Шпоры / Шпоры готовые
.doc
1 поколение (70-е годы): СУБД, поддерживающие сетевую или иерархическую модель и рассчитанные на большие ЭВМ (mainframe). Типичными представителями первого поколения являются СУБД, основанные на предложениях CODASIL [Олле 81] и IMS [Дейт 80]. Для СУБД 1-го поколения характерны закрытость и централизованная архитектура. 2 поколение (80-е годы): СУБД, основанные на реляционной модели. Для них характерны непроцедурный язык запросов (SQL) и значительная степень независимости данных. Плохо приспособлены для следующих классов приложений: САПР, CASE, гипертекстовые приложения. Большая часть коммерческих СУБД 2-го поколения приобретает некоторые черты, с которыми связывается понятие третьего поколения СУБД. СУБД третьего поколения: Помимо традиционных услуг по управлению данными, СУБД третьего поколения обеспечат поддержку более богатых структур объектов и правил, включает в себя СУБД второго поколения, открыты для других подсистем.
|
1 поколение (70-е годы): СУБД, поддерживающие сетевую или иерархическую модель и рассчитанные на большие ЭВМ (mainframe). Типичными представителями первого поколения являются СУБД, основанные на предложениях CODASIL [Олле 81] и IMS [Дейт 80]. Для СУБД 1-го поколения характерны закрытость и централизованная архитектура. Иерархические системы Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много баз данных, что создает существенные проблемы с переходом как на новую технологию БД, так и на новую технику. Иерархические структуры данных Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. Тип дерева состоит из одного "корневого" типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи. Пример типа дерева (схемы иерархической БД):
Здесь Отдел является предком для Начальник и Сотрудники, а Начальник и Сотрудники - потомки Отдел. Между типами записи поддерживаются связи. Сетевые структуры данных Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков. Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи. Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
Простой пример сетевой схемы БД:
|


2 поколение (80-е годы): СУБД, основанные на реляционной модели. Для них характерны непроцедурный язык запросов (SQL) и значительная степень независимости данных. Плохо приспособлены для следующих классов приложений: САПР, CASE, гипертекстовые приложения. Большая часть коммерческих СУБД 2-го поколения приобретает некоторые черты, с которыми связывается понятие третьего поколения СУБД. Базовые понятия реляционных баз данных Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение. Для начала покажем смысл этих понятий на примере отношения СОТРУДНИКИ, содержащего информацию о сотрудниках некоторой организации:
|
Принцип 1 Помимо традиционных услуг по управлению данными, СУБД третьего поколения обеспечат поддержку более богатых структур объектов и правил, Принцип 2 включает в себя СУБД второго поколения, Принцип 3 должны быть открыты для других подсистем. 1. Предложения, касающиеся управления объектами и правилами Предложение 1.1: Система типов СУБД третьего поколения должна быть богатой и разнообразной. Предложение 1.2: Наследование - хорошая идея. Предложение 1.3: Функции, в том числе процедуры и методы баз данных, и инкапсуляция - хорошие идеи. Предложение 1.4: Уникальные идентификаторы (UID) записей должны задаваться СУБД только в том случае, когда недоступен определенный пользователем первичный ключ. Предложение 1.5: Правила (триггеры, ограничения) станут одной из ключевых характеристик будущих систем. Их не следует ассоциировать с определенными функциями или наборами. 2. Предложения, касающиеся увеличения функциональных возможностей СУБД Предложение 2.1: Все программируемые доступы к базам данных должны осуществляться через непроцедурный язык доступа высокого уровня. Предложение 2.2: Должно быть по крайней мере два способа спецификации наборов: посредством перечисления членов и путем использования языка запросов для задания членов. Предложение 2.3: Существенно наличие обновляемых представлений. Предложение 2.4: Показатели производительности не имеют почти ничего общего с моделями данных и не должны в них проявляться. 3. Предложения, следующие из необходимости открытости системы Предложение 3.1: СУБД третьего поколения должны быть доступны из различных ЯВУ. Предложение 3.2: Язык "X с поддержкой стабильных данных" (для различных X) - хорошая идея. Языки будут поддерживаться над единой СУБД благодаря расширениям компилятора и (более или менее) сложной системе времени выполнения. Предложение 3.3: Хорошо это или плохо, но SQL становится интергалактическим языком данных. Предложение 3.4: Запросы и ответы на них должны образовывать нижний уровень коммуникаций между клиентом и сервером.
|

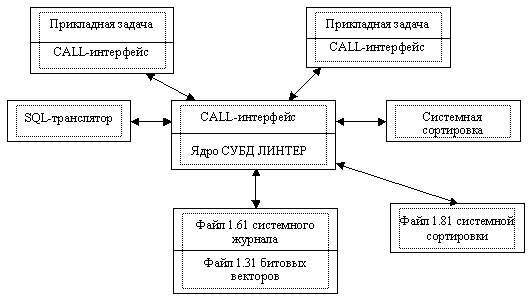
СУБД ЛИНТЕР - это комплекс задач, работающих под управлением операционной системы. Структура программного обеспечения СУБД ЛИНТЕР приведена на рис. 1. Часть задач являются собственно системой управления базой данных, другие представляют собой утилиты и инструментальные средства для поддержки жизненного цикла базы данных (БД) (управление БД, архивирование и восстановление, тестирование и др.). Центральной частью системы являются средства ведения БД (обработки запросов).
|
Главное требование к интерфейсу СУБД – он должен быть удобным и интуитивно понятным для пользователя (за счёт чего, отчасти, и достигается комфортная работа). Во первых пользователю должно быть предложено иерархически построенное меню. С его помощью выбирается требуемая функция системы. Для ввода данных, их просмотра и редактирования в базе данных чаще всего используются два способа их представления - табличный и в виде экранных форм. Экранные формы применяют в случаях, когда длина записи данных превышает размер строки дисплея или когда удобнее работать с привычной формой документа. Должно быть предусмотрено выполнение некоторого набора типовых процедур. Обеспечивается, в частности, ввод записей в базу данных с верификацией их по заданным простым ограничениям целостности, например, по диапазону изменения значений числового поля формы или по шаблону значения строкового поля. Кроме того, должны быть возможны просмотр, редактирование и удаление записей, а также поиск записей по задаваемому через экранную форму критерию. При этом пользователь задает значения поисковых полей формы, имея в виду, что в результате поиска должны быть найдены и показаны все записи, имеющие такие же значения всех поисковых полей. К числу типовых процедур приложения относится также вывод отчета по любой форме, известной системе, на экран дисплея или на принтер. Дружественный характер СУБД для ПЭВМ хорошо сочетается с главной направленностью технологии персональных ЭВМ на обеспечение комфортных условий работы пользователей. Благодаря этому достигается существенно более высокая производительность труда пользователя при создании и эксплуатации "персональных" баз данных, чем при выполнении подобных работ на "больших" ЭВМ со свойственными их социальной пользовательской среде значительными накладными расходами и более низкой надежностью. В подавляющем большинстве СУБД для ПЭВМ предусматривается интерактивный режим работы пользователей. При этом широко используются интерфейсы в стиле меню с указанием для пользователя альтернативных вариантов выбора возможных действий и способов их инициирования, с отображением текущего состояния системы БД и диагностикой ошибок. |
Ядро СУБД ЛИНТЕР - это реентерабельная программа, осуществляющая диспетчеризацию и параллельную обработку запросов. При получении запроса ядро производит анализ ресурсов. Если их достаточно, то запрос принимается на выполнение, в противном случае приложению посылается соответствующий код возврата, и приложение реагирует на него в соответствии с заложенным алгоритмом. Среди запросов, принятых ядром, особую группу занимают так называемые служебные запросы. Примеры таких запросов:
Эти служебные запросы имеют следующие особенности: их обработка непрерываема, они выполняется только модулями ядра СУБД ЛИНТЕР без участия других средств ведения БД. Таким образом, два служебных запроса, посланных по разным каналам, ядро будет выполнять последовательно, не прерываясь на обработку других запросов.
Архитектура "клиент-сервер" обеспечивает простое и относительно дешевое решение проблемы коллективного доступа к базам данных в локальной сети. Термин "сервер баз данных" обычно используют для обозначения всей СУБД, основанной на архитектуре "клиент-сервер", включая и серверную, и клиентскую части. Такие системы предназначены для хранения и обеспечения доступа к базам данных. Принципы взаимодействия между клиентскими и серверными частями Доступ к базе данных от прикладной программы или пользователя производится путем обращения к клиентской части системы. В качестве основного интерфейса между клиентской и серверной частями выступает язык баз данных SQL. Типичное разделение функций между клиентами и серверами В типичном на сегодняшний день случае на стороне клиента СУБД работает только такое программное обеспечение, которое не имеет непосредственного доступа к базам данных, а обращается для этого к серверу с использованием языка SQL. Сегментация БД, выборка по связям, обработка сообщений. |
Непосредственное управление данными во внешней памяти Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы). В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти.
|
Администратор базы данных (АБД) - под этим понятием подразумевается лицо (или группа лиц, возможно, целое штатное подразделение), на которое возложено управление средствами базы данных организации. Функции администратора заключаются в следующем:
|
Различается:
Методы: организационный, технический, программный(вход по пользователю, защита по таблице, защита по записи, инкопсуляция) Защита базы данных (БД) означает защиту самих данных и их контролируемое использование на рабочих ЭВМ сети, а также защиту любой сопутствующей информации, которая может быть извлечена из этих данных или получена путем перекрестных ссылок. Когда рассматриваются процедуры защиты сетевых БД, то данные и их логические структуры представляются двумя различными способами. Отдельные объекты данных могут быть сами объектами защиты, но могут быть организованы в структуры БД (сегменты, отношения, каталоги и т. д.). Защита таких структур рассматривается в основном при анализе механизмов контроля доступа. |
Для более полной защиты необходимо ввести следующие уровни: а) Регистрация и аутентификация пользователей, ведение системного журнала. Идентификацию и аутентификацию пользователей можно проводить следующими способами:
В системном журнале регистрируются любые попытки входа в систему и все действия оператора в системе. б) Определение прав доступа к информации БД для конкретного пользователя (авторизация пользователя) при обращении к СУБД. Все действия пользователя протоколируются в системном журнале. Определение полномочий пользователя при доступе к БД происходит на основе анализа специальной информации - списка пользователей с правами доступа, которая формируется администратором БД, исходя из принципа минимальных полномочий для каждого пользователя. Это второй этап процедуры авторизации пользователя. На этом уровне происходит конфигурация БД под полномочия конкретном пользователя. Пользователю предоставляется в виде как бы отдельной базы та часть БД, доступ к которой ему разрешен администратором. Все обращения вне этой части должны блокироваться системой. В этом случае пользователь работает с виртуальной "личной" БД. в) Непосредственный доступ к БД. На этом уровне для повышения защищенности системы в целом целесообразно использовать зашифрование/расшифрование отдельных объектов БД. Ключи для шифрования можно определять исходя из идентификатора пользователя и его полномочий, то есть "паспорта"пользователя. В качестве примера можно привести алгоритм, реализованный на кафедре" Защита информации в АСУ и сетях ЭВМ " Московского инженерно-физическом института. При создании базы данных вводится дополнительное поле, в котором записывается уровень конфиденциальности данной записи. Информация БД шифруется и хранится на диске в зашифрованном виде. В каталоге СУБД создается БД, представляющая из себя регистрационную книгу, где содержится следующая информация: имя или код пользователя, пароль, уровень доступа. Данный файл и управляющая *.prg-программа также шифруются. Создается и запускается управляющий *.bat-файл.
|
Предметная область может относиться к любому типу организации (например, банк, университет, больница или завод). Типы предметных областей:
Исходя из этого можно сделать вывод о том, что для базы данных размеров в сотни и тысячи записей можно воспользоваться например СУБД Fox Pro; в случает с сотнями тысяч записей подойдёт СУБД Oracle. |
Под банком данных понимается совокупность базы данных (БД), прикладных программ (ПП), пользователей банка данных, СУБД и словарей-справочников. Структура автоматизированного банка данных представлена на рисунке:
Данные в таких системах формируются в специально организованные базы данных. Таким образом, понятие базы данных было сформулировано только в недавние годы. База данных может быть определена как совокупность предназначенных для машинной обработки данных, которая служит для удовлетворения нужд многих пользователей в рамках одной или нескольких организаций. Ключевым моментом является то, что база данных, будучи интегрированным средством, предназначена для использования всеми членами организации, которым необходима информация, содержащаяся в базе данных. Информация уже не скрыта в сочетании "файл программа", она хранится явным образом в базе данных, которая может включать много различных типов логических записей. База данных ориентирована на интегрированные требования, а не на одну программу, как было с частными файлами данных. Переход от структуры БД к требуемой структуре в программе пользователя осуществляется автоматически с помощью СУБД. Средствами автоматизации формирования и использования точной и полной информации являются словари данных (системы словарей справочников данных). Словарь данных обычно организуется в виде нескольких физических баз данных с логическими связями между ними. Особенно важен словарь данных при взаимодействии нескольких систем обработки данных, при построении распределенных банков данных, при заимствовании программ, выполненных в других организациях. В последнем случае словарные статьи извлекают из написанных программ, устанавливают синонимические связи их со статьями словаря системы и переводят их в формат, принятый в системе.
|
Базой данных называется специальным образом организованная совокупность данных, которые:
Таблица есть мультимножество (неупорядоченный набор объектов, которые не обязательно различны) строк. Строка есть непустая последовательность (упорядоченный набор объектов, которые не обязательно различны) значений. Все строки одной таблицы обладают одинаковой мощностью (мощность набора есть число объектов в этом наборе) и содержат значения каждого столбца этой таблицы. I-ое значение каждой строки таблицы является значением i-ого столбца этой таблицы. Строка является минимальным элементом данных, которые можно занести в таблицу и удалить из таблицы. Степень таблицы есть число столбцов этой таблицы. В любой момент времени степень таблицы та же, что и мощность каждой из ее строк, и мощность таблицы та же, что и мощность каждого из ее столбцов. Таблица имеет описание. Это описание включает описание каждого из столбцов таблицы. Базовая таблица есть именованная таблица, определенная через <определение таблицы> (<table definition>). Описание базовой таблицы включает ее имя. Порожденная таблица - это таблица, порожденная прямо или косвенно из одной или нескольких других таблиц путем вычисления <спецификации запроса> (<query specification>). Значениями порожденной таблицы являются значения определяющих таблиц при ее порождении. Представляемая таблица есть именованная таблица, определенная через <определение представления> (<view definition>). Описание представляемой таблицы включает ее имя. Таблица является либо изменяемой (updatable), либо только читаемой. Операции занесения, модификации и удаления допускаются для изменяемых таблиц и не допускаются для только читаемых таблиц. Сгруппированная таблица есть множество групп, порождаемых в ходе вычисления <раздела group by> (<group by clause>). Группа - это мульти-множество строк, в которых все значения столбца (столбцов) группирования равны. Сгруппированную таблицу можно рассматривать как набор таблиц. Множественные функции могут применяться к индивидуальным кортежам внутри сгруппированной таблицы. Формы используются для просмотра, ввода и редактирования данных, хранящихся в таблицах, и являются наиболее наглядным средством представления информации. Также они позволяют работать не с одной, а с несколькими связанными таблицами, что, в свою очередь, также увеличивает наглядность. |
Отчет представляет собой форматированное представление данных, выводимое на экран, принтер или в файл. Он может быть представлен в табличном виде или в свободной форме. Табличный отчет - это напечатанная таблица, в которой строка представляет собой запись, а каждый из элементов строки содержит поле исходной таблицы или вычисляемое поле. Данные в таблице упорядочены. Табличные отчеты используются для печати данных, представленных в виде списка. При подготовке писем, почтовых этикеток поля используемых в отчете таблиц должны располагаться в специально выделенных для них местах. В этом случае табличный отчет не подходит и используются отчеты в свободной форме. Запросы являются средством выборки данных из одной или нескольких таблиц, с возможностью её упорядочивания. |
Модуль (<module>) есть долговременно хранимый объект, определенный на языке модулей. <Модуль> (<module>) состоит из необязательного <имя модуля> (<module name>), <раздела языка> (<language clause>), <раздела полномочий модуля> (<module authorization clause>), ноля или более курсоров, определенных через <объявление курсора> (<declare cursor>) и одной или более <процедур> (<procedure>). Прикладная программа есть сегмент выполняемого кода, содержащий, возможно, несколько подпрограмм. Единственный <модуль> (<module>) ассоциируется с прикладной программой в течение ее выполнения. Прикладная программа должна быть ассоциирована с самое большее одним <модулем> (<module>). Способ установления этой ассоциации, включающий возможное требование выполнения некоторого определенного в реализации оператора, определяется в реализации. Макросы клавиатуры представляют собой средства для ускорения набора повторяющегося текста, ускоряя тем самым разработку приложений. Макроподстановки и аналогичные функции обеспечивают требуемую гибкость в программировании среды. Макросы клавиатуры выполняют функции, аналогичные функциям макросов в других средах, облегчая работу и разработчиков, и пользователей:
|
|
Двумя фундаментальными языками запросов к реляционным БД являются языки реляционной алгебры и реляционного исчисления. Запросы бывают двух видов: на выборку и на просмотр(view). Select - Семантика табличного выражения состоит в том, что на основе последовательного применения разделов from, where, group by и having из заданных в разделе from таблиц строится некоторая новая результирующая таблица, порядок следования строк которой не определен и среди строк которой могут находиться дубликаты (т.е. в общем случае таблица-результат табличного выражения является мультимножеством строк). Механизм представлений (view) является мощным средством языка SQL, позволяющим скрыть реальную структуру БД от некоторых пользователей за счет определения представления БД, которое реально является некоторым хранимым в БД запросом с именованными столбцами, а для пользователя ничем не отличается от базовой таблицы БД (с учетом технических ограничений). Любая реализация должна гарантировать, что состояние представляемой таблицы точно соответствует состоянию базовых таблиц, на которых определено представление. Обычно вычисление представляемой таблицы (материализация соответствующего запроса) производится каждый раз при использовании представления. |
Язык для взаимодействия с БД SQL появился в середине 70-х и был разработан в рамках проекта экспериментальной реляционной СУБД System R. Исходное название языка SEQUEL (Structered English Query Language) только частично отражает суть этого языка. Конечно, язык был ориентирован главным образом на удобную и понятную пользователям формулировку запросов к реляционной БД, но на самом деле уже являлся полным языком БД, содержащим помимо операторов формулирования запросов и манипулирования БД средства определения и манипулирования схемой БД; определения ограничений целостности и триггеров; представлений БД; возможности определения структур физического уровня, поддерживающих эффективное выполнение запросов; авторизации доступа к отношениям и их полям; точек сохранения транзакции и откатов. В языке отсутствовали средства синхронизации доступа к объектам БД со стороны параллельно выполняемых транзакций: с самого начала предполагалось, что необходимую синхронизацию неявно выполняет СУБД. |
Visual FoxPro является постоянно развивающейся системой. По сравнению с предыдущей версией, в Visual FoxPro 7.0 сделан еще один шаг в расширении функциональных возможностей системы, улучшены имеющиеся средства, касающиеся интерфейса среды разработки. Макс. размер символьного поля: 254 Макс. размер числового поля: 20 Макс кол-во записей в файле: 1млрд Макс. кол-во пользователей(одновременно открытых таблиц): 255 В базе данных, созданной в Visual FoxPro, вы можете использовать события, связанные с базой данных, такие как открытие таблицы, добавление или удаление таблицы для проверки прав доступа при открытии таблицы, трассировки выполняемых действий и т. п. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|