

2.2. Сортировка данных
Выберите команду Sort – Сортировка в меню Data – Данные (или нажмите кнопку на панели инструментов) для вызова диалога Sort Options - Параметры сортировки, который используется для сортировки переменных в таблице данных.
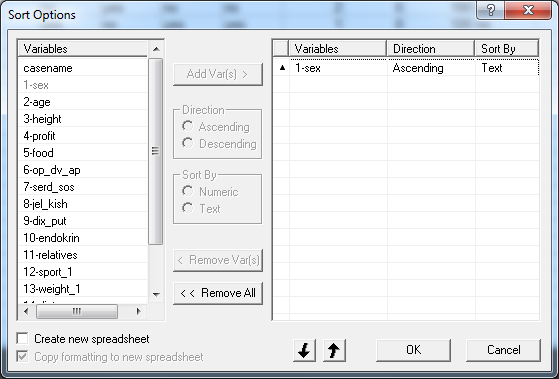
Выберите переменные, по которым необходимо осуществить сортировку и перенесите их с помощью кнопки Add Vars (Добавить переменные) в правую часть окна. Условия сортировки выбирается для каждой из выбранных переменных отдельно. Из выпадающих списков укажите порядок сортировки Ascending - По Возрастанию или Descending - По убыванию и тип значений Numeric – Число или Text-Текст.
Для данных приведенных в ЛБ_1 осуществим сортировку данных по возрастанию сначала по переменной пол, а затем по возрасту.
2.3. Преобразование данных
3.1 Преобразование шкалы переменных.
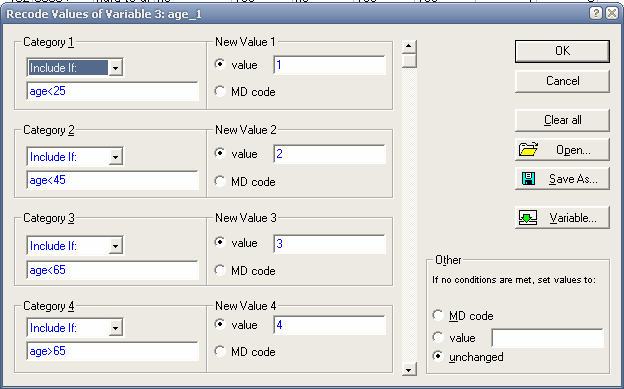
Команда Recode во вкладке Data позволяет перекодировать уже существующую. Например, нужно перекодировать переменную «age» в номинальную шкалу по следующему принципу:
если возраст человека больше 0 и меньше 25лет – (значение 1),
если возраст от 25 до 45лет – (значение 2),
если возраст от 45 до 60лет – (значение3)
больше 60 лет – (значение 4),
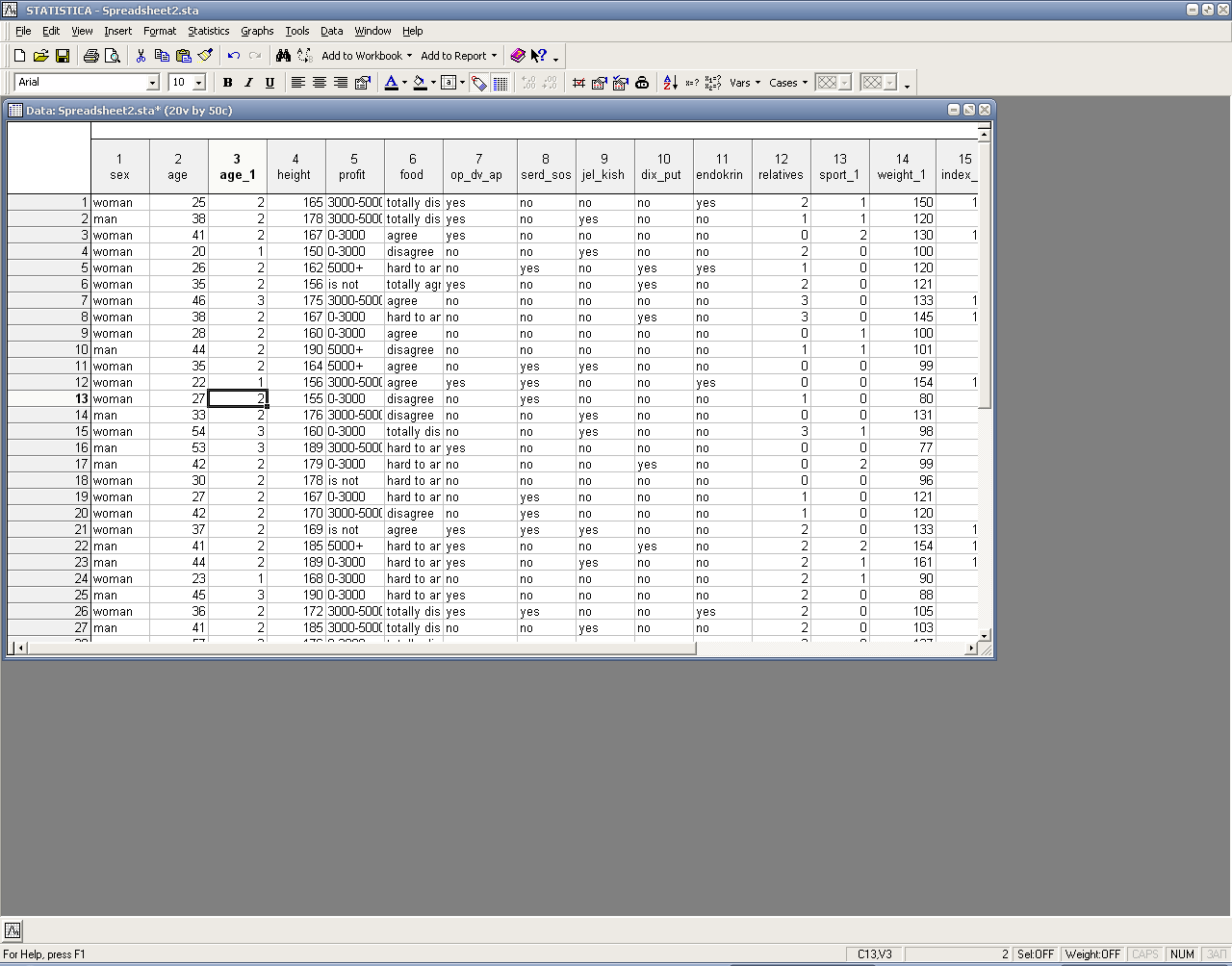
Для этого необходимо во вкладке Data выбрать функцию Recode. Предварительно необходимо создать новую переменную «age_1» и скопировать в неё данные с переменной «age» и установить на ней курсор. Откроется окно Recode Values of Variable… В этом окне необходимо задать перекодировку согласно рисунку
В результате чего получим
Ранжирование. Команда Rank во вкладке Data позволяет рассчитать ранговые места объектов по заданной переменной.
Ранжирование может быть произведено как для одной переменной (например, для «weight_2», как показано ниже), так и для нескольких переменных одновременно.
Предварительно создадим новую переменную «Rweight_2» и скопируем значения из переменной «weight_2» в переменную «Rweight_2», для которой выполним команду Rank
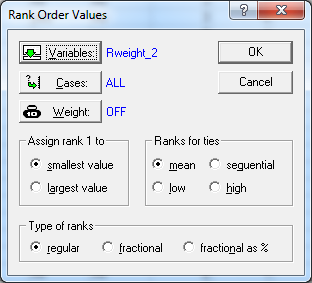
В результате получим:
Стандартизация (нормировка данных). В STATISTICA существует функция Standardize во вкладке Data.
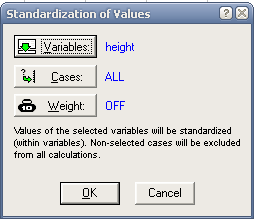
В открывшемся окне Standardization oh Values необходимо выбрать переменную (одну или несколько), которую необходимо стандартизировать, при необходимости указать вес.
2.3.2. Вычисление новых переменных
Для того, что бы выполнить вычисление новой переменной в системе STATISTICA предварительно необходимо её создать.
Рассчитаем индекс массы тела
до программы похудения участников
опроса по формуле
![]() .
.
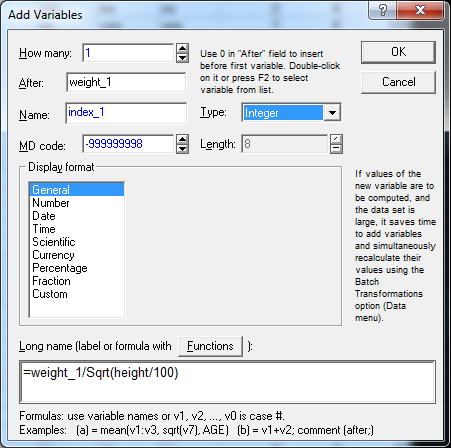
Предварительно добавим новую переменную «index_1» и поместим её после переменной «weight_1». В поле Long name начиная с символа «=» введите формулу для расчета индекса массы тела
Рассчитаем новую переменную «index_2» - массы тела респондентов после программы похудения тех, кто соблюдал диету. Для этого необходимо выполнить Functions – Operators - iif
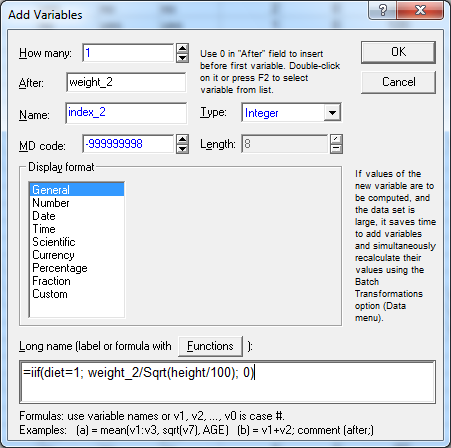
В результате получим:
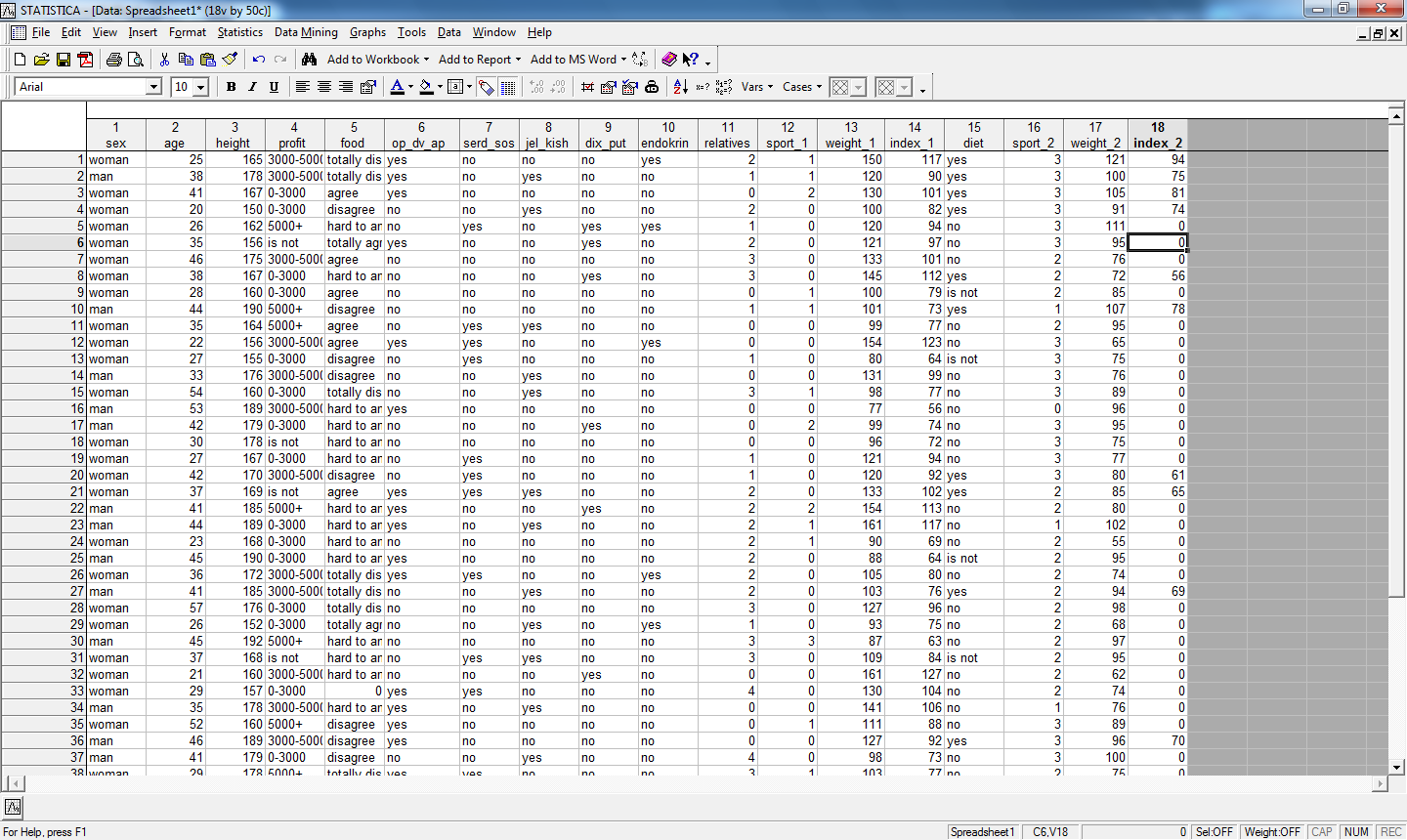
2.4. Статистическая корректировка данных.
2.4.1. Обработка пропущенных значений.
Для каждой переменной набора данных можно ввести свое значениекода пропущенных данных (MD Code). Это значение будет свидетельствовать об отсутствии данных для конкретного наблюдения или переменной (при этом в таблице исходных данных отображается пустая ячейка). Чтобы изменить этот код для конкретной переменной, нужно дважды щелкнуть на ее имени в таблице исходных данных, чтобы открыть диалоговое окно спецификаций переменной. По умолчаниюкод пропущенных данныхв системеSTATISTICA, используемый при создании новых файлов, добавлении новых переменных или импорте данных, равен-9999.
Способ использования пропущенных данных можно подобрать индивидуально для каждой процедуры анализа. Там, где это возможно, пользователю предоставлен выбор способа обработки пропущенных данных: удаление их из вычисленийпострочноилипопарно, замена на средние значения, а также их преобразование или интерполяция.
Выберите команду Replace Missing Data - Заменить пропущенные данные в меню Data (Данные) – Data Filtering/Recoding (Фильтрация даныых/Перекодирование) для вызова диалога Missing Data Replacement - Замена пропущенных данных, который используется для замены пропущенных данных в выбранных переменных на средние значения этих переменных.
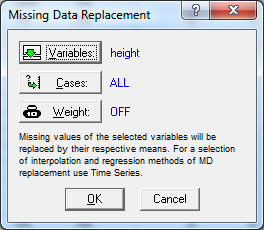
Нажмите кнопку Variables – Переменные для вызова диалога Select Variables - Выбор переменных, который используется для выбора переменных, в которых пропущенные данные заменяются на средние.
Вы можете использовать условия выбора наблюдений при вычислении средних для выбранных наблюдений. Для этого нажмите кнопку Cases – Наблюдения для вызова диалога Spreadsheet Case Selection Conditions - Условия выбора наблюдений в таблице данных. В этом диалоге вы можете задать новые условия выбора наблюдений или открыть существующие.
По умолчанию, каждое (выбранное) наблюдение равно среднему значению переменной. Для изменения, нажмите кнопку Weight – Вес для вызова диалога Spreadsheet Case Weights – Веса наблюдений таблицы данных, в котором вы выбираете взвешенную переменную. При выборе одной из переменных с весами, влияние каждого наблюдения изменяется в зависимости от значений весов переменных для данного наблюдения.
Для того, чтобы определить резко выделяющиеся (аномальные значения), необходимо построить коробчатую диаграмму (Graphs – Legacy Dialogs - Boxplot) и графически определить выделяющиеся значения (и их наличие вообще). Если в ходе анализа были выявлены резко выделяющиеся значения и было принято решение их удалить, то удаление осуществляется в ручную.