

Статистика практическая работа 3
.docxМинистерство сельского хозяйства Российской Федерации
Федеральное государственное бюджетное
образовательное учреждение высшего образования
«Государственный университет по землеустройству»
Кафедра землепользования и кадастров
Практическая работа по статистике №3:
«Парный линейный корреляционно-регрессионный анализ»
Выполнил:
Проверил:
Москва 2019
Задача 3.1. Парная линейная регрессия и статистическая оценка ее достоверности с использованием инструмента «Регрессия» MS EXCEL.
Условие: имеются данные выборочного наблюдения за рынком участков близ Санкт-Петербурга (приложение 1.1).
Требуется: изучить взаимосвязь между размером участка и стоимостью участка. Используя встроенный инструмент «Регрессия» MS EXCEL 2010, построить парную линейную модель регрессии, оценить достоверность полученных результатов.
Решение. Прежде чем моделировать взаимосвязь переменных в виде уравнения регрессии, необходимо убедиться, что они действительно взаимосвязаны. Одним из приемов обнаружения корреляционной связи между двумя переменными является графический способ – построение точечного графика, где координатами точек являются соответствующие значения х и у в конкретных наблюдениях. В нашем примере х- это факторная переменная «размер участка, соток», у – результативная переменная «стоимость участка, тыс. руб.» (табл. 3.1.)
Табл. 3.1
№ п/п
|
Населенный пункт |
Размер участка, соток |
Стоимость участка, тыс. руб. |
1 |
2 |
5 |
6 |
1 |
п. Симагино |
10 |
400 |
2 |
Ландышевка |
7 |
400 |
3 |
р.п. Поляны |
10 |
500 |
4 |
Горьковское |
6 |
750 |
5 |
Первомайское |
6 |
790 |
6 |
Семиозерье |
6 |
800 |
7 |
п. Симагино |
10 |
390 |
8 |
Пионерское |
10 |
850 |
9 |
Смирново |
10 |
900 |
10 |
р.п. Поляны |
10 |
1000 |
11 |
Уткино |
10 |
1200 |
12 |
Кирилловское |
10 |
1300 |
13 |
Заходское |
10 |
1360 |
14 |
Уткино |
10 |
1500 |
15 |
Невский |
6 |
2300 |
16 |
Ильичево |
7 |
2500 |
17 |
п. Симагино |
30 |
2500 |
18 |
п. Симагино |
11 |
2600 |
19 |
Зеленая роща |
19,5 |
2900 |
20 |
д. Ровное |
14 |
2850 |
21 |
п. Симагино |
50 |
3500 |
22 |
п. Вязы |
10 |
4400 |
23 |
п. Симагино |
59 |
7000 |
24 |
Лейпясуо |
7,3 |
630 |
25 |
Кирилловское |
9 |
100 |
26 |
Кирилловское |
6 |
500 |
27 |
Каннельярви |
13,5 |
550 |
28 |
д. Лужайка |
7,5 |
220 |
29 |
Лейпясуо |
10 |
900 |
30 |
п. Вязы |
10 |
4400 |
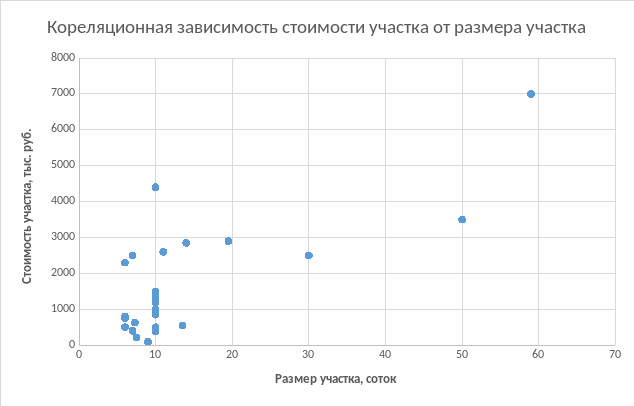
Табл.3.2.
ВЫВОД ИТОГОВ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Регрессионная статистика |
|
|
|
|
|
|
|
|
Множественный R |
0,693216 |
|
|
|
|
|
|
|
R-квадрат |
0,480548 |
|
|
|
|
|
|
|
Нормированный R-квадрат |
0,461996 |
|
|
|
|
|
|
|
Стандартная ошибка |
1154,785 |
|
|
|
|
|
|
|
Наблюдения |
30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Дисперсионный анализ |
|
|
|
|
|
|
||
|
df |
SS |
MS |
F |
Значимость F |
|
|
|
Регрессия |
1 |
34542327 |
34542327 |
25,90297 |
2,17E-05 |
|
|
|
Остаток |
28 |
37338770 |
1333528 |
|
|
|
|
|
Итого |
29 |
71881097 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-Значение |
Нижние 95% |
Верхние 95% |
Нижние 95,0% |
Верхние 95,0% |
Y-пересечение |
491,3988 |
312,6417 |
1,571763 |
0,127239 |
-149,019 |
1131,816 |
-149,019 |
1131,816 |
Переменная X 1 |
89,28074 |
17,54216 |
5,089496 |
2,17E-05 |
53,34726 |
125,2142 |
53,34726 |
125,2142 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ВЫВОД ОСТАТКА |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Наблюдение |
Предсказанное Y |
Остатки |
|
|
|
|
|
|
1 |
1384,206 |
-984,206 |
|
|
|
|
|
|
2 |
1116,364 |
-716,364 |
|
|
|
|
|
|
3 |
1384,206 |
-884,206 |
|
|
|
|
|
|
4 |
1027,083 |
-277,083 |
|
|
|
|
|
|
5 |
1027,083 |
-237,083 |
|
|
|
|
|
|
6 |
1027,083 |
-227,083 |
|
|
|
|
|
|
7 |
1384,206 |
-994,206 |
|
|
|
|
|
|
8 |
1384,206 |
-534,206 |
|
|
|
|
|
|
9 |
1384,206 |
-484,206 |
|
|
|
|
|
|
10 |
1384,206 |
-384,206 |
|
|
|
|
|
|
11 |
1384,206 |
-184,206 |
|
|
|
|
|
|
12 |
1384,206 |
-84,2062 |
|
|
|
|
|
|
13 |
1384,206 |
-24,2062 |
|
|
|
|
|
|
14 |
1384,206 |
115,7938 |
|
|
|
|
|
|
15 |
1027,083 |
1272,917 |
|
|
|
|
|
|
16 |
1116,364 |
1383,636 |
|
|
|
|
|
|
17 |
3169,821 |
-669,821 |
|
|
|
|
|
|
18 |
1473,487 |
1126,513 |
|
|
|
|
|
|
19 |
2232,373 |
667,6268 |
|
|
|
|
|
|
20 |
1741,329 |
1108,671 |
|
|
|
|
|
|
21 |
4955,436 |
-1455,44 |
|
|
|
|
|
|
22 |
1384,206 |
3015,794 |
|
|
|
|
|
|
23 |
5758,963 |
1241,037 |
|
|
|
|
|
|
24 |
1143,148 |
-513,148 |
|
|
|
|
|
|
25 |
1294,925 |
-1194,93 |
|
|
|
|
|
|
26 |
1027,083 |
-527,083 |
|
|
|
|
|
|
27 |
1696,689 |
-1146,69 |
|
|
|
|
|
|
28 |
1161,004 |
-941,004 |
|
|
|
|
|
|
29 |
1384,206 |
-484,206 |
|
|
|
|
|
|
30 |
1384,206 |
3015,794 |
|
|
|
|
|
|
Раскроем содержание вывода итогов и условных обозначений.
Таблица «Регрессионная статистика»:
· Множественный R – коэффициент корреляции, в нашем примере – парный коэффициент корреляции (Rмнож.=0,693216), коэффициент корреляции говорит о тесноте связи, по шкале в нашем случае связь умеренная (средняя);
Шкала меры тесноты связи:
До 0,3 - связь практически отсутствует;
0,3 – 0,5 - связь слабая;
0,5 – 0,7 - связь умеренная (средняя);
0,7 – 0,9 - связь тесная (сильная);
0,9-0,99 – связь очень тесная (близка к функциональной).
· R-квадрат – коэффициент детерминации;
· Нормированный R2 - это тот же коэффициент детерминации, но скорректированный на величину выборки. Нормированный R2=1-(1-R2)*((n-1)/(n-k)), где n - число наблюдений; k - число параметров в уравнении регрессии. Нормированный R2 предпочтительнее использовать в случае добавления новых регрессоров (факторов), т.к. при их увеличении будет также увеличиваться значение R2, однако это не будет свидетельствовать об улучшении модели. Коэффициент детерминации говорит о том, что чем ближе коэффициент детерминации к единице, тем сильнее факторный признак влияет на результативный, и тем теснее связь между ними (R2=0,480548);
· Стандартная ошибка показывает, на какую величину в среднем по всем наблюдениям фактические значения результативного признака
будут отклоняться от их значений, определенных по уравнению регрессии. Стандартная ошибка =1154,785
· Наблюдения - указывается число наблюдений.
Таблица «Дисперсионный анализ»:
· В первой графе таблицы представлены источники вариации зависимой переменной – регрессионная вариация (обусловленная влиянием изу-чаемого фактора), остаточная (влияние прочих факторов) и общая ва-риация (влияние всех причин);
В первой графе таблицы представлены источники вариации зависимой пере-менной – регрессионная вариация (обусловленная влиянием изучаемого фак-тора), остаточная (влияние прочих факторов) и общая вариация (влияние всех причин);
· В столбце d.f. (degree of freedom) приводится число степеней свободы для каждого из источников вариации: d.f.общ. = n-1=30-1=29; d.f.регр.=m-1=2-1=1, где m –число параметров в уравнении регрессии; d.f.ост.= 29-1=28 (n-1)-( m-1);
· В столбце SS (sum of squares) представлены суммы квадратов отклоне-ний или объемы вариации зависимой переменной по источникам ее возникновения, SSост.+SSрег.=SSобщ.-Закон разложения вариации, SSрег=-34542327 влияние фактора размер участка, SSост.= 37338770-влияние остальных факторов, SSобщ.= 71881097-влияние всех факторов, ;
· MS (mid square) – средний квадрат отклонений или дисперсия зависи-мой переменной по источникам вариации; MS=SS/ d.f.
MSрег.= 34542327
MSост.= 1333528
Если MSрег,> MSост.( 34542327>1333528), то мы должны проверить фактическое значение Фишера
· F - это фактическое значение критерия Фишера, определенное как от-ношение регрессионной дисперсии к остаточной (если первая больше
второй). Сравним фактическое значение критерия Фишера и его табличное значение, чтобы убедиться, что модель достоверна.
Fфакт.= 25,90297
Fтабл.=4,60
Fфакт.> Fтабл. (25,90>4,60), значит можно утверждать, что данная модель достоверна.
· Значимость критерия Фишера: уровень значимости - это допустимая вероятность отвергнуть в результате проверки верную нулевую гипотезу. В рассматриваемом случае это означает вероятность признания по выборке наличие связи между переменными в генеральной совокупности, когда на самом деле ее там нет. Обычно уровень значимости принимается равным 0,05;
· В столбце «Коэффициенты» представлены параметры уравнения регрессии у=а+вх: «у-пересечение» - это свободный член уравнения регрессии а, коэффициент при переменной х есть коэффициент регрессии в, в нашем случае уравнение регрессии примет вид: у=491,3988+89,28074х;
· Стандартные ошибки параметров показывают, на какую величину в среднем по всем выборкам равного объема выборочные параметры связи (оценки) будут отличаться от истинных, генеральных параметров регрессии;
· t-статистика – это фактическое (выборочное) значение критерия t, которое равно отношению выборочного параметра к его стандартной ошибке;
· P-значение – это уровень значимости отдельных параметров уравнения регрессии; это вероятность того, что критическое значение используемого критерия (t-Стьюдента или t-нормального распределения) превысит значение, вычисленное по выборке. В данном случае сравниваем p-значения с выбранным уровнем значимости (0,05), в нашем случае
Р-значение меньше уровня значимости, значит фактор (балл почв) является подходящим по этому критерию;
· Нижнее 95% и Верхнее 95% - это границы доверительного интервала данного параметра, определенные для 95% уровня вероятности суждения.