

3 курс (заочка) / Доклад - Data Mining / Полезности по теме / Data Mining
.pdf3.8.Обработка с запоминанием
При всех основных методах часто имеет смысл записывать и впоследствии изучать полученную информацию. Для некоторых методов это совершенно очевидно. Например, при построении последовательных моделей и обучении в целях прогнозирования анализируются исторические данные из разных источников и экземпляров информации.
В других случаях этот процесс может быть более ярко выраженным. Деревья решений редко строятся один раз и никогда не забываются. При выявлении новой информации, событий и точек данных может понадобиться построение дополнительных ветвей или даже совершенно новых деревьев.
Некоторые из этих процессов можно автоматизировать. Например, построение прогностической модели для выявления мошенничества с кредитными картами сводится к определению вероятностей, которые можно использовать для текущей транзакции, с последующим обновлением этой модели при добавлении новых (подтвержденных) транзакций. Затем эта информация регистрируется, так что в следующий раз решение можно будет принять быстрее.
4. ПОЛУЧЕНИЕ И ПОДГОТОВКА ДАННЫХ
Сам интеллектуальный анализ данных опирается на построение подходящей модели и структуры, которые можно использовать для обработки, выявления и создания необходимой информации. Независимо от формы и структуры источника данных, информация структурируется и организуется в соответствии с форматом, который позволяет выполнять интеллектуальный анализ данных с максимально эффективной моделью.
Подумайте о комбинировании бизнес-требований по интеллектуальному анализу данных с выявлением существующих переменных (покупатель, стоимость, страна) и созданием новых переменных, которые можно использовать для анализа данных на подготовительном этапе.
Аналитические переменные для данных, полученных из множества различных источников, можно составить в единую, определенную структуру (например, создать класс покупателей определенных уровней и возрастов или класс ошибок определенного типа).
В зависимости от источника данных важно выбрать правильный способ построения и преобразования этой информации, каким бы ни был метод окончательного анализа данных. Этот шаг также ведет к более сложному процессу выявления, сбора, упрощения или расширения информации в соответствии с входными данными (см. рисунок 5).
11

Рисунок 5. Подготовка данных
Источник данных, местоположение и база данных влияют на то, как будет обрабатываться и объединяться информация.
4.1.Опора на SQL
Наиболее простым из всех подходов часто служит опора на базы данных SQL. SQL (и соответствующая структура таблицы) хорошо понятен, но структуру и формат информации нельзя игнорировать полностью. Например, при изучении поведения пользователей по данным о продажах в модели данных SQL (и интеллектуального анализа данных в целом) существуют два основных формата, которые можно использовать: транзакционный и поведенческодемографический.
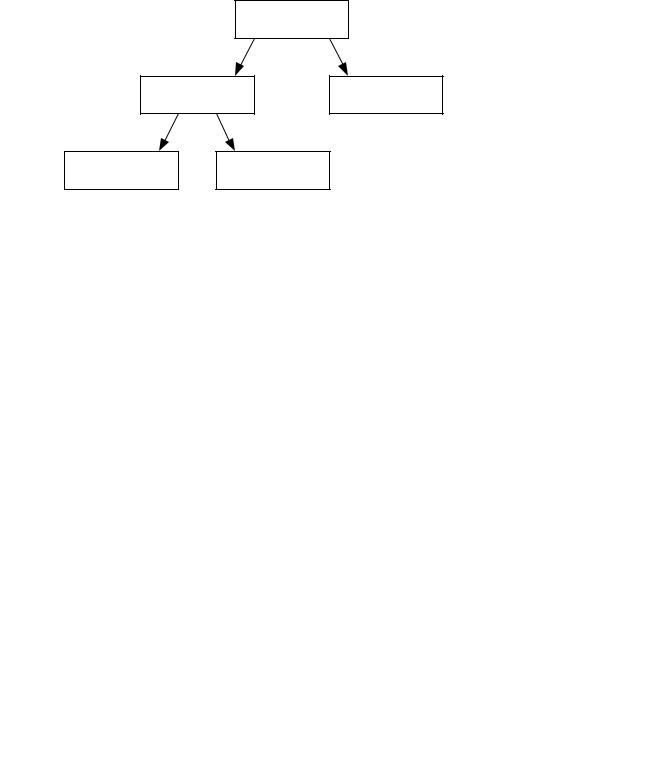
При работе с InfoSphere Warehouse создание поведенческодемографической модели в целях анализа данных о покупателях для понимания моделей их поведения предусматривает использование исходных данных SQL, основанных на информации о транзакциях, и известных параметров покупателей с организацией этой информации в заранее определенную табличную структуру. Затем InfoSphere Warehouse может использовать эту информацию для интеллектуального анализа данных методом кластеризации и классификации с целью получения нужного результата. Демографические данные о покупателях и данные о транзакциях можно скомбинировать, а затем преобразовать в формат, который допускает анализ определенных данных, как показано на рисунке 6.
12
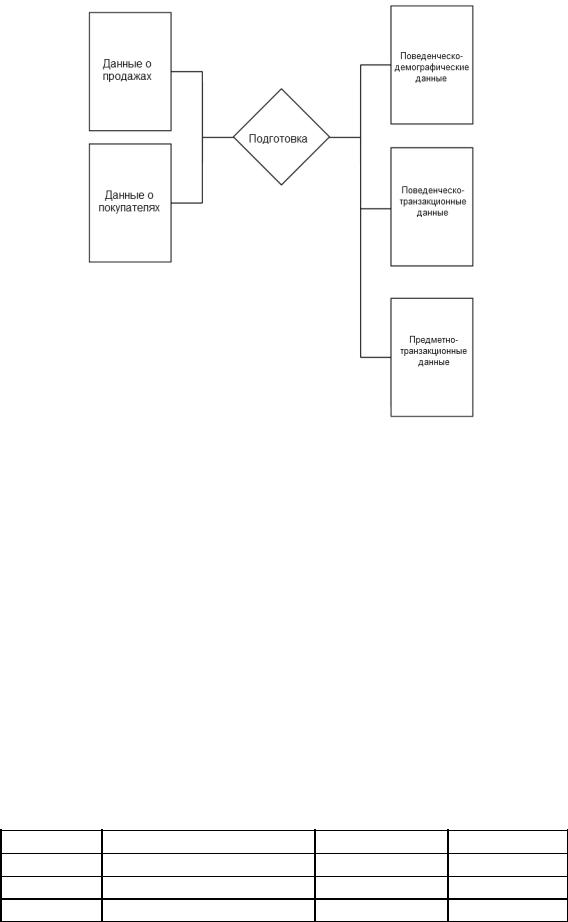
Рисунок 6. Специальный формат анализа данных
Например, по данным о продажах можно выявить тенденции продаж конкретных товаров. Исходные данные о продажах отдельных товаров можно преобразовать в информацию о транзакциях, в которой идентификаторы покупателей сопоставляются с данными транзакций и кодами товаров. Используя эту информацию, легко выявить последовательности и отношения для отдельных товаров и отдельных покупателей с течением времени. Это позволяет InfoSphere Warehouse вычислять последовательную информацию, определяя, например, когда покупатель, скорее всего, снова приобретет тот же товар.
Из исходных данных можно создавать новые точки анализа данных. Например, можно развернуть (или доработать) информацию о товаре путем сопоставления или классификации отдельных товаров в более широких группах, а затем проанализировать данные для этих групп, вместо отдельных покупателей.
В таблице 1 приведен пример расширения информации.
|
Таблица 1. Расширенная таблица товаров |
||
product_id |
product_name |
product_group |
product_type |
101 |
Клубника неупакованная |
Клубника |
Фрукты |
102 |
Клубника в коробках |
Клубника |
Фрукты |
110 |
Бананы неупакованные |
Бананы |
Фрукты |
|
13 |
|
|
5. ЛАБОРАТОРНЫЕ РАБОТЫ
5.1.Цель лабораторной работы
Освоение методов интеллектуального анализа данных, в частности: классификации объектов БД методом построения дерева решений; выявление связей между объектами БД методом ассоциаций.
5.2.Задачи лабораторной работы
1.На основании модели предметной области из перечня объектовклассов выбрать 1-2 наиболее важных, для которых могут существовать варианты (экземпляры классов). Определить для этих объектов – классов не менее 3-х свойств, на основе которых экземпляры классов могут быть разбиты на подклассы. Например, по содержанию предметной области, необходимо арендовать помещение (под офис, под магазин и т.п.). Выбор осуществляется на основе следующих свойств: цена за кв.м.; площадь, качество отделки помещения (высокое, среднее, низкое); расстояние от метро (0 мин., до 10 минут, до 20 минут) и т.п. На основе этих параметров сформировать прототип реляционной Базы Данных (РБД) из 15 записей с описанием конкретных помещений. Задача состоит в том, чтобы разбить имеющиеся варианты на 3 класса (например: евро-класс (1), бизнес – класс (2), эконом – класс (3)).
2.На основе той же модели предметной области сформировать прототип РБД из 15-ти транзакций, т.е. последовательности записей типа: (письменный стол, кресло, компьютер, офис), (обеденный стол, меню, кафе), (кресло, стол, настольная лампа, кабинет) и т.п.
3.Решить задачу классификации записей БД (п. 1) методом построения дерева решений. Обосновать порядок применения свойств для классификации объектов, выявить взаимосвязь данных, разработать правила классификации применить метод прироста информации (метод энтропии).
4.Выявить наиболее сильные взаимосвязи между элементами транзакций (гипотезами правил типа «если, то….») на основе вычисления значений достоверности, поддержки, лифта, левериджа, улучшения для разработанных гипотез, применить метод ассоциации.
5.3.Порядок решения задачи
1.Создать два прототипа РБД (15 записей).
2.Наполнить Хранилище Данных первичной информацией из прототипов РБД.
3.Провести анализ данных и их классификацию на основе метода дерева решений. Результат представить в виде дерева.
14
4. Сформировать множество гипотез правил на основании метода ассоциаций, найти наиболее сильное и наиболее слабое правила и доказать это расчетами. Расчеты лифта, левереджа осуществить вручную.
5.4.Представление результатов
Вотчет о результатах лабораторной работы входят:
результаты по дереву решений:
Прототип РБД;
Имена классов для разбиения объектов РБД на классы;
Расчеты по выбору порядка применения свойств для классификации объектов (видеоформы);
Дерево решений, классы объектов, классификационные правила (видеоформы и вручную).
результаты по методу ассоциации:
Прототип РБД;
наиболее вероятное ассоциативное правило и расчеты его достоверности, поддержки, лифта, левереджа и улучшения (видеоформы и вручную);
Результаты сравнения расчетов по ассоциативному правилу и обоснованный вывод о наиболее значимом ассоциативном правиле.
6.ТЕОРЕТИЧЕСКИЕ УКАЗАНИЯ ПО ВЫПОЛНЕНИЮ ЛАБОРАТОРНОЙ РАБОТЫ
Классификацию данных можно рассматривать как процесс, состоящий из двух этапов. На первом этапе строится модель, описывающая предварительно определенный набор классов или категорий. Модель строится на основе анализа данных, содержащих признаки (атрибуты) объектов и соответствующую им метку класса. Такой набор называется обучающей выборкой. В контексте классификации записи могут упоминаться как наблюдения, примеры, прецеденты или объекты.
Поскольку метка класса каждого примера предварительно задана, построение классификационной модели часто называют обучением с учителем. В процессе обучения формируются правила, по которым производится оттеснение объектов к одному из классов.
На втором этапе модель применяется для классификации новых, ранее не известных объектов и наблюдений. Перед этим оценивается точность построенной классификационной модели.
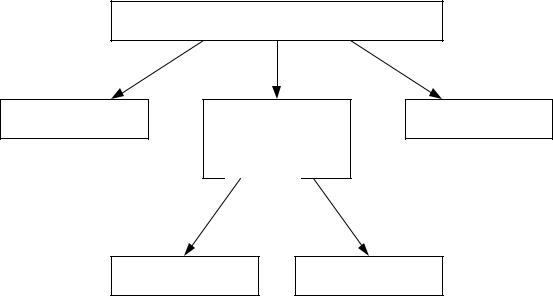
Деревья решений (деревья классификаций) – классификационная техника, в ходе которой решающие правила извлекаются непосредственно из
15
исходных данных в процессе обучения. Дерево решений – это иерархическая модель, где в каждом узле производится проверка определенного атрибута(признака) с помощью правила. Каждая выходящая из узла ветвь есть результат проверки, она содержит объекты, для которых значения данного атрибута удовлетворяют правилу в узле. Каждый конечный узел дерева(лист) содержит объекты, относящиеся к одному классу.
Пример дерева решений
Классический алгоритм построения деревьев решений использует стратегию «разделяй и властвуй». Начиная с корневого узла, где присутствуют все обучающие примеры, происходит их разделение на два подмножества или более на основе значений атрибута, выбранных в соответствии с критерием (правилом) разделения. Для каждого подмножества создается дочерний узел, с которым оно ассоциируется. Затем процесс ветвления повторяется для каждого дочернего узла до тех пор, пока не будет выполнено одно из условий остановки алгоритма, что служит упрощению дерева. Упрощение дерева заключается в том, что после его построения удаляется те ветви, правила в которых имеют низкую ценность, поскольку относятся к небольшому числу примеров.
Мерой оценки возможного разбиения является так называемая чистота, под которой понимается отсутствие примесей. Низкая чистота означает, что в подмножестве представлены объекты, относящиеся к различным классам. Высокая чистота свидетельствует о том, что члены отдельного класса доминируют. Наилучшим разбиением можно назвать то, которое дает наибольшее увеличение чистоты дочерних узлов относительно родительского. Кроме того, хорошее разбиении должно создавать узлы примерно одинакового размера или как минимум не создавать узлы, содержащие всего несколько записей.
Рассмотрим пример Дерева решений для следующей модели базы данных различных помещений:
16
|
|
Качество |
Близость к |
Метка |
Помещение |
Площадь |
отделки |
метро |
класса |
1 |
Большая |
Высокое |
Близко |
1(ЭЛИТ) |
2 |
Большая |
Среднее |
Близко |
2(БИЗНЕС) |
3 |
Малая |
Низкое |
Далеко |
3(ЭКОНОМ) |
4 |
Малая |
Высокое |
Близко |
1(ЭЛИТ) |
5 |
Средняя |
Среднее |
Очень Далеко |
3(ЭКОНОМ) |
6 |
Большая |
Высокое |
Близко |
1(ЭЛИТ) |
7 |
Малая |
Низкое |
Очень Далеко |
3(ЭКОНОМ) |
8 |
Средняя |
Среднее |
Близко |
2(БИЗНЕС) |
9 |
Малая |
Низкое |
Очень Далеко |
3(ЭКОНОМ) |
10 |
Средняя |
Высокое |
Близко |
1(ЭЛИТ) |
1.Выбираем критерий наилучшего ветвления, то есть атрибут который даст наиболее чистое разбиение на классы. Для этого просчитаем возможные варианты разбиения на классы:
При разбиении по атрибуту Площадь мы будем иметь: Большая площадь: 2 объекта 1го класса и 1 объект 2го класса.
Средняя площадь: 1 объект 1го класса, 1 объект 2го класса и 1 объект 3го класса.
Малая площадь: 3 объекта 3го класса и 1 объект 1го класса. Как можно видеть, чистых классов при данном разбиении нет. При разбиении по атрибуту Качество отделки мы будем иметь: Высокое: 4 объекта 1го класса Среднее: 2 объекта 2го класса и 1 объект 3го класса Низкое: 3 объекта 3го класса
При разбиении по атрибуту Качество отделки мы можем видеть появление двух чистых классов(Высокое и низкое).
Аналогичным образом проверяются третий и любой последующий параметры, если они существуют.
В данном случае очевидно, что параметр Качество отделки дает наиболее чистое разбиение.
2.В случае если первое разбиение дает хотя бы один не чистый класс, для этого класса производится дополнительное разбиение по одному из оставшихся атрибутов, выбор которых производится аналогично. В нашем случае этим параметром будет Близость к метро.
Таким образом итоговое дерево будет выглядеть следующим образом:
17
КРИТЕРИИ ОЦЕНКИ И ЗАЩИТЫ ЛАБОРАТОРНЫХ РАБОТ
Лабораторные занятия оцениваются в два этапа:
1)Проведение непосредственно самой лабораторной работы.
2)Защита теоретических знаний, относящихся к лабораторной работе.
Лабораторные занятия оцениваются по пятибалльной системе:
-Оценка в «5 баллов» выставляется в том случае, если студент глубоко и прочно освоил суть лабораторный работы, умеет тесно связывать теорию с практикой. Проведение лабораторной работы выполнено без каких-либо нарушений, защита теоретической части изложено исчерпывающе полно, последовательно, четко и логически стройно.
-Оценка в «4 балла» выставляется тогда, когда студент освоил суть лабораторной работы, при проведении которой не было обнаружено каких-либо грубых нарушений. Защита теоретической части изложено грамотно, без существенных неточностей.
-Оценка в «3 балла» выставляется, если студент имеет знания основного теоретического материала, но не усвоил его деталей. В ходе лабораторной работы обнаружены какие-либо неточности.
-Оценка в «2 балла и ниже» выставляется тогда, когда студент не знает значительную часть или вообще не знает теоретический материал. Лабораторные работы проводились неуверенно и с большими затруднениям, а при защите теоретических знаний допущены существенные ошибки.
18
СПИСОК ЛИТЕРАТУРЫ Основная литература
1.Статистическая обработка данных в учебно-исследовательских работах [Текст] : учебное пособие / П. А. Волкова, А. Б. Шипунов. - М. : ФОРУМ, 2012.
-96 с.
2.Теория планирования эксперимента и анализ статистических данных [Текст] : учебное пособие для магистров : для студентов вузов, обучающихся по специальности "Прикладная математика" / Н. И. Сидняев. - М. : Юрайт, 2012. - 399 с.
Дополнительная литература
3.1 Алгоритмы построение и анализ [Текст] = Introduction to Algorithms : учебник ; пер. с англ. / Т. Кормен, Ч. Лейзерсон, Р. Риверс ; пер. под ред. А.
Шеня. - М. : МЦНМО, 2000. - 960 с.
4.Data Mining [Текст] / Дюк В., Самойленко А. - СПб. ; М. ; Харьков :
Питер, 2001. - 366 с.
5.Программное обеспечение анализа интерференционных систем в сейсморазведке [Text] : методические указания к лабораторным работам по курсу "Программно-алгоритмическое обеспечение оптимизации полевых геофизических работ" для студ.спец.08.04.09 "Геофизические методы поисков и разведки полезных ископаемых" очной и заочной форм обучения / сост.Туренко С.К., состКайгородов Е.П. - Тюмень : ТюмГНГУ, 2000. - 28 с
6.Анализ данных на компьютере [Text] : учебные пособия для вузов / Ю.Н. Тюрин, А.А. Макаров; ред. В.Э. Фигурнов. - М. : Мнфра-м;Финансы и статистика, 1995. - 384 с.
19
ТЕХНОЛОГИЯ ИНТЕЛЛЕКТУАЛЬНОГО АНАЛИЗА ДАННЫХ
Методические указания по курсу «Технология интеллектуального анализа данных»
для студентов всех форм обучения направления 230400.62 «Информационные системы и технологии»
Составитель: Поспелов Виталий Евгеньевич
Подписано в печать 17.01.2014. Формат 60х90 1/16. Усл. печ. л. 1,25. Тираж 45 экз. Заказ № 61.
Библиотечно-издательский комплекс федерального государственного бюджетного образовательного
учреждения высшего профессионального образования «Тюменский государственный нефтегазовый университет». 625000, Тюмень, ул. Володарского, 38.
Типография библиотечно-издательского комплекса. 625039, Тюмень, ул. Киевская, 52.
4