

23. Понятие и составляющие информационной системы
https://ru.wikipedia.org/wiki/Информационная_система
Информационная система (ИС) — система, предназначенная для хранения, поиска и обработки информации, и соответствующие организационные ресурсы (человеческие, технические, финансовые и т. д.), которые обеспечивают и распространяют информацию.
Достаточно широкое понимание информационной системы подразумевает, что её неотъемлемыми компонентами являются данные, техническое и программное обеспечение, а также персонал и организационные мероприятия.[4] Широко[5] трактует понятие «информационной системы» федеральный закон Российской Федерации «Об информации, информационных технологиях и о защите информации», подразумевая под информационной системой совокупность содержащейся в базах данных информации и обеспечивающих её обработку информационных технологий и технических средств[6].
Среди российских ученых в области информатики наиболее широкое определение ИС дает М. Р. Когаловский, по мнению которого в понятие информационной системы помимо данных, программ, аппаратного обеспечения и людских ресурсов следует также включать коммуникационное оборудование, лингвистические средства и информационные ресурсы, которые в совокупности образуют систему, обеспечивающую «поддержку динамической информационной модели некоторой части реального мира для удовлетворения информационных потребностей пользователей»[7][8]:59.
Более узкое понимание информационной системы ограничивает её состав данными, программами и аппаратным обеспечением. Интеграция этих компонентов позволяет автоматизировать процессы управления информацией и целенаправленной деятельности конечных пользователей, направленной на получение, модификацию и хранение информации[9]. Так, российский стандарт ГОСТ РВ 51987 подразумевает под ИС «автоматизированную систему, результатом функционирования которой является представление выходной информации для последующего использования». ГОСТ Р 53622-2009 использует термин информационно-вычислительная система для обозначения совокупности данных (или баз данных), систем управления базами данных и прикладных программ, функционирующих на вычислительных средствах как единое целое для решения определенных задач
24. Характеристика этапов разработки БД.
http://mkechinov.ru/article.database.html
База данных — совокупность связанных данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования, независимая от прикладных программ.
Для понятия «база данных» существует несколько классификаций. По модели представления данных БД можно классифицировать следующим образом: картотеки, иерархические, сетевые, многомерные, объектно-ориентированные, дедуктивные и реляционные. Далее речь пойдет о реляционной модели. Эта модель баз данных не была хронологически первой, но первой получила математическое описание, и, будучи экономной по части базовых понятий (что сделало ее невероятно привлекательной для программистов и пользователей), в основном используется в web-приложениях.
Так что же такое «реляционная модель БД»? В реляционных базах данных вся информация заключена в таблицы. Столбцы в такой таблице имеют конкретный тип и размер; все содержимое ячеек столбца должно соответствовать их типу. Строки представляют собой набор неструктурированных данных и образуют математическое отношение. Таким образом, вся база данных – это множество таблиц-отношений, отсюда и название модели (от англ. relation – отношение).
Один из главных принципов организации данных – построение взаимосвязей между всеми элементами, что и отличает базу данных от простого набора таблиц. Т.е. информация в таблицах реляционной базы данных должна быть соответствующим образом организована. Еще один важнейший принцип — нормализация таблиц, которая сводится к устранению недостатков структуры базы данных, приводящих к различным аномалиям и нарушениям целостности данных. Недостатками структуры можно назвать, например, противоречивость данных, а аномалией – возникновение случайных ошибок в процессе эксплуатации БД. Проще говоря, нормализация – разбиение таблицы на две или более для исключения повторения (избыточности) информации.
Разработка базы данных – сложный длительный процесс, который можно разделить на 3 этапа:
концептуальное проектирование — сбор, анализ и редактирование требований к данным;
логическое проектирование — преобразование требований к данным в структуры данных;
физическое проектирование — определение особенностей хранения данных, методов доступа и т. д.
На уровне физической модели электронная БД представляет собой файл или их набор в формате TXT, CSV, Excel, DBF, XML либо в специализированном формате конкретной СУБД (системы управления базами данных).
25. Характеристика элементов ER-диаграмм. Типы связей, примеры
http://www.interface.ru/home.asp?artId=1635
Основные понятия ER-диаграмм
Определение 1: Сущность - это класс однотипных объектов, информация о которых должна быть учтена в модели. Каждая сущность должна иметь наименование, выраженное существительным в единственном числе. Примерами сущностей могут быть такие классы объектов как "Поставщик", "Сотрудник", "Накладная". Каждая сущность в модели изображается в виде прямоугольника с наименованием:

Рис. 1
Определение 2: Экземпляр сущности - это конкретный представитель данной сущности. Например, представителем сущности "Сотрудник" может быть "Сотрудник Иванов". Экземпляры сущностей должны быть различимы , т.е. сущности должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности.
Определение 3: Атрибут сущности - это именованная характеристика, являющаяся некоторым свойством сущности. Наименование атрибута должно быть выражено существительным в единственном числе (возможно, с характеризующими прилагательными). Примерами атрибутов сущности "Сотрудник" могут быть такие атрибуты как "Табельный номер", "Фамилия", "Имя", "Отчество", "Должность", "Зарплата" и т.п. Атрибуты изображаются в пределах прямоугольника, определяющего сущность:

Рис. 2
Определение 4: Ключ сущности - это неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности. Неизбыточность заключается в том, что удаление любого атрибута из ключа нарушается его уникальность. Сущность может иметь несколько различных ключей. Ключевые атрибуты изображаются на диаграмме подчеркиванием:

Рис. 3
Определение 5: Связь - это некоторая ассоциация между двумя сущностями. Одна сущность может быть связана с другой сущностью или сама с собою. Связи позволяют по одной сущности находить другие сущности, связанные с нею. Например, связи между сущностями могут выражаться следующими фразами - "СОТРУДНИК может иметь несколько ДЕТЕЙ", "каждый СОТРУДНИК обязан числиться ровно в одном ОТДЕЛЕ". Графически связь изображается линией, соединяющей две сущности:

Рис. 4
Каждая связь имеет два конца и одно или два наименования. Наименование обычно выражается в неопределенной глагольной форме: "иметь", "принадлежать" и т.п. Каждое из наименований относится к своему концу связи. Иногда наименования не пишутся ввиду их очевидности.
Каждая связь может иметь один из следующих типов связи :

Рис. 5
Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две.
Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется родительской, правая (со стороны "много") - дочерней. Характерный пример такой связи приведен на Рис. 4.
Связь типа много-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности.
Каждая связь может иметь одну из двух модальностей связи:
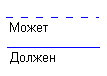
Рис. 6
Модальность "может" означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром. Модальность "должен" означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности. Связь может иметь разную модальность с разных концов (как на Рис. 4). Описанный графический синтаксис позволяет однозначно читать диаграммы, пользуясь следующей схемой построения фраз:
<Каждый экземпляр СУЩНОСТИ 1> <МОДАЛЬНОСТЬ СВЯЗИ> <НАИМЕНОВАНИЕ СВЯЗИ> <ТИП СВЯЗИ> <экземпляр СУЩНОСТИ 2>
Каждая связь может быть прочитана как слева направо, так и справа налево. Связь на Рис. 4 читается так:
Слева направо: "каждый сотрудник может иметь несколько детей". Справа налево: "Каждый ребенок обязан принадлежать ровно одному сотруднику".
Пример разработки простой ER-модели
При разработке ER-моделей мы должны получить следующую информацию о предметной области:
Список сущностей предметной области.
Список атрибутов сущностей.
Описание взаимосвязей между сущностями.
ER-диаграммы удобны тем, что процесс выделения сущностей, атрибутов и связей является итерационным. Разработав первый приближенный вариант диаграмм, мы уточняем их, опрашивая экспертов предметной области. При этом документацией, в которой фиксируются результаты бесед, являются сами ER-диаграммы.
Предположим, что перед нами стоит задача разработать информационную систему по заказу некоторой оптовой торговой фирмы. В первую очередь мы должны изучить предметную область и процессы, происходящие в ней. Для этого мы опрашиваем сотрудников фирмы, читаем документацию, изучаем формы заказов, накладных и т.п.
Например, в ходе беседы с менеджером по продажам, выяснилось, что он (менеджер) считает, что проектируемая система должна выполнять следующие действия:
Хранить информацию о покупателях.
Печатать накладные на отпущенные товары.
Следить за наличием товаров на складе.
Выделим все существительные в этих предложениях - это будут потенциальные кандидаты на сущности и атрибуты, и проанализируем их (непонятные термины будем выделять знаком вопроса):
Покупатель - явный кандидат на сущность.
Накладная - явный кандидат на сущность.
Товар - явный кандидат на сущность
(?)Склад - а вообще, сколько складов имеет фирма? Если несколько, то это будет кандидатом на новую сущность.
(?)Наличие товара - это, скорее всего, атрибут, но атрибут какой сущности?
Сразу возникает очевидная связь между сущностями - "покупатели могут покупать много товаров" и "товары могут продаваться многим покупателям". Первый вариант диаграммы выглядит так:
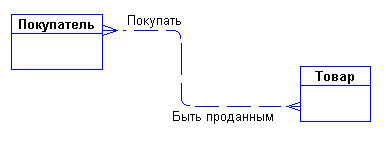
Рис. 7
Задав дополнительные вопросы менеджеру, мы выяснили, что фирма имеет несколько складов. Причем, каждый товар может храниться на нескольких складах и быть проданным с любого склада.
Куда поместить сущности "Накладная" и "Склад" и с чем их связать? Спросим себя, как связаны эти сущности между собой и с сущностями "Покупатель" и "Товар"? Покупатели покупают товары, получая при этом накладные, в которые внесены данные о количестве и цене купленного товара. Каждый покупатель может получить несколько накладных. Каждая накладная обязана выписываться на одного покупателя. Каждая накладная обязана содержать несколько товаров (не бывает пустых накладных). Каждый товар, в свою очередь, может быть продан нескольким покупателям через несколько накладных. Кроме того, каждая накладная должна быть выписана с определенного склада, и с любого склада может быть выписано много накладных. Таким образом, после уточнения, диаграмма будет выглядеть следующим образом:
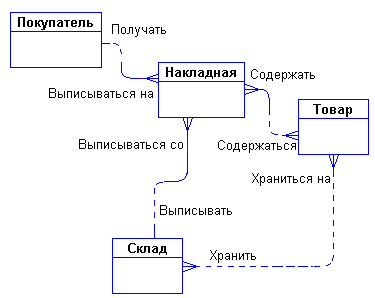
Рис. 8
Пора подумать об атрибутах сущностей. Беседуя с сотрудниками фирмы, мы выяснили следующее:
Каждый покупатель является юридическим лицом и имеет наименование, адрес, банковские реквизиты.
Каждый товар имеет наименование, цену, а также характеризуется единицами измерения.
Каждая накладная имеет уникальный номер, дату выписки, список товаров с количествами и ценами, а также общую сумму накладной. Накладная выписывается с определенного склада и на определенного покупателя.
Каждый склад имеет свое наименование.
Снова выпишем все существительные, которые будут потенциальными атрибутами, и проанализируем их:
Юридическое лицо - термин риторический, мы не работаем с физическими лицами. Не обращаем внимания.
Наименование покупателя - явная характеристика покупателя.
Адрес - явная характеристика покупателя.
Банковские реквизиты - явная характеристика покупателя.
Наименование товара - явная характеристика товара.
(?)Цена товара - похоже, что это характеристика товара. Отличается ли эта характеристика от цены в накладной?
Единица измерения - явная характеристика товара.
Номер накладной - явная уникальная характеристика накладной.
Дата накладной - явная характеристика накладной.
(?)Список товаров в накладной - список не может быть атрибутом. Вероятно, нужно выделить этот список в отдельную сущность.
(?)Количество товара в накладной - это явная характеристика, но характеристика чего? Это характеристика не просто "товара", а "товара в накладной".
(?)Цена товара в накладной - опять же это должна быть не просто характеристика товара, а характеристика товара в накладной. Но цена товара уже встречалась выше - это одно и то же?
Сумма накладной - явная характеристика накладной. Эта характеристика не является независимой. Сумма накладной равна сумме стоимостей всех товаров, входящих в накладную.
Наименование склада - явная характеристика склада.
В ходе дополнительной беседы с менеджером удалось прояснить различные понятия цен. Оказалось, что каждый товар имеет некоторую текущую цену. Эта цена, по которой товар продается в данный момент. Естественно, что эта цена может меняться со временем. Цена одного и того же товара в разных накладных, выписанных в разное время, может быть различной. Таким образом, имеется две цены - цена товара в накладной и текущая цена товара.
С возникающим понятием "Список товаров в накладной" все довольно ясно. Сущности "Накладная" и "Товар" связаны друг с другом отношением типа много-ко-многим. Такая связь, как мы отмечали ранее, должна быть расщеплена на две связи типа один-ко-многим. Для этого требуется дополнительная сущность. Этой сущностью и будет сущность "Список товаров в накладной". Связь ее с сущностями "Накладная" и "Товар" характеризуется следующими фразами - "каждая накладная обязана иметь несколько записей из списка товаров в накладной", "каждая запись из списка товаров в накладной обязана включаться ровно в одну накладную", "каждый товар может включаться в несколько записей из списка товаров в накладной", " каждая запись из списка товаров в накладной обязана быть связана ровно с одним товаром". Атрибуты "Количество товара в накладной" и "Цена товара в накладной" являются атрибутами сущности " Список товаров в накладной".
Точно также поступим со связью, соединяющей сущности "Склад" и "Товар". Введем дополнительную сущность "Товар на складе". Атрибутом этой сущности будет "Количество товара на складе". Таким образом, товар будет числиться на любом складе и количество его на каждом складе будет свое.
Теперь можно внести все это в диаграмму:
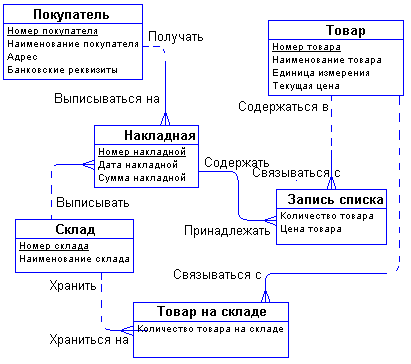
Рис. 9
Концептуальные и физические ER-модели
Разработанный выше пример ER-диаграммы является примером концептуальной диаграммы. Это означает, что диаграмма не учитывает особенности конкретной СУБД. По данной концептуальной диаграмме можно построить физическую диаграмму, которая уже будут учитываться такие особенности СУБД, как допустимые типы и наименования полей и таблиц, ограничения целостности и т.п. Физический вариант диаграммы, приведенной на Рис. 9 может выглядеть, например, следующим образом:

Рис. 10
На данной диаграмме каждая сущность представляет собой таблицу базы данных, каждый атрибут становится колонкой соответствующей таблицы. Обращаем внимание на то, что во многих таблицах, например, "CUST_DETAIL" и "PROD_IN_SKLAD", соответствующих сущностям "Запись списка накладной" и "Товар на складе", появились новые атрибуты, которых не было в концептуальной модели - это ключевые атрибуты родительских таблиц, мигрировавших в дочерние таблицы для того, чтобы обеспечить связь между таблицами посредством внешних ключей.
Легко заметить, что полученные таблицы сразу находятся в 3НФ.
26. Основные понятия реляционной модели данных
http://www.interface.ru/home.asp?artId=1531
реляционная модель состоит из трех частей:
Структурной части
Целостной части
Манипуляционной части
Структурная часть описывает, какие объекты рассматриваются реляционной моделью. Постулируется, что единственной структурой данных, используемой в реляционной модели, являются нормализованные n-арные отношения.
Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей.
Манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными - реляционную алгебру и реляционное исчисление.
В данной главе рассматривается структурная часть реляционной модели.
Типы данных
Любые данные, используемые в программировании, имеют свои типы данных.
Важно! Реляционная модель требует, чтобы типы используемых данных были простыми.
Для уточнения этого утверждения рассмотрим, какие вообще типы данных обычно рассматриваются в программировании. Как правило, типы данных делятся на три группы:
Простые типы данных
Структурированные типы данных
Ссылочные типы данных
Простые типы данных
Простые, или атомарные, типы данных не обладают внутренней структурой. Данные такого типа называют скалярами. К простым типам данных относятся следующие типы:
Логический
Строковый
Численный
Различные языки программирования могут расширять и уточнять этот список, добавляя такие типы как:
Целый
Вещественный
Дата
Время
Денежный
Перечислимый
Интервальный
И т. д.…
Конечно, понятие атомарности довольно относительно. Так, строковый тип данных можно рассматривать как одномерный массив символов, а целый тип данных - как набор битов. Важно лишь то, что при переходе на такой низкий уровень теряется семантика (смысл) данных. Если строку, выражающую, например, фамилию сотрудника, разложить в массив символов, то при этом теряется смысл такой строки как единого целого.
Структурированные типы данных
Структурированные типы данных предназначены для задания сложных структур данных. Структурированные типы данных конструируются из составляющих элементов, называемых компонентами, которые, в свою очередь, могут обладать структурой. В качестве структурированных типов данных можно привести следующие типы данных:
Массивы
Записи (Структуры)
С математической точки зрения массив представляет собой функцию с конечной областью определения. Например, рассмотрим конечное множество натуральных чисел
![]()
называемое множеством индексов. Отображение
![]()
из
множества ![]() во
множество вещественных чисел
во
множество вещественных чисел ![]() задает
одномерный вещественный массив. Значение
этой функции для некоторого значения
индекса
задает
одномерный вещественный массив. Значение
этой функции для некоторого значения
индекса ![]() называется
элементом массива, соответствующим
.
Аналогично можно задавать многомерные
массивы.
называется
элементом массива, соответствующим
.
Аналогично можно задавать многомерные
массивы.
Запись (или
структура) представляет собой кортеж
из некоторого декартового произведения
множеств. Действительно, запись
представляет собой именованный
упорядоченный набор элементов ![]() ,
каждый из которых принадлежит типу
,
каждый из которых принадлежит типу ![]() .
Таким образом, запись
.
Таким образом, запись ![]() есть
элемент множества
есть
элемент множества ![]() .
Объявляя новые типы записей на основе
уже имеющихся типов, пользователь может
конструировать сколь угодно сложные
типы данных.
.
Объявляя новые типы записей на основе
уже имеющихся типов, пользователь может
конструировать сколь угодно сложные
типы данных.
Общим для структурированных типов данных является то, что они имеют внутреннюю структуру, используемую на том же уровне абстракции, что и сами типы данных.
Поясним это следующим образом. При работе с массивами или записями можно манипулировать массивом или записью и как с единым целым (создавать, удалять, копировать целые массивы или записи), так и поэлементно. Для структурированных типов данных есть специальные функции - конструкторы типов, позволяющие создавать массивы или записи из элементов более простых типов.
Работая же с простыми типами данных, например с числовыми, мы манипулируем ими как неделимыми целыми объектами. Чтобы "увидеть", что числовой тип данных на самом деле сложен (является набором битов), нужно перейти на более низкий уровень абстракции. На уровне программного кода это будет выглядеть как ассемблерные вставки в код на языке высокого уровня или использование специальных побитных операций.
Ссылочные типы данных
Ссылочный тип данных ( указатели ) предназначен для обеспечения возможности указания на другие данные. Указатели характерны для языков процедурного типа, в которых есть понятие области памяти для хранения данных. Ссылочный тип данных предназначен для обработки сложных изменяющихся структур, например деревьев, графов, рекурсивных структур.
Типы данных, используемые в реляционной модели
Собственно, для реляционной модели данных тип используемых данных не важен. Требование, чтобы тип данных был простым , нужно понимать так, что в реляционных операциях не должна учитываться внутренняя структура данных . Конечно, должны быть описаны действия, которые можно производить с данными как с единым целым, например, данные числового типа можно складывать, для строк возможна операция конкатенации и т.д.
С этой точки
зрения, если рассматривать массив,
например, как единое целое и не использовать
поэлементных операций, то массив можно
считать простым типом данных. Более
того, можно создать свой, сколь угодно
сложных тип данных, описать возможные
действия с этим типом данных, и, если в
операциях не требуется знание внутренней
структуры данных, то такой тип данных
также будет простым с точки зрения
реляционной теории. Например, можно
создать новый тип - комплексные числа
как запись вида ![]() ,
где
,
где ![]() .
Можно описать функции сложения, умножения,
вычитания и деления, и все действия с
компонентами
.
Можно описать функции сложения, умножения,
вычитания и деления, и все действия с
компонентами ![]() и
и ![]() выполнять
только внутри этих операций. Тогда, если
в действиях с этим типом использовать
только описанные операции, то внутренняя
структура не играет роли, и тип данных
извне выглядит как атомарный.
выполнять
только внутри этих операций. Тогда, если
в действиях с этим типом использовать
только описанные операции, то внутренняя
структура не играет роли, и тип данных
извне выглядит как атомарный.
Именно так в некоторых пост-реляционных СУБД реализована работа со сколь угодно сложными типами данных, создаваемых пользователями.
Отношения, атрибуты, кортежи отношения
Определения и примеры
Фундаментальным понятием реляционной модели данных является понятие отношения. В определении понятия отношения будем следовать книге К. Дейта.
Определение 1. Атрибут отношения есть пара вида <Имя_атрибута : Имя_домена>. Имена атрибутов должны быть уникальны в пределах отношения. Часто имена атрибутов отношения совпадают с именами соответствующих доменов.
Определение
2. Отношение ![]() ,
определенное на множестве доменов
,
определенное на множестве доменов ![]() (не
обязательно различных), содержит две
части: заголовок и тело.
Заголовок
отношения содержит фиксированное
количество атрибутов отношения:
(не
обязательно различных), содержит две
части: заголовок и тело.
Заголовок
отношения содержит фиксированное
количество атрибутов отношения:
![]()
Тело отношения содержит множество кортежей отношения. Каждый кортеж отношения представляет собой множество пар вида <Имя_атрибута: Значение_атрибута>:
![]()
таких что
значение ![]() атрибута
атрибута ![]() принадлежит
домену
принадлежит
домену ![]()
Отношение обычно записывается в виде:
![]() ,
,
или короче
![]() ,
,
или просто
.
Число атрибутов в отношении называют степенью (или -арностью ) отношения. Мощность множества кортежей отношения называют мощностью отношения.
Возвращаясь к математическому понятию отношения, введенному в предыдущей главе, можно сделать следующие выводы:
Вывод 1: Заголовок отношения описывает декартово произведение доменов, на котором задано отношение. Заголовок статичен, он не меняется во время работы с базой данных. Если в отношении изменены, добавлены или удалены атрибуты, то в результате получим уже другое отношение (пусть даже с прежним именем).
Вывод 2: Тело отношения представляет собой набор кортежей, т.е. подмножество декартового произведения доменов. Таким образом, тело отношения собственно и является отношением в математическом смысле слова. Тело отношения может изменяться во время работы с базой данных - кортежи могут изменяться, добавляться и удаляться.
Пример 1. Рассмотрим отношение "Сотрудники" заданное на доменах "Номер_сотрудника", "Фамилия", "Зарплата", "Номер_отдела". Т.к. все домены различны, то имена атрибутов отношения удобно назвать так же, как и соответствующие домены. Заголовок отношения имеет вид:
Сотрудники (Номер_сотрудника, Фамилия, Зарплата, Номер_отдела)
Пусть в данный момент отношение содержит три кортежа:
(1, Иванов, 1000, 1) (2, Петров, 2000, 2) (3, Сидоров, 3000, 1)
такое отношение естественным образом представляется в виде таблицы:
Номер_сотрудника |
Фамилия |
Зарплата |
Номер_отдела |
1 |
Иванов |
1000 |
1 |
2 |
Петров |
2000 |
2 |
3 |
Сидоров |
3000 |
1 |
Таблица 1 Отношение "Сотрудники"
Определение 3. Реляционной базой данных называется набор отношений.
Определение 4. Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных.
Хотя любое отношение можно изобразить в виде таблицы, нужно четко понимать, что отношения не являются таблицами . Это близкие, но не совпадающие понятия. Различия между отношениями и таблицами будут рассмотрены ниже.
Термины, которыми оперирует реляционная модель данных, имеют соответствующие "табличные" синонимы:
Реляционный термин |
Соответствующий "табличный" термин |
База данных |
Набор таблиц |
Схема базы данных |
Набор заголовков таблиц |
Отношение |
Таблица |
Заголовок отношения |
Заголовок таблицы |
Тело отношения |
Тело таблицы |
Атрибут отношения |
Наименование столбца таблицы |
Кортеж отношения |
Строка таблицы |
Степень (-арность) отношения |
Количество столбцов таблицы |
Мощность отношения |
Количество строк таблицы |
Домены и типы данных |
Типы данные в ячейках таблицы |
Свойства отношений
Свойства отношений непосредственно следуют из приведенного выше определения отношения. В этих свойствах в основном и состоят различия между отношениями и таблицами.
В отношении нет одинаковых кортежей . Действительно, тело отношения есть множество кортежей и, как всякое множество, не может содержать неразличимые элементы (см. понятие множества в гл.1.). Таблицы в отличие от отношений могут содержать одинаковые строки.
Кортежи не упорядочены (сверху вниз) . Действительно, несмотря на то, что мы изобразили отношение "Сотрудники" в виде таблицы, нельзя сказать, что сотрудник Иванов "предшествует" сотруднику Петрову. Причина та же - тело отношения есть множество, а множество не упорядочено. Это вторая причина, по которой нельзя отождествить отношения и таблицы - строки в таблицах упорядочены. Одно и то же отношение может быть изображено разными таблицами, в которых строки идут в различном порядке .
Атрибуты не упорядочены (слева направо) . Т.к. каждый атрибут имеет уникальное имя в пределах отношения, то порядок атрибутов не имеет значения. Это свойство несколько отличает отношение от математического определения отношения (см. гл.1 - компоненты кортежей там упорядочены ). Это также третья причина, по которой нельзя отождествить отношения и таблицы - столбцы в таблице упорядочены. Одно и то же отношение может быть изображено разными таблицами, в которых столбцы идут в различном порядке .
Все значения атрибутов атомарны . Это следует из того, что лежащие в их основе атрибуты имеют атомарные значения. Это четвертое отличие отношений от таблиц - в ячейки таблиц можно поместить что угодно - массивы, структуры, и даже другие таблицы.
Замечание. Из свойств отношения следует, что не каждая таблица может задавать отношение. Для того, чтобы некоторая таблица задавала отношение, необходимо, чтобы таблица имела простую структуру (содержала бы только строки и столбцы, причем, в каждой строке было бы одинаковое количество полей), в таблице не должно быть одинаковых строк, любой столбец таблицы должен содержать данные только одного типа, все используемые типы данных должны быть простыми.
Замечание. Каждое отношение можно считать классом эквивалентности таблиц, для которых выполняются следующие условия:
Таблицы имеют одинаковое количество столбцов.
Таблицы содержат столбцы с одинаковыми наименованиями.
Столбцы с одинаковыми наименованиями содержат данные из одних и тех же доменов.
Таблицы имеют одинаковые строки с учетом того, что порядок столбцов может различаться.
Все такие таблицы есть различные изображения одного и того же отношения.
27. Понятие целостности реляционных баз данных
https://ru.wikipedia.org/wiki/Целостность_базы_данных
Це́лостность ба́зы да́нных (database integrity) — соответствие имеющейся в базе данных информации её внутренней логике, структуре и всем явно заданным правилам. Каждое правило, налагающее некоторое ограничение на возможное состояние базы данных, называется ограничением целостности (integrity constraint). Примеры правил: вес детали должен быть положительным; количество знаков в телефонном номере не должно превышать 25; возраст родителей не может быть меньше возраста их биологического ребёнка и т. д.
Понятие согласованности, или целостности данных является ключевым понятием баз данных.
Кузнецов С. Д.[1]:30
Очевидно, что ограничения должны быть формально объявлены для СУБД, после чего СУБД должна предписывать их выполнение. Объявление ограничений сводится просто к использованию соответствующих средств языка базы данных, а соблюдение ограничений осуществляется с помощью контроля со стороны СУБД над операциями обновления, которые могут нарушить эти ограничения, и запрещения тех операций, которые их действительно нарушают. При первоначальном объявлении ограничения система должна проверить, удовлетворяет ли ему в настоящий момент база данных. Если это условие не соблюдается, ограничение должно быть отвергнуто; в противном случае оно принимается (то есть записывается в каталог системы) и начиная с этого момента соблюдается. В теории реляционных баз данных принято выделять четыре типа ограничений целостности[2]:353:
Ограничением базы данных называется ограничение на значения, которые разрешено принимать указанной базе данных.
Ограничением переменной отношения называется ограничение на значения, которые разрешено принимать указанной переменной отношения.
Ограничением атрибута называется ограничение на значения, которые разрешено принимать указанному атрибуту.
Ограничение типа представляет собой не что иное, как определение множества значений, из которых состоит данный тип.
Примером распространённого ограничения уровня переменной отношения является потенциальный ключ; примером распространённого ограничения уровня базы данных является внешний ключ.
28. Понятие функциональной зависимости атрибутов отношения.
29. Реляционная алгебра. Операции ограничения, проекции объединения и пересечения
30. Реляционная алгебра. Операции разности, произведения, соединения и деления
http://migku.wikidot.com/gos-db-16
Реляционная алгебра — формальная система манипулирования отношениями в реляционной модели данных.
31. Понятие нормализации БД. Свойства нормальных форм
32. Характеристика 1НФ. Пример приведения к 1НФ
33. Характеристика 2НФ. Пример приведения к 2НФ
34. Характеристика 3НФ. Пример приведения к 3НФ
http://www.libma.ru/kompyutery_i_internet/bazy_dannyh_konspekt_lekcii/p10.php
Понятие, которое мы будем рассматривать в данном разделе, связано с понятием функциональных зависимостей, т. е. смысл нормализации схем баз данных неразрывно связан с понятием ограничений, накладываемых системой функциональных зависимостей, и во многом следует из этого понятия.
Исходной точкой любого проектирования базы данных является представление предметной области в виде одного или нескольких отношений, и на каждом шаге проектирования производится некоторый набор схем отношений, обладающих «улучшенными» свойствами. Таким образом, процесс проектирования представляет собой процесс нормализации схем отношений, причем каждая следующая нормальная форма обладает свойствами, в некотором смысле лучшими, чем предыдущая.
Каждой нормальной форме соответствует определенный набор ограничений, и отношение находится в некоторой нормальной форме, если удовлетворяет свойственному ей набору ограничений. Примером может служить ограничение первой нормальной формы – значения всех атрибутов отношения атомарны.
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм:
1) первая нормальная форма (1 NF);
2) вторая нормальная форма (2 NF);
3) третья нормальная форма (3 NF);
4) нормальная форма Бойса – Кодда (BCNF);
5) четвертая нормальная форма (4 NF);
6) пятая нормальная форма, или нормальная форма проекции-соединения (5 NF или PJ/NF).
(В данный курс лекций включается подробное рассмотрение первых четырех нормальных форм базовых отношений, поэтому мы не будем подробно разбирать четвертую и пятую нормальные формы.)
Основные свойства нормальных форм состоят в следующем:
1) каждая следующая нормальная форма в некотором смысле лучше предыдущей нормальной формы;
2) при переходе к следующей нормальной форме свойства предыдущих нормальных форм сохраняются.
2. Первая нормальная форма (1nf)
На ранних стадиях проектирования баз данных и разработки схем их управления использовались простые и однозначные атрибуты как наиболее продуктивные и рациональные единицы кода. Тогда применяли наряду с простыми и составные атрибуты, а также наряду с однозначными и многозначные атрибуты. Поясним значения каждого из этих понятий.
Составные атрибуты, в отличие от простых, – это атрибуты, составленные из нескольких простых атрибутов.
Многозначные атрибуты, в отличие от однозначных, – это атрибуты, представляющие множество значений.
Приведем примеры простых, составных, однозначных и многозначных атрибутов.
Рассмотрим следующую таблицу, представляющую отношение:

Здесь атрибут «Телефон» – простой, однозначный, а атрибут «Адрес» – простой, но многозначный.
Теперь рассмотрим другую таблицу, с другими атрибутами:

В этом отношении, представленном таблицей, атрибут «Телефоны» – простой, но многозначный, а атрибут «Адреса» – и составной, и многозначный.
Вообще возможны различные комбинации простых или составных атрибутов. В разных случаях таблицы, представляющие отношения, могут выглядеть следующим общим образом:

При нормализации схем базовых отношений программистами может быть использована одна из четырех наиболее распространенных видов нормальных форм: первая нормальная форма (1NF), вторая нормальная форма (2NF), третья нормальная форма (3NF) или нормальная форма Бойса – Кодда (NFBC). Поясним: сокращение NF – это аббревиатура от англоязычного словосочетания Normal Form. Формально, кроме вышеназванных, существуют и другие виды нормальных форм, но вышеназванные – одни из самых востребованных.
В настоящее время разработчики баз данных стараются избегать составных и многозначных атрибутов, чтобы не усложнять написание кода, не перегружать его структуру и не запутывать пользователей. Из этих соображений логически и вытекает определение первой нормальной формы.
Определение. Любое базовое отношение находится в первой нормальной форме тогда и только тогда, когда схема этого отношения содержит только простые и только однозначные атрибуты, причем обязательно с одной и той же семантикой.
Для наглядного объяснения различий нормализованных и ненормализованных отношений рассмотрим пример.
Пусть, имеется ненормализованное отношение, со следующей схемой.
Итак, вариант 1 схемы отношения с заданным на ней простым первичным ключом:
Сотрудники (№ табельный, Фамилия Имя Отчество, Код должности, Телефоны, Дата приема или увольнения);
Primary key (№ табельный);
Перечислим, какие в этой схеме отношения имеются ошибки, т. е. назовем те признаки, которые и делают собственно эту схему ненормализованной:
1) атрибут «Фамилия Имя Отчество» является составным, т. е. составленным из разнородных элементов;
2) атрибут «Телефоны» является многозначным, т. е. его значением является множество значений;
3) атрибут «Дата приема или увольнения» не имеет однозначной семантики, т. е. в последнем случае не понятно, какая именно дата внесена.
Если, например, ввести дополнительный атрибут, чтобы поточнее определить смысл даты, то для этого атрибута значение будет семантически понятно, но тем не менее остается возможность хранения только какой-то одной из указанных дат для каждого сотрудника.
Что же необходимо сделать для приведения этого отношения к нормальной форме?
Во-первых, необходимо провести разбиение составных атрибутов на простые, для того, чтобы исключить эти самые составные атрибуты, а также атрибуты с составной семантикой.
А во-вторых, необходимо провести декомпозицию этого отношения, т. е. нужно разбить его на несколько новых самостоятельных отношений, с тем чтобы исключить многозначные атрибуты.
Таким образом, с учетом всего вышесказанного после приведения отношения «Сотрудники» к первой нормальной форме или 1NF путем его декомпозиции мы получим систему следующих отношений с заданными на них первичными и внешними ключами.
Итак, вариант 2 отношения:
Сотрудники (№ табельный, Фамилия, Имя, Отчество, Код должности, Дата приема, Дата увольнения);
Primary key (№ табельный);
Телефоны (№ табельный, Телефон);
Primary key (№ табельный, Телефон);
Foreign key (№ табельный) references Сотрудники (№ табельный);
Итак, что мы видим? Составного атрибута «Фамилия Имя Отчество» больше в нашем отношении нет, вместо него присутствуют три простых атрибута «Фамилия», «Имя» и «Отчество», поэтому эта причина «ненормальности» отношения исключилась.
Кроме того, вместо атрибута с неясной семантикой «Дата приема или увольнения» у нас появилось два атрибута «Дата приема» и «Дата увольнения», каждый из которых имеет однозначную семантику. Следовательно, вторая причина того, что наше отношение «Сотрудники» не находится в нормальной форме, также благополучно устранена.
И, наконец, последняя причина того, что отношение «Сотрудники» не было приведено к нормальной форме, – это наличие многозначного атрибута «Телефоны». Чтобы избавиться от этого атрибута, и необходимо было провести декомпозицию всего отношения. Из исходного отношения «Сотрудники» в результате этой декомпозиции был исключен атрибут «Телефоны» вообще, но зато образовалось второе отношение – «Телефоны», в котором присутствуют два атрибута: «№ табельный» сотрудника и «Телефон», т. е. все атрибуты – опять-таки простые, условие принадлежности к первой нормальной форме выполняется. Эти атрибуты «№ табельный» и «Телефон» образуют составной первичный ключ отношения «Телефоны», а атрибут «№ табельный», в свою очередь, является внешним ключом, ссылающимся на одноименный атрибут отношения «Сотрудники», т. е. в отношении «Телефоны» атрибут первичного ключа «№ табельный» является одновременно внешним ключом, ссылающимся на первичный ключ отношения «Сотрудники». Таким образом, обеспечивается связь между этими двумя отношениями. Посредством этой связи можно по номеру табельному любого сотрудника без особого труда и затрат времени вывести весь список его телефонов, не прибегая к использованию составных атрибутов.
Заметим, что в случае наличия в отношении системы ограничений функциональных зависимостей после всех вышеприведенных преобразований нормализация не была бы завершена. Однако в данном конкретном примере нет ограничений функциональных зависимостей, поэтому дальнейшая нормализация этого отношения не требуется.