

лаб 1 / Лб1_Vi
.docxМІНІСТЕРСТВО ОСВІТИ ТА НАУКИ УКРАЇНИ
ХАРКІВСЬКИЙ НАЦІОНАЛЬНИЙ УНІВЕРСИТЕТ РАДІОЕЛЕКТРОНІКИ
Кафедра СТ
Звіт
про виконання лабораторної роботи № 1
з дисципліни Інтелектуальна обробка даних в розподілених інформаційних середовищах
на тему “ Робота з DataFrame. Попереднє оброблення даних. Заповнення пропущених значень.”
Виконав: ст. гр. СПРм-19-1 Шемчук В. Н. |
Перевірила: Перова І. Г. |
Харків 2020
РАБОТА С DATAFRAME. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА ДАННЫХ. ЗАПОЛНЕНИЕ ПРОПУЩЕННЫХ ЗНАЧЕНИЙ.
Цель работы: получение навыков работы с DataFrame. Изучение методов предварительной обработки данных и заполнения пропущенных значений.
Ход работы:
1. Загрузить файл Dataset.xlsx в DataFrame.
file = pd.ExcelFile('Dataset.xlsx')
df = pd.read_excel(file, sheet_name='Лист1', header=1);
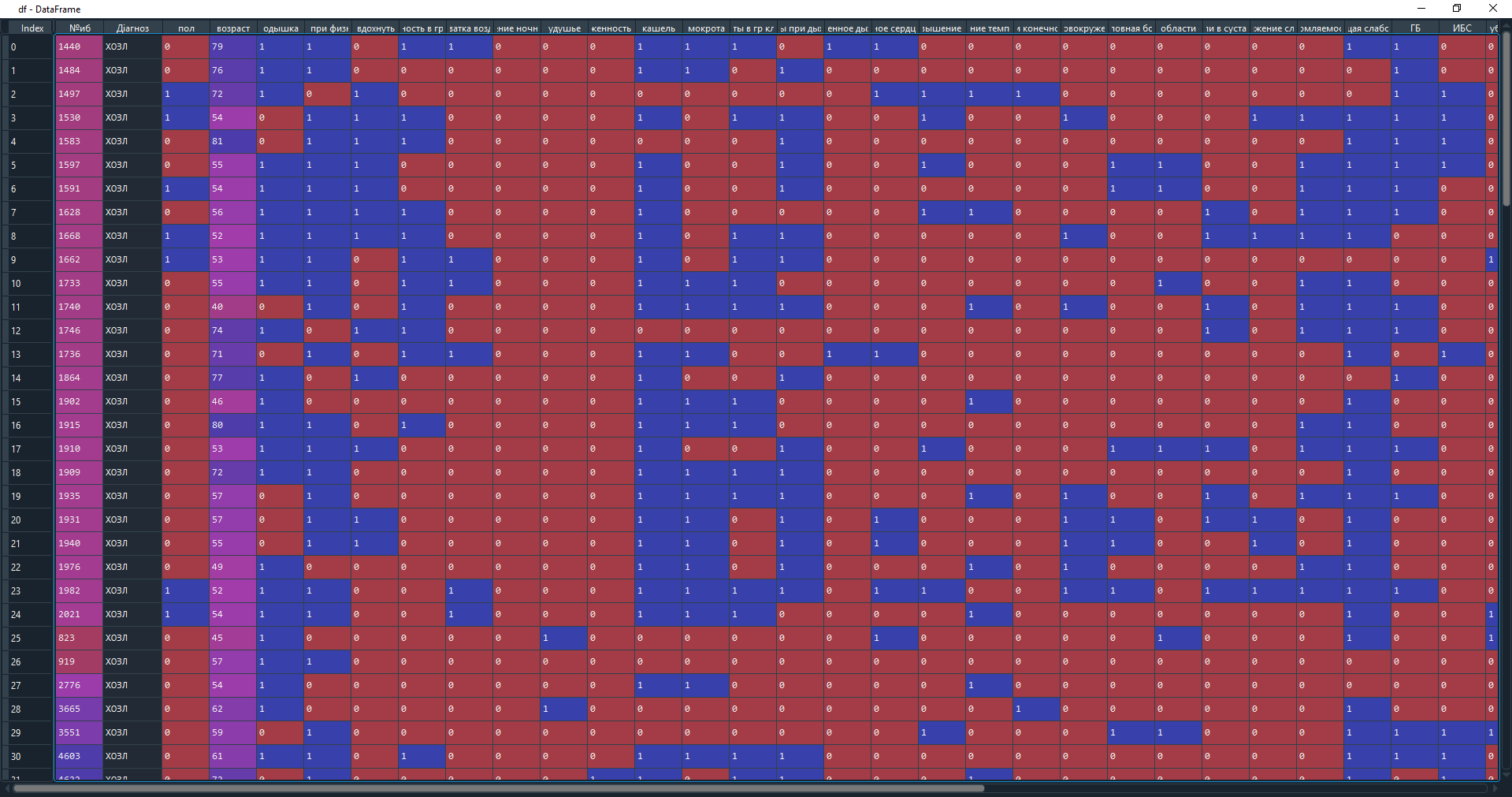
Рисунок 1 – Загрузка данных
2. С помощью метода df.describe () вывести в отдельную DataFrame результаты работы.

Рисунок 2 – Результаты команды describe начальных значений Dataset
3. Заполнить в DataFrame все пропущенные значения с помощью метода (df.fillna ()) с различными вариантами параметров метода и сохранить результаты заполнения в разные DataFrame.
# Заменяем пустые на значение строки ниже
df.fillna(method='pad')
# Заменяем пустые на значение строки ниже
df.fillna(method='bfill')
# Замолняем пропуски на 0
df.fillna(0)
Примеры использования команд приведены в прикрепленном файле к отчету.
4. Создать собственный метод заполнения пропущенных значений на основе метода нечеткой пространственной экстраполяции.
def isNa(value):
if isinstance(value, int) or isinstance(value, float):
if math.isnan(value) and value != 0:
return True
return False
def dropNaRowByPercent (df, maxNaPercents):
for y, colObject in df.iteritems():
countOfNa = 0;
countOfRows = len(colObject);
for key in colObject:
if isNa(key):
countOfNa += 1
percentNaInRow = (countOfNa / countOfRows) * 100;
#print('index =', rowObject.name, 'count_na =' ,countOfNa, '|',percentNaInRow, '%')
if percentNaInRow > maxNaPercents:
print('deleting', colObject.name)
df = df.drop(colObject.name, axis=1)
return df
def generateValue(naPosX, naPosY, rowCount):
distances = []
for x, naFreeRow in df_dropNa.iterrows():
res = 0
for y, value in df_res.iloc[naPosX].iteritems():
if (isNa(value) != True) and (isinstance(value, int) or isinstance(value, float)):
res += abs(naFreeRow[y] - value)
distances.append(res/rowCount)
#print("distances: " + str(distances))
inverseDistancesSum = 0
for distance in distances:
inverseDistancesSum += 1/distance
#print("inverse distance sum: " + str(inverseDistancesSum))
affiliationLevels = []
for distance in distances:
affiliationLevels.append((1/distance)/inverseDistancesSum)
#print("affiliation levels: " + str(affiliationLevels))
naValue = 0
iterator = 0
for x, value in df_dropNa[naPosY].iteritems():
naValue += value * affiliationLevels[iterator]
iterator += 1
return naValue
file = pd.ExcelFile('Dataset.xlsx')
df = pd.read_excel(file, sheet_name='Лист1', header=1);
df_res = dropNaRowByPercent(df, 20);
df_dropNa = df_res.dropna()
resultData = df_res.copy()
for x, row in df_res.iterrows():
for y, value in row.iteritems():
if isNa(value):
resultData.loc[x, y] = generateValue(x, y, len(df_dropNa.index) + 1)
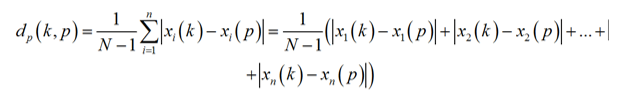
Рисунок 3 – Формула расчета расстояний между симптомами пациента
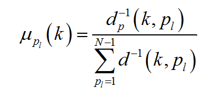
Рисунок 4 – Формула расчета принадлежности
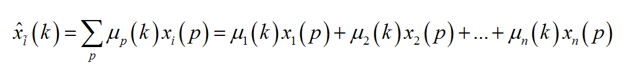
Рисунок 5 – Формула заполнения пропущенных значений
Результаты программы приведены в прикрепленном к отчету файле.
5. Повторить пункт 2 для DataFrame без пропусков. Сравнить полученные результаты. Сделать выводы.

Рисунок 6 – Результаты команды describe результата
Если сравнивать вывод команды describe для начальных данных и результата, то разницы почти не видно.
6. В качестве финальной DataFrame необходимо заполнить пробелы в тех признаках, где это имеет смысл (пропусков меньше, например, 20%). Удалить те столбцы, значения которых содержит более 20% пропусков.
Для примера были отобраны те признаки, в которых пропусков меньше 7%.
Рисунок 7 – финальная DataFrame (132, 94) в которой пропусков меньше 7%.