

пособие_ism
.pdfРисунок 5.29 – Стрелка вызова работы "Сборка и тестирование компьютеров" модели-цели
Для слияния моделей нужно щелкнуть правой кнопкой мыши по работе со стрелкой вызова в модели-цели и во всплывающем меню вы-
брать пункт Merge Model.
Появляется диалог, в котором следует указать опции слияния модели (рисунок 5.30). При слиянии моделей объединяются и словари стрелок и работ. В случае одинаковых определений возможна перезапись определений или принятие определений из модели-источника. То же относится к именам стрелок, хранилищам данных и внешним ссылкам.
Рисунок 5.30 – Диалог Continue with merge
90
После подтверждения слияния (кнопка OK) модель-источник подсоединяется к модели-цели, стрелка вызова исчезает, а работа, от которой отходила стрелка вызова, становится декомпозируемой – к ней подсоединяется диаграмма декомпозиции первого уровня моделиисточника. Стрелки, касающиеся работы на диаграмме модели-цели, автоматически не мигрируют в декомпозицию, а отображаются как неразрешенные. Их следует туннелировать вручную.
Впроцессе слияния модель-источник остается неизменной, и к модели-цели подключается фактически ее копия. Не нужно путать слияние моделей с синхронизацией. Если в дальнейшем модель-источник будет редактироваться, эти изменения автоматически не попадут в соответствующую ветвь модели-цели.
Разделение моделей производится аналогично. Для отщепления ветви от модели следует щелкнуть правой кнопкой мыши по декомпозированной работе (работа не должна иметь диагональной черты в левом верхнем углу) и выбрать во всплывающем меню пункт Split Model. В появившемся диалоге Split Options следует указать имя создаваемой модели. После подтверждения расщепления в старой модели работа станет недекомпозированной (признак – диагональная черта в левом верхнем углу), будет создана стрелка вызова, ее имя будет совпадать с именем новой модели, и, наконец, будет создана новая модель, причем имя контекстной работы будет совпадать с именем работы, от которой была «оторвана» декомпозиция.
Диаграммы потоков данных (Data Flow Diagramming) являются основным средством моделирования функциональных требований к проектируемой системе. Требования представляются в виде иерархии процессов, связанных потоками данных. Диаграммы потоков данных показывают, как каждый процесс преобразует свои входные данные в выходные, и выявляют отношения между этими процессами. DFDдиаграммы успешно используются как дополнение к модели IDEF0 для описания документооборота и обработки информации. Подобно IDEF0, DFD представляет моделируемую систему как сеть связанных работ. Основные компоненты DFD (как было сказано выше) – процессы или работы, внешние сущности, потоки данных, накопители данных (хранилища).
ВBPwin для построения диаграмм потоков данных используется нотация Гейна-Сарсона.
Для того чтобы дополнить модель IDEF0 диаграммой DFD, нужно
впроцессе декомпозиции в диалоге Activity Box Count щелкнуть по ра- дио-кнопке DFD. В палитре инструментов на новой диаграмме DFD появляются новые кнопки:
−External Reference – добавить в диаграмму внешнюю ссылку;
−Data store – добавить в диаграмму хранилище данных;
91
− Diagram Dictionary Editor – ссылка на другую страницу. В отличие от IDEF0 этот инструмент позволяет направить стрелку на любую диаграмму (а не только на верхний уровень).
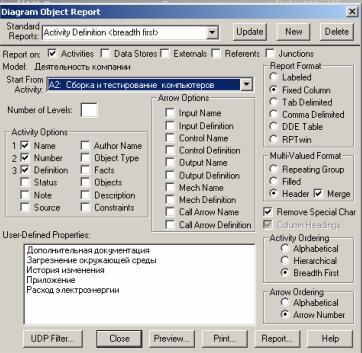
Рисунок 5.31 – Диалог настройки отчета Diagram Object Report
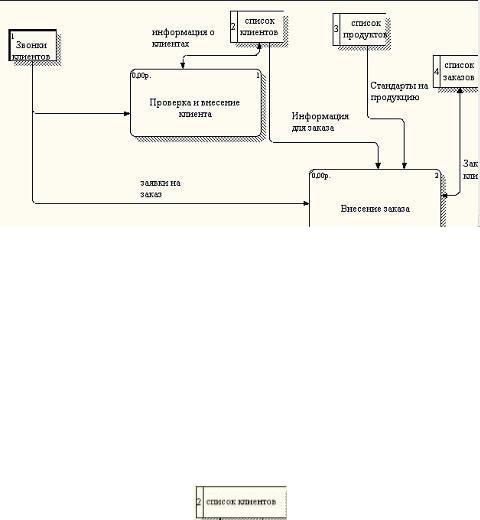
Вотличие от стрелок IDEF0, которые представляют собой жесткие взаимосвязи, стрелки DFD показывают, как объекты (включая данные) двигаются от одной работы к другой. Это представление потоков совместно с хранилищами данных и внешними сущностями делает модели DFD более похожими на физические характеристики системы — движение объектов, хранение объектов, поставка и распространение объектов
(рисунок 5.32).
ВDFD работы (процессы) представляют собой функции системы, преобразующие входы в выходы. Хотя работы изображаются прямоугольниками со скругленными углами, смысл их совпадает со смыслом работ IDEF0 и IDEF3. Так же, как процессы IDEF3, они имеют входы и выходы, но не поддерживают управления и механизмы, как IDEF0 (рисунок 5.32) (блоки «Проверка и внесение клиентов», «Внесение заказов»).
Внешние сущности изображают входы в систему и/или выходы из системы. Внешние сущности изображаются в виде прямоугольника с тенью и обычно располагаются по краям диаграммы (рисунок 5.32, блок «Звонки клиентов»). Одна внешняя сущность может быть использована многократно на одной или нескольких диаграммах. Обычно такой прием
92
используют, чтобы не рисовать слишком длинных и запутанных стрелок.
Рисунок 5.32 – Пример диаграммы DFD
Потоки работ изображаются стрелками и описывают движение объектов из одной части системы в другую. Поскольку в DFD каждая сторона работы не имеет четкого назначения, как в IDEF0, стрелки могут подходить и выходить из любой грани прямоугольника работы. В DFD также применяются двунаправленные стрелки для описания диалогов типа «команда-ответ» между работами, между работой и внешней сущностью и между внешними сущностями (рисунок 5.32).
В отличие от стрелок, описывающих объекты в движении, хранилища данных изображают объекты в покое (рисунок 5.33).
Рисунок 5.33 – Хранилище данных
Вматериальных системах хранилища данных изображаются там, где объекты ожидают обработки, например в очереди. В системах обработки информации хранилища данных являются механизмом, кото-
рый позволяет сохранить данные для последующих процессов.
ВDFD стрелки могут сливаться и разветвляться, что позволяет описать декомпозицию стрелок. Каждый новый сегмент сливающейся или разветвляющейся стрелки может иметь собственное имя.
Диаграммы DFD могут быть построены с использованием традиционного структурного анализа, подобно тому, как строятся диаграммы
IDEF0.
ВDFD номер каждой работы может включать префикс, номер родительской работы (А) и номер объекта. Номер объекта – это уникальный номер работы на диаграмме. Например, работа может иметь номер А.12.4. Уникальный номер имеют хранилища данных и внешние сущно-
93
сти независимо от их расположения на диаграмме. Каждое хранилище данных имеет префикс D и уникальный номер, например D5. Каждая внешняя сущность имеет префикс Е и уникальный номер, например Е5.
5.3Рекомендации по выбору средств построения модели данных на основе стандарта IDEF1Х
Построение модели данных является одним из ключевых этапов при разработке программного обеспечения. Ошибки, допущенные при построении модели данных, могут негативно сказаться на последующих этапах работы. В связи с этим рекомендуется при разработке моделей данных (концептуальной, логической, физической) пользоваться современными инструментальными средствами, обеспечивающими не только быстрое визуальное проектирование модели данных, но и своевременное выявление ошибок, допущенных в процессе проектирования. Этим требованиям соответствуют современные программные средства, относящиеся к категории CASE.
К средствам такого типа, в частности, относятся такие CASE-
средства, как AllFusion ERwin Data Modeler (или просто ERwin), Rational Rose, Sybase Power Designer и т.п.
5.4CASEсредство ERWin
ERWin имеет два уровня представления модели — логический и физический. Логический уровень – это абстрактный взгляд на дан-
ные, когда данные представляются так, как выглядят в реальном мире, и могут называться так, как они называются в реальном мире, например «Постоянный клиент», «Отдел» или «Фамилия сотрудника». Объекты модели, представляемые на логическом уровне, называются сущностями и атрибутами. Логическая модель данных может быть построена на основе другой логической модели, например на основе модели процессов. Логическая модель данных является универсальной и никак не связана с конкретной реализацией СУБД.
Физическая модель данных, напротив, зависит от конкретной СУБД, фактически являясь отображением системного каталога. В
физической модели содержится информация обо всех объектах базы данных. Поскольку стандартов на объекты базы данных не существует (например, нет стандарта на типы данных), физическая модель зависит от конкретной реализации СУБД. Следовательно, одной и той же логической модели могут соответствовать несколько разных физических моделей. Если в логической модели не имеет значения, какой конкретно тип данных имеет атрибут, то в физической модели важно описать всю информацию о конкретных физических объектах – таблицах, колонках, индексах, процедурах и т.д.
94
Документирование модели. Многие СУБД имеют ограничение на именование объектов (например, ограничение на длину имени таблицы или запрет использования специальных символов – пробела и т. п.). Зачастую разработчики информационных систем имеют дело с нелокализованными версиями СУБД. Это означает, что объекты баз данных могут называться короткими словами, только латинскими символами и без использования специальных символов (т.е. нельзя назвать таблицу, используя предложение – ее можно назвать только одним словом). Кроме того, проектировщики баз данных нередко злоупотребляют «техническими» наименованиями, в результате таблица и колонки получают наименования типа RTD_324 или CUST_A12 и т.д. Полученную в результате структуру могут понять только специалисты (а чаще всего – только авторы модели), ее невозможно обсуждать с экспертами предметной области. Разделение модели на логическую и физическую позволяет решить эту проблему. На физическом уровне объекты базы данных могут называться так, как того требуют ограничения СУБД. На логическом уровне можно этим объектам дать синонимы – имена более понятные неспециалистам, в том числе на кириллице и с использованием специальных символов. Например, таблице CUST_A12 может соответствовать сущность Постоянный клиент. Такое соответствие позволяет лучше документировать модель и дает возможность обсуждать структуру данных с экспертами предметной области.
Масштабирование. Создание модели данных, как правило, начинается с разработки логической модели. После описания логической модели проектировщик может выбрать необходимую СУБД, и ERWin автоматически создаст соответствующую физическую модель. На основе физической модели ERWin может сгенерировать системный каталог СУБД или соответствующий SQL-скрипт. Этот процесс называется прямым проектированием (Forward Engineering). Тем самым достигается масштабируемость – создав одну логическую модель данных, можно сгенерировать физические модели под любую поддерживаемую ERWin СУБД. С другой стороны, ERWin способен по содержимому системного каталога или SQL-скрипту воссоздать физическую и логическую модель данных (Reverse Engineering). На основе полученной логической модели данных можно сгенерировать физическую модель для другой СУБД и затем создать ее системный каталог. Следовательно, ERWin позволяет решить задачу по переносу структуры данных с одного сервера на другой. Например, можно перенести структуру данных с Oracle на Informix (или наоборот) или перенести структуру dbf-файлов в реляционную СУБД, тем самым облегчив переход от файл-серверной к клиентсерверной системе. Однако, формальный перенос структуры «плоских» таблиц на реляционную СУБД обычно неэффективен. Для того чтобы
95
извлечь выгоды от перехода на клиент-серверную технологию, структуру данных следует модифицировать.
Для переключения между логической и физической моделью данных служит список выбора в центральной части панели инструментов
ERWin (рисунок 5.34).
Если при переключении физической модели еще не существует, она будет создана автоматически.
Рисунок 5.34 – Переключение между логической и физической моделью
Интерфейс ERWin выполнен в стиле Windows-приложений, достаточно прост и интуитивно понятен. Рассмотрим кратко основные функции ERWin по отображению модели.
Каждому уровню отображения модели соответствует своя палитра инструментов. На логическом уровне палитра инструментов имеет следующие кнопки:
−кнопку указателя (режим мыши) – в этом режиме можно установить фокус на каком-либо объекте модели;
−кнопку внесения сущности;
−кнопку категории (категория, или категориальная связь, – специальный тип связи между сущностями, которая будет рассмотрена ниже);
−кнопку внесения текстового блока;
−кнопку перенесения атрибутов внутри сущностей и между ними;
−кнопки создания связей: идентифицирующую, «многие-ко- многим» и неидентифицирующую.
На физическом уровне палитра инструментов имеет:
−вместо кнопки категорий — кнопку внесения представлений
(view);
−вместо кнопки связи «многие-ко-многим» — кнопку связей представлений.
Для создания моделей данных в ERWin можно использовать две нотации: IDEF1X и IE (Information Engineering). В дальнейшем будет рассматриваться нотация IDEF1X.
ERwin имеет несколько уровней отображения диаграммы: уровень сущностей, уровень атрибутов, уровень определений, уровень первич-
96
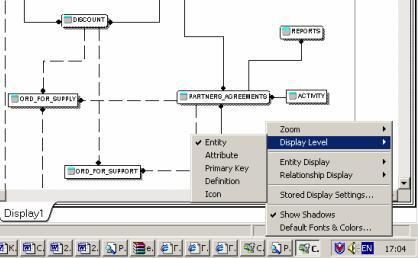
ных ключей и уровень иконок. Переключиться между первыми тремя уровнями можно с использованием кнопок панели инструментов. Переключиться на другие уровни отображения можно при помощи контекстного меню, которое появляется, если щелкнуть мышью по любому месту диаграммы, не занятому объектами модели. В контекстном меню следует выбрать пункт Display Level (рисунок 5.35) и затем – необходимый уровень отображения.
Рисунок 5.35 – Выбор уровней отображения диаграммы
Различают три уровня логической модели, отличающихся по глубине представления информации о данных:
−диаграмма сущность-связь (Entity Relationship Diagram, ERD);
−модель данных, основанная на ключах (Key Based model, KB);
−полная атрибутивная модель (Fully Attributed model, FA).
Диаграмма сущность-связь представляет собой модель данных
верхнего уровня. Она включает сущности и взаимосвязи, отражающие основные бизнес-правила предметной области. Такая диаграмма не слишком детализирована, в нее включаются основные сущности и связи между ними, которые удовлетворяют основным требованиям, предъявляемым к ИС. Диаграмма сущность-связь может включать связи "мно- гие-ко-многим" и не включать описание ключей. Как правило, ERD используется для презентаций и обсуждения структуры данных с экспертами предметной области.
Модель данных, основанная на ключах, – более подробное представление данных. Она включает описание всех сущностей и первичных ключей и предназначена для представления структуры данных и ключей, которые соответствуют предметной области.
Полная атрибутивная модель – наиболее детальное представление структуры данных: представляет данные в третьей нормальной форме и включает все сущности, атрибуты и связи.
97
Основные компоненты диаграммы ERWin – это сущности, атрибуты и связи. Каждая сущность является множеством подобных индивидуальных объектов, называемых экземплярами. Каждый экземпляр индивидуален и должен отличаться от всех остальных экземпляров. Атрибут выражает определенное свойство объекта. С точки зрения базы данных (физическая модель) сущности соответствует таблица, экземпляру сущности – строка в таблице, а атрибуту – колонка таблицы.
Построение модели данных предполагает определение сущностей и атрибутов, т. е. необходимо определить, какая информация будет храниться в конкретной сущности или атрибуте. Сущность можно опреде-
лить как объект, событие или концепцию, информация о которых должна сохраняться. Сущности должны иметь наименование с четким смысловым значением, именоваться существительным в единственном числе, не носить "технических" наименований и быть достаточно важными для того, чтобы их моделировать. Именование сущности в единственном числе облегчает в дальнейшем чтение модели. Фактически имя сущности дается по имени ее экземпляра. Примером может быть сущность «Заказчик» (но не «Заказчики»!) с атрибутами «Номер заказчика», «Фамилия заказчика» и «Адрес заказчика». На уровне физической модели ей может соответствовать таблица Customer с колонками
Customer_number, Customer_name и Customer_address. Каждая сущность должна быть полностью определена с помощью текстового описания. Для внесения дополнительных комментариев и определений к сущности служат свойства, определенные пользователем (UDP). Использование (UDP) аналогично их использованию в BPWin.
Как было указано выше, каждый атрибут хранит информацию об определенном свойстве сущности, а каждый экземпляр сущности должен быть уникальным. Атрибут или группа атрибутов, которые идентифицируют сущность, называется первичным ключом.
Очень важно дать атрибуту правильное имя. Атрибуты должны именоваться в единственном числе и иметь четкое смысловое значение. Соблюдение этого правила позволяет частично решить проблему нормализации данных уже на этапе определения атрибутов. Например, создание в сущности «Сотрудник» атрибута «Телефоны сотрудника» противоречит требованиям нормализации, поскольку атрибут должен быть атомарным, т. е. не содержать множественных значений. Согласно синтаксису IDEF1X имя атрибута должно быть уникально в рамках модели (а не только в рамках сущности!). По умолчанию при попытке внесения уже существующего имени атрибута ERWin переименовывает его.
Каждый атрибут должен быть определен, при этом следует избегать циклических определений, например, когда термин 1 определяется через термин 2, термин 2 – через термин 3, а термин 3 в свою очередь – через термин 1. Часто приходится создавать производные атрибуты, т.е.
98
атрибуты, значение которых можно вычислить из других атрибутов. Примером производного атрибута может служить «Возраст сотрудника», который может быть вычислен из атрибута «Дата рождения сотрудника». Такой атрибут может привести к конфликтам; действительно, если вовремя не обновить значение атрибута «Возраст сотрудника», он может противоречить значению атрибута «Дата рождения сотрудника». Производные атрибуты – ошибка нормализации, однако их вводят для повышения производительности системы, чтобы не проводить вычисления, которые на практике могут быть сложными.
Связь является логическим соотношением между сущностями. Каждая связь должна именоваться глаголом или глагольной фразой. Имя связи выражает некоторое ограничение или бизнес-правило и облегчает чтение диаграммы. По умолчанию имя связи на диаграмме не показывается. На логическом уровне можно установить идентифицирующую связь «один-ко-многим», связь «многие-ко-многим» и неидентифицирующую связь «один-ко-многим».
В IDEF1X различают зависимые и независимые сущности. Тип сущности определяется ее связью с другими сущностями. Идентифицирующая связь устанавливается между независимой (родительский конец связи) и зависимой (дочерний конец связи) сущностями. Когда рисуется идентифицирующая связь, ERWin автоматически преобразует дочернюю сущность в зависимую. Зависимая сущность изображается прямоугольником со скругленными углами. Экземпляр зависимой сущности определяется только через отношение к родительской сущности. При установлении идентифицирующей связи атрибуты первичного ключа родительской сущности автоматически переносятся в состав первичного ключа дочерней сущности. Эта операция дополнения атрибутов дочерней сущности при создании связи называется миграцией атрибутов. В дочерней сущности новые атрибуты помечаются как внешний ключ –
FK.
При установлении неидентифицирующей связи дочерняя сущность остается независимой, а атрибуты первичного ключа родительской сущности мигрируют в состав неключевых компонентов родительской сущности. Неидентифицирующая связь служит для связывания независимых сущностей.
Идентифицирующая связь показывается на диаграмме сплошной линией с жирной точкой на дочернем конце связи, неидентифицирующая – пунктирной (рисунок 5.35).
Мощность связей (Cardinality) – служит для обозначения отношения числа экземпляров родительской сущности к числу экземпляров дочерней.
Различают четыре типа сущности:
99