

Требования к данным
Ценность информационных систем заключается в том, что они предоставляют возможность манипулировать данными. Используйте этот раздел шаблона для описания различных аспектов данных, которые будет потреблять система в качестве входной информации, как-то обрабатывать и возвращать в виде выходной информации. Можно описать много схем для точного документирования данных (которые также называют информацией).
Компьютерные системы работают с данными так, чтобы это приносило пользу клиентам. Хотя они и явно не показаны на трехуровневой модели требований, но требования к данным охватывают все три уровня.
Всюду, где есть функции, есть данные. Независимо от того, как представлены данные — пиксели в видеоигре, пакеты в вызове сотового телефона, квартальные показатели вашей компании, операции банковского счета или чтолибо другое, функциональность программы создается для создания, изменения, отображения, удаления, обработки и использования данных. Бизнесаналитик должен начинать собирать определения данных по мере того, как они появляются в процессе выявления требований.
Хорошей отправной точкой являются входной и выходной потоки на контекстной диаграмме системы. Эти потоки представляют главные элементы данных на высоком уровне абстракции, которые бизнес-аналитик должен преобразовать в подробности требований в процессе их выявления.
Существительные, которые пользователи упоминают в процессе выявления требований, часто указывают на важные сущности данных: заказ химиката, сотрудник, химикат, состояние, отчет об использовании химиката. Здесь описываются приемы анализа и представления данных, которые важны для пользователей вашего приложения, а также способы определения отчетов и панелей мониторинга, которые должно создавать ваше приложение.
1.1 Логическая модель данных
Модель данных это визуальное представление объектов и наборов данных, которые будет обрабатывать система, а также отношений между ними. Существует много видов нотации для моделирования данных, в том числе диаграммы отношений «сущность–связь» и диаграммы классов UML. Можно включить модель данных для бизнес-операций, выполняемых системой или логическое представление данных, с которыми будет работать система. Это не то же самое, что модель данных реализации, которая реализуется в виде дизайна базы данных.
Моделирование отношений данных
Так же, как описанная в главе 12 диаграмма потоков данных иллюстрирует процессы, происходящие в системе, так модель данных изображает связи данных в системе. Модель данных предоставляет высокоуровневое представление данных системы, а словарь данных дает подробную картину.
Широко используется такая модель данных, как диаграмма «сущность–связь» (entity-relationship diagrams, ERD).
Если диаграмма «сущность–связь» представляет логические группы информации предметной области и их взаимосвязи, нужно использовать диаграмму «сущность–связь» в качестве инструмента анализа требований. Анализ диаграммы «сущность–связь» помогает понять и связать компоненты данных компании или системы, даже без предположения, что продукт будет включать базу данных. Создавая эту диаграмму в ходе разработки системы, вы определяете логическую или физическую (реализацию) структуру базы данных системы. Такое представление реализации расширяет или дополняет понимание системы, которое образовалось в процессе анализа, и оптимизирует ее реализацию, скажем, в среде реляционной базы данных.
Сущностями (entities) называются физические элементы (включая людей) или агрегации элементов данных, важных для анализируемого бизнеса или для системы, которую вы планируете создать. Сущности именуются посредством существительных в единственном числе, они показаны в прямоугольниках на диаграмме «сущность–связь». На рис. 11-1 показана часть диаграммы «сущность–связь» для Chemical Tracking System с использованием нотации Питера Чена, одной из нескольких применяемых для диаграмм такого типа систем обозначений данных.
Другие объекты представляют действующие лица, взаимодействующие с системой (Сотрудник, разместивший заказ на химикат), физические элементы, являющиеся частью бизнес-операций (Контейнер с химикатом), и блоки данных, которые не показаны на уровне 0 диаграммы потоков данных, но показаны на ее более низком уровне (История контейнера, Химикат). В процессе проектирования физической реляционной базы данных сущности обычно становятся таблицами. Каждая сущность описывается несколькими атрибутами; у разных экземпляров сущности значения атрибутов могут отличаться. Например, в атрибуты каждого химиката включены уникальный химический идентификатор, строгое название химиката и графическое представление его химической структуры. В словаре данных приводятся детальные определения этих атрибутов — это гарантирует, что объекты на диаграмме «сущность–связь» и соответствующие им хранилища данных на диаграмме потоков данных определены одинаково.
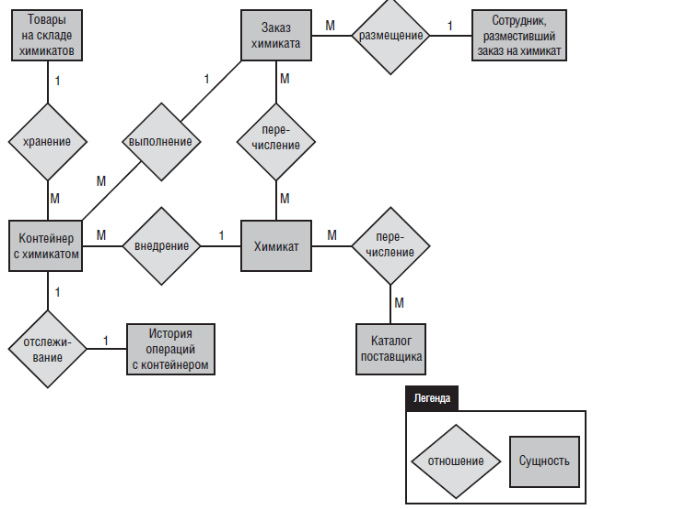
Рис. 13-1. Фрагмент диаграммы «сущность–связь» системы Chemical Tracking System
Ромбы на диаграмме «сущность–связь» обозначают связи (relationship), показывающие логические и числовые связи пар объектов. Названия связям даются в соответствии с характером соединений. Например, связи между элементами «Сотрудник, разместивший заказ на химикат», и «Запрос химиката» определяются как размещение (placing). Вы можете прочитать эту связь как «Сотрудник размещает Запрос на химикат» (справа налево, активный залог) или как «Запрос на химикат размещен Сотрудником» (слева направо, пассивный залог). Согласно некоторым правилам, фигуру в форме ромба следует назвать «размещен тем-то», что имеет смысл, только если читать диаграмму слева направо. Если перерисовать диаграмму с обратным относительным положением элементов «Сотрудник, разместивший заказ на химикат» и «Заказ химиката», тогда название связи «размещен» будет неверным при чтении слева направо: утверждение «Сотрудник размещен заказом химиката» неверно. Лучше назвать связь «размещение», а потом изменить формулировку в соответствии с грамматикой при чтении утверждения — «размещает» или «размещен». Показывая диаграмму «сущность–связь» клиентам, попросите их проверить, все ли связи показаны корректно. Также попросите их определить все возможные сущности и связи с сущностями, которые не показаны на модели.
Мощность (cardinality) каждой связи, или ее численность, показаны цифрами или буквами на линиях, соединяющих сущности и связи. Для диаграмм «сущность–связь» используются различные нотации для обозначения мощности; нотация на рис. 1-1 используется чаще всего. Поскольку каждый сотрудник, разместивший заказ на химикат, может разместить несколько заказов, то между элементами «Сотрудник, разместивший заказ на химикат», и «Заказ химиката» существует связь «один ко многим». Это количество элементов показано цифрой 1 на линии, соединяющей элемент «Сотрудник, разместивший заказ на химикат», и связь «размещение», и буквой М (многие) на линии, соединяющей элемент «Запрос химиката» и связь «размещение». К другим возможным мощностям относятся: «один к одному» (каждый контейнер с химикатом отслеживается в одной истории контейнера) и «многие ко многим» (в каждом каталоге поставщика содержится множество Химикатов, а некоторые Химикаты встречаются в нескольких Каталогах поставщика). Если вам известна более точная мощность, чем просто много (у человека ровно два биологических родителя), вместо общего М можно указать конкретное число или диапазон.
В альтернативных нотациях диаграммы «сущность–связь» на линиях, соединяющих сущности и связи, для обозначения мощности используются другие символы. В нотации Джеймса Мартина, показанной на рис. 1-2, сущности по-прежнему представлены прямоугольниками, но связи между ними обозначают на соединяющей их линии. Вертикальная черта рядом с элементом «Товары на складе химикатов» указывает на мощность «1», а «гусиная лапка» рядом с элементом «Контейнер с химикатом» указывает на мощность «многие». Круг рядом с гусиной лапкой означает в элементе «Товары на складе химикатов» может находится ноль или больше элементов «Контейнер с химикатом».

Рис. 1-2. Одна альтернативная нотация в диаграмме «сущность–связь»
Помимо различных нотаций диаграммы «сущность–связь» существуют другие соглашения о моделировании данных. Команды, применяющие объектно-ориентированные методы разработки, обычно создают UML диаграммы классов, на которых показаны атрибуты данных классов (что соответствует сущностям на диаграмме «сущность–связь»), логические связи между классами и мощность этих связей. На рис. 1-3 показана часть диаграммы классов для Chemical Tracking System. На ней показаны отношения «один ко многим» между элементами «Сотрудник, заказывающий химикат» и «Заказ химиката», каждый из которых является «классом» в прямоугольнике. Нотация «1..*» означает «один или больше». В диаграммах классов может применяться другая нотация для обозначения мощности (или множественности). Заметьте, что на диаграмме классов в средней части прямоугольника также перечисляются атрибуты класса. На рис. 1-3 показана упрощенная версия нотации диаграммы классов. Когда диаграммы классов используются для объектно-ориентированного анализа и проектирования, в нижней части прямоугольника (в данном примере она пуста) обычно показываются операции, или поведения, которые объекты этого класса должны выполнять. Но для моделирования данных третий раздел прямоугольника класса оставлен пустым.
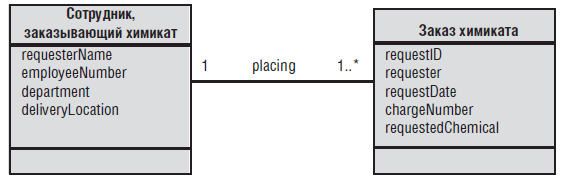
Рис. 1-3. Фрагмент UML-диаграммы классов системы Chemical Tracking System
Неважно, какая нотация используется для рисования модели данных. А важно то, чтобы все вовлеченные в проект люди (в идеале, все сотрудники организации), создающие такие модели, использовали одинаковые соглашения нотации и что все, кто использует или рецензирует модели, знали, как их интерпретировать.
Естественно, система должна также включать функциональность, которая делает что-то полезное с данными. Отношения между сущностями частопозволяют обнаружить такую функциональность. На рис. 1-1 показано, что между элементами «Контейнер с химикатом» и «История операций с контейнером» существует отношение «отслеживание». Поэтому нужна определенная функциональность — возможно зафиксированная в форме варианта использования, пользовательской истории или потока процессов, которая предоставляет пользователю доступ к истории операций с конкретным контейнером с химикатом. При анализе требований проекта с помощью моделей данных вы можете даже обнаружить ненужные данные, которые были обнаружены в процессе обсуждения, но потом нигде больше не использовались.
При выполнении анализа данных нужно сопоставлять различные представления информации между собой для обнаружения пробелов, ошибок и противоречий. Сущности в диаграмме «сущность–связь» скорее всего определены в словаре данных. Потоки данных и хранилища в диаграмме потоков данных скорее всего есть где-то в диаграмме «сущность–связь», а также в словаре данных. Отображаемые поля в спецификации отчета также должны присутствовать в словаре данных. Во время анализа данных можно сравнить эти дополняющие друг друга представления, чтобы найти ошибки и дополнительно уточнить свои требования к данным.
Один из точных способов поиска недостающих требований — матрица CRUD (Create, Read, Update, Delete — создание, чтение, обновление, удаление). Она позволяет соотнести действия системы с элементами данных (отдельными или их совокупностями), что дает представление о том, где и как каждый элемент данных создается, считывается, обновляется и удаляется. (Некоторые добавляют к названию матрицы букву L, указывая, что элемент данных является списком (list), или M или C — соответственно для обозначения перемещения или копирования данных из одного места в другое. Для простоты мы будем придерживаться обозначения CRUD.) В зависимости от используемых способов анализа требований можно исследовать различные типы соответствий, в том числе:
-
элементы данных и системные события;
-
элементы данных и задачи пользователей или варианты использования;
-
классы объектов и варианты использования.
На рис. 1-5 показана матрица CRUD для части системы Chemical Tracking System. Каждая ячейка указывает, как вариант использования, определенный в крайнем левом столбце, использует элементы данных, показанные в остальных столбцах. Вариант использования может создать (C), прочитать (R), обновить (U) или удалить (D) сущность. После создания матрицы посмотрите, нет ли ячейки столбца, в которой нет одной из этих букв. Например, если сущность обновлена, но до этого ее не создавали, то откуда она взялась?
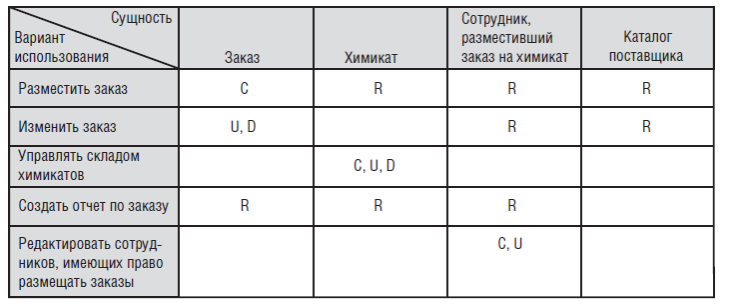
Рис. 1-5. Пример матрицы CRUDL для Chemical Tracking System
Обратите внимание, что ни одна ячейка в столбце «Сотрудник, разместивший заказ на химикат» не содержит D. То есть ни в одном из случаев использования на рис. 1-5 нельзя удалить сотрудника из списка людей, заказывавших химикаты. Интерпретировать это можно тремя способами:
-
удаление сотрудника, разместившего заказ на химикат, не является ожидаемой функцией Chemical Tracking System;
-
мы пропустили вариант использования, который удаляет сотрудника, разместившего заказ на химикат;
-
вариант использования «Редактировать сотрудников, имеющих право размещать заказы» некорректный. Предполагается, что пользователь может удалить из списка сотрудника, размещающего заказ на химикат, но в настоящее время эта функциональность не указана в вариантах использования.
Мы не знаем, какая интерпретация правильна, но CRUD — это надежный
способ для обнаружения недостающих требований.