

4. Средства анализа технологий параллельного программирования.
4.1. Комплексный подход к анализу эффективности программ для параллельных вычислительных систем
В этом разделе представлены этапы решения параллельных задач. Для улучшения параллельной программы необходимо учитывать все её особенности, то есть знать всю её структуру.
Во-первых, устройство. Для того, чтобы улучшить программу, необходимо знать, на каком устройстве она должна работать. Для этого, выполняется анализ параметров компьютера: тип процессора, число процессоров, объем памяти, возможности ввода/вывода и тому подобное – это кажется простым и очевидным, на практике, может быть причиной проблем пользователей.
Во-вторых, анализ эффективности системного программного обеспечения и приложений. Тесты дают возможность узнать фактическую скорость передачи сообщений, параметр задержки, эффективность обмена параллельных процессов в различных логических топологиях, скорость реакции различных функций с системами обмена сообщениями, задержка на барьерах.
В-третьих, программа анализа структуры. То есть, нужно узнать, есть ли возможность повысить эффективность программы, не изменяя её алгоритма.
Последнее, анализ алгоритмического подхода. В этом случае заменяются алгоритмы, которые ухудшают работу параллельной программы, то есть заменить неуместные алгоритмические решения таким образом, чтобы их свойства удовлетворяли особенности архитектуры нужного устройства.
Все указанные выше пункты рассматриваться комплексно, с учетом задачи разработки эффективных параллельных приложений. Что и является основным приоритетом для дальнейшей работы в сфере компьютерных технологий.
4.2. Типы анализа производительности
Выделяют два основных подхода к анализу производительности технологий параллельного программирования:
А) «Трассировка + Визуализация»:
1) Сбор в журнал информации о программе во время её исполнения.
2) Просмотр и анализ полученного журнала.
В) «Онлайн-анализ». Анализ производится в ходе выполнения программы.
5.Анализ производительности технологий mpi и OpenMp
Представлены результаты тестов, проведенных для пяти узлов с двумя процессорами имеющих по четыре ядра на вычислительном кластере с максимальной производительностью 480 GFlops.
Предоставим результаты тестирования технологий MPI и OpenMP. Для анализа производительности, использовались стандартные пакеты, предназначенные для параллельных вычислений, такие как HPL, IMB и NPB.
Тестом Linpack определим максимальную производительность вычислительной системы. Для тестирования использовалась версия HPL-1, для портативного внедрения в компьютеры с распределённой памятью. Программа HPL решает система линейных алгебраических уравнений Ax = b путем разложения матрицы на две, с возможностью определить главный элемент. Здесь А – это вещественная матрица размерности N, матрица двойной точности. Данный тест принято считать основным для вычисления производительности вычислительных систем.
На графике приведены результаты влияние числа ядер на производительность.
Рисунок 5.1. влияние числа ядер на производительность.

Узнали пиковую производительность вычислительной системы для матрицы размерностью N = 96000 на тесте Linpack, она была равна 305 GFlops. Основываясь на рисунок 5.1. можем утверждать, что текущая архитектура при увеличении узлов хорошо подходит для решения типовых задач.
Тест IMB. Тест содержит основные операции обмена сообщениями в стандарте MPI-1. Экспериментальные значения в относительных единицах времени, чтобы оценить производительность различных вариантов передачи сообщений MPI. Полученные данные дадут возможность выбрать методы обмена сообщениями для создания параллельных программ. В таблице 1 показаны результаты тестов запущенных на четырех ядрах одного узла и запуск на 40 ядрах всех узлов. Для четырех ядер операции связи выполняются в оперативной памяти, для сорока ядер используются еще и комуникационные средства Gigabit Ethernet.
Таблица 5.1.
Результаты испытаний IMB
Тип передачи сообщений |
8 Байт |
1 MБайт |
||
n = 4 |
n = 40 |
n = 4 |
n = 40 |
|
PingPong |
1,1 |
- |
0,7× |
- |
Sendrecv |
1,1 |
14 |
1,6× |
1,0× |
Exchange |
1,9 |
50 |
3,6× |
7,1× |
Allreduce |
2,6 |
183 |
2,9× |
8,6× |
Reduce |
2,0 |
24 |
2,2× |
1,1× |
Allgather |
2,4 |
318 |
6,9× |
4,6× |
Alltoall |
3,5 |
334 |
1,0× |
3,9× |
Bcast |
1,4 |
33 |
1,5× |
8,9× |


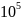

Таблица 5.1 предоставляет данные для малых и больших сообщений: 8 байт и 1048576 байт (1 Мб). Время работы в условных единицах для сообщений первого типа в основном зависит от латентности среды связи, для второго типа от пропускной способности среды связи. Таблица данных 5.1. показывают разницу результатов при количестве ядер равном четырем и сорока, в несколько раз, это связано с тем, что в одном случае, все операции связи выполняются в оперативной памяти, в другом операции связи выполняются еще и в сети Gigabit Ethernet.
Объясним используемые операции передачи сообщений. Тест PingPong только два активных процесса, которые, когда выполняют MPI_Send, MPI_Recv, другие процессы ждут. Тест SendRecv в опытной эксплуатации выполняет MPI_Sendrecv в периодических цепях связи. Для теста Exchange MPI_Isend / MPI_WAITALL, MPI_Recv, которые используются в алгоритмах сетки для обмена на границах. В других тестах с использованием коллективных операций: MPI_ALLREDUCE и MPI_Reduce, MPI_Allgather, MPI_Alltoall, MPI_Bcast. Тесты показывают, что задержка в общих операциях достаточно велика, в связи с одновременной отправкой сообщений. Отсюда следует, что для сети Gigabit Ethernet: при программировании необходимо избегать коллективных операций большой длины передачи, отправляя равномерно данные программы, предпочтительнее асинхронные операции по двум точкам.
Испытание NPB. NAS Parallel Benchmark тест предназначен для оценки производительности параллельных вычислений. Тест состоит из серии простых задач: ядра и приложений. Ядра и приложения могут выполнять вычисления в классах сложности: S, W, A, B, C, D. С увеличением сложности увеличивается размерность класса базовых наборов данных и число итераций в основных программных циклах. Ниже приведены результаты тестирования серии тестов производительности NAS Parallel Benchmark, и их порядок строится в соответствии с уровнем нагрузки на сети связи. Ниже приведены показатели производительности в результате тридцати тестов.
Тест «ЕР» используется для оценки производительности в вычислениях с плавающей точкой, с условием отсутствия заметных межпроцессорных взаимодействий. Это включает в себя генерирование псевдослучайных чисел. В таблица 5.2 видим результаты работы теста, в скобках приводится количество узлов. Видно, что для одного узла, OpenMP показывает ту же производительность, что и MPI. Производительность не изменяется, когда мы увеличиваем количество узлов. Компилятор ifort, в отличии от других, на данном тесте показал самые высокие результаты.
Таблица 5.2
Производительность R / N для испытания EP
N |
Тип |
Компилятор |
Класс A |
Класс B |
Класс C |
Класс D |
8(1) |
MPI |
ifort – O3 |
51 |
51 |
51 |
50 |
MPI |
gfort – O3 |
26 |
26 |
26 |
26 |
|
MPI |
LLVM – O3 |
27 |
27 |
28 |
27 |
|
OpenMP |
ifort – O3 |
52 |
52 |
52 |
- |
|
16(2) |
MPI |
ifort – O3 |
49 |
51 |
50 |
50 |
32(4) |
MPI |
ifort –O3 |
49 |
49 |
49 |
49 |
В тесте «LU» проведено разложение Гауса-Зейделя. Он показывает результаты оценки эффективности, в том числе значений относительного изменения в% (R - среднее значение, к - размер выборки):
 ,
,

Можно видеть, что в том же самом узле технологии OpenMP показывает лучшую производительность, чем MPI. В связи с увеличением числа узлов не меняет производительность класса C. Сложность этого теста используются синхронное сообщение прохождения короткой длины, так что сеть связи не перегружена.
Таблица 5.3.
Результаты испытаний LU
Ядра |
Технология |
Компилятор |
Класс А |
Класс B |
Класс C |
|||
R/n |
σn |
R/n |
σn |
R/n |
σn |
|||
8(1) |
MPI |
ifort |
950 |
0,8 |
798 |
0,3 |
574 |
3 |
MPI |
gfort |
954 |
0,6 |
809 |
0,4 |
590 |
5 |
|
MPI |
LLVM |
962 |
0,6 |
806 |
1 |
608 |
5 |
|
OpenMP |
ifort |
1132 |
0,3 |
1052 |
0,4 |
654 |
2 |
|
16(2) |
MPI |
ifort |
1102 |
3 |
756 |
0,9 |
756 |
0,8 |
32(4) |
MPI |
ifort |
358 |
28 |
421 |
12 |
546 |
5 |
Тест множественной сетки «MG» является приближенным решением уравнения Пуассона с трехмерными периодическими границами условий. Таблица 5.4 показывает результаты экспериментов. Можно видеть, что в пределах той же технологии, узел OpenMP показал такую же производительность, как и MPI. Тем не менее, производительность снижается с увеличением числа узлов. GNU компилятор показал большую эффективность в этом тесте.
Таблица 5.4.
Результаты испытаний МГ
Ядра |
Технология |
Компилятор |
Класс А |
Класс B |
Класс C |
|||
R/n |
σn |
R/n |
σn |
R/n |
σn |
|||
8(1) |
MPI |
ifort |
302 |
0,1 |
323 |
0,1 |
303 |
0,1 |
MPI |
gfort |
341 |
0,1 |
368 |
0,1 |
328 |
0,3 |
|
MPI |
LLVM |
339 |
0,1 |
367 |
0,1 |
328 |
0,2 |
|
OpenMP |
ifort |
320 |
0,2 |
346 |
0,1 |
- |
- |
|
16(2) |
MPI |
ifort |
239 |
0,4 |
262 |
0,3 |
265 |
0,3 |
32(4) |
MPI |
ifort |
104 |
21 |
126 |
9 |
150 |
2 |
В тесте сопряженных градиент «CG» решается система линейных алгебраических уравнений с разряженнием произвольной матрицы метода сопряженных градиентов. Переключение организовано с помощью двухточечной неблокируемому взаимодействий. Из таблицы. 5.5. то ясно, что в том же самом узле технологии OpenMP показывает лучшую производительность, чем MPI. С увеличением числа узлов R / п производительность заметно снижается.
Таблица 5.5.
Результаты для испытания CG
Ядра |
Технология |
Компилятор |
Класс А |
Класс B |
Класс C |
|||
R/n |
σn |
R/n |
σn |
R/n |
σn |
|||
8(1) |
MPI |
ifort |
264 |
2,9 |
118 |
0,14 |
119 |
0,09 |
MPI |
gfort |
273 |
4,84 |
118 |
0,43 |
119 |
0,18 |
|
MPI |
LLVM |
252 |
4,74 |
117 |
0,13 |
118 |
0,21 |
|
OpenMP |
ifort |
354 |
3,77 |
127 |
0,5 |
126 |
0,14 |
|
16(2) |
MPI |
ifort |
172 |
2,64 |
90 |
1,51 |
89 |
1,12 |
32(4) |
MPI |
ifort |
97 |
0,83 |
89 |
1,2 |
55 |
1,66 |
Тест «FT», тест быстрого преобразования Фурье. Взаимодействие между процессами с помощью следующих коллективных операций: MPI_Reduce, MPI_Barrier, MPI_Bcast, MPI_Alltoall. Данные, представленные в таблице. 5.6, показывают, что в пределах той же технологии узла производительности OpenMP показывает производительность в два раза выше, чем MPI. С увеличением числа узлов R / п производительность резко падает.
Таблица 5.6.
Результаты испытаний FT
Ядра |
Технология |
Компилятор |
Класс А |
Класс B |
Класс C |
|||
R/n |
σn |
R/n |
σn |
R/n |
σn |
|||
8(1) |
MPI |
ifort |
311 |
0,1 |
332 |
0,1 |
350 |
0,2 |
MPI |
gfort |
294 |
0,3 |
357 |
0,1 |
371 |
0,3 |
|
MPI |
LLVM |
294 |
0,3 |
355 |
0,1 |
369 |
0,2 |
|
OpenMP |
ifort |
650 |
0,4 |
690 |
0,1 |
- |
- |
|
16(2) |
MPI |
ifort |
110 |
3 |
116 |
1 |
128 |
0,8 |
32(4) |
MPI |
ifort |
49 |
7 |
72 |
1 |
90 |
0,7 |
Тест «IS» параллельно сортирует массив целых чисел, при помощи карманной сортировки. Результаты представлены в таблице 5.7. Мы видим, что при увеличении количества узлов, для технологии MPI падает производительность, а технология OpenMP показывает самые высокие результаты.
Таблица 5.7.
Результаты испытаний для IS
Ядра |
Технология |
Компилятор |
Класс А |
Класс B |
Класс C |
|||
R/n |
Σn |
R/n |
σn |
R/n |
σn |
|||
8(1) |
MPI |
icc |
20,4 |
0,4 |
19,1 |
0,6 |
18,8 |
0,7 |
MPI |
gcc |
20,6 |
0,2 |
19,2 |
0,7 |
18,8 |
0,8 |
|
MPI |
LLVM |
20,5 |
0,3 |
19,2 |
0,7 |
18,8 |
0,8 |
|
OpenMP |
icc |
35,6 |
0,1 |
33,8 |
0,1 |
33,9 |
0,1 |
|
16(2) |
MPI |
icc |
3,35 |
12 |
4,86 |
3 |
5,18 |
1 |
32(4) |
MPI |
icc |
0,44 |
29 |
1,47 |
17 |
2,95 |
4 |
Передача сообщений между процессами осуществляется с использованием MPI_Alltoall и MPI_ALLREDUCE операций. Экспериментальные результаты указывают, что производительность при использовании одного узла OpenMP в полтора раза выше, чем MPI. Производительность быстро падает с увеличением числа узлов. Вероятно, данное понижение производительности происходит в связи с большой нагрузкой, из-за сообщений большого размера, на сети связи. Решение подобных задач при увеличении количества узлов, будет вести к ухудшению производительности, если сравнить с вычислениями на одном узле. Исходя из этого, рекомендуемый предел распараллеливание для схожих задач будет ограничение в количество ядер на одном узле. Для этого кластера - 8 процессов.
Когда процессы работают с большими объемами данных, которые не помещаются в кэш-памяти, самым правильным является их разделению на различных физических процессорах, исходя из этого нужно использовать OpenMP. Когда маленький объем передаваемых сообщений максимальной производительности будут достигнуты, когда они работают на одном физическом процессоре, а в этом случае удобнее MPI.
Компиляторы icc и ifort иногда показывают очень большой разрыв между работой других компиляторов, и более эффективными в отличии по сравнению с GNU. Но GNU изредка выигрывают у других компиляторов. Учитывая, что они свободно распространяется по лицензии GPL, они отлично подходят для целей образования и для проведения научных исследований.
Заключение
Равномерная загрузка процессов является главной задачей при организации параллельных вычислений. Если бы основной вычислительной работы будет заниматься один процессор, мы возвращаемся к обычным последовательным вычисления, которые не приносят выигрыша за счет распараллеливания. Не менее важным вопросом является скорость обмена информацией между процессорами. Если загрузка процессоры равномерно загружены, но скорость обмена данными мала, то много времени будет тратиться лишь на ожидание информации, нужной для работы данного процессора.
В работе мы рассмотрели две категории технологий:
Технологии для разработки параллельных программ для систем с общей и распределенной памятью.
Технологии разработки параллельных программ для графических процессоров.
Увеличение эффективности параллельных программ и возможность свести к минимуму расходы организации параллелизма – основное требование к модели обмена сообщениями, в качестве интерфейса связи.
CUDA относительно методов GPGPU лучше из-за того, что эта архитектура предназначена для качественного применения неграфических вычислений на графическом процессоре и использование языка C, без необходимости приводить алгоритмы в удобный графический вид. CUDA предлагает новый способ вычислений на графических процессорах, которая не использует графический API, предлагая оперативное запоминающее устройство (рассеивают или собираются). Эта архитектура лишена недостатков и GPGPU использует все исполнительные блоки, а также расширение возможностей в связи с целочисленной арифметикой и битовые операции сдвига.
Когда процессы работают с большими объемами данных, которые не помещаются в кэш-памяти, самым правильным является их разделению на различных физических процессорах, исходя из этого нужно использовать OpenMP. Когда маленький объем передаваемых сообщений максимальной производительности будут достигнуты, когда они работают на одном физическом процессоре, а в этом случае удобнее MPI.
Рассмотрели ряд программ, используемых для распараллеливания. И рассмотрены проблемы, связанные с их использованием.
В ходе выполнения работы мы ознакомились с технологиями параллельного программирования, их особенностями на уровне достаточном для осознанного выбора конкретной технологии, дабы начать её изучение более углубленно.
Список используемой литературы:
NVIDIA Corporation, – CUDA C Best Practices Guide. – Version 3.2. [Электронный ресурс] / Режим доступа http://developer.download.nvidia.com/compute/cuda/3_2/toolkit/docs/ CUDA_C_Best_Practices_Guide.pd.
Боресков А. В., Харламов А. В. – Основы работы с технологией CUDA. – М.: ДМКПресс, 2010. – 232 с.
Васильева М.В., Захаров П.Е., Сирдитов И.К., Попов П.А., Еремеева М.С. – Параллельное программирование на основе библиотек.
Гергель В.П. – Современные языки и технологии параллельного программирования. – М. : МГУ , 2012. – 408 с.
Гришагин В.А., Свистунов. А.Н. – Параллельное программирование на основе MPI. – Н. Новгород: ННГУ, 2005. – 89 с.
Крюков В.А. Разработка параллельных программ для вычислительных кластеров и сетей // Информационные технологии и вычислительные системы. – 2003 г. – № 1 – 2.
Мальковский С.И., Пересветов В.В. – Оценка производительности вычислительного кластера на четырехъядерных процессорах, – 2009.
Технологии параллельного программирования [Электронный ресурс] / Режим доступа http: parallel.ru.