

otvety_4
.pdf1. Поиск информации в Интернет. Релевантность, пертитентность.
ИПС (информационно-поисковая система) – это система, обеспечивающая поиск и отбор необходимых данных в специальной базе с описаниями источников информации (индексе) на основе информационно-поискового языка и соответствующих правил поиска.
Главной задачей любой ИПС является поиск информации релевантной информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего. Поэтому вводится качественная характеристика процедуры поиска – релевантность.
Релевантность – это соответствие результатов поиска сформулированному запросу.
Пертинентность (в информационном поиске) — соответствие полученной информации информационной потребности пользователя.
Пертинентность измеряется степенью соответствие между ожиданиями пользователя и результатами поиска (сравните с релевантностью), которая определяется как отношение объема полезной для пользователя информации к общему объему полученной информации, найденной поисковой системой.
Достижение высокой степени пертинентности — основное поле конкурентной борьбы современных поисковых систем. Именно для максимального удовлетворения информационных потребностей пользователей в настоящее время в ИП-системах широко применяются теории и методы семантических сетей, контент-анализа и глубинного анализа текстов (Text mining, интеллектуальный анализ текстов).
Для поиска нужной информации в сети используется адрес ресурса (англ. Uniform Resource Locator (URL) адрес), содержащий имя протокола, по которому нужно обращаться к требуемой информации, адрес сервера и имя файла на этом сервере (рис. 2).
http://web.city.ac.uk/citylife/pages.html
Протокол |
Адрес сервера |
Полное имя файла |
|
|
|
Рис. 2. Пример адреса ресурса Поиско́вая систе́ма — программно-аппаратный комплекс с веб-интерфейсом,
предоставляющий возможность поиска информации в Интернете. Под поисковой системой обычно подразумевается сайт, на котором размещён интерфейс системы. Программной частью поисковой системы является поисковая машина (поисковый движок) — комплекс программ, обеспечивающий функциональность поисковой системы и обычно являющийся коммерческой тайной компанииразработчика поисковой системы
Поиск информации в Интернете осуществляется с помощью специальных программ, обрабатывающих запросы — информационно-поисковых систем (ИПС). Существует несколько моделей, на которых основана работа поисковых систем, но исторически две модели приобрели наибольшую популярность — это поисковые каталоги и поисковые указатели.
Поисковые каталоги устроены по тому же принципу, что и тематические каталоги крупных библиотек. Они обычно представляют собой иерархические гипертекстовые меню с пунктами и подпунктами, определяющими тематику сайтов, адреса которых содержатся в данном каталоге, с постепенным, от уровня к уровню, уточнением темы. Поисковые каталоги создаются вручную. Высококвалифицированные редакторы лично просматривают информационное пространство WWW, отбирают то, что по их мнению представляет общественный интерес, и заносят в каталог.
Основной проблемой поисковых каталогов является чрезвычайно низкий коэффициент охвата ресурсов WWW. Чтобы многократно увеличить коэффициент охвата ресурсов Web, из процесса наполнения базы данных поисковой системы необходимо исключить человеческий фактор — работа должна быть автоматизирована.
Автоматическую каталогизацию Web-ресурсов и удовлетворение запросов клиентов выполняют поисковые указатели. Работу поискового указателя можно условно разделить на три этапа:
сбор первичной базы данных. Для сканирования информационного пространства WWW используются специальные агентские программы — черви, задача которых состоит в поиске неизвестных ресурсов и регистрация их в базе данных;
индексация базы данных — первичная обработка с целью оптимизации поиска. На этапе индексации создаются специализированные документы — собственно поисковые указатели;
рафинирование результирующего списка. На этом этапе создается список ссылок, который будет передан пользователю в качестве результирующего. Рафинирование результирующего списка заключается в фильтрации и ранжировании результатов поиска.
Под фильтрацией понимается отсев ссылок, которые нецелесообразно выдавать пользователю (например, проверяется наличие дубликатов). Ранжирование заключается в создании специального порядка представления результирующего списка (по количеству ключевых слов, сопутствующих слов и др.).
Главной задачей любой ИПС является поиск информации релевантной информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего. Поэтому вводится качественная характеристика процедуры поиска – релевантность.
Релевантность – это соответствие результатов поиска сформулированному запросу.
1 Поисковые инструменты
Поисковые инструменты - это особое программное обеспечение, основная цель которого – обеспечить наиболее оптимальный и качественный поиск информации для пользователей Интернета. Поисковые инструменты размещаются на специальных веб-серверах, каждый из которых выполняет определенную функцию:
Машины веб-поиска - это сервера с огромной базой данных URL-адресов, которые автоматически обращаются к страницам WWW по всем этим адресам, изучают содержимое этих страниц, формируют и прописывают ключевые слова со страниц в свою базу данных (индексирует страницы).
Более того, роботы поисковых систем переходят по встречаемым на страницах ссылкам и переиндексируют их. Так как почти любая страница WWW имеет множество ссылок на другие страницы, то при подобной работе поисковая машина в конечном результате теоретически может обойти все сайты в Интернет.
Именно этот вид поисковых инструментов является наиболее известным и популярным среди всех пользователей сети Интернет. У каждого на слуху названия известных машин веб-поиска
(поисковых систем) – Яndex, Rambler, Aport.
Работа машин веб-поиска сводится к следующему:
1.Анализ веб-страниц и занесение результатов анализа на тот или иной уровень базы данных поискового сервера.
2.Поиск информации по запросу пользователя.
3.Обеспечение удобного интерфейса для поиска информации и просмотра результата поиска пользователем.
Приемы работы, используемые при работе с теми или другими поисковыми инструментами, практически одинаковы. При их описании используются следующие понятия:
1.Интерфейс поискового инструмента представлен в виде страницы с гиперссылками, строкой подачи запроса (строкой поиска) и инструментами активизации запроса.
2.Индекс поисковой системы – это информационная база, содержащая результат анализа веб-страниц, составленная по определенным правилам.
3.Запрос – это ключевое слово или фраза, которую вводит пользователь в строку поиска. Для формирования различных запросов используются специальные символы ("", , ~), математические символы (*, +, ?).
Схема поиска информации проста. Пользователь набирает ключевую фразу и активизирует поиск, тем самым получает подборку документов по сформулированному (заданному) запросу. Этот список документов ранжируется по определенным критериям так, чтобы вверху списка оказались те документы, которые наиболее соответствуют запросу пользователя. Каждый из поисковых
инструментов использует различные критерии ранжирования документов, как при анализе результатов поиска, так и при формировании индекса (наполнении индексной базы данных webстраниц).
В России наиболее крупными и популярными поисковыми указателями являются:
«Яndex» (www.yandex.ru)
«Pамблер» (www.rambler.ru)
«Google» (www.google.ru)
«Апорт2000» (www.aport.ru)
2 Механизмы поиска
Обобщенная технология поиска состоит из следующих этапов:
Пользователь формулирует запрос
Система проводит поиск документов (или их поисковых образов)
Пользователь получает результат (сведения о документах)
Пользователь совершенствует или реформирует запрос
Организация нового поиска...
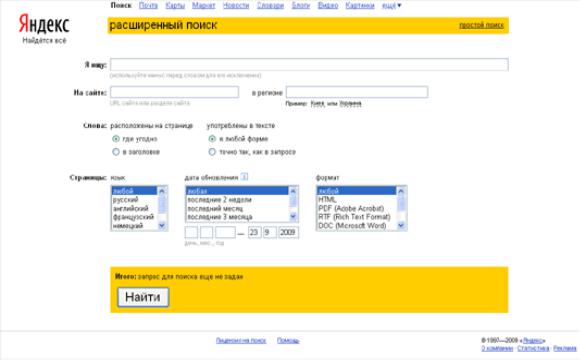
Как правило, поисковые машины поддерживают два режима: режим простого поиска и режим расширенного поиска. Рассмотрим обобщенные возможности.
Формирования запроса в режиме простого поиска. Можно просто вводить через пробел одно или несколько слов; поиск слов со всевозможными окончаниями моделируется символом * в конце слова. Многие системы позволяют искать словосочетания или фразу, для этого необходимо ее заключить в кавычки. Возможно обязательное включение или исключение определенных слов.
Основная проблема поиска по примитивно составленному запросу (в виде перечисления ключевых слов) заключается в том, что поисковая машина найдет все страницы, на которых указанные слова встречаются в любой части документа. Как правило, количество найденных страниц будет слишком велико.
Для улучшения качества поиска в режиме простого поиска допустимо использование логических операторов и операторов, позволяющих ограничить область поиска, а также выбор определенной категории документов из представленного списка.
Многие поисковые системы включают в свой язык составления запросов специальные операторы, позволяющие проводить поиск в определенных зонах документа, например, в его заголовке, или искать документ по известной части его адреса.
Режим расширенного или детального запроса в разных системах реализован индивидуально, но чаще всего это бланк, в котором упомянутые операторы и ключевые элементы реализуются простой установкой соответствующих флажков или выбором параметров из списка.
Ниже в качестве примера приведены сведения из раздела помощь поисковой системы Yandex:
окно расширенного поиска, язык запросов, искать в найденном.
Искать в найденном Если в результате запроса Яндекс нашел много документов, но по более широкой теме, чем вам хочется, вы можете сократить этот список, уточнив запрос. Еще один вариант — включить флажок в найденном в форме поиска, задать дополнительные ключевые слова, и следующий поиск будет вестись только по тем документам, которые были отобраны в предыдущем поиске.
Памятка по использованию языка запросов
Пример |
Значение |
"К нам на утренний рассол" |
Слова идут подряд в точной форме |
"Прибыл * посол" |
Пропущено слово в цитате |
полгорбушки & мосол |
Слова в пределах одного предложения |
снаряжайся && добудь |
Слова в пределах одного документа |
глухаря | куропатку | кого-нибудь |
Поиск любого из слов |
не смогешь << винить |
Неранжирующее "и": выражение после оператора не |
|
влияет на позицию документа в выдаче |
я должон /2 казнить |
Расстояние в пределах двух слов в любую сторону |
|
(то есть между заданными словами может |
|
встречаться одно слово) |
государственное дело && /3 улавливаешь |
Расстояние в 3 предложения в любую сторону |
нить |
|
нешто я ~~ пойму |
Исключение слова пойму из поиска |
при моем /+2 уму |
Расстояние в пределах двух слов в прямом порядке |
чай ~ лаптем |
Поиск предложения, где слово чай встречается без |
|
слова лаптем |
щи /(-1 +2) хлебаю |
Расстояние от одного слова в обратном порядке до |
|
двух слов в прямом |
!Соображаю !что !чему |
Слова в точной форме с заданным регистром |
получается && (+на | !мне) |
Скобки формируют группы в сложных запросах |
!!политика |
Словарная форма слова |
title:(в стране) |
Поиск по заголовкам документов |
url:ptici.narod.ru/ptici/kuropatka.htm |
Поиск по URL |
беспременно inurl:vojne |
Поиск с учетом фрагмента URL |
host:lib.ru |
Поиск по хосту |
rhost:ru.lib.* |
Поиск по хосту в обратной записи |
site:http://www.lib.ru/PXESY/FILATOW |
Поиск по всем поддоменам и страницам заданного |
|
сайта |
mime:pdf |
Поиск по одному типу файлов |
lang:en |
Поиск с ограничением по языку |
domain:ru |
Поиск с ограничением по домену |
date:200712* |
Поиск с ограничением по дате |
государственное дело && /3 улавливаешь |
Расстояние в 3 предложения в любую сторону |

нить |
|
нешто я ~~ пойму |
Исключение слова пойму из поиска |
Интересной возможностью является поиск документов в сети, ссылающиеся на страницу с указанным вами адресом (URL). Таким образом, можно найти в сети страницы, на которых есть ссылки на ваш Web-сайт. Некоторые системы позволят ограничить область поиска внутри указанного домена.
В качестве дополнительных специальных операторов можно выделить:
Операторы поиска документов с определенным графическим файлом;
Операторы ограничения по дате искомых страниц;
Операторы близости между словами;
Операторы учета словоформы;
Операторы сортировки результатов (по релевантности, свежести, старости).
Следует заметить, что, к великому сожалению, на сегодняшний день не существует стандарта на количество и синтаксис поддерживаемых операторов для различных поисковых систем. Попытки разработать стандарт на синтаксис поддерживаемых операторов предпринимаются, поэтому есть надежда на то, что разработчики поисковых систем позаботятся об удобстве пользователей. На данном этапе развития средств поиска, пользователь, обращаясь к определенной поисковой системе, непременно должен в первую очередь ознакомиться с ее правилами составления запросов. Как правило, на домашней странице будет обязательно присутствовать ссылка Помощь (Help), по которой вы перейдете к справочной информации.
Различные поисковые системы описывают разное количество источников информации в Интернет. Поэтому нельзя ограничиваться поиском только в одной поисковой системе.
Рассмотрим способы представления результатов поиска в поисковых машинах.
Чаще всего количество найденных документов превышает несколько десятков, а в отдельных случаях может достигать сотен тысяч! Поэтому в качестве формы выдачи составляется список документов по 5-10-15 единиц на странице с возможностью перехода к следующей порции внизу страницы. Обязательно указывается заголовок и URL(адрес) найденного документа, иногда система указывает в процентах степень релевантности документа.
В описании документа чаще всего содержится несколько первых предложений или выдержки из текста документа с выделением ключевых слов. Как правило, указана дата обновления (проверки) документа, его размер в килобайтах, некоторые системы определяют язык документа и его кодировку (для русскоязычных документов).
Что можно делать с полученными результатами? Если название и описание документа соответствует вашим требованиям, можно немедленно перейти к его первоисточнику по ссылке. Это удобнее делать в новом окне, чтобы иметь возможность далее анализировать результаты выдачи. Многие поисковые системы позволяют проводить поиск в найденных документах, причем вы можете уточнить ваш запрос введением дополнительных терминов.
Если интеллектуальность системы высока, вам могут предложить услугу поиска похожих документов. Для этого вы выбираете особо понравившийся документ и указываете его системе в качестве образца для подражания.
Однако, автоматизация определение похожести – весьма нетривиальная задача, и зачастую эта функция работает неадекватно вашим надеждам. Некоторые поисковики позволяют провести пересортировку результатов. Для экономии вашего времени можно сохранить результаты поиска в виде файла на локальном диске для последующего изучения в автономном режиме.
3 Поиск с помощью каталогов (directories)
Каталог Интернет-ресурсов – это постоянно обновляющийся и пополняющийся иерархический каталог, содержащий множество категорий и отдельных web-серверов с кратким описанием их содержимого.
Способ поиска по каталогу подразумевает «движение вниз по ступенькам», то есть движение от более общих категорий к более конкретным. Одним из преимуществ тематических каталогов является то, что пояснения к ссылкам дают создатели каталога и полностью отражают его содержание, то есть дает Вам возможность точнее определить, насколько соответствует содержание
сервера цели Вашего поиска. |
|
|
|
|
|
|
Примером |
тематического |
русскоязычного |
каталога |
можно |
назвать |
ресурс |

http://www.ulitka.ru/.
На главной странице данного сайта расположен тематический рубрикатор, с помощью которого пользователь попадает в рубрику со ссылками на интересующую его продукцию.
Кроме того, некоторые тематические каталоги позволяют искать по ключевым словам. Пользователь вводит необходимое ключевое слово в строку поиска и получает список ссылок с
описаниями сайтов, которые наиболее полно соответствуют его запросу. Стоит отметить, что этот поиск происходит не в содержимом WWW-серверов, а в их кратком описании, хранящихся в каталоге.
В нашем примере в каталоге также имеется возможность сортировки сайтов по количеству посещений, по алфавиту, по дате занесения.
Другие примеры русскоязычных каталогов: Каталог@Mail.ru Weblist Vsego.ru Cреди англоязычных каталогов можно выделить: http://www.DMOS.org http://www.yahoo.com/ http://www.looksmart.com
4 Поиск с помощью подборки ссылок
Подборки ссылок – это отсортированные по темам ссылки. Они достаточно сильно отличаются друг от друга по наполнению, поэтому чтобы найти подборку, наиболее полно отвечающую Вашим интересам, необходимо ходить по ним самостоятельно, дабы составить собственное мнение.
В качестве примера приведем Подборку ссылок "Сокровища Интернет" АО "Релком" Пользователь, нажимая на любую из заинтересовавших его рубрик
СОДЕРЖАНИЕ
Автомобилистам попадает на подборку со ссылками на полезные Интернет-ресурсы Автомобилистам
Автомобильная электроника.
Музей автомото старины.
Коллегия Правовой Защиты Автовладельцев.
Sportdrive.
Преимуществом такого вида поисковых инструментов является их целенаправленность, обычно подборка включает в себя редкие интернет ресурсы, подобранные конкретным веб-мастером или хозяином интернет странички.
5 Система поиска FTP файлов (FTP Search)
Система поиска FTP-файлов – это особый тип средств поиска в Internet, который позволяет находить файлы, доступные на «анонимных» FTP-серверах. Протокол FTP предназначен для передачи по сети файлов, и в этом смысле он функционально является своеобразным аналогом
Gopher.
Основным критерием поиска является название файла, задаваемое разными способами
(точное соответствие, подстрока, регулярное выражение и т.д.). Данный тип поиска, конечно же, не может соперничать по возможностям с поисковыми машинами, так как содержимое файлов никак не учитывается при поиске, а файлам, как известно, можно давать произвольные имена. Тем не менее, если Вам требуется найти какую-нибудь известную программу или описание стандарта, то с большой долей вероятности файл, его содержащий, будет иметь соответствующее имя, и Вы сможете найти его при помощи одного из серверов FTP Search:
FileSearch ищет файлы на FTP-серверах по именам самих файлов и каталогов. Если Вы ищете какую-либо программу или еще что-то, то на WWW-серверах Вы скорее найдете их описание, а с FTP-серверов Вы сможете перекачать их к себе.
6 Системы мета-поиска
Для быстрого поиска в базах сразу нескольких поисковых систем лучше обратиться к системам мета-поиска.
Системы мета-поиска – это поисковые машины, которые посылают Ваш запрос на огромное количество разных поисковых систем, затем обрабатывают полученные результаты, удаляют повторяющиеся адреса ресурсов и представляют более широкий спектр того, что представлено в сети Интернет.
Наиболее популярная в мире система мета-поиска Search.com. Русскоязычная мета системаНигма.
Далее мы будем, в основном, рассматривать ИПС для всемирной паутины (WWW). Основными показателями ИПС для WWW являются пространственный масштаб и специализация.
По пространственному масштабу ИПС можно разделить на локальные, глобальные,
региональные и специализированные. Локальные поисковые системы могут быть разработаны для быстрого поиска страниц в масштабе отдельного сервера.
Региональные ИПС описывают информационные ресурсы определенного региона, например, русскоязычные страницы в Интернете. Глобальные поисковые системы в отличие от локальных стремятся объять необъятное – по возможности наиболее полно описать ресурсы всего информационного пространства сети Интернет.
Кроме того, ИПС также могут специализироваться по поиску различных источников информации, например, документов WWW, файлов, адресов и т.д.
Рассмотрим подробнее основные задачи, которые должны решить разработчики ИПС. Как следует из определения, ИПС для WWW проводят поиск в собственной базе (индексе) с
описанием распределенных источников информации.
Следовательно, сначала нужно описать информационные ресурсы и создать индекс. Построение индекса начинается с определения начального набора URL источников информации. Затем
проводится процедура индексирования.
Индексирование – описание источников информации и построение специальной базы данных (индекса) для эффективного поиска.
Внекоторых информационно-поисковых системах описание источников информации проводится людьми, которые составляют краткую аннотацию на каждый ресурс. Затем, как правило, проводится сортировка аннотаций по темам (составление тематического каталога). описание, составленное человеком, будет совершенно адекватно источнику, но процедура описания занимает значительный период времени, поэтому формируемый индекс имеет, как правило, ограниченный объем.
ВИПС второго типа процедура описания информационных ресурсов автоматизирована. Для этого разрабатывается специальная программа-робот, которая по определенной технологии обходит ресурсы, описывает их (проводит индексирование) и анализирует ссылки с текущей страницы для расширения области поиска. Как может описать документ программа? Чаще всего просто составляется список слов, которые встречаются в тексте и других частях документа,
при этом учитывается частота повторения и местоположение слова, то есть, слову приписывается своеобразный весовой коэффициент в зависимости от его значимости. Например, если слово находится в названии Web-страницы, робот пометит этот факт для себя. Поскольку описание автоматизировано, затраты времени невелики, и индекс может оказаться очень большим по размеру.
Следовательно, следующей задачей для ИПС второго типа является разработка роботаиндексировщика. Для поиска в системах данного типа пользователю придется научиться составлять запросы, в простейшем случае состоящие из нескольких слов. Тогда ИПС будет искать в своем индексе документы, в описаниях которых встречаются слова из запроса. Для проведения более качественного поиска необходимо разрабатывать специальный язык запросов для пользователя. В зависимости от особенностей построения модели индекса и поддерживаемого языка запросов разрабатывается механизм поиска и алгоритм сортировки результатов поиска. Поскольку индекс имеет значительный объем, количество найденных документов может оказаться достаточно большим. Следовательно, чрезвычайно важно, как поисковая машина проведет поиск и отсортирует его результаты.
Не последнее значение имеет внешний вид поисковой системы, предстающий перед пользователем, поэтому одной из задач является разработка удобного и красивого интерфейса. Наконец, исключительно важна форма представления результатов поиска, поскольку пользователю необходимо узнать как можно больше о найденном источнике информации, чтобы принять правильное решение о необходимости его посещения.
Для обращения к поисковому серверу пользователь использует стандартную программу-клиент для всемирной паутины, то есть браузер. По адресу домашней страницы ИПС пользователь работает с интерфейсом поисковой системы, который служит для общения пользователя с поисковым аппаратом системы (системой формирования запросов и просмотра результатов поиска).
2.Основные сервисы (службы Интернета), их классификация.
Под сервисами или службами Интернет обычно понимаются те виды услуг, которые оказываются серверами, входящими в сеть. Каждый сервис уникален и одновременно неотделим от остальных, поэтому нельзя ввести сколько-нибудь жесткую или определенную классификацию. Каждый сервис характеризуется свойствами, часть которых объединяет его с одной группой сервисов, а другая часть с другой группой.
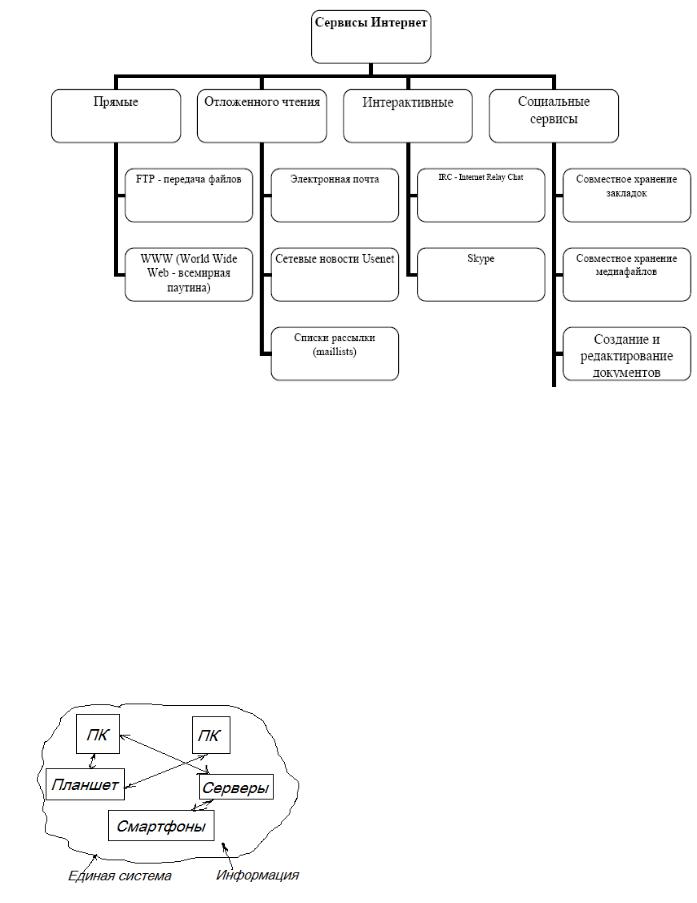
Рис. 3. Классификация типов сервисов Интернет Сервисы, относящиеся к классу Отложенного чтения, наиболее распространены, наиболее
универсальны и наименее требовательны к ресурсам компьютеров и линиям связи. Основным признаком этой группы является та особенность, что запрос и получение информации могут быть достаточно сильно разделены по времени. Сюда относится, например, электронная почта.
Сервисы прямого обращения характерны тем, что информация по запросу возвращается немедленно. Однако от получателя информации не требуется немедленной реакции.
Сервисы, где требуется немедленная реакция на полученную информацию, т.е. получаемая информация является, по сути дела, запросом, относятся к интерактивным сервисам. Для пояснения вышесказанного можно заметить, что в обычной связи аналогами сервисов интерактивных, прямых и отложенного чтения являются, например, телефон, факс и письменная корреспонденция.
Социальные сервисы - сетевое программное обеспечение, поддерживающее групповые взаимодействия.
3. Облачные сервисы: виды, применение.
??? Можно ли обеспечить для элементов этой системы взаимодействие по единым правилам?
Возможности облачных сервисов:
1.Хранение информации (Google-disk, Yandex-disk, …) +:
резервное хранение (компьютер вышел из строя, но инфа не пропадет)
синхронизация изменений (любые изменения распространяются на все включенные условия
усиленная защита
–:
утечка инфы, высокая незащищенность данных
хакеры
2. «Облачные вычисления» Доступ к ПО Модели:
a.доступ к определенным программам (пр-р: обеспечение как услуга)
+можно не покупать ПО, а арендовать на некоторое время
+можно протестировать перед покупкой
b.Платформа как услуга (ОС, средства тестирования или отладки)
+аналогичны + пункта а
MS 365 Доступ круга пользователей к редактированию документов
c.Услуга как рабочий стол
d.инфраструктура как услуга (работа всех участников фирмы в рамках облачной системы) Итак, решаем, пользоваться или нет: + и -:
+легальное ПО +Выход с любого устройства, подключенного к Интернет
+низкие требования к устройству +резервное хранение данных +синхронизация данных
+возможность использования мощного профессионального ПО на простом оборудовании
-невозможность контролировать действия 3их лиц -выход только при подключении к Интернет -Пользование услуг конкретного владельца -периодическая необходимость оплаты
4.Информационные ресурсы интернет. Всемирная паутина WWW. Классификация сайтов.
Классификация информационных ресурсов интернет
Мировые информационные ресурсы обычно подразделяются на три сектора:
-сектор деловой информации;
-сектор научно-технической и специальной информации;
-сектор массовой потребительской информации.
Сектор научно-технической и специальной информации включает: документальную, библиографическую, реферативную и полнотекстовую информацию о фундаментальных и прикладных исследованиях и профессиональную информацию для юристов, врачей, инженеров и остальных групп.
Сектор массовой потребительской информации включает новости и справочную информацию, потребительскую развлекательную информацию.
Можно рассматривать WWW как единое распределенное информационное пространство, состоящее из сотен миллионов гипермедийных документов.
Понятие гипермедиа означает объединение двух понятий: мультимедиа и гипертекст. Мультимедиа – документ включает в себя не только текст, но и двух- и трехмерную графику,
видео и звук.
Информация в WWW представляется в виде документов, каждый из которых может содержать как внутренние перекрестные ссылки, так и ссылки на другие документы, хранящиеся на том же самом или на любом другом сервере.
Гипертекст – множество отдельных документов (страниц), которые имеют ссылки друг на друга. Гипертекстовая ссылка – выделенная часть документа, реализующая переход к другому документу. Реализуется в виде подчеркнутого текста, кнопки или картинки.
Все пространство WWW состоит из документов, называемых Web-страницами. Web-страница – документ в WWW, содержащий: