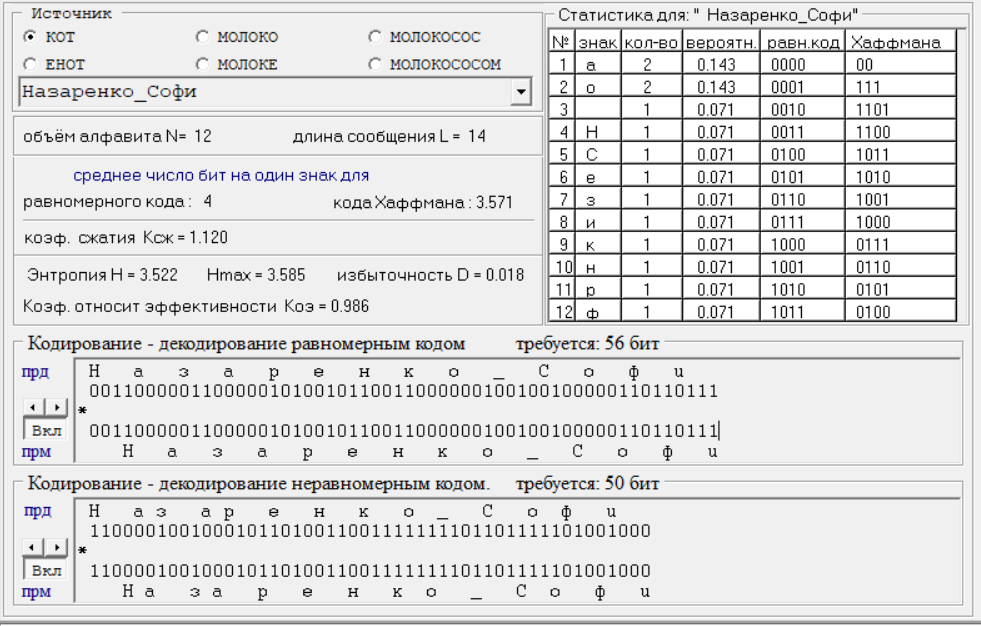
Рисунок 2 - Статистика и кодирование – декодирование
Посмотрев на рисунок выше, можно увидеть, что расчет по формулам оказался верным.
Распечатка №2 Декодирование при наличии ошибки

Рисунок 3 - Декодирование при наличии ошибки
Дерево кодовых слов для равномерного и кода Хаффмана (рис 3-4).
 Построение
кода Хаффмана для десяти знаков,
появляющихся с вероятностями выше,
иллюстрируется рисунками 3 и 4.
Построение
кода Хаффмана для десяти знаков,
появляющихся с вероятностями выше,
иллюстрируется рисунками 3 и 4.
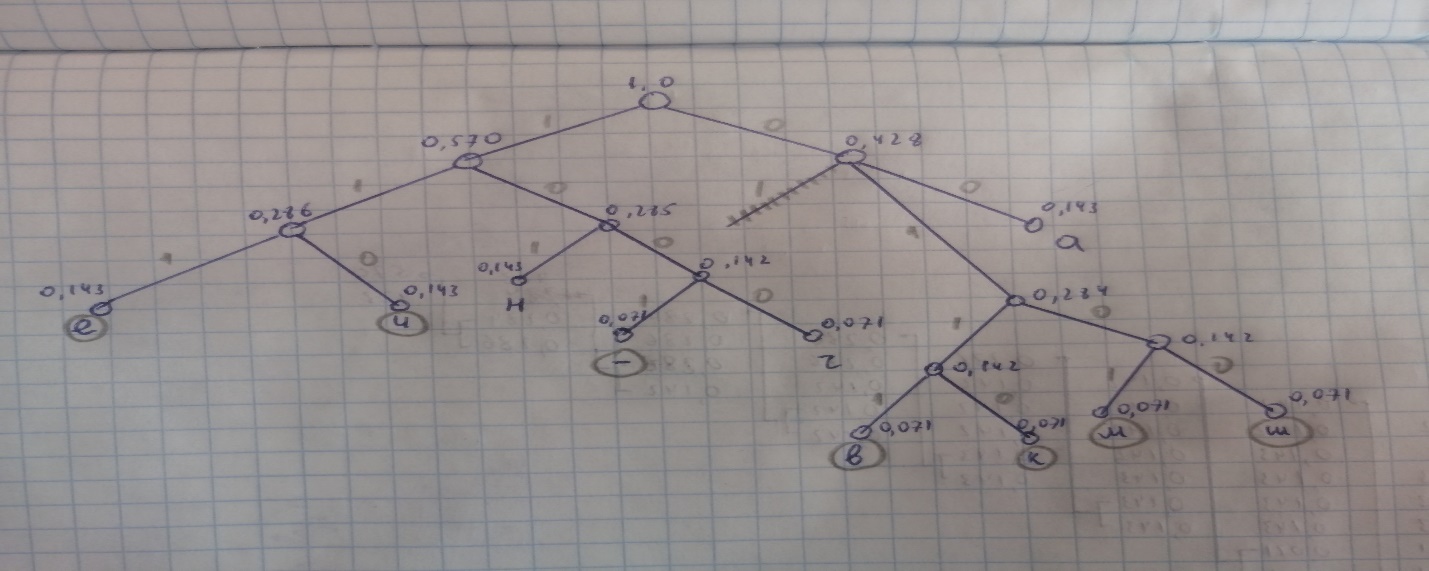
Рисунок 3-4 – Дерево кодовых слов Хаффмана
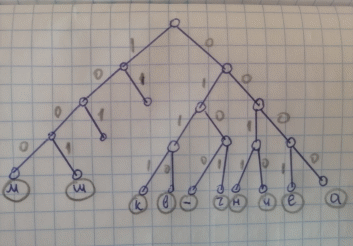 Рисунок
5 – Дерево кодовых слов для равномерного
кода
Рисунок
5 – Дерево кодовых слов для равномерного
кода
Выводы по работе:
Вывод: в ходе выполнения данной работы были изучены принципы эффективного кодирования ИДС, производились наблюдения и анализ процесса кодирования и декодирования при отсутствии ошибок и процесса декодирования при наличии ошибок.
Контрольные вопросы
Принцип построения кодовой комбинации при кодировании равномерным кодом.
Равномерный код – такой код, когда все символы какого-либо алфавита кодируются кодами одинаковой длины. Пример: Алфавит русского языка – 33 буквы, для кодирования одного символа – 6 бит. А-000000, Б-000001, ....., Я-100000
Принцип построение кодовой комбинации при кодировании неравномерным кодом.
Неравномерный код – такой код, когда все элементы какого-либо множества кодируются кодом различной длины. Общий принцип неравномерного кода: суть его в том, чтобы кодировать наиболее часто используемые элементы как можно меньшим количеством бит, так как ими вы оперируете очень часто.
Показатели количественной оценки эффективности неравномерного кодирования
Эффективность неравномерных кодов оценивается коэффициентом относительной эффективности который показывает степень использования статистической избыточности. Для оптимальных кодов Коэ=1.
![]()
Коэффициент сжатия
Коэффициент сжатия – отношение среднего числа двоичных символов, приходящихся на один знак алфавита, при кодировании заданного источника неравномерным кодом к длине кодовой комбинации в случае кодирования источника равномерным кодом
Принцип декодирования последовательности префиксного кода.
При декодировании последовательности комбинаций префиксного кода определение кода каждого знака производится однозначно. В противном случае, т.е. для комбинаций непрефиксного кода характерна неоднозначность декодирования.
Пусть, например, некоторый код удовлетворяет требованию префиксности, т.е. знакам алфавита соответствуют кодовые комбинации вида: А-00 Б-01 B-101 Г-100.
Составим произвольно комбинацию передаваемых знаков алфавита и соответствующую ей кодовую последовательность:
БАБВГВГЕГААБ.
01000110110010101100000001.()
Эта последовательность декодируется однозначно:
01 00 01 101 100 101 01 100 00 00 01
Б А Б В Г В Б Г А А Б
Рассмотрим другой случай, когда кодирование ансамбля знаков проведено по кодовой таблице вида
А-00; Б-01; В-001; Г-010.
+Тогда последовательность кодовых комбинаций того же сообщения будет иметь вид
01000100101000101010000001.
В этом случае возможны различные варианты декодирования:
01 00 01 001 01 00 01 01 010 00 00 01
Б А Б В Б А Б Б Г А А Б
или
010 001 001 010 001 01 010 00 00 01
Г В В Г В Б Г А А Б