

272 |
Chapter 6 Data Types |
location(a[i, j]) = address of a[row_lb, col_lb]
-(((row_lb * n) + col_lb) * element_size)
+(((i * n) + j) * element_size)
where the first two terms are the constant part and the last is the variable part. This can be generalized relatively easily to an arbitrary number of dimensions.
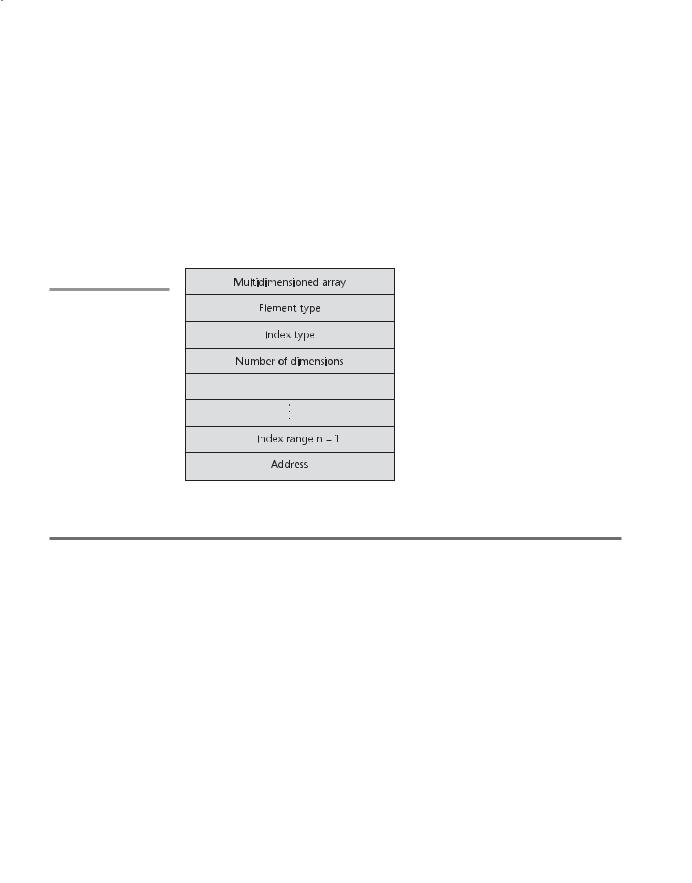
For each dimension of an array, one add and one multiply instruction are required for the access function. Therefore, accesses to elements of arrays with several subscripts are costly. The compile-time descriptor for a multidimensional array is shown in Figure 6.6.
Figure 6.6
A compile-time descriptor for a multidimensional array




 0
0
6.6 Associative Arrays
An associative array is an unordered collection of data elements that are indexed by an equal number of values called keys. In the case of non-associative arrays, the indices never need to be stored (because of their regularity). In an associative array, however, the user-defined keys must be stored in the structure. So each element of an associative array is in fact a pair of entities, a key and a value. We use Perl’s design of associative arrays to illustrate this data structure. Associative arrays are also supported directly by Python, Ruby, and Lua and by the standard class libraries of Java, C++, C#, and F#.
The only design issue that is specific for associative arrays is the form of references to their elements.
6.6.1Structure and Operations
In Perl, associative arrays are called hashes, because in the implementation their elements are stored and retrieved with hash functions. The namespace for Perl hashes is distinct: Every hash variable name must begin with a percent sign (%). Each hash element consists of two parts: a key, which is a string, and

6.6 Associative Arrays |
273 |
a value, which is a scalar (number, string, or reference). Hashes can be set to literal values with the assignment statement, as in
%salaries = ("Gary" => 75000, "Perry" => 57000,
"Mary" => 55750, "Cedric" => 47850);
Individual element values are referenced using notation that is similar to that used for Perl arrays. The key value is placed in braces and the hash name is replaced by a scalar variable name that is the same except for the first character. Although hashes are not scalars, the value parts of hash elements are scalars, so references to hash element values use scalar names. Recall that scalar variable names begin with dollar signs ($). For example,
$salaries{"Perry"} = 58850;
A new element is added using the same assignment statement form. An element can be removed from the hash with the delete operator, as in
delete $salaries{"Gary"};
The entire hash can be emptied by assigning the empty literal to it, as in
@salaries = ();
The size of a Perl hash is dynamic: It grows when an element is added and shrinks when an element is deleted, and also when it is emptied by assignment of the empty literal. The exists operator returns true or false, depending on whether its operand key is an element in the hash. For example,
if (exists $salaries{"Shelly"}) . . .
The keys operator, when applied to a hash, returns an array of the keys of the hash. The values operator does the same for the values of the hash. The each operator iterates over the element pairs of a hash.
Python’s associative arrays, which are called dictionaries, are similar to those of Perl, except the values are all references to objects. The associative arrays supported by Ruby are similar to those of Python, except that the keys can be any object,6 rather than just strings. There is a progression from Perl’s hashes, in which the keys must be strings, to PHP’s arrays, in which the keys can be integers or strings, to Ruby’s hashes, in which any type object can be a key.
PHP’s arrays are both normal arrays and associative arrays. They can be treated as either. The language provides functions that allow both indexed and
6.Objects that change do not make good keys, because the changes could change the hash function value. Therefore, arrays and hashes are never used as keys.
inter view
Lua
R O B E R T O I E R U S A L I M S C H Y
Roberto Ierusalimschy is one of the creators of the scripting language Lua, which is used widely in game development and embedded systems applications. He is an associate professor in the Department of Computer Science at Pontifícia Universidade Católica do Rio de Janeiro in Brazil. (For more information about Lua, visit www.lua.org.)
How and where did you first become involved with computing? Before I entered college in 1978, I had no idea about computing. I remember that I tried to read a book on programming in Fortran but did not pass the initial chapter on definitions for variables and constants.
In my first year in college I took a Programming 101 course in Fortran. At that time we ran our programming assignments in an IBM 370 mainframe. We had to punch cards with our code, surround the deck with some fixed JCL cards and give it to an operator. Some time later (often a few hours) we got a listing with the results, which frequently were only compiler errors.
Soon after that a friend of mine brought from abroad a microcomputer, a Z80 CPU with 4K bytes of memory. We started to do all kinds of programs for this machine, all in assembly—or, more exactly, in machine code, as it did not have an assembler. We wrote our programs in assembly, then translated them by hand to hexadecimal to enter them into memory to run.
Since then I was hooked.
There have been few successful programming languages designed in academic environments in the last 25 years. Although you are an academic, Lua was designed for very practical applications. Do you consider Lua an academic or an industrial language? Lua is certainly an industrial language, but with an academic “accent.” Lua was created for two industrial applications, and it has been used in industrial applications all its life. We tried to be very pragmatic on its design. However, except for its first version, we were never under the typical pressure from an industrial environment. We always had the luxury of choosing when to release a new version or of choosing whether to accept user demands.That gave us some latitude that other languages have not enjoyed.
More recently, we have done some academic research with Lua. But it is a long process to merge these academic results into the official distribution; more often than not these results have little direct impact on Lua. Nevertheless, there have been some nice exceptions, such as the register-based virtual machine and “ephemeron tables” (to appear in Lua 5.2).
You have said Lua was raised, rather than designed. Can you comment on what you meant and what you think are the benefits of this approach? We meant that most important pieces of Lua were not present in its first version. The language started as a very small and simple language and got several of its relevant features as it evolved.
Before talking about the benefits (and the drawbacks) of this approach, let me make it clear that we did not choose that approach. We never thought, “let us grow a new language.” It just happened.
I guess that a most difficult part when designing a language is to foresee how different mechanisms will interact in daily use. By raising a language—that is, creating it piece by piece—you may avoid most of those interaction problems, as you can think about each new feature only after the rest of the language is in place and has been tested by real users in real applications.
Of course, this approach has a major drawback, too: You may arrive at a point where a most-needed new feature is incompatible with what you already have in place.
Lua has changed in a variety of ways since it was first released in 1994. You have said that there have been times when you regretted not including a Boolean type in Lua. Why didn’t you simply add one? This may sound funny, but what we really missed was the value “false”; we had no use for a “true” value.
274

Like the original LISP, Lua treated nil as false and everything else as true. The problem is that nil also represents an unitialized variable. There was no way to distinguish between an unitialized variable from a false variable. So, we needed a false value, to make that distinction possible. But the true value was useless; a 1 or any other constant was good enough.
I guess this is a typical example where our “industrial” mind conflicted with our “academic” mind. A really pragmatic mind would add the Boolean type without thinking twice. But our academic mind was upset by this inelegance. In the end the pragmatic side won, but it took some time.
What were the most important Lua features, other than the preprocessor, that later became recognized as misfeatures and were removed from the language? I do not remember other big misfeatures. We did remove several features from Lua, but mostly because they were superseded by a new, usually “better” in some sense, feature. This happened with tag methods (superseded by metamethods), weak references in the C API (superseded by weak tables), and upvalues (superseded by proper lexical scoping).
When a new feature for Lua that would break backward compatibility is considered, how is that decision made? These are always hard decisions. First, we try to find some other format that could avoid or at least reduce the incompatibility. If that is not possible, we try to provide easy ways around the incompatibility. (For instance, if we remove a function from the core library we may provide a separated implementation that the programmer may incorporate into her code.) Also, we try to measure how difficult it will be to detect and correct the incompatibility. If the new feature creates syntax errors (e.g., a new reserved word), that is not that bad; we may even provide an automatic tool to fix old code. However, if the new feature may produce subtle bugs (e.g., a preexisting function returning a different result), we consider it unacceptable.
Were iterator methods, like those of Ruby, considered for Lua, rather than the for statement that was added? What considerations led to the choice? They were not only considered, they were actually implemented! Since version 3.1 (from 1998), Lua has had a function “foreach”, that applies a given function to all pairs in a table. Similarly, with
“gsub” it is easy to apply a given function to each character in a string.
Instead of a special “block” mechanism for the iterator body, Lua has used first-class functions for the task. See the next example:
—'t' is a table from names to values —the next "loop" prints all keys with values greater than 10
foreach(t, function(key, value)
if value > 10 then print(key) end end)
However, when we first implemented iterators, functions in Lua did not have full lexical scoping. Moreover, the syntax is a little heavy (macros would help). Also, exit statements (break and return) are always confusing when used inside iteration bodies. So, in the end we decided for the for statement.
But “true iterators” are still a useful design in Lua, even more now that functions have proper lexical scoping. In my Lua book, I end the chapter about the for statement with a discussion of true iterators.
Can you briefly describe what you mean when you describe Lua as an extensible extension language? It is an “extensible language” because it is
easy to register new functions and types defined in other languages. So it is easy to extend the language. From a more concrete point of view, it is easy to call C from Lua. It is an “extension language” because it is easy to
use Lua to extend an application, to morph Lua into a macro language for the application. (This is “script-
ing” in its purer meaning.) From a more concrete point of view, it is easy to call Lua from C.
Data structures have evolved from arrays, records, and hashes to combinations of these. Can you estimate the significance of Lua’s tables in the evolution of data structures in programming languages? I do not think the Lua table has had any significance in the evolution of other languages. Maybe that will change in the future, but I am not sure about it. In my view, the main benefit offered by Lua tables is its simplicity, an “all-in-one” solution. But this simplicity has its costs: For instance, static analysis of Lua programs is very hard, partially because of tables being so generic and ubiquitous. Each language has its own priorities.
275