

GrozI_Course_Work
.pdfМІНІСТЕРСТВО ОСВІТИ І НАУКИ УКРАЇНИ НАЦІОНАЛЬНИЙ ПЕДАГОГІЧНИЙ УНІВЕРСИТЕТ ІМЕНІ М.П.ДРАГОМАНОВА
Факультет інформатики Кафедра програмної інженерії
Грозь Ілля Дмитрович
Основні методи сортування масивів. Швидке сортування. Порівняння роботи.
Курсова робота
Спеціальність: 31 – Інженерія Програмного забезпечення
Науковий керівник Біляй Ю.П.
____________
Допущено до захисту: Завідувач кафедри Малежик П.М.
___________
Київ – 2020
1
Зміст
РОЗДІЛ 1 ВСТУПНА ЧАСТИНА 1. Вступ
РОЗДІЛ 2 ОПИС, АНАЛІЗ, РЕАЛІЗАЦІЯ АЛГОРИТМІВ СОРТУВАННЯ
2. Список алгоритмів сортування
2.1.Сортування вибором
2.1.1.Аналіз сортування вибором
2.1.2Реалізація
2.2.Сотування вставкою
2.2.1Аналіз сотування вставкою
2.2.2Реалізація
2.3.Шейкерне сортування
2.3.1Аналіз шейкерного сортування
2.3.2Реалізація
2.4.Сортування підрахунком
2.4.1Аналіз сортування підрахунком
2.4.2Реалізація
2.5.Швидке сортування
2.5.1.Аналіз швидкого сортування
2.5.2Реалізація
2.6.Сортування злиттям
2.6.1Аналіз сортування злиттям
2.6.2Реалізація
2.7.Пірамідальне сортування
2.7.1.Аналіз пірамідального сортування
2.7.2 Реалізація РОЗДІЛ 3 МЕТОДОЛОГІЯ ТЕСТУВАННЯ
1.Апаратне забезпечення
2.Програмне забезпечення
3.Тестові дані
РОЗДІЛ 4 ПОРІВНЯННЯ РОБОТИ АЛГОРИТМІВ СОРТУВАННЯ 1. Тестування
1.1.Довільні дані ,I-група
1.2.Довільні дані ,1I-група
2.1.Реверсивно відсортовані дані,I-група
2.2.Реверсивно відсортовані дані,II-група
3.1.Частково відсортовані дані,I-група
3.2.Частково відсортовані дані,II-група
4.1.Відсортовані дані,I-група
4.2.Відсортовані дані,II-група
2
Вступ
Проблема сортування - одна з найбільш давніх проблем інформатики. З самого початку епохи комп’ютерних обчислень багато дослідників виводили та аналізували проблеми алгоритмім сортування. Розвиток та дослідження проблеми сортування даних проходили поетапно на протязі багатьох років. На даний момент перший єтап ручного сортування, який проходив ще до винайдення перших ЕОМ, нас не цікавить. Тому перейдемо одразу до другого етапу розвитку способів та алгоритмів сортування , який бере свій початок у 1940 році з появи перших електронно обчислювальних машин. У 1946 році вийшла перша стаття про алгоритми сортування даних, автором якої був Джон Вільям Мочлі (John William Mauchly) - американський фізик і інженер, один з творців першого в світі електронного цифрового комп'ютера загального призначення ENIAC. У статті розглядався цілий ряд нових алгоритмів сортування, в тому числі метод бінарних вставок.
До середини 1950-х років найбільш поширеними були модифікації сортування злиттям і вставками складності O (n log n) для n елементів. У середині 1950-х років з появою перших високорівневих мов програмування почався вибуховий розвиток алгоритмів сортування. У 1959 році Дональд Левіс Шелл (Donald Lewis Shell) запропонував метод сортування з спадним кроком (shellsort), в 1960 році Чарльз Ентоні Річард Хоар (Charles Antony Richard Hoare) - метод швидкого сортування (quicksort), в 1964 році Дж. У . Дж. Вільямс (JVJ Williams) - метод пірамідального сортування (heapsort). Багато з розроблених в цей період алгоритмів широко використовуються в наш час. Підсумки цього етапу активного розвитку алгоритмів сортування підвів в 1973 році Дональд Кнут (Donald Ervin Knuth) у третьому томі своєї фундаментальної монографії «Мистецтво программування» ( «The Art of Computer Programming»).
До початку 1970-х років використовувалися наступні види алгоритмів внутрішнього сортування: сортування по засобом підрахунку; сортування шляхом вставок; обмінна сортування; сортування за допомогою вибору; сортування методом злиття; сортування методом розподілу. Найбільша кількість розроблених на той час методів відносилося до сортування шляхом вставок (метод простих вставок, бінарні і двоколійних вставки, метод Шелла, вставка в списокта ін.), Обмінного сортування (метод бульбашки і його модифікації, паралельне сортування Бетчера, швидке сортування, обмінне сортування за розрядами, асимптотичні методи) і сортування за допомогою вибору (вибір з дерева, пірамідальна сортування, метод виключення найбільшого з включених, метод пов'язанийного уявлення пріоритетних черг). Не менш активно розроблялися і методи зовнішньої сортування, в тому числі методи багатоколійного злиття і вибору з заміщенням, багатофазного злиття, каскадного злиття, зовнішнього порозрядного сортування і т. д.
3 Черговий сплеск інтересу до алгоритмів сортування стався в середині 1970-х років коли єлементной базою комп’ютерів здебільшого стали інтегральні схеми і з'явилася можливість об'єднання потужності обчислювальних машин шляхом створення єдиних обчислювальних центрів, які дозволяють працювати з поділом часу. Цей етап продовжується по наш час концентруючись на задачах сортування на частково впорядкованих множинах.
По наш час винаходять багато корисних алгоритмів сортування, таких як: Timsort (2002), Library sort (2006) та інші.
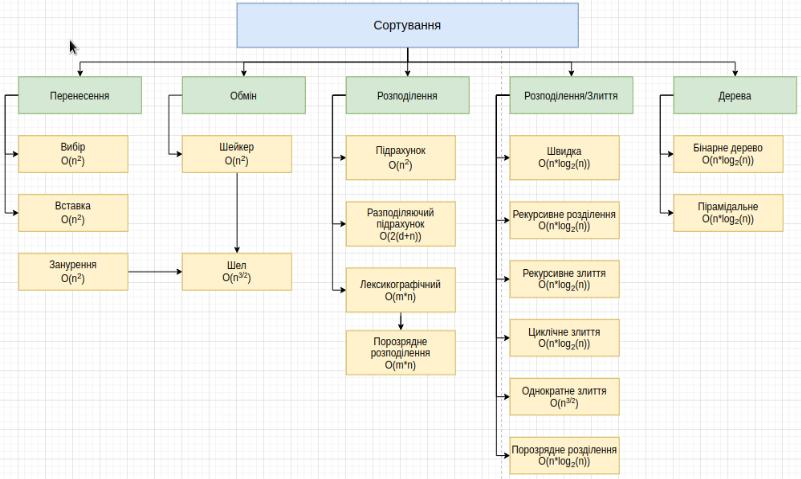
Для моєї роботи треба виділити основні актуальні методи сортування з яких вибрати по 2 методи для аналізу та порівняння.
(Спрощена класифікація алгоритмів сортування)
4
Список алгоритмів сортування
Для порівняння та реалізації мною вибрані такі алгоритми сортування:
1.Сортування вибором (Selection sort)
2.Сотування вставкою (Insertion sort)
3.Шейкерне сортування (Shaker sort)
4.Сортування підрахунком (Counting sort)
5.Швидке сортування (Quick sort)
6.Сортування злиттям (Merge sort)
7.Пірамідальне сортування (Heap sort)
5
2.1. Сортування вибором (Selection sort)
Метод сортування вибором заснований на двох основних правилах.
1.Вибирається елемент з найменшим ключем.
2.Міняється місцями з першим елементом.
Ці операції повторюються з залишившимися n-1 елементами, потім n-2 елементами до тих пір поки не залишиться один елемент — найбільший.
function selectionSort(T[n] a): for i = 0 to n - 2
for j = i + 1 to n - 1 if a[i] > a[j]
swap(a[i], a[j])
(Псевдокод)
Аналіз сортування вибором
Щоб проаналізувати хід роботи сортування методом вибору треба звернути увагу, що, якщо у нас n елементів, зовнішній цикл виконується n - 1 раз, тому у нас n - 1 замін. У кожній ітерації зовнішнього циклу ми порівнюємо всі елементи від i + 1 до кінця масиву A. В перший прохід ми порівнюємо всі елементи від A [1] до A [n - 1], тому у нас n - 1 порівнянь. У другій прохід ми порівнюємо всі елементи від A [2] до A [n - 1], тому у нас n - 2 порівнянь. В останньому проході циклу ми порівнюємо останні два елементи, A [n - 2] і A [n - 1], і у нас всього одне порівняння. Виходить, що всього порівнянь у нас
1+2+...+(n−1)=1+2+...+(n−1)+n−n= n(n+1)−n=n (n−1)
2 2
Виходячи з цього можна сказати що складність сортування сетодом вибору дорівнює O(n−1)=O(n) замінам та O(n(n−1)/2)=O(n2) порівнянням. Зазвичай порівняння виконуються швидше, ніж заміни, так як операція заміни включає в себе переміщення даних. Чим більше переставлятимемо дані, тим очевидніше стає різниця.
6
Реалізація
for(i=0;i<n-1;i++)
{
min=arr[i]; loc=i;
for(j=i+1;j<n;j++)
{
if(min>arr[j])
{
min=arr[j]; loc=j;
}
}
temp=arr[i]; arr[i]=arr[loc]; arr[loc]=temp;
}
7
2.2 Сортування вставкою (Insertion sort)
Суть алгоритму сортування вставками полягає в тому що
1.На першому кроці порівнюються другий та перший елемент
2.Якщо порядок між ними, в залежності від типу сортування (за зростанням чи за спаданням) порушений, то перший елемент пересувається на одну позицію вправо. Тепер відсортований масив складається з двох елементів.
Продовжуючи ітераційний процес далі, беремо наступний (третій, четвертий і так далі) елемент і по черзі порівнюємо його, починаючи з кінця, з іншими елементами в уже відсортованому масиві.
Виходячи з методу роботи алгоритма можна сказати що сортування вставкою буде найкращим чином показувати себе на частково відсортованих даних.
function insertionSort(a): for i = 1 to n - 1
j = i - 1
while j 0 and a[j] > a[j + 1] swap(a[j], a[j + 1])
j--
(Псевдокод)
Аналіз сортування вставкою
Для оцінки складності алгоритму треба розуміти стан вихідного масиву. Якщо масив вже упорядкований, то всі елементи залишаться на своєму місці і вкладений цикл не буде виконаний жодного разу. У цьому випадку складність алгоритму сортування вставками - лінійна, тобто O(n) Аналогічно, якщо масив «майже впорядкований», тобто для перетворення його в упорядкований потрібно поміняти місцями декілька сусідніх або близьких елементів, то складність також буде лінійною. Але якщо масив упорядкований у зворотному порядку, наприклад, кожен елемент більше поперелньго, а необхідно досягти зворотного порядку, то кожен елемент буде пересуватися максимально вліво, тобто до самої крайньої позиції. У цьому випадку кількість виконуваних переміщень дорівнюватиме:
1+2+...+(n−1)+n= n(n+1)=O(n2)
2
Укращому випадку час роботи - лінійний, в гіршому випадку — квадратичний.
Увипадку якщо в середньому елементи масиву впорядковано випадково. Математичне сподівання кількості переміщень елементів дорівнюватиме половині від числа переміщень в гіршому випадку, тобто математичне очікування числа переміщень дорівнюватиме:
n(n+1)=O(n2 )
4
8
Реалізація
for (i = 1; i < N; i++)
{
key = arr[i]; j = i - 1;
while (j >= 0 && arr[j] > key)
{
arr[j + 1] = arr[j]; j = j - 1;
}
arr[j + 1] = key;
}
9
2.3 Шейкерне сортування (Shaker sort)
Принцип работи полягає в багаторазовій пробіжці по масиву сусідні елементи порівнюються і, в разі необхідності, міняються місцями. При досягненні кінця масиву напрямок змінюється на протилежний. Таким чином по черзі виштовхуються великі і дрібні елементи масиву в кінець і початок структури відповідно.
function ShakerSort( A : list of sortable items ) defined as: do
swapped := false
for each i in 0 to length( A ) - 2 do: if A[ i ] > A[ i + 1 ] then
order
swap( A[ i ], A[ i + 1 ] ) swapped := true
end if end for
if not swapped then break do-while loop
end if
swapped := false
for each i in length( A ) - 2 to 0 do: if A[ i ] > A[ i + 1 ] then
swap( A[ i ], A[ i + 1 ] ) swapped := true
end if end for
while swapped end procedure
|
|
(Псевдокод) |
Аналіз шейкерного сортування |
||
Найменша кількість порівнянь |
Cmin=n−1 . Кнут знайшов, що середня кількість |
|
проходів пропорційна n−k1 √ |
|
та середня кількість порівнянь пропорційна |
n |
||
1 |
[n2−n(k2 +ln(n))] |
. Тому складність шейкерного сортування |
O(n2 ) в гіршому та |
2 |
|
|
|
середньому випадках та O(n) в кращому . Таким чином шейкерне сортування має сенс використовувати коли ми знаємо що масив даних вже майже відсортовано. Що досить рідко зустрічається на практиці.
Реалізація