

Готовые отчеты (2021) / Лабораторная работа 6
.pdfРисунок 34 — EMNIST Letters. Сеть 1. Динамика изменения ошибки и точности
Рисунок 35 — EMNIST Letters. Сеть 1. Обучающая выборка. Матрица неточностей
Рисунок 36 — EMNIST Letters. Сеть 1. Тестовая выборка. Матрица неточностей
21
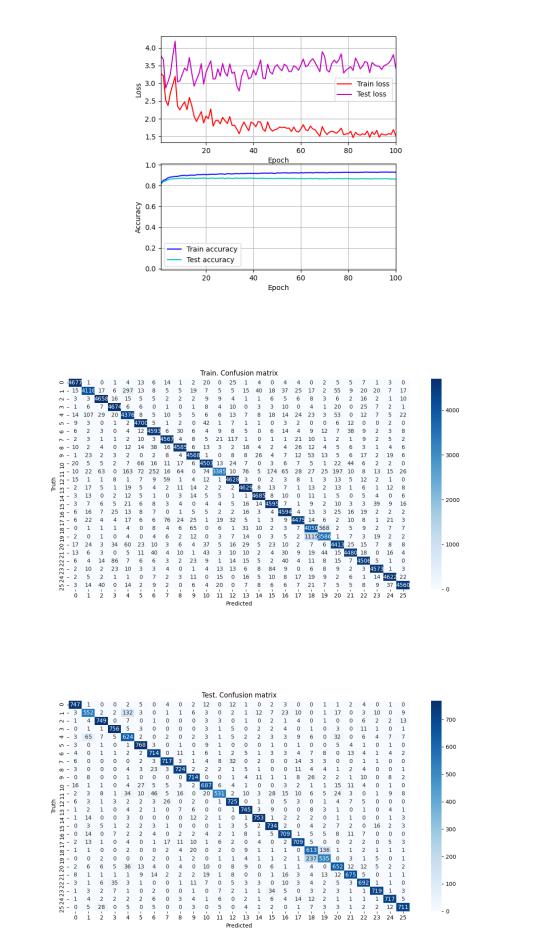
Рисунок 37 — EMNIST Letters. Сеть 2. Динамика изменения ошибки и точности
Рисунок 38 — EMNIST Letters. Сеть 2. Обучающая выборка. Матрица неточностей
Рисунок 39 — EMNIST Letters. Сеть 2. Тестовая выборка. Матрица неточностей
22
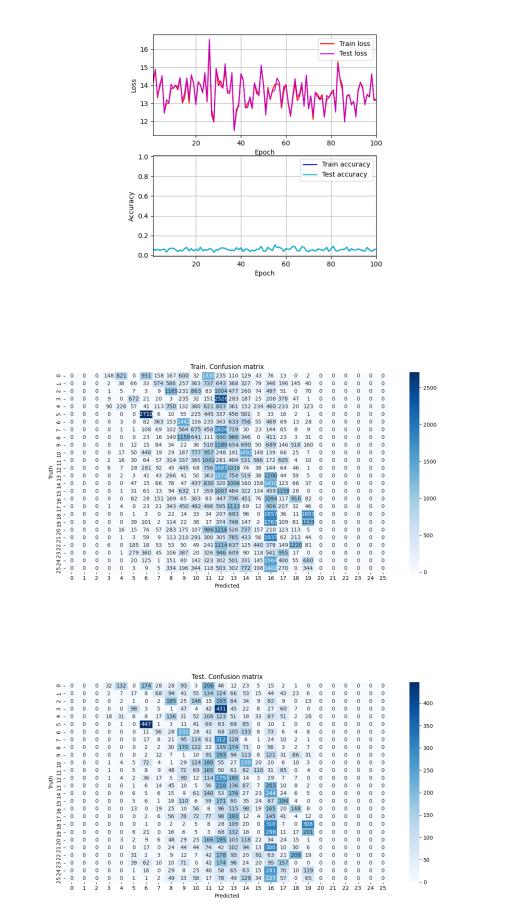
Рисунок 40 — EMNIST Letters. Сеть 3. Динамика изменения ошибки и точности
Рисунок 41 — EMNIST Letters. Сеть 3. Обучающая выборка. Матрица неточностей
Рисунок 42 — EMNIST Letters. Сеть 3. Тестовая выборка. Матрица неточностей
23
Таблица 14 — Результаты EMNIST Balanced
Сеть |
Настройки |
Результат |
|
|
|
1 |
Loss: MSE |
Train Accuracy: |
|
Optimizer: AdaDelta |
69.85% |
|
Learning rate: 75 |
|
|
Test Accuracy: |
|
|
Batch size: 32 |
|
|
Hidden layers: |
67.27% |
|
— Dense(units=10, activation=sigmoid |
Epochs: 30 |
|
weights_initializer=xavier_normal_normalized, |
|
|
bias_initializer=xavier_normal_normalized) |
Train MSE: 15.098 |
|
|
Test MSE: 17.278 |
|
|
Time: 1903 s. ≈ 32 m. |
|
|
|
2 |
Loss: MSE |
Train Accuracy: |
|
Optimizer: AdaDelta |
89.44% |
|
Learning rate: 75 |
|
|
Test Accuracy: |
|
|
Batch size: 32 |
|
|
Hidden layers: |
79.79% |
|
— Dense(units=120, activation=sigmoid |
Epochs: 98 |
|
weights_initializer=xavier_normal_normalized, |
|
|
bias_initializer=xavier_normal_normalized) |
Train MSE: 5.995 |
|
— Dense(units=10, activation=sigmoid |
Test MSE: 11.702 |
|
weights_initializer=xavier_normal_normalized, |
|
|
bias_initializer=xavier_normal_normalized) |
Time: 16990 s. ≈ 283 m. |
3 |
Loss: MSE |
Train Accuracy: |
|
Kohonen learning rate: 0.7 |
31.05% |
|
Grossberg learning rate: 0.1 |
|
|
Test Accuracy: |
|
|
Optimize: True |
|
|
Layers: |
31.12% |
|
— Kohonen(units=120, |
Epochs: 100 |
|
weights_initializer=xavier_normal_normalized, |
|
|
distance_function=euclidean) |
Train MSE: 1.009 |
|
— Grossberg(units=10, |
Test MSE: 1.154 |
|
weights_initializer=full(fill_value=23)) |
|
|
Time: 4943 s. ≈ 82 m. |
|
|
|
|
|
|
|
|
Точность нейронной сети №3 напрямую зависит от числа нейронов в |
|
слое Кохонена. Чем больше, тем лучше, но медленнее. При 112.800 нейронах точность будет 100% на первой же итерации, однако в этом случае очень долгое обучение и очень медленное прогнозирование.
24
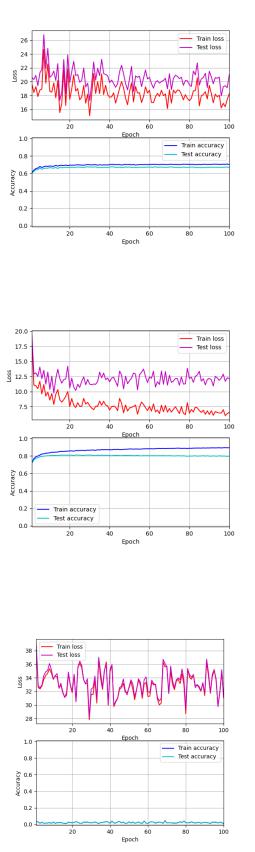
Рисунок 43 — EMNIST Balanced. Сеть 1. Динамика изменения ошибки и точности
Рисунок 44 — EMNIST Balanced. Сеть 2. Динамика изменения ошибки и точности
Рисунок 45 — EMNIST Balanced. Сеть 3. Динамика изменения ошибки и точности
25
Таблица 15 — Результаты «Sonar»
Сеть |
Настройки |
Результат |
|
|
|
1 |
Loss: MSE |
Train Accuracy: |
|
Optimizer: AdaDelta |
97.59% |
|
Learning rate: 120 |
|
|
Epochs: 763 |
|
|
Batch size: 32 |
|
|
Hidden layer: |
Train MSE: 0.024 |
|
— Dense(units=2, activation=sigmoid |
Time: 7.747 s. |
|
weights_initializer=xavier_normal_normalized, |
|
|
bias_initializer=xavier_normal_normalized) |
|
2 |
Loss: MSE |
Train Accuracy: |
|
Optimizer: AdaDelta |
100% |
|
Learning rate: 120 |
|
|
Epochs: 80 |
|
|
Batch size: 32 |
|
|
Hidden layers: |
Train MSE: 0.00 |
|
— Dense(units=80, activation=sigmoid |
Time: 1.68 s. |
|
weights_initializer=xavier_normal_normalized, |
|
|
bias_initializer=xavier_normal_normalized) |
|
|
— Dense(units=2, activation=sigmoid |
|
|
weights_initializer=xavier_normal_normalized, |
|
|
bias_initializer=xavier_normal_normalized) |
|
3 |
Loss: MSE |
Train Accuracy: |
|
Kohonen learning rate: 0.7 |
100% |
|
Grossberg learning rate: 0.1 |
|
|
Epochs: 7 |
|
|
Optimize: True |
|
|
Layers: |
Train MSE: 0.00 |
|
— Kohonen(units=200, weights_initializer=0.5, |
Time: 4.392 s. |
|
distance_function=euclidean) |
|
|
|
|
|
— Grossberg(units=2, weights_initializer=0.5) |
|
|
|
|
26
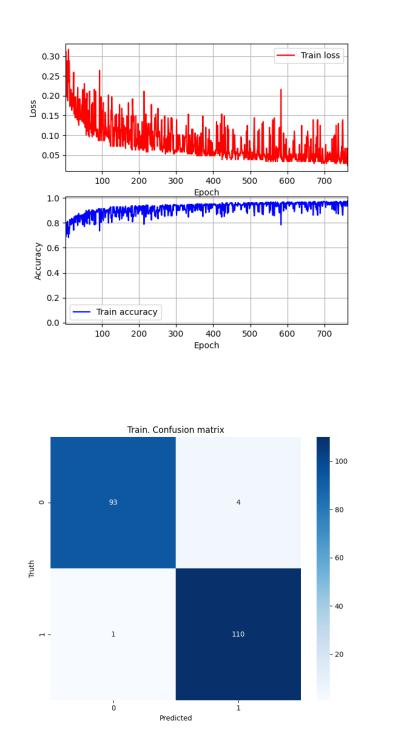
Рисунок 46 — Sonar. Сеть 1. Динамика изменения ошибки и точности
Рисунок 47 — Sonar. Сеть 1. Обучающая выборка. Матрица неточностей
27
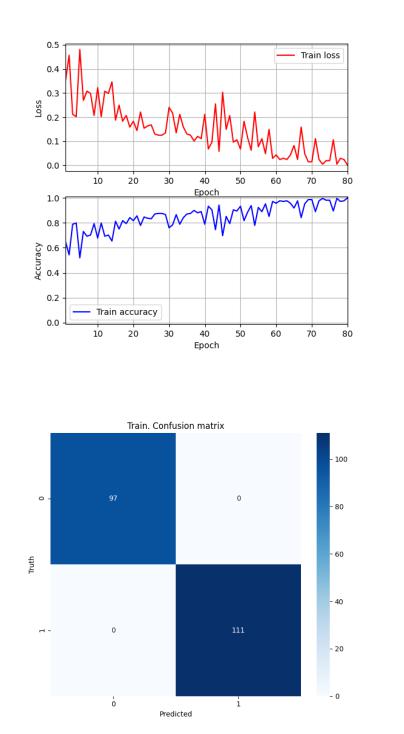
Рисунок 48 — Sonar. Сеть 2. Динамика изменения ошибки и точности
Рисунок 49 — Sonar. Сеть 2. Обучающая выборка. Матрица неточностей
28
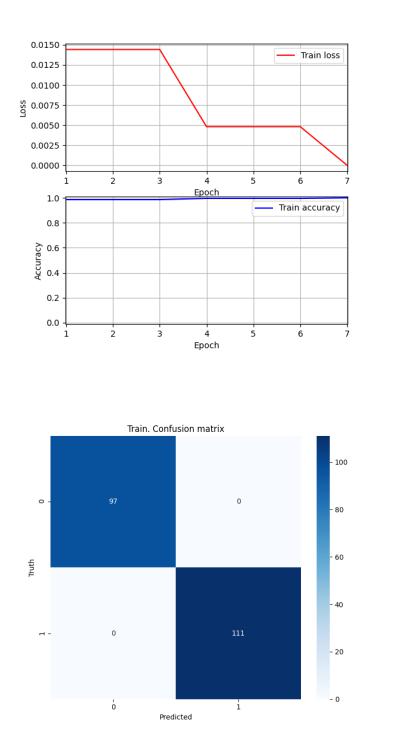
Рисунок 50 — Sonar. Сеть 3. Динамика изменения ошибки и точности
Рисунок 51 — Sonar. Сеть 3. Обучающая выборка. Матрица неточностей
29
Таблица 16 — Результаты «Wine»
Сеть |
Настройки |
Результат |
|
|
|
1 |
Loss: MSE |
Train Accuracy: |
|
Optimizer: AdaDelta |
100% |
|
Learning rate: 120 |
|
|
Epochs: 94 |
|
|
Batch size: 32 |
|
|
Hidden layer: |
Train MSE: 0.00 |
|
— Dense(units=3, activation=sigmoid |
Time: 0.819 s. |
|
weights_initializer=xavier_normal_normalized, |
|
|
bias_initializer=xavier_normal_normalized) |
|
2 |
Loss: MSE |
Train Accuracy: |
|
Optimizer: AdaDelta |
100% |
|
Learning rate: 120 |
|
|
Epochs: 21 |
|
|
Batch size: 32 |
|
|
Hidden layers: |
Train MSE: 0.00 |
|
— Dense(units=80, activation=sigmoid |
Time: 0.33 s. |
|
weights_initializer=xavier_normal_normalized, |
|
|
bias_initializer=xavier_normal_normalized) |
|
|
— Dense(units=3, activation=sigmoid |
|
|
weights_initializer=xavier_normal_normalized, |
|
|
bias_initializer=xavier_normal_normalized) |
|
3 |
Loss: MSE |
Train Accuracy: |
|
Kohonen learning rate: 0.7 |
100% |
|
Grossberg learning rate: 0.1 |
|
|
Epochs: 11 |
|
|
Optimize: True |
|
|
Layers: |
Train MSE: 0.00 |
|
— Kohonen(units=80, weights_initializer=ones, |
Time: 2.613 s. |
|
distance_function=euclidean) |
|
|
|
|
|
— Grossberg(units=3, weights_initializer=ones) |
|
|
|
|
30