

Виды запросов на обработку данных
Все приведенные выше примеры являлись запросами на выборку информации. Запросы этого типа являются наиболее распространенными. Все такие запросы на языке SQL реализуются посредством команды SELECT.
Перечислим другие типичные операции обработки данных: добавление (на языке SQL — INSERT), модификация (UPDATE), удаление (DELETE).
В конструкторе запросов SQL эти операции можно получить, выбирая соответствующий тип запроса.
Отдельно следует сказать о запросах, которые плохо укладываются в строгую реляционную модель. Например, следующий запрос на языке SQL возвращает количество строк в таблице “Учителя”:
SELECT COUNT(*) FROM «Учителя»
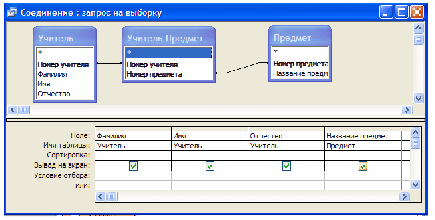
Понятно, что количество — число, атомарное значение. Тем не менее все реляционные СУБД сформируют таблицу, содержащую единственное значение. И уже эта таблица будет результатом запроса.
Дополнительные интерфейсы для редактирования и представления данных
Практически все современные СУБД предоставляют удобные интерфейсы редактирования и представления данных — формы и отчеты. Важно отметить, что указанные средства не имеют отношения к теории реляционных баз данных и лишь облегчают взаимодействие пользователей с СУБД. Этот вопрос нуждается в подобном уточнении, так как во многих популярных системах таблицы, запросы, формы и отчеты оказываются равноположенными (см. рисунок).
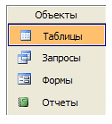
Это удобно для практической работы, но не должно вводить в заблуждение разработчиков учебных курсов и преподавателей. В отличие от таблиц и запросов, в формах и отчетах нет серьезного предмета для изучения. С ними связано множество вопросов, но все они носят технический, специфичный для конкретной СУБД характер.
5.5. Проектирование баз данных
Для функционирования информационной системы (см. “БД и СУБД” 2) необходимо, чтобы инфологическая, концептуальная модель адекватно отображала реалии предметной области. Фундаментальными же реалиями при построении инфологических моделей являются объекты (сущности) с их свойствами (атрибутами) и связи между ними. Методологии, позволяющие отображать существующую смысловую содержательность реальности независимо от компьютерного представления, относятся к так называемым семантическим методологиям.
Подобные методологии являются нисходящими, поскольку они начинаются на высшем уровне абстракции и заканчиваются представлением макета конкретной БД для конкретной СУБД.
С начала 70-х годов XX века было предложено несколько семантических методик построения инфологических моделей. Наиболее популярной и употребительной стала методика на основе так называемых “ER-моделей” (ER — “сущность-связь”, entity-relationship). ER-модели были разработаны П.Ченом в 1976 г. Отличительные особенности ER-моделей — мощность, гибкость, прозрачность.
Для повышения (существенного!) эффективности процесса разработки моделей применяют специальные комплексы программных средств — CASE-средства (Computer Aided Software/System Engineering).
ER-модели
Для основных элементов — сущностей, связей, атрибутов — в ER-моделях используются следующие обозначения (надписи на всех рисунках будут сделаны на этапе верстки):
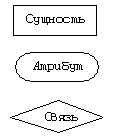
Как правило, для именования сущностей используют существительные, для связей — глаголы.
Если на этапе построения ER-модели определяются атрибуты, являющиеся первичными ключами соответствующих сущностей, то они, как правило, подчеркиваются.
Принадлежность атрибутов сущностям и связи между сущностями обозначают линиями. Линии, обозначающие связи, снабжаются указаниями на тип связи (“один к одному”, “один ко многим”, “многие ко многим”). Единого стандарта на способ обозначения типа связи нет, в последнее время одним из наиболее удобных и наглядных признан стиль, который используется в Microsoft Access. Согласно ему связи обозначаются цифрой 1 на стороне “одного” и символом “Ґ” на стороне “многих”.
Рассмотрим примеры из близкой всем нам школьной жизни.
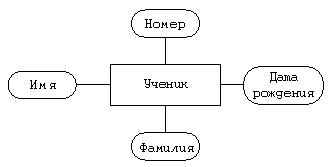
Сущность “ученик”
Атрибуты — уникальный (допустим — в пределах данной школы) номер, фамилия, имя, дата рождения.
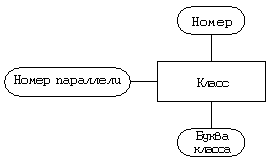
Сущность “класс”
Атрибуты — уникальный номер, номер параллели, буква класса внутри параллели.
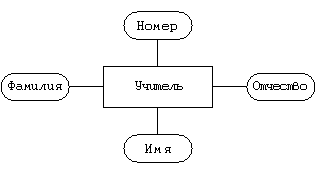
Сущность “учитель”
Атрибуты — уникальный номер, фамилия, имя, отчество.
Сущность “предмет”
Атрибуты — уникальный номер, название.
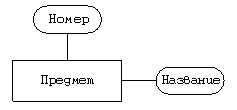
Сущность “класс—ученик”
Тип — “один ко многим”.

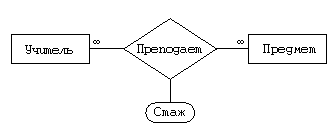
Сущность “учитель—предмет”
Тип — “многие ко многим”.

Связи, как и сущности, могут иметь атрибуты. Например, администрацию школы нередко интересует стаж преподавания данным учителем данного предмета. Если подобную информацию необходимо хранить, то естественно добавить “стаж” в качестве атрибута связи “учитель—предмет”.
Переход от ER-модели к реляционной
Описанию реляционной модели данных посвящена отдельная статья (см. “Реляционные БД” 2).
При переходе от ER-модели к даталогической реляционной модели, как правило:
— каждая сущность описывается отдельной таблицей;
— атрибуты становятся полями таблиц, для них задаются подходящие типы данных, имеющиеся в используемой СУБД;
— в таблицах определяются первичные ключи, при необходимости вводятся суррогатные;
— для связей “многие ко многим” вводятся соответствующие таблицы, снабженные, возможно, требуемыми атрибутами;
— при необходимости производится нормализация таблиц до заданной нормальной формы (как правило — до 3НФ).
После разработки макета БД его рекомендуется проанализировать с точки зрения удобства и эффективности выполнения типовых запросов. На этом этапе иногда приходится не только изменять даталогическую модель, но даже денормализовать БД, перекладывая ряд функций на уровень приложения. Приведем типичный пример. Допустим, в БД хранится информация о файлах, включающая путь, имя, описание (обычная задача для множества ИС). Все мы знаем, что при работе с подобными файловыми коллекциями в Интернете пользователю обычно сообщается и размер файла в байтах. Ясно, что размер можно вычислить в любой момент, однако поскольку вся остальная информация берется из БД, а вычисление размера требует выполнения медленной операции — обращения к файловой системе, нередко принимают решение хранить размер в БД и на уровне приложения вычислять и обновлять его при каждой операции с файлом. Понятно, что в этом случае таблица не будет удовлетворять даже второй нормальной форме.
Разработчики баз данных в целом следуют приведенной выше схеме. Вместе с тем они, например, часто предусматривают первичные ключи еще на этапе построения ER-модели, а таблицы сразу стараются делать нормализованными. Однако спроектировать БД “с ходу” можно лишь на небольшом проекте. Как правило, все описанные выше этапы все равно приходится проходить. И чем квалифицированнее специалист, тем тщательнее он относится ко всем шагам разработки.