

Знаходження точкових та інтервальних оцінок параметрів генеральної сукупності за вибіркою (неперервна ознака). Побудова статистичної кривої розподілу.
Мета: Навчитися обчислювати числові характеристики неперервної ознаки; будувати статистичні криві розподілу і порівнювати їх з відповідними теоретичними кривими, зокрема, з нормальною кривою; оволодіти методами побудови надійних інтервалів для оцінок параметрів нормального розподілу.
Числові характеристики вибірки (для неперервної ознаки) .
Нехай вибірка для неперервної ознаки представлена інтервальною частотною таблицею.
Формули
числових характеристик для дискретної
ознаки використовуються і для знаходження
числових характеристик неперервної
ознаки, якщо замість інтервальної
частотної таблиці буде побудована
частотна таблиця. Для цього потрібно
замінити інтервали їх представниками,
рівними середині іншого інтервалу:
![]() .
Одержується послідовність рівновіддалених
варіант, частоти яких дорівнюють
відповідним частотам інтервалів. Ця
інформація записується у вигляді
частотної таблиці:
.
Одержується послідовність рівновіддалених
варіант, частоти яких дорівнюють
відповідним частотам інтервалів. Ця
інформація записується у вигляді
частотної таблиці:
|
|
|
... |
|
|
|
|
... |
|
Таку частотну таблицю використовують для побудови полігону частот: першими координатами точок ламаної лінії є середини інтервалів, а другими - відносні (абсолютні) частоти, що відповідають даним інтервалам. Таку лінію ще називають частотною ламаною або статистичною (експериментальною) кривою розподілу, так як вона показує розподіл вивчаємої ознаки по окремих інтервалах:


 y
y

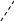
 wk-1
wk-1





 w3
w3

 w2
w2
w1


 wk
wk


x1
x2
![]() x3
x3
![]() x4
xk-1
x4
xk-1![]() xk
xk+1
xi
xk
xk+1
xi
При збільшенні числа спостережень (вимірювань) і зменшенні інтервального проміжку крива розподілу намагається стати плавною кривою. Криві розподілу можуть мати різні форми – криві з вершинами, зсунутими вправо або вліво; криві з піднятими або сплющеними вершинами, багато вершинні криві. Симетричні криві розподілу називають кривими нормального розподілу.
Статистичне оцінювання параметрів розподілу (оцінка параметрів генеральної сукупності за вибіркою)
а) Точкове оцінювання параметрів розподілу.
Нехай
потрібно підібрати деякий розподіл для
досліджуваної випадкової величини
за вибіркою
![]() .
Виходячи з аналізу вибірки (наприклад,
по виду гістограми чи полігону відносних
частот), можна вибрати певний розподіл
(нормальний, рівномірний, біноміальний
тощо).
.
Виходячи з аналізу вибірки (наприклад,
по виду гістограми чи полігону відносних
частот), можна вибрати певний розподіл
(нормальний, рівномірний, біноміальний
тощо).
Після того, як вид розподілу випадкової величини вибрано (він, зрозуміло, містить невідомі параметри), переходять до оцінки параметрів гіпотетичного (теоретичного) розподілу за даними вибірки. Так, наприклад, для нормального розподілу це параметри а і б. Розв’язання питання “про найкращу” оцінку невідомого параметру розподілу і складає теорію статистичного оцінювання.
Кожна
числова характеристика вибірки
– це реалізація
випадкової величини, яка від вибірки
до вибірки може приймати різні значення,
а значить сама є випадковою величиною.
Таку випадкову величину називають
статистикою (статистичною оцінкою) і
позначають
![]() .
Отже,
-
статистична оцінка параметра
.
Отже,
-
статистична оцінка параметра
![]() теоретичного розподілу.
теоретичного розподілу.
Оцінки бувають точкові і інтервальні.
Оцінка називається точковою, якщо вона визначається одним числом.
В
ролі точкових оцінок використовують
числові характеристики вибірки.
Наприклад,
![]() -
оцінка математичного сподівання
-
оцінка математичного сподівання
![]() генеральної сукупності. В принципі для
невідомого параметра
може існувати декілька числових
характеристик вибірки, які цілком
підходять для того, щоб бути оцінкою.
Наприклад,
,
генеральної сукупності. В принципі для
невідомого параметра
може існувати декілька числових
характеристик вибірки, які цілком
підходять для того, щоб бути оцінкою.
Наприклад,
,
![]() ,
,
![]() можуть бути оцінками для
,
а
можуть бути оцінками для
,
а
![]() і
і
![]() -
оцінками для дисперсії
-
оцінками для дисперсії
![]() .
.
Щоб вирішити, яка з статистик є найкращою, потрібно визначити деякі бажані властивості таких оцінок.
Оцінка
називається
незміщеною (незсуненою)
оцінкою параметра
,
якщо при довільному обсязі вибірки
математичне сподівання оцінки
дорівнює оцінюваному параметру
,
тобто
![]() ,
де
,
де
![]() .
.
Незсуненість оцінки означає, що при використанні цієї оцінки в одних випадках завищується шуканий параметр статистичної сукупності, в інших – занижується. Але в середньому, як кажуть, ми будемо “попадати в точку”. Отже, вимога незсуненості оцінки гарантує від одержання систематичних помилок (помилок одного знаку).
Якщо існує більше однієї незсуненої оцінки, то вибирають більш ефективну оцінку.
Оцінка
називається ефективною
оцінкою
параметра
, якщо при заданому обсязі вибірки вона
має найменшу дисперсію, тобто
![]() .
.
При
використанні тієї чи іншої оцінки
бажано, щоб точність оцінки
![]() збільшувалась із збільшенням об’єму
вибірки. Гранична точність буде досягнута
тоді, коли значення оцінки співпаде із
значенням параметра при необмеженому
збільшенні об’єму вибірки. Такі оцінки
називаються спроможними.
збільшувалась із збільшенням об’єму
вибірки. Гранична точність буде досягнута
тоді, коли значення оцінки співпаде із
значенням параметра при необмеженому
збільшенні об’єму вибірки. Такі оцінки
називаються спроможними.
Оцінка
називається спроможною
(консистентною)
оцінкою параметра
,
якщо при
![]() вона збігається за ймовірністю до
оцінюваного параметра
,
тобто
вона збігається за ймовірністю до
оцінюваного параметра
,
тобто
Зауваження.
При виборі оцінок слід приймати до уваги
наведені властивості і враховувати
відносну простоту обчислень. Іноді
вибирається неефективна оцінка тільки
тому, що її обчислення набагато простіше,
ніж обчислення ефективної оцінки.
Наприклад, для контролю якості продукції
мірою розсіювання статистичної сукупності
часто служить варіаційний розмах R,
який
використовується замість більш складної
і ефективної оцінки- статистичного
стандартного відхилення
![]() .
Можна показати, що оцінка
є
незміщеною, не є ефективною, але є
спроможною для дисперсії
.
Щоб статистична дисперсія, як оцінка,
стала незміщеною, вводять поняття
виправленої
статистичної дисперсії
,
яка обчислюється за формулою:
.
Можна показати, що оцінка
є
незміщеною, не є ефективною, але є
спроможною для дисперсії
.
Щоб статистична дисперсія, як оцінка,
стала незміщеною, вводять поняття
виправленої
статистичної дисперсії
,
яка обчислюється за формулою:![]() ,
де
,
де
![]() -
поправка Бесселя.
-
поправка Бесселя.
Зауваження.
Поправка
Бесселя при малих значеннях
значно відрізняється від 1. Тому при
![]() користуються виправленою статистичною
дисперсією. При
користуються виправленою статистичною
дисперсією. При
![]() практично немає різниці між використанням
і
практично немає різниці між використанням
і
![]() .
.
б) Інтервальне оцінювання параметрів розподілу.
Оцінка називається інтервальною, якщо вона визначається двома числами – кінцями інтервалу.
Такою оцінкою слід користуватися при великому обсязі вибірки.
Точкові
оцінки, розглянуті вище, не завжди
співпадають з істинними значеннями
невідомих параметрів розподілу. Отже,
є деяка похибка при заміні невідомого
параметра
його оцінкою
, тобто
![]() .
.
Величина похибки, при цьому, невідома, хоча хотілось би знати, до яких помилок може привести заміна параметра його точковою оцінкою.
Точністю
оцінки
![]() називається
число
називається
число
![]() ,
для якого
,
для якого
![]() .
.
Зрозуміло,
чим менше
![]() ,
тим точнішою буде оцінка. Проте,
статистичні методи не дозволяють
категорично стверджувати, що оцінка
задовольняє нерівність; можна лише
говорити про ймовірність, з якою ця
нерівність здійснюється.
,
тим точнішою буде оцінка. Проте,
статистичні методи не дозволяють
категорично стверджувати, що оцінка
задовольняє нерівність; можна лише
говорити про ймовірність, з якою ця
нерівність здійснюється.
Надійністю
(надійним
рівнем) оцінки
параметра
називається ймовірність
![]() ,
з якою здійснюється нерівність
,
тобто
,
з якою здійснюється нерівність
,
тобто
![]()
ще називають довірча ймовірність.
Як правило, число задається наперед і береться рівним 0,95; 0,99; 0,999, тобто числом, близьким до 1.
Надійним
(довірчим) інтервалом
називається інтервал
![]() ,
який з ймовірністю
”Накриває” (містить в собі) невідомий
параметр
.
,
який з ймовірністю
”Накриває” (містить в собі) невідомий
параметр
.
Числа
![]() та
та
![]() називається надійними
(довірчими) межами для
параметра
.
називається надійними
(довірчими) межами для
параметра
.
Розглянемо на прикладі зміст, який має задана надійність ρ. Так надійність 0,95 означає, що якщо проведена достатньо велика кількість вибірок, то 95% з них визначають такі надійні інтервали, які покривають оцінюваний параметр θ і лише в 5% випадків він може вийти за межі довірчого інтервалу. Тому, якщо ρ вибирається близьким до 1, то можна бути практично впевненим, що в одиничній серії випробувань надійний інтервал “накриє” параметр θ.
Метод визначення надійних інтервалів був розроблений американським статистиком Ю.Непманом, виходячи з ідеї англійського статистика Р.Фішера.
Надійні інтервали для параметрів нормального розподілу
Нехай деяка ознака Х генеральної сукупності розподілено нормально, тобто Х~N(a,σ), де а – математичне сподівання, а σ – середнє квадратичне відхилення.
Межі надійного інтервалу для оцінки параметра а визначається в залежності від значення n (обсягу вибірки). Маємо:
1.)
![]() ,
при n>30.
,
при n>30.
Тут
tρ
знаходиться з умови Ф(tρ)=![]() ,
Ф(х)=
,
Ф(х)=![]()
 – функція Лапласа, для значень якої
складені спеціальні таблиці; ρ – задана
надійна ймовірність;
– функція Лапласа, для значень якої
складені спеціальні таблиці; ρ – задана
надійна ймовірність;
![]() – статистичне середнє квадратичне
відхилення.
– статистичне середнє квадратичне
відхилення.
2)
![]() при n≤30
.
при n≤30
.
Тут tρ – коефіцієнт Стьюдента, що знаходиться з таблиці значень функції tρ=t(ρ,n); ρ – задана надійна ймовірність; – виправлене статистичне середнє квадратичне відхилення.
Межі довірчого інтервалу для оцінки параметра σ визначаються так:
![]() ,
якщо
,
якщо
![]() ,
,
![]() ,
якщо
,
якщо
![]() .
.
Значенні
q
знаходиться за таблицею значень функції
![]() .
.
Таблиці значень функції tρ=t(ρ,n) і додаються
Таблиці значень
![]() Таблиці
значень
Таблиці
значень
![]()
n
|
0,95 |
0,99 |
0,999 |
5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 25 30 35 40 45 50 60 70 80 90 100 120 |
2.78 2.57 2.45 2.37 2.31 2.26 2.23 2.20 2.18 2.16 2.15 2.13 2.12 2.11 2.10 2.093 2.064 2.045 2.032 2.023 2.016 2.009 2.001 1.996 1.991 1.987 1.984 1.980 1.960
|
4.60 4.03 3.71 3.50 3.36 3.25 3.17 3.11 3.06 3.01 2.98 2.95 2.92 2.90 2.88 2.861 2.797 2.756 2.729 2.708 2.692 2.679 2.662 2.649 2.640 2.633 2.627 2.617 2.576
|
8.61 6.86 5.96 5.41 5.04 4.78 4.59 4.44 4.32 4.22 4.14 4.07 4.02. 3.97 3.92 3.883 3.745 3.659 3.600 3.558 3.527 3.502 3.464 3.439 3.418 3.403 3.392 3.374 3.291 |
 ρ
ρρ n
|
0,95 |
0,99 |
0,999 |
5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 25 30 35 40 45 50 60 70 80 90 100 150 200 250 |
1.37 1.09 0.92 0.80 0.71 0.67 0.59 0.55 0.52 0.18 0.46 0.44 0.42 0.40 0.39 0.37 0.32 0.28 0.26 0.24 0.22 0.21 0.188 0.174 0.161 0.151 0.143 0.115 0.099 0.089 |
2.67 2.01 1.62 1.38 1.20 1.08 0.98 0.90 0.83 0.78 0.73 0.70 0.66 0.53 0.60 0.58 0.49 0.43 0.38 0.35 0.32 0.30 0.269 0.245 0.226 0.211 0.198 0.160 0.136 0.120 |
5.64 3.88 2.98 2.42 2.06 1.80 1.60 1.45 1.33 1.23 1.15 1.07 1.01 0.96 0.92 0.88 0.73 0.63 0.56 0.50 0.46 0.43 0.38 0.34 0.31 0.29 0.27 0.221 0.185 0.162 |
Завдання 1. а) Обчислити числові характеристики неперервної ознаки х – зріст учня, використавши інтервальну частотну таблицю цієї ознаки, що одержана при виконанні завдання лабораторної роботи №1.
б)
побудувати статистичну криву розподілу
і співставити її з відповідною кривою
нормального розподілу (використати
асиметрію і ексцес). Знайти інтервал
(![]() )
і з’ясувати чи всі значення ознаки
належать цьому інтервалу.
)
і з’ясувати чи всі значення ознаки
належать цьому інтервалу.
Завдання 2. Побудувати надійні інтервали для оцінки параметрів нормального розподілу неперервної ознаки х – зріст учня.