

ТСП_1ЛР_В5
.docxМИНОБРНАУКИ РОССИИ
Санкт-Петербургский государственный
электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
Кафедра биотехнических систем
отчет
по лабораторной работе №1
по дисциплине «Теория случайных процессов»
Тема: «Моделирование непрерывных и дискретных случайных величин»
Вариант 5
Студентки гр. 9502 |
|
Камышанова О.А. Изланова А.Е. Позняк В.Ю. |
Преподаватель |
|
Скоробогатова А.И. |
Санкт-Петербург
2021
Цель работы: получить знание о генераторах случайных величин и их практической реализации, работа также закрепляет практические навыки применения теории вероятностей и основ статистического анализа.
Основные теоретические сведения.
Для генерации НСВ необходимо использовать метод обратных функций, который заключается в том, что необходимо найти функцию F-1, обратную заданной функции распределения F, после чего подставить в полученную функцию F-1 выборку значений Z, сгенерированных по нормальному закону. На выходе мы получим множество значений F-1(Z), которые будут распределены по заданному закону F.
Для задание ДСВ удобно интервал [0,1] разделить на подынтервалы длинами рi, а затем задать выборку нормированных значений Z, тогда эти значения Z будут задавать вероятность выпадения P для каждого Xi значения заданной ДСВ. Необходимо будет соотнести по значению Z к какому интервалу рi будет относиться наш элемент Xi, затем элемент Xi можно «восстановить» по значению его вероятности.
Точечная оценка математического ожидания рассчитывается с помощью следующей формулы:
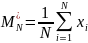
Точечная оценка дисперсии может быть
рассчитана следующим образом:
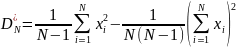
Нахождения интервальной оценки среднего:

Где
 – выборочная дисперсия;
– выборочная дисперсия;
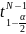 – коэффициент Стьюдента для
– коэффициент Стьюдента для
 степеней свободы и уровня значимости
степеней свободы и уровня значимости
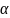 .
.
Для нахождения интервальной оценки дисперсии:
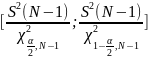
Где
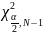 – коэффициент хи-квадрат для
степеней свободы и уровня значимости
.
– коэффициент хи-квадрат для
степеней свободы и уровня значимости
.
Для оценки выборочной дисперсии можно
использовать следующую формулу: 
clear all close all syms x; f = 1.5 * x^(1/2); F = int (f, [0 x]); x1 = rand([50 1]); x2 = rand([200 1]); x3 = rand([1000 1]); s1 = x1.^(2/3); s2 = x2.^(2/3); s3 = x3.^(2/3); N1=x1*1; N2=x2*1; N3=x3*1; %Расчет среднего, дисперсии, СКО SR(1,1)=sum(N1)/length(N1); SR(2,1)=sum(N2)/length(N2); SR(3,1)=sum(N3)/length(N3); DISP(1,1)=var(N1); DISP(2,1)=var(N2); DISP(3,1)=var(N3); SKO(1,1)=std(N1); SKO(2,1)=std(N2); SKO(3,1)=std(N3); MAT(1,1)=mean(N1); MAT(2,1)=mean(N2); MAT(3,1)=mean(N3); %Уровни значимости a(1,1)=0.1; a(2,1)=0.05; a(3,1)=0.01; %Коэффициенты Стьюдента %альфа 0,1 St1(1,1)=tinv(0.9,49); St1(2,1)=tinv(0.9,199); St1(3,1)=tinv(0.9,999); %альфа 0,05 St1(1,2)=tinv(.95,49); St1(2,2)=tinv(.95,199); St1(3,2)=tinv(.95,999); %альфа 0,01 St1(1,3)=tinv(0.99,49); St1(2,3)=tinv(0.99,199); St1(3,3)=tinv(0.99,999); %Интервалы для дисперсии %верх граница для n=50 HiIntD(1,1)=(S1*49)/Hi2Hi(1,1); HiIntD(2,1)=(S1*49)/Hi2Hi(1,2); HiIntD(3,1)=(S1*49)/Hi2Hi(1,3); %верх граница для n=200 HiIntD(1,2)=(S2*199)/Hi2Hi(2,1); HiIntD(2,2)=(S2*199)/Hi2Hi(2,2); HiIntD(3,2)=(S2*199)/Hi2Hi(2,3); %верх граница для n=1000 HiIntD(1,3)=(S3*999)/Hi2Hi(3,1); HiIntD(2,3)=(S3*999)/Hi2Hi(3,2); HiIntD(3,3)=(S3*999)/Hi2Hi(3,3); %НИЖН граница для n=50 DoIntD(1,1)=(S1*49)/Hi2Do(1,1); DoIntD(2,1)=(S1*49)/Hi2Do(1,2); DoIntD(3,1)=(S1*49)/Hi2Do(1,3); %нижн граница для n=200 DoIntD(1,2)=(S2*199)/Hi2Do(2,1); DoIntD(2,2)=(S2*199)/Hi2Do(2,2); DoIntD(3,2)=(S2*199)/Hi2Do(2,3); %нижн граница для n=1000 DoIntD(1,3)=(S3*999)/Hi2Do(3,1); DoIntD(2,3)=(S3*999)/Hi2Do(3,2); DoIntD(3,3)=(S3*999)/Hi2Do(3,3); %Границы среднего %верхн граница для n=50 HiIntSr(1,1)=MAT(1,1)+St1(1,1)*sqrt(S1/49); HiIntSr(2,1)=MAT(1,1)+St1(2,1)*sqrt(S1/49); HiIntSr(3,1)=MAT(1,1)+St1(3,1)*sqrt(S1/49); %верхн граница для n=200 HiIntSr(1,2)=MAT(2,1)+St1(1,2)*sqrt(S2/199); HiIntSr(2,2)=MAT(2,1)+St1(2,2)*sqrt(S2/199); HiIntSr(3,2)=MAT(2,1)+St1(3,2)*sqrt(S2/199);
%верхн граница для n=1000 HiIntSr(1,3)=MAT(3,1)+St1(1,3)*sqrt(S3/999); HiIntSr(2,3)=MAT(3,1)+St1(2,3)*sqrt(S3/999); HiIntSr(3,3)=MAT(3,1)+St1(3,3)*sqrt(S3/999); %нижн граница для n=50 DoIntSr(1,1)=MAT(1,1)-St1(1,1)*sqrt(S1/49); DoIntSr(2,1)=MAT(1,1)-St1(2,1)*sqrt(S1/49); DoIntSr(3,1)=MAT(1,1)-St1(3,1)*sqrt(S1/49); |
%Хи-квадрат(верхняя граница) %альфа 0,1 Hi2Hi(1,1)=chi2inv(0.95,49); Hi2Hi(2,1)=chi2inv(0.95,199); Hi2Hi(3,1)=chi2inv(0.95,999); %альфа 0,05 Hi2Hi(1,2)=chi2inv(.975,49); Hi2Hi(2,2)=chi2inv(.975,199); Hi2Hi(3,2)=chi2inv(.975,999); %альфа 0,01 Hi2Hi(1,3)=chi2inv(0.995,49); Hi2Hi(2,3)=chi2inv(0.995,199); Hi2Hi(3,3)=chi2inv(0.995,999); %Хи=квадрат(нижняя граница) %альфа 0,1 Hi2Do(1,1)=chi2inv(0.05,49); Hi2Do(2,1)=chi2inv(0.05,199); Hi2Do(3,1)=chi2inv(0.05,999); %альфа 0,05 Hi2Do(1,2)=chi2inv(.025,49); Hi2Do(2,2)=chi2inv(.025,199); Hi2Do(3,2)=chi2inv(.025,999); %альфа 0,01 Hi2Do(1,3)=chi2inv(0.005,49); Hi2Do(2,3)=chi2inv(0.005,199); Hi2Do(3,3)=chi2inv(0.005,999); %Выборочная дисперсия i=1:50; S1=sum((x1(i,1)-MAT(1,1)).^2)./49; i=1:200; S2=sum((x2(i,1)-MAT(2,1)).^2)./199; i=1:1000; S3=sum((x3(i,1)-MAT(3,1)).^2)./999;
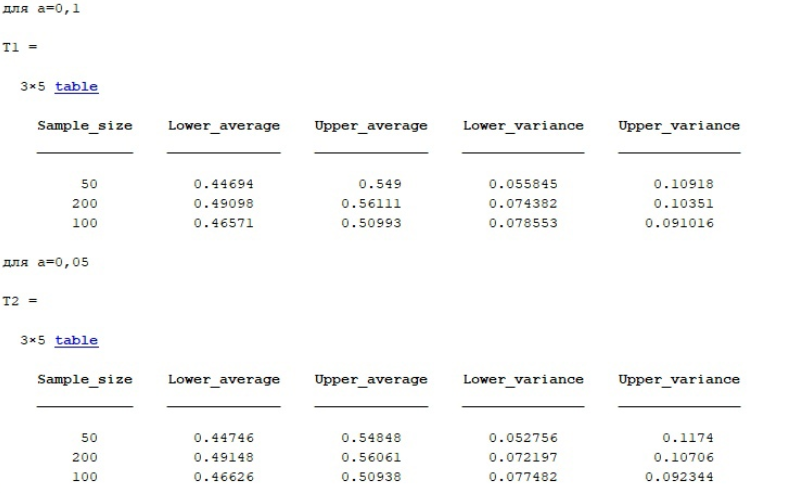
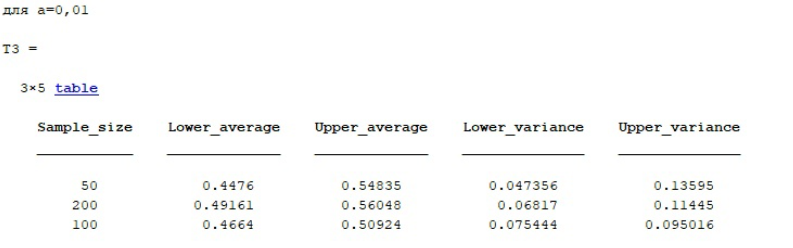
%нижн граница для n=200 DoIntSr(1,2)=MAT(2,1)-St1(1,2)*sqrt(S2/199); DoIntSr(2,2)=MAT(2,1)-St1(2,2)*sqrt(S2/199); DoIntSr(3,2)=MAT(2,1)-St1(3,2)*sqrt(S2/199); %нижн граница для n=1000 DoIntSr(1,3)=MAT(3,1)-St1(1,3)*sqrt(S3/999); DoIntSr(2,3)=MAT(3,1)-St1(2,3)*sqrt(S3/999); DoIntSr(3,3)=MAT(3,1)-St1(3,3)*sqrt(S3/999); %Таблица для 0,1 name=sprintf('для а=0,1'); disp(name); Sample_size=[50;200;100]; Lower_average=[DoIntSr(1,1);DoIntSr(1,2);DoIntSr(1,3)]; Upper_average=[HiIntSr(1,1);HiIntSr(1,2);HiIntSr(1,3)]; Lower_variance=[HiIntD(1,1);HiIntD(1,2);HiIntD(1,3)]; Upper_variance=[DoIntD(1,1);DoIntD(1,2);DoIntD(1,3)]; T1 = table(Sample_size,Lower_average,Upper_average,Lower_variance,Upper_variance) %Таблица для 0,05 name=sprintf('для а=0,05'); disp(name); Sample_size=[50;200;100]; Lower_average=[DoIntSr(2,1);DoIntSr(2,2);DoIntSr(2,3)]; Upper_average=[HiIntSr(2,1);HiIntSr(2,2);HiIntSr(2,3)]; Lower_variance=[HiIntD(2,1);HiIntD(2,2);HiIntD(2,3)]; Upper_variance=[DoIntD(2,1);DoIntD(2,2);DoIntD(2,3)]; T2 = table(Sample_size,Lower_average,Upper_average,Lower_variance,Upper_variance) %Таблица для 0,01 name=sprintf('для а=0,01'); disp(name); Sample_size=[50;200;100]; Lower_average=[DoIntSr(3,1);DoIntSr(3,2);DoIntSr(3,3)]; Upper_average=[HiIntSr(3,1);HiIntSr(3,2);HiIntSr(3,3)]; Lower_variance=[HiIntD(3,1);HiIntD(3,2);HiIntD(3,3)] Upper_variance=[DoIntD(3,1);DoIntD(3,2);DoIntD(3,3)]; T3 = table(Sample_size,Lower_average,Upper_average,Lower_variance,Upper_variance) %формула Стерджесса (расчет кол-ва интервалов) nd1 = ceil( 1 + 3.322*log10(length(x1)) ); nd2= ceil( 1 + 3.322*log10(length(x2)) ); nd3= ceil( 1 + 3.322*log10(length(x3)) ); %вывод гистограмм figure(1) subplot(2,3,1) t1 = 0:1/(fix(1+3.322*log10(length(s1)))-1):1; c1 = hist(s1,fix(1+3.322*log10(length(s1))))/length(s1)/(t1(2)-t1(1)); bar(t1,c1); %постройка поверх графика hold on fplot (f,[0 1], 'linewidth', 2) % continueworking subplot(2,3,2) t2 = 0:1/(fix(1+3.322*log10(length(s2)))-1):1; c2 = hist(s2,fix(1+3.322*log10(length(s2))))/length(s2)/(t2(2)-t2(1)); bar(t2,c2); %постройка поверх графика hold on fplot (f,[0 1], 'linewidth', 2) %histogram(s2,round(1+3.322*log10(length(s2)))) subplot(2,3,3) t3 = 0:1/(fix(1+3.322*log10(length(s3)))-1):1; c3 = hist(s3,fix(1+3.322*log10(length(s3))))/length(s3)/(t3(2)-t3(1)); bar(t3,c3); hold on fplot (f,[0 1], 'linewidth', 2) %histogram(s3,round(1+3.322*log10(length(s3)))) %grapphics subplot(2,3,4) fplot(f,[0 1],'g','linewidth',3); hold on fplot(0, [1 3],'g','linewidth',3); hold on fplot(F,[0 1],'r', 'linewidth',2); hold on fplot(1, [1 3],'r', 'linewidth',2); |
Генерирование дискретных случайных величин
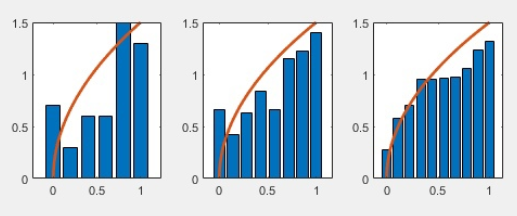
Рис 1. Гистограмма и теоретически полученная плотность вероятности для непрерывной случайной величины
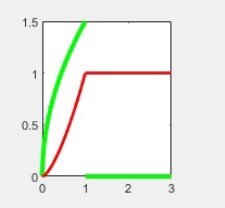
Рис.2 График распределения вероятности (красным), график плотности распределения вероятности (зеленым).
Непрерывно распределенная случайная величина:
clc; clear all; close all; k = 0:1:29; P = (1-0.1)*0.1.^k; x1 = rand([1 50]); x2 = rand([1 200]); x3 = rand([1 1000]); counter = 0; for j = 1:50 for i = 1:29 if ((P(i+1) < x1(j)) && (x1(j) <= P(i))) counter = counter + 1; Elm_in_interval_1(counter) = i - 1; break elseif x1(j) <= P(30) Elm_in_interval_1(counter) = 29; elseif x1(j) > 0.9 break end end end counter = 0; for j = 1:200 for i = 1:29 if ((P(i+1) < x2(j)) && (x2(j) <= P(i))) counter = counter + 1; Elm_in_interval_2(counter) = i - 1; break elseif x2(j) <= P(30) Elm_in_interval_2(counter) = 29; elseif x2(j) > 0.9 break end end end counter = 0; for j = 1:1000 for i = 1:29 if ((P(i+1) < x3(j)) && (x3(j) <= P(i))) counter = counter + 1; Elm_in_interval_3(counter) = i - 1; break elseif x3(j) <= P(30) Elm_in_interval_3(counter) = 29; elseif x3(j) > 0.9 break end end end %Хи=квадрат(нижняя граница) %альфа 0,1 Hi2Do(1,1)=chi2inv(0.05,49); Hi2Do(2,1)=chi2inv(0.05,199); Hi2Do(3,1)=chi2inv(0.05,999); %альфа 0,05 Hi2Do(1,2)=chi2inv(.025,49); Hi2Do(2,2)=chi2inv(.025,199); Hi2Do(3,2)=chi2inv(.025,999); %альфа 0,01 Hi2Do(1,3)=chi2inv(0.005,49); Hi2Do(2,3)=chi2inv(0.005,199); Hi2Do(3,3)=chi2inv(0.005,999); %Выборочная дисперсия i=1:50; S1=sum((x1(1,i)-MAT(1,1)).^2)./49; i=1:200; S2=sum((x2(1,i)-MAT(2,1)).^2)./199; i=1:1000; S3=sum((x3(1,i)-MAT(3,1)).^2)./999; %Интервалы для дисперсии %верх граница для n=50 HiIntD(1,1)=(S1*49)/Hi2Hi(1,1); HiIntD(2,1)=(S1*49)/Hi2Hi(1,2); HiIntD(3,1)=(S1*49)/Hi2Hi(1,3); %верх граница для n=200 HiIntD(1,2)=(S2*199)/Hi2Hi(2,1); HiIntD(2,2)=(S2*199)/Hi2Hi(2,2); HiIntD(3,2)=(S2*199)/Hi2Hi(2,3); %верх граница для n=1000 HiIntD(1,3)=(S3*999)/Hi2Hi(3,1); HiIntD(2,3)=(S3*999)/Hi2Hi(3,2); HiIntD(3,3)=(S3*999)/Hi2Hi(3,3); %НИЖН граница для n=50 DoIntD(1,1)=(S1*49)/Hi2Do(1,1); DoIntD(2,1)=(S1*49)/Hi2Do(1,2); DoIntD(3,1)=(S1*49)/Hi2Do(1,3); %нижн граница для n=200 DoIntD(1,2)=(S2*199)/Hi2Do(2,1); DoIntD(2,2)=(S2*199)/Hi2Do(2,2); DoIntD(3,2)=(S2*199)/Hi2Do(2,3); %нижн граница для n=1000 DoIntD(1,3)=(S3*999)/Hi2Do(3,1); DoIntD(2,3)=(S3*999)/Hi2Do(3,2); DoIntD(3,3)=(S3*999)/Hi2Do(3,3); %Таблица для 0,01 name=sprintf('для а=0,01'); disp(name); Sample_size=[50;200;100]; Lower_average=[DoIntSr(3,1);DoIntSr(3,2);DoIntSr(3,3)]; Upper_average=[HiIntSr(3,1);HiIntSr(3,2);HiIntSr(3,3)]; Lower_variance=[HiIntD(3,1);HiIntD(3,2);HiIntD(3,3)]; Upper_variance=[DoIntD(3,1);DoIntD(3,2);DoIntD(3,3)]; T3 = table(Sample_size,Lower_average,Upper_average,Lower_variance,Upper_variance)
|
%Расчёт тотечных оценок %Расчет среднего, дисперсии, СКО SR(1,1)=sum(x1)/length(x1); SR(2,1)=sum(x2)/length(x2); SR(3,1)=sum(x3)/length(x3); DISP(1,1)=var(x1); DISP(2,1)=var(x2); DISP(3,1)=var(x3); SKO(1,1)=std(x1); SKO(2,1)=std(x2); SKO(3,1)=std(x3); MAT(1,1)=mean(x1); MAT(2,1)=mean(x2); MAT(3,1)=mean(x3); %Уровни значимости a(1,1)=0.1; a(2,1)=0.05; a(3,1)=0.01; %Коэффициенты Стьюдента %альфа 0,1 St1(1,1)=tinv(0.9,49); St1(2,1)=tinv(0.9,199); St1(3,1)=tinv(0.9,999); %альфа 0,05 St1(1,2)=tinv(.95,49); St1(2,2)=tinv(.95,199); St1(3,2)=tinv(.95,999); %альфа 0,01 St1(1,3)=tinv(0.99,49); St1(2,3)=tinv(0.99,199); St1(3,3)=tinv(0.99,999); %Хи-квадрат(верхняя граница) %альфа 0,1 Hi2Hi(1,1)=chi2inv(0.95,49); Hi2Hi(2,1)=chi2inv(0.95,199); Hi2Hi(3,1)=chi2inv(0.95,999); %альфа 0,05 Hi2Hi(1,2)=chi2inv(.975,49); Hi2Hi(2,2)=chi2inv(.975,199); Hi2Hi(3,2)=chi2inv(.975,999); %альфа 0,01 Hi2Hi(1,3)=chi2inv(0.995,49); Hi2Hi(2,3)=chi2inv(0.995,199); Hi2Hi(3,3)=chi2inv(0.995,999);
%Границы среднего %верхн граница для n=50 HiIntSr(1,1)=MAT(1,1)+St1(1,1)*sqrt(S1/49); HiIntSr(2,1)=MAT(1,1)+St1(2,1)*sqrt(S1/49); HiIntSr(3,1)=MAT(1,1)+St1(3,1)*sqrt(S1/49); %верхн граница для n=200 HiIntSr(1,2)=MAT(2,1)+St1(1,2)*sqrt(S2/199); HiIntSr(2,2)=MAT(2,1)+St1(2,2)*sqrt(S2/199); HiIntSr(3,2)=MAT(2,1)+St1(3,2)*sqrt(S2/199); %верхн граница для n=1000 HiIntSr(1,3)=MAT(3,1)+St1(1,3)*sqrt(S3/999); HiIntSr(2,3)=MAT(3,1)+St1(2,3)*sqrt(S3/999); HiIntSr(3,3)=MAT(3,1)+St1(3,3)*sqrt(S3/999); %нижн граница для n=50 DoIntSr(1,1)=MAT(1,1)-St1(1,1)*sqrt(S1/49); DoIntSr(2,1)=MAT(1,1)-St1(2,1)*sqrt(S1/49); DoIntSr(3,1)=MAT(1,1)-St1(3,1)*sqrt(S1/49); %нижн граница для n=200 DoIntSr(1,2)=MAT(2,1)-St1(1,2)*sqrt(S2/199); DoIntSr(2,2)=MAT(2,1)-St1(2,2)*sqrt(S2/199); DoIntSr(3,2)=MAT(2,1)-St1(3,2)*sqrt(S2/199); %нижн граница для n=1000 DoIntSr(1,3)=MAT(3,1)-St1(1,3)*sqrt(S3/999); DoIntSr(2,3)=MAT(3,1)-St1(2,3)*sqrt(S3/999); DoIntSr(3,3)=MAT(3,1)-St1(3,3)*sqrt(S3/999); %Таблица для 0,1 name=sprintf('для а=0,1'); disp(name); Sample_size=[50;200;100]; Lower_average=[DoIntSr(1,1);DoIntSr(1,2);DoIntSr(1,3)]; Upper_average=[HiIntSr(1,1);HiIntSr(1,2);HiIntSr(1,3)]; Lower_variance=[HiIntD(1,1);HiIntD(1,2);HiIntD(1,3)]; Upper_variance=[DoIntD(1,1);DoIntD(1,2);DoIntD(1,3)]; T1 = table(Sample_size,Lower_average,Upper_average,Lower_variance,Upper_variance)
%Таблица для 0,05 name=sprintf('для а=0,05'); disp(name); Sample_size=[50;200;100]; Lower_average=[DoIntSr(2,1);DoIntSr(2,2);DoIntSr(2,3)]; Upper_average=[HiIntSr(2,1);HiIntSr(2,2);HiIntSr(2,3)]; Lower_variance=[HiIntD(2,1);HiIntD(2,2);HiIntD(2,3)]; Upper_variance=[DoIntD(2,1);DoIntD(2,2);DoIntD(2,3)]; T2 = table(Sample_size,Lower_average,Upper_average,Lower_variance,Upper_variance)
syms x; f = (1-0.1)*0.1^x; figure(1) subplot(2,3,1) c1 = hist(Elm_in_interval_1,k); bar(k,c1/length(x1)); %постройка поверх графика hold on subplot(2,3,2) c2 = hist(Elm_in_interval_2,k); bar(k,c2/length(x2)); %постройка поверх графика hold on subplot(2,3,3) c3 = hist(Elm_in_interval_3,k); bar(k,c3/length(x3)); hold on subplot (2,3,5) bar(P); |
Дискретно распределённая случайная величина:
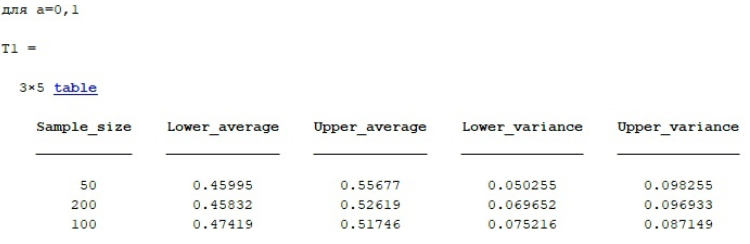
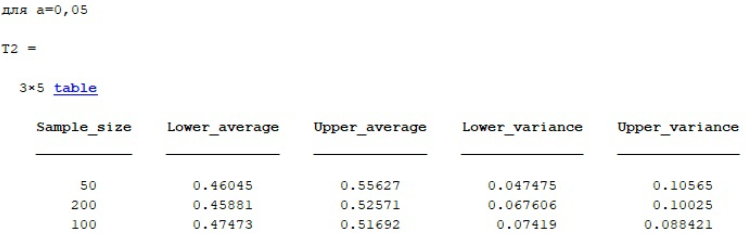
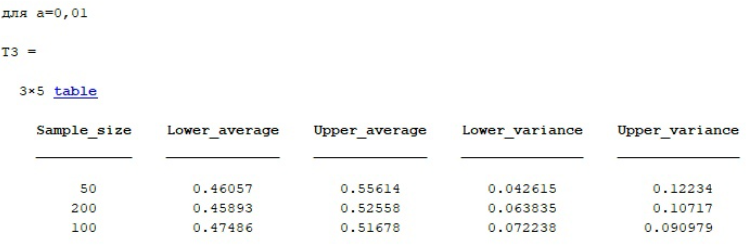
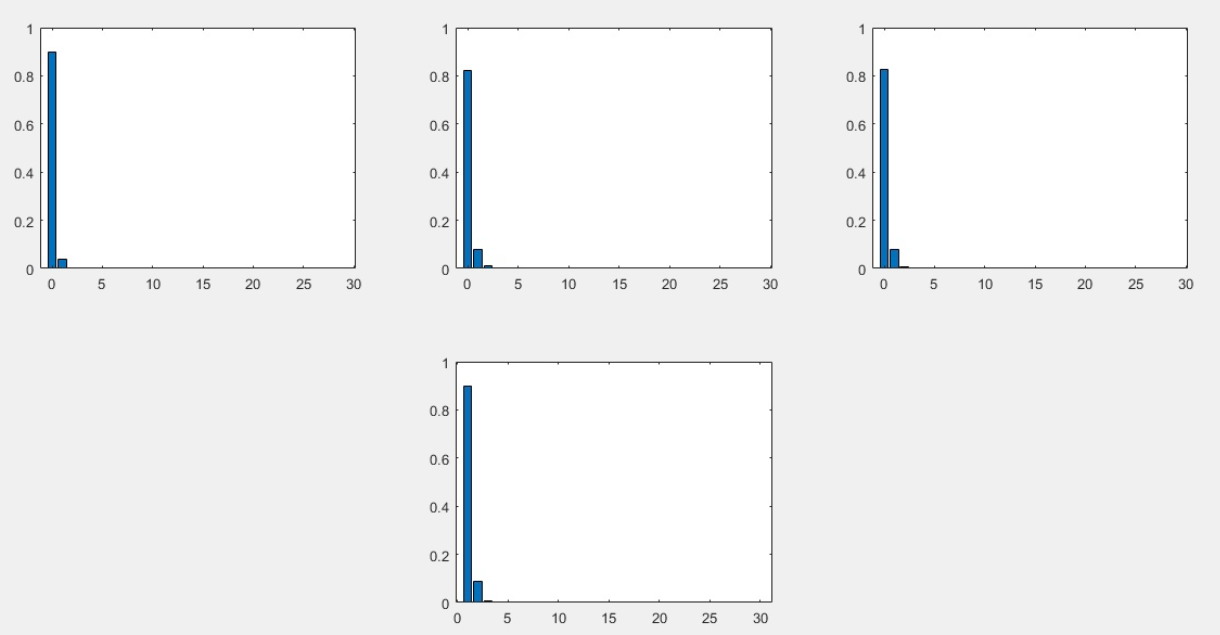
Рис. 3 Теоретический и экспериментальный законы распределения для дискретной случайной величины.
Вывод: в ходе лабораторной работы были получены знание о генераторах случайных величин и их практической реализации. Были закреплены практические навыки применения теории вероятностей и основ статистического анализа. Были реализованы генераторы непрерывной СВ и дискретной СВ.
Для ряда сгенерированных выборок были рассчитаны точечные оценки дисперсии, мат. ожидания и СКО и интервальные оценки среднего и дисперсии для различных уровней значимости, данные сведены в таблицу и указаны в отчете.
Для НСВ и ДСВ были построены гистограммы и сравнены с теоретическими значениями, были построены графики распределения вероятностей, графики плотности распределения вероятностей.