

Лабораторные работы / lab3 / lab3
.docxМИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ
РОССИЙСКОЙ ФЕДЕРАЦИИ
Московский Политехнический Университет (МПУ)
Кафедра «Автоматика и управление»»
ЛАБОРАТОРНАЯ РАБОТА №3
по дисциплине
«Технологии нейронных сетей принятия решений»
Выполнил:
Преподаватель:
\
к.т.н. доцент
Цель работы: создание модели нейронной сети распознавания букв латинского алфавита.
Используемое оборудование: MatLab 2010b
Теоретическое введение
Нейронные сети часто используются в задачах распознавания образов, в данной лабораторной работе рассмотрим распознавание букв латинского алфавита.
При считывании изображения в MatLab (к примеру JPEG картинки) создаётся матрица AxBx3, где AxB – значение ширины и высоты изображения, 3 слоя соответствуют целочисленным значениям цветов RGB (Red,Green,Blue) от 0 до 255. Это означает, что подавать считанный файл изображения напрямую во входной слой сети нельзя, так как он не подходит по формату (необходим вектор-строка)

Рис.1.1 Представление JPEG рисунка – буквы Z в виде матрицы в MatLab.
В случае латинского алфавита в MatLab уже есть готовая интерпретация. М-функция prprob определяет 26 векторов входа, каждый из которых содержит 35 элементов, этот массив называется алфавитом.
М-функция формирует выходные переменные alphabet и targets которые определяют массивы алфавита и целевых векторов. Для того чтобы восстановить шаблон для i-й буквы алфавита, надо выполнить следующие операторы:
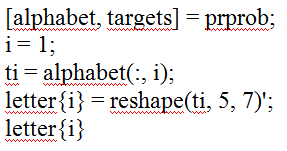

Рис.1.2 Функция prprob в MatLab.
Сам вектор, для подачи на вход сети:
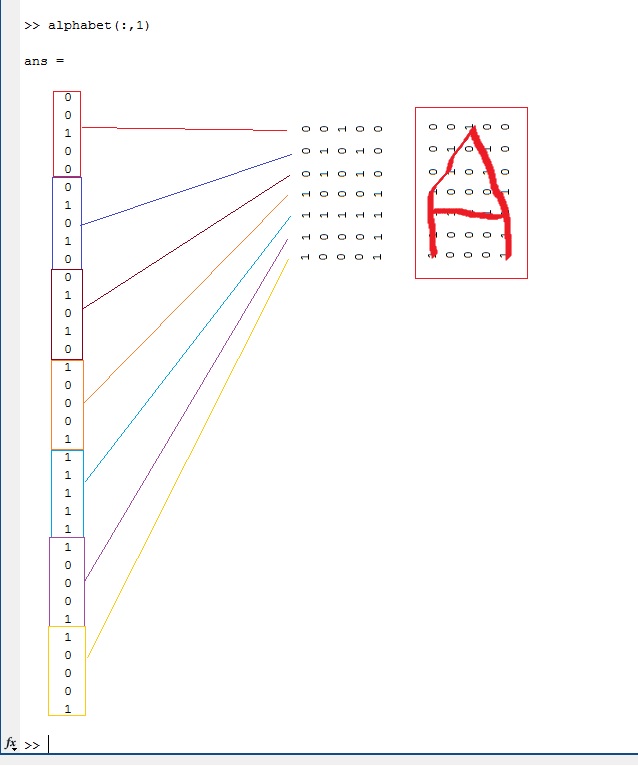
Рис.1.2 Входной вектор буквы «А» для нейронной сети.
Задача: требуется создать нейронную сеть для распознавания 26 символов латинского алфавита.
Выполнение
Для распознавания 26 символов латинского алфавита, получаемых, например, с помощью системы распознавания, выполняющей оцифровку каждого символа в ее поле зрения, используется сеть из двух слоев, не считая входного, с n (10) нейронами в скрытом слое и p (26) нейронами в выходном (по одному на букву). Каждый символ представляется шаблоном размера 7-5, соответствующим пиксельной градации букв.
Для идеального случая на входе – 35 (7*5) значений от 0 до 1, где 1 отчётливое изображение, 0 – отсутствие изображения. Шум может изменить значения, тем самым они могут превышать «эталонные» границы.

Рис.1.3 Представление буквы «А» в виде матрицы 7х5 с коэффициентами 0..1
Предполагается, что шум – это случайная величина со средним значением 0 и стандартным отклонением, меньшим или равным 0.2.
Для работы нейронной сети требуется 35 входов и 26 нейронов в выходном слое. Для решения задачи выберем двухслойную нейронную сеть с логарифмическими сигмоидальными функциями активации (logsig) в каждом слое. Такая функция активации выбрана потому, что диапазон выходных сигналов для этой функции определен от 0 до 1, и этого достаточно, чтобы сформировать значения выходного вектора.
Скрытый слой имеет 10 нейронов. Если при обучении сети возникнут затруднения, то можно увеличить количество нейронов этого уровня. Сеть обучается так, чтобы сформировать единицу в единственном элементе вектора выхода, позиция которого соответствует номеру буквы в алфавите, и заполнить остальную часть вектора нулями.
Вызовем М-файл prprob, который формирует массив векторов входа alphabet размера 35х26 с шаблонами символов алфавита и массив целевых векторов:

Рис.1.4 Обучение сети идеальными векторами алфавита
Чтобы спроектировать нейронную сеть, не чувствительную к воздействию шума, обучим ее с применением двух идеальных и двух зашумленных копий векторов алфавита. Целевые векторы состоят из четырех копий векторов. Зашумленные векторы имеют шум со средним значением 0.1 и 0.2. Это обучает нейрон правильно распознавать зашумленные символы и в то же время хорошо распознавать идеальные векторы.
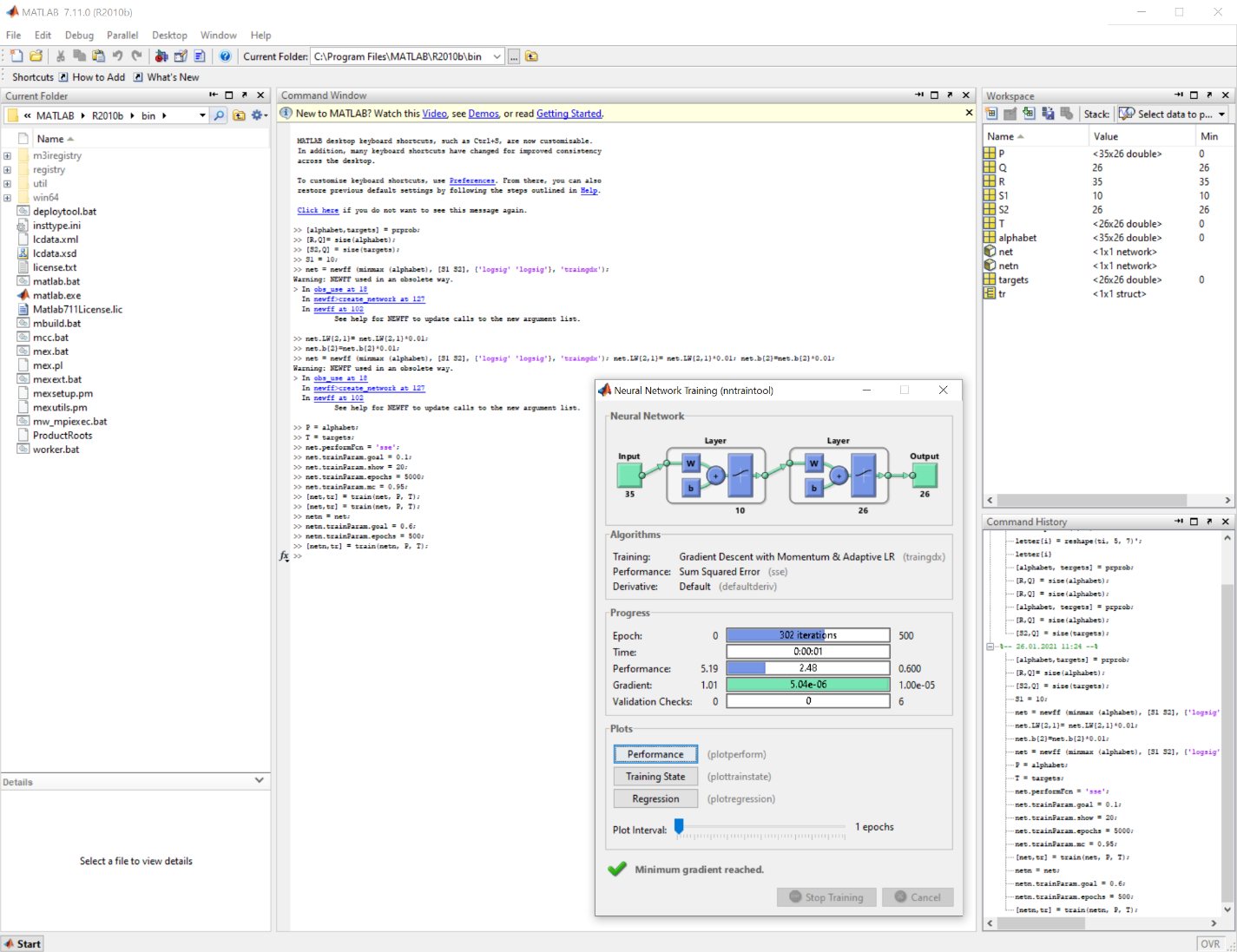
Рис.1.5 Обучение сети “netn” идеальными векторами алфавита после обучения зашумлёнными.
>> net.LW{2,1}= net.LW{2,1}*0.01;
>> net.b{2}=net.b{2}*0.01;
>> net = newff (minmax (alphabet), [S1 S2], {'logsig' 'logsig'}, 'traingdx'); net.LW{2,1}= net.LW{2,1}*0.01; net.b{2}=net.b{2}*0.01;
Warning: NEWFF used in an obsolete way.
> In obs_use at 18
In newff>create_network at 127
In newff at 102
See help for NEWFF to update calls to the new argument list.
>> P = alphabet;
>> T = targets;
>> net.performFcn = 'sse';
>> net.trainParam.goal = 0.1;
>> net.trainParam.show = 20;
>> net.trainParam.epochs = 5000;
>> net.trainParam.mc = 0.95;
>> [net,tr] = train(net, P, T);
>> [net,tr] = train(net, P, T)
Протестируем обученную сеть netn – создадим зашумлённый вектор буквы «А»(1.6) и вектор буквы «W»(1.7):
>> netn = net;
>> netn.trainParam.goal = 0.6;
>> netn.trainParam.epochs = 500;
>> [netn,tr] = train(netn, P, T);
>> A = alphabet(:,1)+randn(35,1)*0.2;
>> W = alphabet(:,23)+randn(35,1)*0.2;
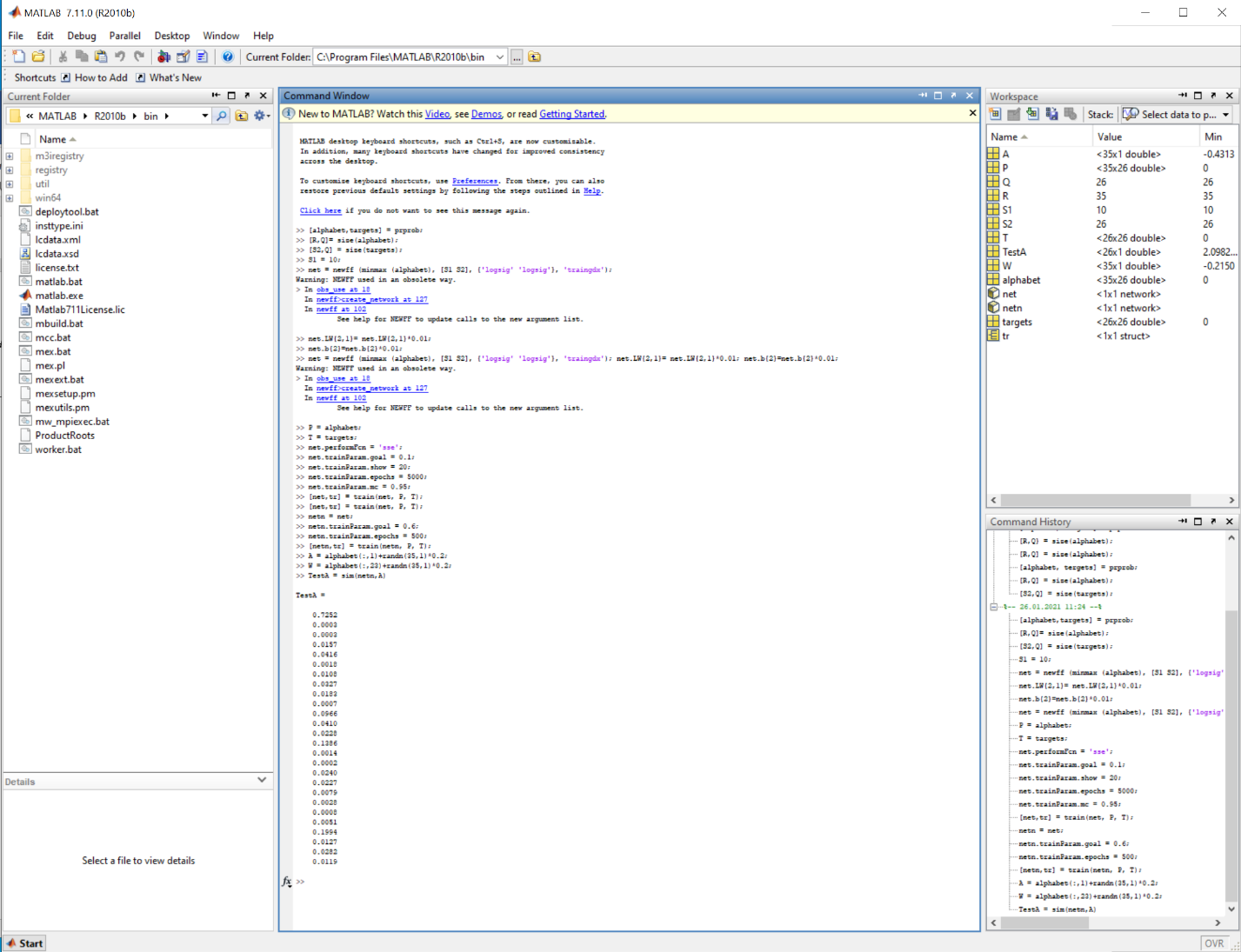
Рис.1.6 Зашумлённый вектор буквы «A».
>> TestA = sim(netn,A)
TestA =
0.7252
0.0003
0.0003
0.0157
0.0416
0.0018
0.0108
0.0327
0.0183
0.0007
0.0966
0.0410
0.0228
0.1386
0.0014
0.0002
0.0240
0.0227
0.0079
0.0028
0.0008
0.0051
0.1994
0.0127
0.0282
0.0119
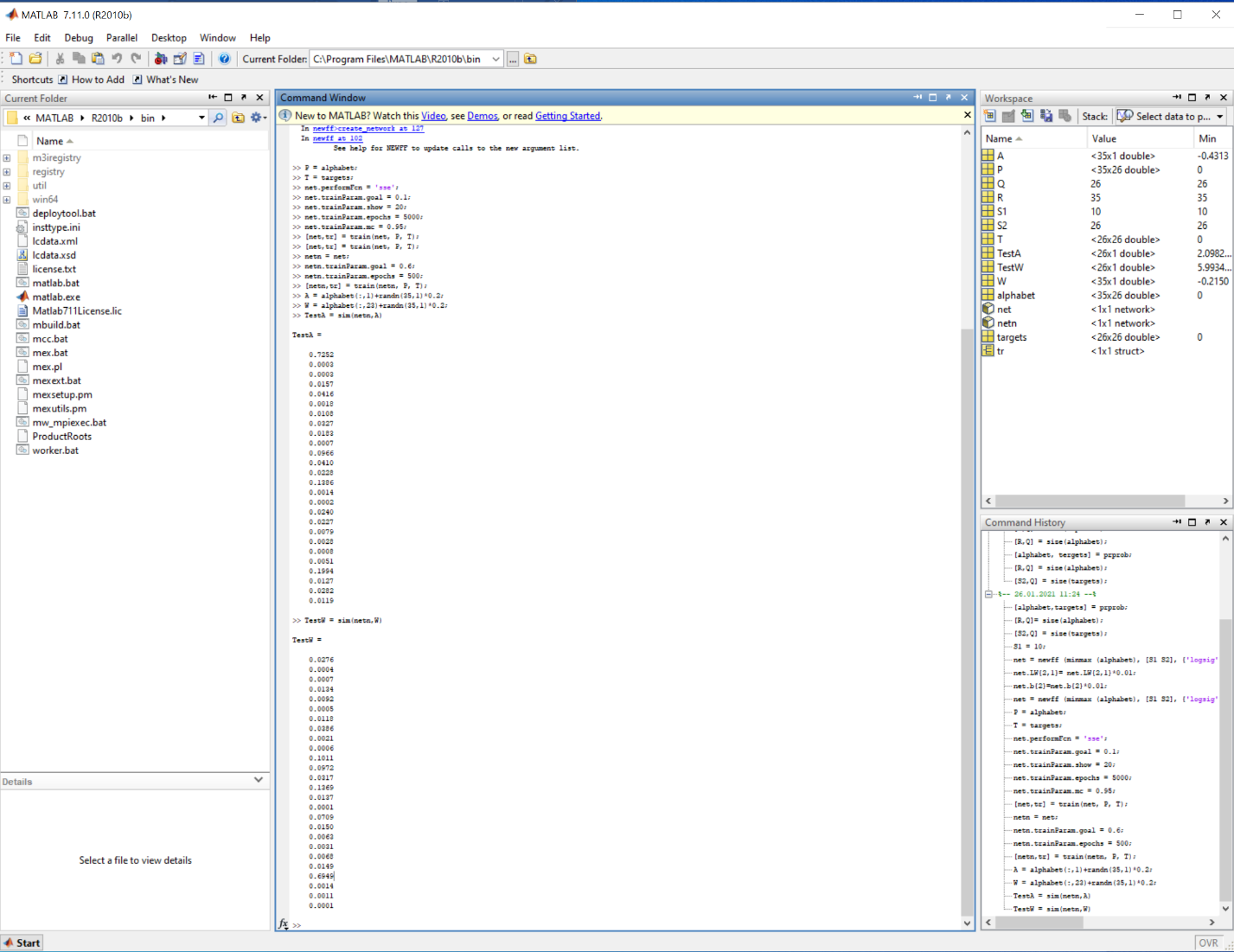
Рис.1.7 Зашумлённый вектор буквы «W».
>> TestW = sim(netn,W)
TestW =
0.0276
0.0004
0.0007
0.0134
0.0092
0.0005
0.0118
0.0386
0.0021
0.0006
0.1011
0.0972
0.0317
0.1369
0.0137
0.0001
0.0709
0.0150
0.0063
0.0031
0.0068
0.0149
0.6949
0.0014
0.0011
0.0001
>>
Как видно из результатов нейронная сеть справилась с задачей и определила 1-ую и 23-ью букву латинского алфавита.
Вывод: во время выполнения данной лабораторной работы мною были получены навыки создания модели нейронной сети распознавания букв латинского алфавита.