

только он. Очевидно, что непротиворечивость выбора на основе только левого контекста обеспечить сложнее, чем на основе левого и правого контекстов. Поэтому класс LR(0) грамматик уже, чем класс LR(1) грамматик, для которых учитывается и правый контекст тоже.
Ситуация представляет собой множество правил КС-грамматики, в которых указывается положение считывающей головки МП-автомата, которое может возникнуть при разборе сентенциальной формы этой грамматики. Это положение обозначается в правой части правила специальным символом •. Этот символ не входит в алфавит грамматики. Если S – аксиома некоторой Для КС-грамматики G(T, N, P, S), где S→α1 | α2 | … | αn P, αi V*, начальной ситуацией будет множество правил R={S→•α1 , S→•α2 , … , S→•αn }. Последовательность ситуаций строится по следующим правилам:
1.r R : A→γ•Bβ, A,B N, γ,β V* , p P : B→α, α V* R=R {B→•α}, т.е. ситуация пополняется новыми пра-
вилами
2.r R : A→γ•xβ, A N, γ,β V* , x V R’={A→γx•β }, и R→xR’ т.е. строится новая ситуация, знак →x означает, что новая ситуация следует из текущей по символу x.
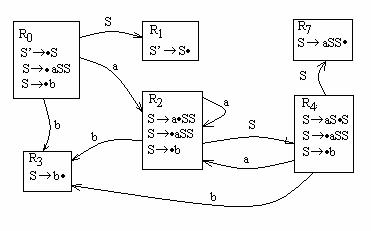
Множество связанных между собой по разным символам ситуаций и является последовательностью ситуаций. Она может быть изображена в виде графа. Поскольку количество правил грамматики конечно, то и последовательность ситуаций тоже конечна. Для построения управляющего автомата все ситуации в последовательности нумеруются: R0, R1, R2, …, Rn. Здесь R0
– начальная ситуация. Пример:
G=({a,b},{S}, {S→aSS | b},S). Построим последовательность ситуаций.
Вначале строим пополненную грамматику, поскольку аксиома встречается в правой части правил: G’=({a,b},{S,S’}, {S’→S, S→aSS | b},S’).
0. |
R0={ S’→•S}. |
|
|
1. |
Поскольку существуют правила для S, то R0= R0 { S→•aSS , S→•b} |
R0={ S’→•S, S→•aSS , S→•b} |
|
2. |
R0 |
→s R1 = { S’→S•}Других правил в эту ситуацию добавить нельзя |
|
2. R0 →a R2 = { S→a•SS }. |
|
||
1. |
Поскольку существуют правила для S, то R2= R2 { S→•aSS , S→•b} |
R2={ S→a•SS, S→•aSS , S→•b} |
|
2. |
R0 |
→b R3 = { S→b• }. Других правил в эту ситуацию добавить нельзя |
|
2. R2 →s R4 = { S→aS•S } |
|
||
1. |
Поскольку существуют правила для S, то R4= R4 { S→•aSS , S→•b} |
R4={ S→aS•S, S→•aSS , S→•b} |
|
2. R2 →a R5 = { S→a•SS }. |
|
||
1. |
Поскольку существуют правила для S, то R5= R5 { S→•aSS , S→•b} |
R5={ S→a•SS, S→•aSS , S→•b}=R2 |
|
2. R2 |
→b R6 = { S→b• }. Других правил в эту ситуацию добавить нельзя |
R6=R3 |
|
2. R4 |
→s R7 = { S→aSS• } Других правил в эту ситуацию добавить нельзя |
|
|
2. R4 →a R8 = { S→a•SS }. |
|
||
1. |
Поскольку существуют правила для S, то R8= R8 { S→•aSS , S→•b} |
R8={ S→a•SS, S→•aSS , S→•b}=R2 |
|
2. R4 |
→b R9 = { S→b• }. Других правил в эту ситуацию добавить нельзя |
R9=R3 |
|
Итого получилось 6 ситуаций: 0,1,2,3,4,7. Граф:
Построение распознавателя. Распознаватель для LR(0) грамматики функционирует на основе управляющей таблицы. Она строится следующим образом: строками являются все ситуации грамматики, столбцы содержат все символы словаря (как терминальные так и нетерминальные и маркер конца строки). Элементом ij таблицы является операция, которую будет выполнять автомат, если он находится в состоянии i, а текущим символом является j. Автомат использует 2 стека – стек символов и стек состояний. Возможны 4 типа операции:
-перенос(сдвиг) П(s). Текущий символ помещается в стек символов. Если это терминал – перемещение головки чтения. Символ входной строки фиксируется в качестве текущего. В стек состояний заносится s. Автомат переходит в состояние s.
-свертка С(n, A, k). Свертка по правилу k: A→α. Из вершин обоих стеков удаляется по n символов, где n = |α|. Нетерминал А фиксируется в качестве текущего символа. Номер правила (k) заносится в разбор грамматики. Переход в состояние, указанное на вершине стека состояний.

-Ошибка E. Разбор не может быть продолжен. Строка отвергается.
-Конец. Разбор окончен, строка принята.
Управляющая таблица U = {uij } строится на основе последовательности ситуаций.
1.Для каждой ситуации Ri создается строка таблицы i.
2.Для каждой ситуации Ri выполняется следующее:
-r Ri : A→γ•, γ V* , A N, k – номер правила A→γ uij = П (|γ|, A, k), для всех j≠S
-r Ri : A→γ•xβ, γ,β V* , x V, A N, Ri→x Rj uix = С (j)
3.u0S = Конец
4.Во все оставшиеся пустыми ячейки таблицы заносится Ошибка. При этом каждой ячейке можно поставить в соответствие
свое диагностическое сообщение, локализующее и классифицирующее ошибку.
Если таблицу удалось заполнить непротиворечивым образом, т.е. для одной и той же ячейки таблицы нет взаимоисключающих действий, то рассматриваемая грамматика является LR(0) грамматикой. Перед началом работы распознаватель устанавливается в состояние 0, головка чтения – на первый символ входной строки, который принимается в качестве текущего. Стек символов содержит #, стек состояний 0. Дальнейшее функционирование происходит на основе таблицы. Пример:
|
|
Ситуация |
|
S’ |
|
S |
|
a |
|
b |
# |
|
|
||
|
|
0 |
|
|
Конец |
|
П(1) |
|
П(2) |
|
П(3) |
|
Е |
|
|
|
|
1 |
|
|
E |
|
С (1, S’, 1) |
|
С (1, S’, 1) |
|
С (1, S’, 1) |
|
С (1, S’, 1) |
|
|
|
|
2 |
|
|
E |
|
П(4) |
|
П(2) |
|
П(3) |
|
Е |
|
|
|
|
3 |
|
|
E |
|
С (1, S, 3) |
|
С (1, S, 3) |
|
С (1, S, 3) |
|
С (1, S, 3) |
|
|
|
|
4 |
|
|
E |
|
П(7) |
|
П(2) |
|
П(3) |
|
Е |
|
|
|
|
7 |
|
|
E |
|
С (3, S, 2) |
|
С (3, S, 2) |
|
С (3, S, 2) |
|
С (3, S, 2) |
|
|
Пример разбора цепочки abababb: |
|
|
|
|
|
|
|
|
|
||||||
Входная строка |
|
Состояние |
Текущий символ |
|
Стек символов |
|
Стек состояний |
|
Разбор |
|
|||||
abababb# |
|
0 |
|
a |
|
# |
|
0 |
|
|
|
|
|||
bababb# |
|
2 |
|
b |
|
#a |
|
02 |
|
|
|
|
|||
|
ababb# |
|
3 |
|
a |
|
#ab |
|
023 |
|
|
|
|
||
|
ababb# |
|
2 |
|
S |
|
#a |
|
02 |
|
3 |
|
|
||
|
ababb# |
|
4 |
|
a |
|
#aS |
|
024 |
|
3 |
|
|
||
|
babb# |
|
2 |
|
b |
|
#aSa |
|
0242 |
|
3 |
|
|
||
|
abb# |
|
3 |
|
a |
|
#aSab |
|
02423 |
|
3 |
|
|
||
|
abb# |
|
2 |
|
S |
|
#aSa |
|
0242 |
|
33 |
|
|
||
|
abb# |
|
4 |
|
a |
|
#aSaS |
|
02424 |
|
33 |
|
|
||
|
bb# |
|
2 |
|
b |
|
#aSaSa |
|
024242 |
|
33 |
|
|
||
|
b# |
|
3 |
|
b |
|
#aSaSab |
|
0242423 |
|
33 |
|
|
||
|
b# |
|
2 |
|
S |
|
#aSaSa |
|
024242 |
|
333 |
|
|
||
|
b# |
|
4 |
|
b |
|
#aSaSaS |
|
0242424 |
|
333 |
|
|
||
|
# |
|
|
3 |
|
# |
|
#aSaSaSb |
|
02424243 |
|
333 |
|
|
|
|
# |
|
|
4 |
|
S |
|
#aSaSaS |
|
0242424 |
|
3333 |
|
|
|
|
# |
|
|
7 |
|
# |
|
#aSaSaSS |
|
02424247 |
|
3333 |
|
|
|
|
# |
|
|
4 |
|
S |
|
#aSaS |
|
02424 |
|
33332 |
|
|
|
|
# |
|
|
7 |
|
# |
|
#aSaSS |
|
024247 |
|
33332 |
|
|
|
|
# |
|
|
4 |
|
S |
|
#aS |
|
024 |
|
333322 |
|
|
|
|
# |
|
|
7 |
|
# |
|
#aSS |
|
0247 |
|
333322 |
|
|
|
|
# |
|
|
0 |
|
S |
|
# |
|
0 |
|
3333222 |
|
|
|
|
# |
|
|
1 |
|
# |
|
#S |
|
01 |
|
3333222 |
|
|
|
|
# |
|
|
0 |
|
S’ |
|
# |
|
0 |
|
33332221 |
|
|
|
Разберем еще один пример. G({+, (, ), i},{S, E, F},{S→E; E→F+E; E→F; F→(E); F→i}, S) |
|
|
|
|
|||||||||||
0. |
R0={ S→•E}. |
|
|
|
|
|
|
|
|
|
|
|
|
||
1. |
Поскольку существуют правила для E, то R0= R0 { E→•F+E , E→•F} |
R0={ S→•E, E→•F+E, E→•F } |
|||||||||||||
1. |
Поскольку существуют правила для F, то R0= R0 { F→•(E) , F→•i} |
R0={ S→•E, E→•F+E, E→•F, F→•(E) , F→•i} |
|||||||||||||
2. R0 →E R1 = { S→E•}Других правил в эту ситуацию добавить нельзя |
|
|
|
|
|
|
|||||||||
2. R0 →F R2 = { E→F•+E, E→F• } Других правил в эту ситуацию добавить нельзя |
|
|
|
|
|||||||||||
2. |
R0 →( R3 = { F→(•E)} |
|
|
|
|
|
|
|
|
|
|||||
1. |
Поскольку существуют правила для E, то R3= R3 { E→•F+E , E→•F} |
R3={ F→(•E), E→•F+E , E→•F } |
|||||||||||||
1. |
Поскольку существуют правила для F, то R3= R3 { F→•(E) , F→•i} |
R3={ F→(•E), E→•F+E , E→•F, F→•(E) , F→•i } |
|||||||||||||
2. |
R0 →i R4 = { F→i•} Других правил в эту ситуацию добавить нельзя |
|
|
|
|
|
|
||||||||
2. R2 →+ R5 = { E→F+•E } |
|
|
|
|
|
|
|
|
|
||||||
1. |
Поскольку существуют правила для E, то R5= R5 { E→•F+E , E→•F} |
R5={ E→F+•E, E→•F+E , E→•F } |
|||||||||||||
1. |
Поскольку существуют правила для F, то R5= R5 { F→•(E) , F→•i} |
R5={ E→F+•E, E→•F+E , E→•F, F→•(E) , F→•i } |
|||||||||||||
2. |
R3 →E R6 = { F→(E•) } Других правил в эту ситуацию добавить нельзя |
|
|
|
|
|
|
||||||||
2. R3 →F R = { E→F•+E, E→F• } Других правил в эту ситуацию добавить нельзя, она совпадает с R2 |
|||||||||||||||
2. |
R3 →( R = { F→(•E)} |
|
|
|
|
|
|
|
|
|
|||||
1. |
Поскольку существуют правила для E, то R= R { E→•F+E , E→•F} |
R={ F→(•E), E→•F+E , E→•F } |
|
1. |
Поскольку существуют правила для F, то R= R { F→•(E) , F→•i} |
R={ F→(•E), E→•F+E , E→•F, F→•(E) , F→•i } |
|
|
|
ситуация совпадает с R3 |
|
2. |
R3 |
→i R = { F→i• } Других правил в эту ситуацию добавить нельзя, она совпадает с R4 |
|
2. R5 |
→E R7 = { E→F+E• } Других правил в эту ситуацию добавить нельзя |
|
|
2. R5 |
→F R = { E→F•+E, E→F• } Других правил в эту ситуацию добавить нельзя, она совпадает с R2 |
||
2. |
R5 |
→( R = { F→(•E)} |
|
1. |
Поскольку существуют правила для E, то R= R { E→•F+E , E→•F} |
R={ F→(•E), E→•F+E , E→•F } |
|
1. |
Поскольку существуют правила для F, то R= R { F→•(E) , F→•i} |
R={ F→(•E), E→•F+E , E→•F, F→•(E) , F→•i } |
|
|
|
ситуация совпадает с R3 |
|
2. |
R5 |
→i R = { F→i• } Других правил в эту ситуацию добавить нельзя, она совпадает с R4 |
|
2. |
R6 |
→) R8 = { F→(E)•} Других правил в эту ситуацию добавить нельзя |
|
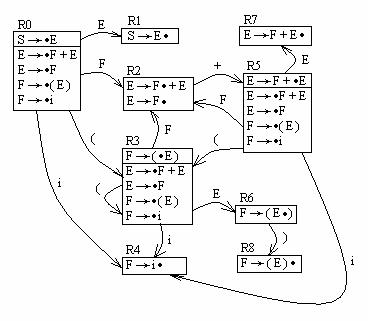
Итого получилось 8 ситуаций. Граф:
|
|
|
|
|
|
|
|
|
|
|
Ситуация |
S |
|
E |
F |
+ |
( |
) |
|
i |
# |
0 |
Конец |
|
П(1) |
П(2) |
Е |
П(3) |
Е |
П(4) |
Е |
|
1 |
Е |
С(1,S,1) |
С(1,S,1) |
С(1,S,1) |
С(1,S,1) |
С(1,S,1) |
С(1,S,1) |
С(1,S,1) |
||
2 |
Е |
С(1,Е,3) |
С(1,Е,3) |
С(1,Е,3) |
С(1,Е,3) |
С(1,Е,3) |
С(1,Е,3) |
С(1,Е,3) |
||
|
|
|
|
|
П(5) |
|
|
|
|
|
3 |
Е |
|
П(6) |
П(2) |
Е |
П(3) |
Е |
П(4) |
Е |
|
4 |
Е |
С(1,F,5) |
С(1,F,5) |
С(1,F,5) |
С(1,F,5) |
С(1,F,5) |
С(1,F,5) |
С(1,F,5) |
||
5 |
Е |
|
П(7) |
П(2) |
Е |
П(3) |
Е |
П(4) |
Е |
|
6 |
Е |
|
Е |
Е |
Е |
Е |
П(8) |
Е |
Е |
|
7 |
Е |
С(3,Е,2) |
С(3,Е,2) |
С(3,Е,2) |
С(3,Е,2) |
С(3,Е,2) |
С(3,Е,2) |
С(3,Е,2) |
||
8 |
Е |
С(3,F,4) |
С(3,F,4) |
С(3,F,4) |
С(3,F,4) |
С(3,F,4) |
С(3,F,4) |
С(3,F,4) |
||
В позиции (2,+) возник конфликт перенос-свертка. Соответственно данная грамматика не является LR(0). Рассмотрим построение распознавателя для LR(1) грамматик.
Ситуация для LR(1) грамматики задается несколько сложнее. Если S – аксиома некоторой Для КС-грамматики G(T, N, P, S), где S→α1 | α2 | … | αn P, αi V*, начальной ситуацией будет множество правил R={S→•α1 /#, S→•α2 /#, … , S→•αn
/#}. Таким образом, в правилах ситуаций указывается еще и правый контекст. Последовательность ситуаций строится по следующим правилам:
1.r R : A→γ•Bbβ /a, A,B N, a,b T, γ,β V* , p P : B→α, α V* R=R {B→•α /b}, т.е. ситуация пополняется новыми правилами с учетом правого контекста
2.r R : A→γ•B /a, A,B N, a T, γ V* , p P : B→α, α V* R=R {B→•α /a}
3.r R : A→γ•BCβ /a, A,B,C N, a T, γ,β V* , p P : B→α, α V* , c S(C) R=R {B→•α /c}, где S(C) – Мно-
жество символов предшественников
4.r R : A→γ•xβ /a, A N, γ,β V* , a T, x V R’={A→γx•β /a}, и R→xR’
Пример: G({+, (, ), i},{S, E, F},{S→E; E→F+E; E→F; F→(E); F→i}, S)
0. R0={ S→•E /#}
1. Поскольку существуют правила для E, то R0= R0 { E→•F+E /# , E→•F /#} R0={ S→•E /#, E→•F+E /# , E→•F /#} 1. Поскольку существуют правила для F, то R0= R0 { F→•(E) /+ , F→•i /+, F→•(E) /# , F→•i /# }
|
|
R0={ S→•E /#, E→•F+E /# , E→•F /#, F→•(E) /+ , F→•i /+, F→•(E) /# , F→•i /# } |
|
2. |
R0 |
→E R1 = { S→E• /#} Других правил в эту ситуацию добавить нельзя |
|
2. |
R0 |
→F R2 = { E→F•+E /#, E→F• /# } Других правил в эту ситуацию добавить нельзя |
|
2. R0 →( R3 = { F→(•E) /+ , F→(•E) /# } |
|
||
1. |
Т.к. существуют правила для E, то R3= R3 { E→•F+E /) , E→•F /)} |
R3={ F→(•E) /+ , F→(•E) /#, E→•F+E /) , E→•F /) } |
|
1. |
Поскольку существуют правила для F, то R3= R3 { F→•(E) /+ , F→•i /+, F→•(E) /) , F→•i /) } |
||
|
|
R3={ F→(•E) /+ , F→(•E) /#, E→•F+E /) , E→•F /), F→•(E) /+ , F→•i /+, F→•(E) /) , F→•i /) } |
|
Продолжая построения аналогичным образом, получим 15 ситуаций. Граф:
Построение распознавателя для LR(1) грамматики. Распознаватель для LR(1) грамматики строится по похожим принципам, что и для LR(0). Управляющая таблица U = {uij } строится следующим образом.
1.Для каждой ситуации Ri создается строка таблицы i.
2.Для каждой ситуации Ri выполняется следующее:
-r Ri : A→γ• /a, γ V* , A N, a T, k – номер правила A→γ uia = П(|γ|, A, k)
-r Ri : A→γ•xβ /a, γ,β V* , x V, A N, a T, Ri→x Rj uix = С(j)
2.u0S = Конец
3.Во все оставшиеся пустыми ячейки таблицы заносится Ошибка.
Если таблицу удалось заполнить непротиворечивым образом, то рассматриваемая грамматика является LR(1) грамматикой. Перед началом работы распознаватель устанавливается в состояние 0, головка чтения – на первый символ входной строки, который принимается в качестве текущего. Стек символов содержит #, стек состояний 0. Дальнейшее функционирование происходит на основе таблицы. Пример:
Ситуация |
S |
E |
F |
+ |
( |
) |
i |
# |
0 |
Конец |
П(1) |
П(2) |
Е |
П(3) |
Е |
П(4) |
Е |
1 |
Е |
Е |
Е |
Е |
Е |
Е |
Е |
С(1,S,1) |
2 |
Е |
Е |
Е |
П(5) |
Е |
Е |
Е |
С(1,Е,3) |
3 |
Е |
П(7) |
П(8) |
Е |
П(9) |
Е |
П(10) |
Е |
4 |
Е |
Е |
Е |
С(1,F,5) |
Е |
Е |
Е |
С(1,F,5) |
5 |
Е |
П(6) |
П(2) |
Е |
П(3) |
Е |
П(4) |
Е |
6 |
Е |
Е |
Е |
Е |
Е |
Е |
Е |
С(3,Е,2) |
7 |
Е |
Е |
Е |
Е |
Е |
П(11) |
Е |
Е |
8 |
Е |
Е |
Е |
П(12) |
Е |
С(1,Е,3) |
Е |
Е |
9 |
Е |
П(13) |
П(8) |
Е |
П(9) |
Е |
П(10) |
Е |
10 |
Е |
Е |
Е |
С(1,F,5) |
Е |
С(1,F,5) |
Е |
Е |
11 |
Е |
Е |
Е |
С(3,F,4) |
Е |
Е |
Е |
С(3,F,4) |

12 |
Е |
П(15) |
П(8) |
Е |
П(9) |
Е |
П(10) |
Е |
13 |
Е |
Е |
Е |
Е |
Е |
П(14) |
Е |
Е |
14 |
Е |
Е |
Е |
С(3,F,4) |
Е |
С(3,F,4) |
Е |
Е |
15 |
Е |
Е |
Е |
Е |
Е |
С(3,Е,2) |
Е |
Е |
Как видно из примера, число состояний значительно увеличилось, более того, число элементов в каждой ситуации тоже больше, чем для LR(0) грамматики. Посмотрим, как происходит разбор строки (i)+i:
Входная строка |
Состояние |
Текущий символ |
Стек символов |
Стек состояний |
Разбор |
(i)+i# |
0 |
( |
# |
0 |
|
i)+i# |
3 |
i |
#( |
0 3 |
|
)+i# |
10 |
) |
#(i |
0 3 10 |
|
)+i# |
3 |
F |
#( |
0 3 |
5 |
)+i# |
8 |
) |
#(F |
0 3 8 |
5 |
)+i# |
3 |
E |
#( |
0 3 |
5 3 |
)+i# |
7 |
) |
#(E |
0 3 7 |
5 3 |
+i# |
11 |
+ |
#(E) |
0 3 7 11 |
5 3 |
+i# |
0 |
F |
# |
0 |
5 3 4 |
+i# |
2 |
+ |
#F |
0 2 |
5 3 4 |
i# |
5 |
i |
#F+ |
0 2 5 |
5 3 4 |
# |
4 |
# |
#F+i |
0 2 5 4 |
5 3 4 |
# |
5 |
F |
#F+ |
0 2 5 |
5 3 4 5 |
# |
2 |
# |
#F+F |
0 2 5 2 |
5 3 4 5 |
# |
5 |
E |
#F+ |
0 2 5 |
5 3 4 5 3 |
# |
6 |
# |
#F+E |
0 2 5 6 |
5 3 4 5 3 |
# |
0 |
E |
# |
0 |
5 3 4 5 3 2 |
# |
1 |
# |
#E |
0 1 |
5 3 4 5 3 2 |
# |
0 |
S |
# |
0 |
5 3 4 5 3 2 1 |
Конфликт при построении LR(0) распознавателя в одной-единственной ячейке привел к необходимости построения LR(1) грамматики, для которой и ситуации строятся значительно сложнее и число состояний значительно возрастает. Поиск методов упрощения построения распознавателей при подобных конфликтах привел к появлению SLR(1) (от simple - простая) и LALR(1) (от look ahead – заглядывание вперед) грамматик. Если проанализировать конфликтную позицию (2,+) {С(1,Е,3), П(5)} таблицы LR(0) распознавателя, то видно, что свертка должна производиться только при последующем символе #, т.е. конфликт разрешается в пользу переноса. Грамматики, для которых подобный анализ позволяет устранить конфликты, относятся к классу SLR(1) грамматик. LALR(1) грамматики используют более сложный анализ контекста.
Формально ситуации для SLR(1) грамматик строятся так же, как и для LR(0) грамматик, но управляющая таблица заполняется иначе:
Управляющая таблица U = {uij } строится на основе последовательности ситуаций.
1. |
Для каждой ситуации Ri создается строка таблицы i. |
2. |
Для каждой ситуации Ri выполняется следующее: |
- |
r Ri : A→γ•, γ V* , A N, k – номер правила A→γ uij = П(|γ|, A, k), для всех j F(A), где F(A) – множество симво- |
|
лов-последователей (этот пункт можно оставить таким же, как и для грамматики LR(0), а изменения принимать во вни- |
|
мание только для конфликтных строк) |
- |
r Ri : A→γ•xβ, γ,β V* , x V, A N, Ri→x Rj uix = С(j) |
3. u0S = Конец |
|
4. |
Во все оставшиеся пустыми ячейки таблицы заносится Ошибка. |
Если таблицу удалось заполнить непротиворечивым образом, то рассматриваемая грамматика является SLR(1) грамматикой. Перед началом работы распознаватель устанавливается в состояние 0, головка чтения – на первый символ входной строки, который принимается в качестве текущего. Стек символов содержит #, стек состояний 0. Дальнейшее функционирование происходит на основе таблицы. Пример:
Пример. Возьмем имеющуюся конфликтную последовательность ситуаций. Сначала построим множество символов – последователей для каждого из нетерминалов: F(S)={#}; F(E)={),#}; F(F)={+,),#}.
Заполним управляющую таблицу:
Ситуация |
S |
E |
F |
+ |
( |
) |
i |
# |
0 |
Конец |
П(1) |
П(2) |
Е |
П(3) |
Е |
П(4) |
Е |
1 |
Е |
Е |
Е |
Е |
Е |
Е |
Е |
С(1,S,1) |
2 |
Е |
Е |
Е |
П(5) |
Е |
С(1,Е,3) |
Е |
С(1,Е,3) |
3 |
Е |
П(6) |
П(2) |
Е |
П(3) |
Е |
П(4) |
Е |
4 |
Е |
Е |
Е |
С(1,F,5) |
Е |
С(1,F,5) |
Е |
С(1,F,5) |
5 |
Е |
П(7) |
П(2) |
Е |
П(3) |
Е |
П(4) |
Е |
6 |
Е |
Е |
Е |
Е |
Е |
П(8) |
Е |
Е |
7 |
Е |
Е |
Е |
Е |
Е |
С(3,Е,2) |
Е |
С(3,Е,2) |
8 |
Е |
Е |
Е |
С(3,F,4) |
Е |
С(3,F,4) |
Е |
С(3,F,4) |
Входная строка |
Состояние |
Текущий символ |
Стек символов |
Стек состояний |
Разбор |
(i)+i# |
0 |
( |
# |
0 |
|
i)+i# |
3 |
i |
#( |
0 3 |
|
)+i# |
4 |
) |
#(i |
0 3 4 |
|
)+i# |
3 |
F |
#( |
0 3 |
5 |
)+i# |
2 |
) |
#(F |
0 3 2 |
5 |
)+i# |
3 |
E |
#( |
0 3 |
5 3 |
)+i# |
6 |
) |
#(E |
0 3 6 |
5 3 |
+i# |
8 |
+ |
#(E) |
0 3 6 8 |
5 3 |
+i# |
0 |
F |
# |
0 |
5 3 4 |
+i# |
2 |
+ |
#F |
0 2 |
5 3 4 |
i# |
5 |
i |
#F+ |
0 2 5 |
5 3 4 |
# |
4 |
# |
#F+i |
0 2 5 4 |
5 3 4 |
# |
5 |
F |
#F+ |
0 2 5 |
5 3 4 5 |
# |
2 |
# |
#F+F |
0 2 5 2 |
5 3 4 5 |
# |
5 |
E |
#F+ |
0 2 5 |
5 3 4 5 3 |
# |
7 |
# |
#F+E |
0 2 5 7 |
5 3 4 5 3 |
# |
0 |
E |
# |
0 |
5 3 4 5 3 2 |
# |
1 |
# |
#E |
0 1 |
5 3 4 5 3 2 |
# |
0 |
S |
# |
0 |
5 3 4 5 3 2 1 |
Как видим, разбор строки идентичен распознавателю LR(1) с точностью до номера состояния.
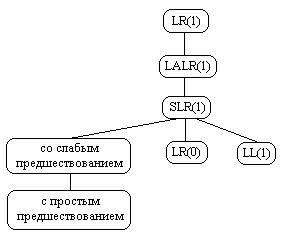
Рассмотрим иерархию КС-грамматик:
Чем уже класс грамматик, тем более простой распознаватель будем иметь на выходе, и тем проще его синтез. С другой стороны, приведение грамматики к более узкому классу требует больших усилий. Иногда, если часть правил не описывается выбранным классом грамматик, они анализируются отдельно, по дополнительному алгоритму.
Любая SLR(1) грамматика является LR(1) грамматикой, но не
наоборот. Класс языков, задаваемый SLR(1) грамматикой уже, чем
для LR(1), а это значит, что не всякий детерминированный КСязык может быть задан SLR(1) грамматикой.
Любая SLR(1) грамматика является LALR(1) грамматикой, но не наоборот. Любой детерминированный КС-язык может быть задан LALR(1) грамматикой. Это значит, что классы языков, задаваемых LALR(1) и LR(1) грамматиками, совпадают, однако не всякая LR(1) грамматика является LALR(1) грамматикой.
С другой стороны, как правило, чем уже класс грамматик в этой иерархии, тем меньше возможностей по диагностированию
ошибок он предоставляет, при этом снижается точность локализации и классификации ошибок.
Автоматизация построения синтаксических анализаторов решается с помощью различных пакетов, например YACC (Yet Another Compiler Compiler). Язык описывается в форме, близкой к форме Бэкуса-Наура, результатом является текст программы синтаксического анализатора. YACC реализует восходящий распознаватель на основе LALR(1) грамматики.