

Готовые отчеты / ЛиФП. Лабораторная работа 4
.pdfФедеральное агентство связи ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ
ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ «САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ТЕЛЕКОММУНИКАЦИЙ ИМ. ПРОФ. М. А. БОНЧ-БРУЕВИЧА» (СПбГУТ)
Факультет инфокоммуникационных сетей и систем Кафедра программной инженерии и вычислительной техники
ЛАБОРАТОРНАЯ РАБОТА №4 по дисциплине «Логическое и функциональное программирование»
Выполнил: студент 3-го курса дневного отделения группы ИКПИ-85
Коваленко Леонид Александрович Преподаватель:
доцент кафедры ПИиВТ Ерофеев Сергей Анатольевич
Санкт-Петербург
2020

Постановка задачи
Написать программу на языке Turbo Prolog 2.0 для подсчета числа операций последовательного, бинарного и интерполяционного поисков.
Схема решения Последовательный (линейный) поиск — простейший вид поиска,
который предполагает последовательный просмотр всех элементов.
•Не требует упорядоченности данных.
•Сложность последовательного поиска в худшем случае: O(n) .
Очевидно, что на списке можно организовать только один единственный вид поиска — последовательный (линейный) поиск, пример реализации которого приведен в табл. 1.
Таблица 1 — Последовательный поиск в списке (SWI-Prolog)
/*
Последовательный (линейный) поиск в списке.
Пример: linear_search([1, 2, 3, 4], 3, I) Результат: I = 2
*/
% linear_search(List, Element, [Return] Index) linear_search(L, E, RI) :- linear_search(L, E, 1, RI).
% linear_search(List, Element, CurrentIndex, [Return] Index) linear_search([], _, _, -1) :- !.
linear_search(_, _, CI, -1) :- CI < 0, !. linear_search([X|_], X, CI, CI) :- !.
linear_search([_|Tail], X, CI, RI) :- CI1 is CI + 1, linear_search(Tail, X, CI1, RI)
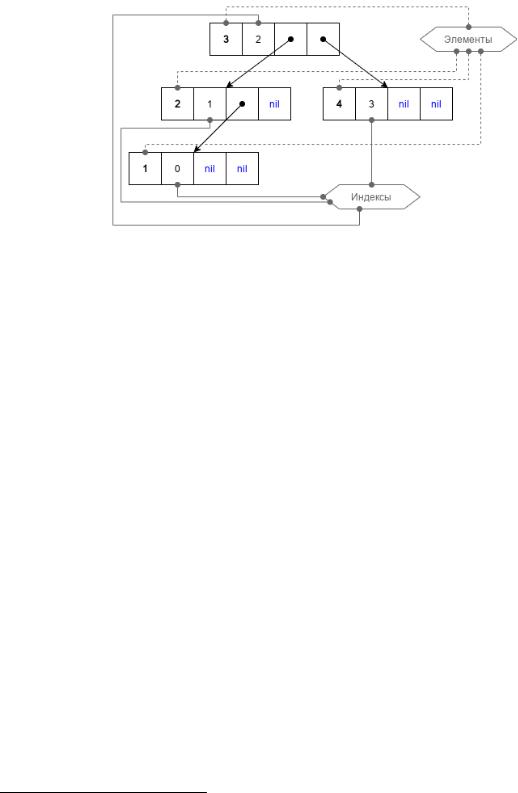
В Prolog можно создавать разные структуры данных. Приведем реализацию последовательного поиска при помощи узловой структуры данных (табл. 2, рис. 1).
Таблица 2 — Последовательный поиск при помощи узловой структуры данных (SWI-Prolog)
/*
Последовательный (линейный) поиск при помощи узловой структуры данных. Пример: linear_construct([1, 2, 3, 4], S), linear_search(S, 3, I)
Результат: S = node(1, 0, node(2, 1, node(3, 2, node(4, 3, nil)))), I = 2 Особый домен: node(Element, Index, NextNode)
*/
% linear_construct(List, [Return] Structure) linear_construct(List, S) :- linear_construct(List, S, 1). linear_construct([], nil, _) :- !. linear_construct([Head|Tail], S, I) :-
S = node(Head, I, Next), I1 is I + 1, linear_construct(Tail, Next, I1).
% linear_search(Structure, Element, [Return] Index) linear_search(nil, _, -1) :- !. linear_search(node(E, I, _), E, I) :- !.
linear_search(node(_, _, Next), E, I) :- linear_search(Next, E, I).
2

Рисунок 1 — Списочная узловая структура Суть этой реализации в том, что создается узловая структура (предикат
linear_construct) для последующего поиска в ней (предикат linear_search). Очевидно, что эта реализация ничем не лучше последовательного
поиска в списке.
Бинарный поиск — алгоритм поиска элемента в отсортированном массиве (векторе), использующий дробление массива на половины.
•Требует упорядоченности данных.
•Сложность бинарного поиска в худшем случае: O(log n) .
Приведем реализацию бинарного поиска при помощи узловой структуры данных (табл. 3).
Таблица 3 — Бинарный поиск при помощи узловой структуры (SWI-Prolog)
/*
Бинарный поиск.
Пример: binary_construct([1, 2, 3, 4], S), binary_search(S, 3, I)
Результат: S = node(t(3, 2), node(t(2, 1), node(t(1, 0), nil, nil), nil), node(t(4, 3), nil, nil)), I = 2
Особые домены: t(Element, Index), node(t(Element, Index), PrevNode, NextNode)
*/
%binary_construct(List, [Return] Structure) binary_construct(List, S) :-
pair_list(List, PairList), quicksort(PairList, SortedPairList), balance_tree(SortedPairList, BalancedList), binary_construct(BalancedList, nil, S), !.
%pair_list(List, [Return] PairList)
pair_list(List, PairList) :- pair_list(List, PairList, 1). pair_list([], [], _) :- !.
pair_list([Head|Tail1], [t(Head, I)|Tail2], I) :-
I1 is I + 1, pair_list(Tail1, Tail2, I1).
%quicksort(List, [Return] SortedList) quicksort([], []).
quicksort([X|Xs], Zs) :- partition(Xs, X, Left, Right), quicksort(Left, Ls), quicksort(Right, Rs), merge(Ls, [X|Rs], Zs).
%quicksort(List, Element, [Return] List[:{Element}], [Return] List[{Element}:]) partition([], _, [], []).
partition([t(X, XI)|Xs], t(Z, ZI), Ls, [t(X, XI)|Rs]) :-
X > Z,
partition(Xs, t(Z, ZI), Ls, Rs).
partition([t(X, XI)|Xs], t(Z, ZI), [t(X, XI)|Ls], Rs) :- X =< Z,
partition(Xs, t(Z, ZI), Ls, Rs).
3

%merge(List1, List2, [Return] List1 + List2) merge([H|Xs], Zs, [H|Ts]) :- merge(Xs, Zs, Ts), !. merge([], Zs, Zs) :- !.
%balance_tree(List, [Return] BalancedList) balance_tree([], []) :- !. balance_tree(List, [H|T]) :-
length(List, Length), Length2 is Length div 2, get(List, Length2, H),
split(List, Length2, U1, [_|U2]), balance_tree(U1, T1), balance_tree(U2, T2),
merge(T1, T2, T), !.
%get(List, Index, [Return] Element)
get([Head|_], |
0, |
X) :- X = Head. |
get([_|Tail], |
I, |
X) :- I1 is I - 1, get(Tail, I1, X). |
get([], _, _) |
:- |
fail. |
% split(List, |
Index, [Return] List[:Index], [Return] List[Index:]) |
|
split([], _, [], |
[]) :- !. |
|
split([H|T1], |
0, |
Left, [H|T2]) :- |
split(T1, |
0, |
Left, T2), !. |
split([H|T1], |
N, |
[H|T2], Right) :- |
N1 is N - |
1, |
|
split(T1, |
N1, T2, Right), !. |
|
%binary_construct(List, ProcStructure, [Return] Structure) binary_construct([], S, S) :- !. binary_construct([Head|Tail], S, RS) :-
binary_construct_aux(Head, S, MS), binary_construct(Tail, MS, RS), !.
%binary_construct_aux(Element, Node1, [Return] Node2) binary_construct_aux(X, nil, node(X, nil, nil)) :- !. binary_construct_aux(t(X, XI), node(ET1, P1, N1), node(ET2, P2, N2)) :-
ET1=t(E1, _), X < E1, binary_construct_aux(t(X, XI), P1, U), (ET2, P2, N2)=(ET1, U, N1), !; ET1=t(E1, _), X > E1, binary_construct_aux(t(X, XI), N1, U), (ET2, P2, N2)=(ET1, P1, U), !; (ET2, P2, N2) = (ET1, P1, N1), !.
%binary_search(Structure, Element, [Return] Index)
binary_search(nil, _, -1) :- !. binary_search(node(t(E, I), _, _), E, I) :- !.
binary_search(node(t(V, _), Prev, _), E, I) :- V > E, binary_search(Prev, E, I), !. binary_search(node(t(V, _), _, Next), E, I) :- V < E, binary_search(Next, E, I), !.
Порядок работы:
1. Каждому элементу сопоставляется его исходный индекс в списке.
Например, для [1, 2, 3, 4] получим [t(1, 0), t(2, 1), t(3, 2), t(4, 3)].
2.Полученный на предыдущем этапе список сортируется. (В примере выше результат первого этапа совпадает с результатом второго.)
3.Полученный на предыдущем этапе список простым образом «балансируется» для последующего построения дерева1.
4.На основе «сбалансированного списка» строится бинарное дерево. Структура данных в результате этого этапа готова для поиска.
5.Производится поиск элементов предикатом binary_search. Балансировка происходит следующим образом:
1.Выбирается серединный элемент списка.
1 Балансировка дерева более трудоемка, поэтому вместо неё «балансируются» элементы списка, на основе которого затем создается дерево.
4
2.Список делится на две части по выбранному элементу списка;
3.Серединный элемент списка становится первым элементом сбалансированного.
4.Далее каждый подсписок обрабатывается рекурсивно, добавляя серединные элементы подсписков в результативный — сбалансированный список.
Рисунок 2 — Бинарная (двоичная) узловая структура Очевидно, что данная реализация гораздо лучше последовательного
поиска в списке по скорости нахождения нужного элемента, однако она требует предварительной обработки и дополнительной памяти.
Интерполяционный поиск — алгоритм предсказания местонахождения элемента: поиск происходит подобно двоичному поиску, но вместо деления области поиска на две части, интерполирующий поиск производит оценку новой области поиска по расстоянию между ключом и текущим значением элемента следующим образом:
|
M=left + |
(key− A [left])(right−left) |
|
|
A[right ]− A [left ] |
||
|
|
||
|
где M — индекс элемента, с которым сравнивается значение ключа, |
||
key |
— ключ (искомый элемент), |
A — массив упорядоченных элементов, |
|
left |
и right — номера крайних элементов области поиска. Важно отметить, |
||
что операция деления в формуле строго целочисленная, т. е. дробная часть, какая бы она ни была, отбрасывается.
•Требует упорядоченности данных.
•Сложность интерполяционного поиска в среднем случае2: O(log log n) .
2Средний случай — равномерное распределение элементов.
5

• Сложность интерполяционного поиска в худшем случае3: O(n) .
Статья Курта Мельхорна и Афанасиоса Цакалидиса («Dynamic Interpolation Search», Kurt Mehlhorn and Athanasios Tsakalidis) гласит следующее: «… the degree of the root is O(√n) . The root splits a file into O(√n) subfiles». Т. е. корень дерева соединен с O(√n) узлами, каждый из которых в свою очередь связан явно или неявно4 с O(√n) узлами. Очевидно, что O(√n) O(√n)=O(n) . Данная структура данных отчасти похожа на B-дерево.
Организовать универсальный (по количеству входных чисел) настоящий интерполяционный поиск на Prolog не представляется
возможным, т. к. сложность получения |
элемента списка — O(n) , |
интерполяционный поиск требует сложности |
O(1) , которая возможна только |
у императивных массивов. А в Prolog нет императивных массивов по сочетанию двух простых причин — длина массива должна быть известна заранее (по определению массива) и массив не может быть изменяемым (по декларативной парадигме).
Дерево — единственная структура данных, которая возможна в Prolog и может обладать наилучшими сложностями вставки и получения элемента
— O(log n) .
Код программы Программа имитирует последовательный, бинарный и
интерполяционный поиски. На вход получает список чисел. На выход выдает местоположение вводимого числа в этом списке и числа итераций поисков.
Входные данные поступают с клавиатуры либо файла, пример содержимого которого приведен в табл. 4.
Таблица 4 — Входные данные в файле
13
7
11
5
3
2
Код программы приведен в табл. 5.
3Пример худшего случая — экспоненциальное возрастание значений элементов.
4Явная связь — связь по одному ребру. Неявная связь — связь по двум или более ребрам (существует маршрут).
6

Таблица 5 — Код программы
NOWARNINGS
% Раздел описания доменов
DOMAINS
file = datafile % Файл datafile
list_of_real = real* % Список вещественных чисел
pair = pair(real, integer) % Пара из вещ. и целого чисел list_of_pair = pair* % Список пар из вещ. и целых чисел list_of_int = integer*
%Раздел описания предикатов PREDICATES
length(list_of_real, integer) length(list_of_pair, integer) input(list_of_real) input_action(list_of_real, integer) read_reals_from_console(list_of_real) read_reals_from_file(list_of_real) pair_list(list_of_real, list_of_pair) pair_list(list_of_real, list_of_pair, integer) quicksort_int(list_of_int, list_of_int) quicksort_pair(list_of_pair, list_of_pair)
partition_int(list_of_int, integer, list_of_int, list_of_int) partition_pair(list_of_pair, pair, list_of_pair, list_of_pair) merge(list_of_int, list_of_int, list_of_int) merge(list_of_pair, list_of_pair, list_of_pair) test(list_of_pair)
get(list_of_pair, integer, pair) linear_search_count(list_of_pair, real, list_of_int) linear_search_count(list_of_pair, real, integer, integer) linear_search_count_main(list_of_pair, real, integer, integer) binary_search_count(list_of_pair, real, list_of_int) binary_search_count(list_of_pair, real, integer, integer)
binary_search_count(list_of_pair, real, integer, integer, integer, integer) binary_search_aux(list_of_pair, real, integer, integer, integer, pair, integer, integer) interpolation_search_count(list_of_pair, real, list_of_int) interpolation_search_count(list_of_pair, real, integer, integer) interpolation_search_count(list_of_pair, real, integer, integer, integer, integer) interpolation_search_aux(list_of_pair, real, integer, integer, integer, pair, integer,
integer) write_all(list_of_int)
del(list_of_pair, integer, list_of_pair)
%Раздел описания внутренней цели
GOAL
input(Reals), % Ввод исходных данных
pair_list(Reals, Pairs), % Создание списка пар вещ. и целых чисел quicksort_pair(Pairs, SortedPairs), % Сортировка списка пар вещ. и целых чисел test(SortedPairs), % Тестирование поисков
readchar(_). % Завершение программы после нажатия клавиши клавиатуры
% Раздел описания предложений CLAUSES
%Длина списка length([], 0). length([_|Xs], N) :-
length(Xs, P),
N = P + 1.
%Ввод исходных данных input(Reals) :-
write("-== MENU ==-"), nl, write("1. Read from console;"), nl, write("2. Read from file."), nl, write("Another button to exit"), nl,
readint(C), % Считывание целого числа input_action(Reals, C), % Ввод length(Reals, Length), Length >= 1; nl.
%Ввод из диалогового окна
input_action(Reals, 1) :- read_reals_from_console(Reals).
% Ввод из файла input_action(Reals, 2) :-
write("File name: "), readln(FileName), % Ввод названия файла
existfile(FileName), % Существует ли файл openread(datafile, FileName), % Открытие файла для чтения readdevice(datafile), % Перенаправление ввода на файл
7

read_reals_from_file(Reals), % Чтение чисел closefile(datafile), !; % Закрытие файла write("Error reading file!"), nl, fail.
% Чтение с консоли read_reals_from_console([Head|Tail]) :-
write("#> "), readreal(Head), % Чтение числа read_reals_from_console(Tail).
read_reals_from_console([]).
% Чтение с файла read_reals_from_file([Head|Tail]) :-
readreal(Head), % Чтение числа read_reals_from_file(Tail).
read_reals_from_file([]).
%Пример содержимого файла:
%47
%53
%59
%41
%5
%7
%Создание списка пар pair(Element, Index)
pair_list(List, PairList) :- pair_list(List, PairList, 1). pair_list([], [], _) :- !.
pair_list([H|T1], [pair(H, I)|T2], I) :- I1 = I + 1,
pair_list(T1, T2, I1).
% Быстрая сортировка quicksort_int([X|Xs], Zs) :-
partition_int(Xs, X, Left, Right), % Разбиение quicksort_int(Left, Ls), % Обработка левой части quicksort_int(Right, Rs), % Обработка правой части merge(Ls, [X|Rs], Zs). % Объединение списков
quicksort_int([], []).
%Пример (для integer):
%quicksort_int([5, 3, 1, 2, 4], X)
%-> X = [1, 2, 3, 4, 5]
quicksort_pair([X|Xs], Zs) :-
partition_pair(Xs, X, Left, Right), % Разбиение quicksort_pair(Left, Ls), % Обработка левой части quicksort_pair(Right, Rs), % Обработка правой части merge(Ls, [X|Rs], Zs). % Объединение списков
quicksort_pair([], []).
%Разбиение списка для integer partition_int([X|Xs], Z, Ls, [X|Rs]) :-
X > Z,
partition_int(Xs, Z, Ls, Rs). partition_int([X|Xs], Z, [X|Ls], Rs) :-
X <= Z,
partition_int(Xs, Z, Ls, Rs). partition_int([], _, [], []).
%Примеры:
%partition_int([1, 2, 3, 4, 5], 2, L, X)
%-> L = [1, 2], X = [3, 4, 5]
%partition_int([1, 2, 3, 4, 5], 4, L, X)
%-> L = [1, 2, 3, 4], X = [5]
%Разбиение списка для pair
partition_pair([pair(X, T)|Xs], pair(Z, ZI), Ls, [pair(X, T)|Rs]) :-
X > Z,
partition_pair(Xs, pair(Z, ZI), Ls, Rs).
partition_pair([pair(X, T)|Xs], pair(Z, ZI), [pair(X, T)|Ls], Rs) :- X <= Z,
partition_pair(Xs, pair(Z, ZI), Ls, Rs). partition_pair([], _, [], []).
% Объединение двух списков
merge([H|Xs], Zs, [H|Ts]) :- merge(Xs, Zs, Ts). merge([], Zs, Zs).
%Пример:
%merge([1, 2, 3], [4, 5, 6], X)
%-> X = [1, 2, 3, 4, 5, 6]
%Тестирование поисков
test(Pairs) :-
write("Enter number: "), readreal(X),
8

linear_search_count(Pairs, X, T1), quicksort_int(T1, ST1), binary_search_count(Pairs, X, T2), quicksort_int(T2, ST2),
interpolation_search_count(Pairs, X, |
T3), quicksort_int(T3, ST3), |
|
write("---------------------- |
"), nl, |
|
write("- Linear search"), nl, write("Position: "), write_all(ST1), nl, write("- Binary search"), nl, write("Position: "), write_all(ST2), nl, write("- Interpolation search"), nl, write("Position: "), write_all(ST3), nl, write("----------------------"), nl,
test(Pairs).
%Получение элемента списка по индексу get([Head|_], 0, X) :- X = Head.
get([_|Tail], I, X) :- I1 = I - 1, get(Tail, I1, X). get([], _, _) :- fail.
%Счетчик последовательного (линейного) поиска linear_search_count([], _, []) :- !. linear_search_count(Pairs, X, List) :-
linear_search_count(Pairs, X, H, K), not(K = -1), del(Pairs, K, T),
linear_search_count(T, X, Tail), List = [H|Tail], !; List = [].
linear_search_count(List, X, N, K) :- linear_search_count_main(List, X, N, K). linear_search_count_main([], _, -1, -1) :- !. linear_search_count_main([pair(X, RI)|_], X, RI, 0) :- !.
linear_search_count_main([_|Tail], X, RI, K) :- linear_search_count_main(Tail, X, RI, KN), not(KN = -1), K = KN + 1.
% Счетчик бинарного (двоичного) поиска binary_search_count([], _, []) :- !. binary_search_count(Pairs, X, List) :-
binary_search_count(Pairs, X, H, K), not(K = -1), del(Pairs, K, T),
binary_search_count(T, X, Tail), List = [H|Tail], !; List = [].
binary_search_count([], _, -1, -1) :- !. binary_search_count(List, X, N, K) :-
length(List, Length), Length > 0, LastIndex = Length - 1,
binary_search_count(List, X, 0, LastIndex, N, K). binary_search_count(List, Value, Low, High, N, K) :-
High < Low, !, N = -1, K = -1; Mid = Low + ((High - Low) div 2), get(List, Mid, MidElem), !,
binary_search_aux(List, Value, Low, Mid, High, MidElem, N, K). binary_search_aux(List, Value, Low, Mid, High, pair(MidElem, MidReal), N, K) :-
MidElem > Value, !, Mid1 = Mid - 1, binary_search_count(List, Value, Low, Mid1, N, K); MidElem < Value, !, Mid1 = Mid + 1, binary_search_count(List, Value, Mid1, High, N, K); N = MidReal, K = Mid.
% Счетчик интерполяционного (интерполирующего) поиска interpolation_search_count([], _, []) :- !. interpolation_search_count(Pairs, X, List) :-
interpolation_search_count(Pairs, X, H, K), not(K = -1), del(Pairs, K, T),
interpolation_search_count(T, X, Tail), List = [H|Tail], !;
List = [].
interpolation_search_count([], _, -1, -1) :- !. interpolation_search_count(List, X, N, K) :-
length(List, Length), Length > 0, LastIndex = Length - 1,
interpolation_search_count(List, X, 0, LastIndex, N, K). interpolation_search_count(List, Value, Low, High, N, K) :-
High < Low, !, N = -1, K = -1;
get(List, Low, pair(LowElem, _)), LowElem < Value, get(List, High, pair(HighElem, _)), HighElem > Value,
Mid = Low + (((Value - LowElem) * (High - Low)) / (HighElem - LowElem)), get(List, Mid, MidElem), !,
interpolation_search_aux(List, Value, Low, Mid, High, MidElem, N, K);
get(List, Low, pair(LowElem, LowReal)), LowElem = Value, !, N = LowReal, K = Low; get(List, High, pair(HighElem, HighReal)), HighElem = Value, !, N = HighReal, K = High;
N = -1, K = -1.
interpolation_search_aux(List, Value, Low, Mid, High, pair(MidElem, MidReal), N, K) :-
MidElem > Value, !, Mid1 = Mid - 1, interpolation_search_count(List, Value, Low, Mid1,
N, K);
MidElem < Value, !, Mid1 = Mid + 1, interpolation_search_count(List, Value, Mid1, High,
N, K);
N = MidReal, K = Mid.
9
%Печать результата write_all([]).
write_all([Head|Tail]) :- write(Head, " "), write_all(Tail).
%Удаление элемента списка по индексу
del([], _, []) :- !. del([_|Tail], 0, List) :-
del(Tail, -1, List), !. del([Head|T1], -1, [Head|T2]) :-
del(T1, -1, T2), !. del([Head|T1], N, [Head|T2]) :-
N1 = N - 1, del(T1, N1, T2).
Тестирование
Программа тестировалась на следующих входных данных (табл. 6). Таблица 6 — Входные данные, на которых тестировалась программа
|
Число для |
|
|
Число итераций |
|
|
Ряд чисел |
Позиция |
|
|
|
||
Последовател |
Бинарный |
Интерполяци |
||||
|
поиска |
|
ьный поиск |
поиск |
онный поиск |
|
|
|
|
||||
|
|
|
|
|
|
|
|
9 |
-1 |
8 |
4 |
0 |
|
|
|
|
|
|
|
|
|
8 |
1 |
7 |
4 |
0 |
|
8 |
|
|
|
|
|
|
7 |
2 |
6 |
3 |
1 |
||
7 |
|
|
|
|
|
|
6 |
3 |
5 |
2 |
1 |
||
6 |
||||||
|
|
|
|
|
||
5 |
4 |
4 |
3 |
1 |
||
5 |
||||||
4 |
4 |
5 |
3 |
1 |
1 |
|
3 |
|
|
|
|
|
|
3 |
6 |
2 |
3 |
1 |
||
2 |
||||||
|
|
|
|
|
||
1 |
2 |
7 |
1 |
2 |
1 |
|
|
|
|
|
|
|
|
|
1 |
8 |
0 |
3 |
0 |
|
|
|
|
|
|
|
|
|
0 |
-1 |
8 |
3 |
0 |
Обнаруженные закономерности при тестировании:
•Последовательный поиск: O(n) .
•Бинарный поиск: O(log n) .
•Интерполяционный поиск: O(log log n)— O(n) . Равномерно: 1+ log log n .
Входные данные для этого примера приведены в табл. 7. Таблица 7 — Файл с входными данными
8
7
6
5
4
3
2
1
10