

2.2. Решающие деревья
Решающее дерево (decision tree, DT) — это логический алгоритм классификации, основанный на поиске конъюнктивных закономерностей.
Напомним некоторые понятия теории графов.
Деревом
называется
конечный связный граф с множеством
вершин V,
не
содержащий
циклов и имеющий выделенную вершину
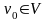 ,
в
которую не входит ни
одно ребро. Эта вершина называется
корнем
дерева.
Вершина, не имеющая выходящих
рёбер, называется терминальной
или
листом.
Остальные
вершины называются
внутренними.
,
в
которую не входит ни
одно ребро. Эта вершина называется
корнем
дерева.
Вершина, не имеющая выходящих
рёбер, называется терминальной
или
листом.
Остальные
вершины называются
внутренними.
Дерево называется бинарным, если из любой его внутренней вершины выходит ровно два ребра. Выходящие рёбра связывают внутреннюю вершину v с левой дочерней вершиной Lv и с правой дочерней вершиной Rv.
Опр.
Бинарное
решающее дерево —
это алгоритм
классификации, задающийся бинарным
деревом, в котором каждой внутренней
вершине
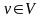 приписан
предикат
приписан
предикат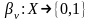 ,
каждой
терминальной вершине
приписано
имя класса cv
Y.
Правило
классификации определяется следующим
образом:
,
каждой
терминальной вершине
приписано
имя класса cv
Y.
Правило
классификации определяется следующим
образом:
Алгоритм :Классификация объекта х X бинарным решающим деревом
1: v:=v0;
2: пока вершина v внутренняя
3:
если
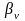 (x)
то
(x)
то
4: v := Rv;
5: иначе
6: v := Lv-
7: вернуть cv.
2.3. Редукция решающих деревьев
Суть редукции состоит в удалении поддеревьев, имеющих недостаточную статистическую надёжность. При этом дерево перестаёт безошибочно классифицировать обучающую выборку, зато качество классификации новых объектов (способность к обобщению), как правило, улучшается.
Придумано огромное количество эвристик для проведения редукции , однако ни одна из них, вообще говоря, не гарантирует улучшения качества классификации.
Предредукция
(pre-pruning)
или
критерий раннего
останова досрочно
прекращает
дальнейшее ветвление в вершине дерева,
если информативность I(β,
S)
для
всех
предикатов
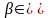 Β
не дотягивает до заданного порогового
значения I0.
Β
не дотягивает до заданного порогового
значения I0.
Предредукция не является эффективным методом избежания переобучения, так как жадное ветвление по-прежнему остаётся глобально неоптимальным. Более эффективной считается стратегия постредукции.
Постредукция (post-pruning) просматривает все внутренние вершины дерева и заменяет отдельные вершины либо одной из дочерних вершин (при этом вторая дочерняя удаляется), либо терминальной вершиной. Процесс замен продолжается до тех пор, пока в дереве остаются вершины, удовлетворяющие критерию замены.
Критерием замены является сокращение числа ошибок на контрольной выборке, отобранной заранее и не участвовавшей в обучении дерева. Рекомендуется оставлять в контроле около 30% объектов. Наиболее экономичной реализацией постредукции является просмотр дерева методом поиска в глубину, при котором в каждой вершине дерева сохраняется информация о подмножестве контрольных объектов, попавших в данную вершину при классификации.
3. Описание алгоритмов построения деревьев решений
3.1. Алгоритм id3
Идея алгоритма заключается в последовательном дроблении выборки на две части до тех пор, пока в каждой части не окажутся объекты только одного класса. Проще всего записать этот алгоритм в виде рекурсивной процедуры LearnID3, которая строит дерево по заданной подвыборке S. Для построения полного дерева она применяется ко всей выборке и возвращает указатель на корень построенного дерева:
v0 := LearnID3 (Xl).
На шаге 6 алгоритма выбирается предикат β, задающий максимально информативное ветвление дерева — разбиение выборки на две части S = s0 U S1. На практике применяются различные критерии ветвления.
1. Критерий, ориентированный на скорейшее отделение одного из классов.
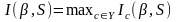
2. Критерий, ориентированный на задачи с большим числом классов. Фактически, это обобщение статистического определения информативности.
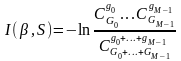 ,где
,где
Gc-число объектов класса с в выборке S, из них gc объектов покрываются правилом β.
3. D-критерий — число пар объектов из разных классов, на которых предикат β принимает разные значения. В случае двух классов он имеет вид
I(β,S)=g(β)(B-b(β))+b(β)(G-g(β)).
Трудоёмкость алгоритма ID3 составляет O(|B|Vol), где v0 — число внутренних вершин дерева.
Алгоритм :Рекурсивный алгоритм построения решающего дерева ID3 Вход:
S — обучающая выборка;
В — множество базовых предикатов;
Выход:
Возвращает корневую вершину дерева, построенного по выборке S;
1: ПРОЦЕДУРА LearnID3 (S);
2: если все объекты из S лежат в одном классе с Y то
3: создать новый лист v;
4: cv:=c;
5: вернуть (v);
6: найти предикат с максимальной информативностью:
β:=
arg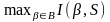 ;
;
7:
разбить выборку на две части S
=
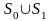 по
предикату β:
по
предикату β:

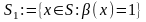
8:
если
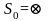 или
или
 то
то
9: создать новый лист v;
10:cv := класс, в котором находится большинство объектов из S;
11: вернуть (v);
12: иначе
13: создать новую внутреннюю вершину v;
14: βv:= β;
15: Lv := LearnID3 (So); (построить левое поддерево)
16: Rv := LearnID3 (S1); (построить правое поддерево)
17: вернуть (v);
Преимущества алгоритма ID3
-Простота и интерпретируемость классификации. Алгоритм способен не только классифицировать объект, но и выдать объяснение классификации в терминах предметной области. Для этого достаточно записать последователь ность условий, пройденных объектом от корня дерева до листа.
-Алгоритм синтеза решающего дерева имеет сложность, линейную по длине выборки.
-Если множество предикатов В настолько богато, что на шаге 6 всегда находится предикат, разбивающий выборку S на непустые подмножества s0 и S1,то алгоритм строит бинарное решающее дерево, безошибочно классифицирую щее выборку Xl.
-Алгоритм очень прост для реализации и легко поддаётся различным усовершенствованиям. Можно использовать различные критерии ветвления и критерии останова, вводить редукцию, и т. д.
Недостатки алгоритма ID3
-Жадность. Локально оптимальный выбор предиката βV не является глобально оптимальным. В случае выбора неоптимального предиката алгоритм не спосо бен вернуться на уровень вверх и заменить неудачный предикат.
-Чем дальше вершина v расположена от корня дерева, тем меньше длина подвыборки S, по которой приходится принимать решение о ветвлении в вершине v. Тем менее статистически надёжным является выбор предиката βV.
-Алгоритм склонен к переобучению — как правило, он переусложняет структуру дерева. Обобщающая способность алгоритма (качество классификации новыхобъектов) относительно невысока.
Основная причина недостатков — неоптимальность жадной стратегии наращивания дерева. Перечисленные недостатки в большей или меньшей степени свойственны большинству алгоритмов синтеза решающих деревьев. Для их устранения применяют различные эвристические приемы: редукцию, элементы глобальной оптимизации, «заглядывание вперёд» (look ahead).