Классификации бд по моделям данных
Базы данных классифицируются по различным признакам. Отметим, что в ряде случаев правильнее говорить не о классификации баз данных, а о классификации СУБД, поскольку именно СУБД определяют наиболее существенные (в частности — структурные) характеристики управляемых ими баз данных.
Самая интересная с содержательной точки зрения классификация БД — по используемой модели данных, или по структуре организации данных. По указанному критерию сегодня принято выделять базы данных следующих видов: иерархические, сетевые, реляционные и объектно-ориентрованные. Сразу отметим важный факт: указанные виды баз данных возникают на этапе перехода от инфологической модели, инвариантной по отношению к структуре организации данных, к даталогической модели.
Первые производственные СУБД использовали иерархическую модель данных, которая может быть представлена в виде дерева. Самой известной СУБД, использующей модель данных этого типа, является система IMS (Information Management System), разработанная фирмой IBM для поддержки лунного проекта “Аполлон”. Эта СУБД создавалась для управления огромным количеством деталей, иерархически связанных между собой, — из деталей собирались узлы, которые входили в еще более крупные модули, и т.д. Подобные конструкции легко и естественно описываются именно иерархической моделью — тут нет необходимости приводить в пример “Аполлон”, достаточно обычного велосипеда.

Иерархическая модель имеет свои естественные достоинства и недостатки. Если вернуться к идее представления конструкции некоторого устройства, то не сложно ответить на вопрос, из каких деталей состоит данный узел, но весьма затруднительно быстро получить ответ на вопрос, какому узлу принадлежит данная деталь (ведь связи направлены от корня вниз). Указанную проблему (но это, конечно, не единственная сложность, возникающая при использовании иерархической модели!) решает сетевая модель организации данных, которая может быть представлена в виде направленного графа произвольного вида (таким образом, в сетевой модели можно расставить связи-стрелочки не только от узла к детали, но и в обратную сторону).
Одной из первых практических реализаций сетевых СУБД стала Integrated Data Store (IDS), созданная компанией General Electric. Архитектура этой СУБД легла в основу деятельности группы Database Task Group, которой конференция по языкам систем данных (Conference on Data Systems Languages — CODASYL) в конце 60-х годов поручила разработать стандарты систем управления базами данных. Этот документ и по сей день используется разработчиками сетевых СУБД, количество которых, по правде говоря… ничтожно. Сетевые СУБД весьма сложны в реализации, не слишком прозрачны не только для проектировщиков и программистов, но и для пользователей. Вследствие этого они оказались на периферии развития технологий после того, как в 1970 г. доктор Э.Ф. Кодд, математик и научный сотрудник фирмы IBM, предложил реляционную модель, основанную на представлении данных в виде таблиц. Одним из основных преимуществ реляционной модели является ее однородность. Все данные хранятся в плоских таблицах и только в них. В настоящее время практически все производственные СУБД различных масштабов используют реляционную модель. Поэтому ей не только посвящена отдельная статья “Реляционные БД” 2, но и в статьях “Описание данных” 2, “Обработка данных”2 и “Проектирование БД” 2 речь идет именно о реляционных БД.
В 1981 г. “за продолжительный фундаментальный вклад в теорию и практику развития СУБД” Кодду была вручена премия Тьюринга — самая престижная международная награда в области информационных технологий. Каждый лауреат этой премии на церемонии вручения читает специальную лекцию. В своей лекции Кодд, в частности, сказал:
“Основной побудительной причиной исследований, результатом которых стало создание реляционной модели данных, было желание четко разграничить логический и физический аспекты управления базами данных, принимая во внимание проблемы создания БД, поиска и обработки информации. Мы назвали это стремлением к независимости информации.
Вторым нашим желанием было создать структурно простую модель, так чтобы пользователи и программисты любой квалификации одинаково могли бы понимать содержащуюся в ней информацию и общаться друг с другом при помощи базы данных. Мы назвали это стремлением к коммуникабельности.
В-третьих, мы хотели использовать концепции языка высокого уровня (но не специфический синтаксис), чтобы пользователи имели возможность описывать операции сразу над большими порциями информации. Это является основой для способов обработки информации, ориентированных на множества (т.е. возможности при помощи одного оператора задать операцию над несколькими множествами записей одновременно). Мы назвали это стремлением к обработке множеств”.
При разработке реляционной модели Кодд ввел два языка: описания данных и их обработки. В настоящее время для этой цели фактически используется один язык SQL (Structured Query Language). Использование общего языка стало одним из решающих конкурентных преимуществ реляционных СУБД. Фактически разработчики различных систем могут соревноваться в производительности, надежности, удобстве обслуживания и т.д., но пользователи чувствуют себя уверенно, зная, что грамотно организованные и описанные данные могут быть быстро экспортированы/импортированы из системы в систему.
Последней из рассматриваемых станет сравнительно новая технология объектно-ориентированных баз данных. Первый стандарт объектно-ориентированных баз данных ODMG-93 (Object Database Management Group) был принят в 1993 г. В нем, в частности, определены два языка — ODL (Object Data Language) для определения данных (объектов) и OQL (Object Query Language) для манипулирования данными. Язык OQL основан на языке SQL. Одним из принципиальных отличий объектных баз данных от реляционных является возможность создания и использования новых типов данных. При этом новые типы порождаются посредством наследования от базовых. В объектных базах данных также различаются операции над всеми данными типа или над конкретным экземпляром.
Объектная технология и традиционный реляционный подход пока имеют различные сферы применения. Если данные состоят из “обычных” простых полей фиксированной (или легко поддающейся оценке сверху) длины, то наилучшим решением является применение реляционной СУБД. Если же данные содержат вложенные структуры, их размер может изменяться динамически, структуры данных могут определяться пользователем в процессе функционирования БД и т.д., то имеет смысл задуматься о применении объектно-ориентированной СУБД.
Вместе с тем отметим, что реляционная и объектно-ориентированная модели не являются взаимно-исключающими. Уже довольно давно разрабатываются объектно-реляционные СУБД. Самым известным примером в этой области, возможно, является система Postgres: именно на ее основе функционируют федеральные порталы Министерства образования. Эта же СУБД используется в системе сайтов Rambler.
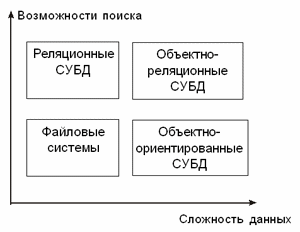
В заключение обратим внимание читателя на весьма неформальную, но популярную среди разработчиков схему, предложенную Майклом Стоунбрекером, одним из идеологов и разработчиков гибридных объектно-реляционных СУБД. Несмотря на то, что указанная схема весьма груба, она наглядно демонстрирует текущие тенденции развития технологий БД.