

2. Подбор объясняющих переменных для множественной линейной модели
Имеется множественная линейная эконометрическая модель, спецификация которой представлена в виде:
yt= a1∙xt1 + a2∙xt2 + a3∙xt3 + … + am∙xtm + ut , (2.1)
t = 1, …, n,
где
m – число параметров модели;
n – объем выборки;
yt – объясняемая переменная в наблюдении t;
xtm – объясняющие переменные в наблюдении t;
ut – случайное возмущение в наблюдении t;
Матричная форма спецификации модели имеет вид:
Y = A∙X + U, (2.2)
где
Y = (y1, y2, y3, …, yn)T – вектор-столбец значений объясняемой (эндогенной) переменной;
 -
детерминированная матрица объясняющих
переменных;
-
детерминированная матрица объясняющих
переменных;
A = (a1, a2, a3, …, am)T - вектор столбец параметров модели;
U = (u1, u2, u3, …, um)T – вектор-столбец случайных возмущений.
С формальной точки зрения, объясняющие переменные в линейной эконометрической модели должны обладать следующими свойствами:
• иметь высокую вариабельность;
• быть сильно коррелированными с объясняемой переменной;
• быть слабо коррелированными между собой;
• быть сильно коррелированными с представляемыми ими другими переменными, не используемыми в качестве объясняющих.
Объясняющие переменные подбираются с помощью статистических методов. Процедура подбора переменных состоит из следующих этапов:
1. На основе накопленных знаний составляется множество так называемых потенциальных объясняющих переменных (первичных переменных), в которое включаются все важнейшие величины, влияющие на объясняемую переменную, т.е. переменные x1, x2, ..., xт.
2. Собирается статистическая информация о реализациях, как объясняемой переменной, так и потенциальных объясняющих переменных.
3. Формируется вектор Y наблюдаемых значений переменной y и матрица X наблюдаемых значений переменных x1, x2, ..., xт в виде, как представлено в пояснении к формуле 2.2.
4. Исключаются потенциальные объясняющие переменные, характеризующиеся слишком низким уровнем вариабельности.
5. Рассчитываются коэффициенты корреляции между всеми рассматриваемыми переменными.
6. Множество потенциальных объясняющих переменных редуцируется с помощью выбранной статистической процедуры.
Метод «Исключение квазинеизменных переменных»
Предварительным условием присвоения различным величинам статуса объясняющих переменных считается достаточно высокая их вариабельность. В качестве меры вариабельности используется коэффициент вариации
![]()
(2.3)
где
![]()
![]() — среднее
арифметическое переменной Xi,
рассчитываемое по формуле:
— среднее
арифметическое переменной Xi,
рассчитываемое по формуле:
(2.4)
т![]() огда
как Si
— стандартное
отклонение переменной Xi,
рассчитываемое по формуле:
огда
как Si
— стандартное
отклонение переменной Xi,
рассчитываемое по формуле:
(2.5)
Задается критическое значение коэффициента вариации v*3, и тогда, переменные, удовлетворяющие неравенству
vi <v* (2.6)
признаются квазинеизменными и исключаются из множества потенциальных объясняющих переменных, так как не несут значимой информации.
Метод анализа вектора и матрицы коэффициентов корреляции
Идея данного метода сводится к выбору таких объясняющих переменных, которые сильно коррелируют с объясняемой переменной и, одновременно, слабо коррелируют между собой. В качестве исходных данных рассматриваются значения коэффициентов корреляции вектора R0, рассчитанные по формуле (1.14), и значения коэффициентов корреляции матрицы R, рассчитанные по формуле (1.16).
В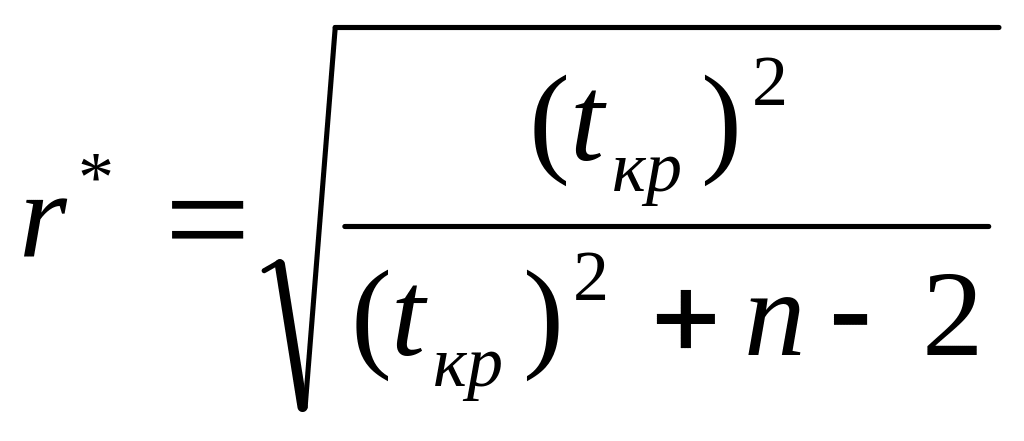 начале
рассчитывается, так называемое,
критическое значение коэффициента
корреляции r*
по формуле:
начале
рассчитывается, так называемое,
критическое значение коэффициента
корреляции r*
по формуле:
(2.7)
где tкр — значение t-распределения Стьюдента для заданного α (берется 0,05) и для (п - 2) степеней свободы.
Критическое значение коэффициента корреляции r* также может априорно задаваться аналитиком.
Алгоритм подбора объясняющих переменных следующий:
1. Из множества потенциальных объясняющих переменных сначала исключаются все элементы, у которых коэффициенты корреляции в векторе R0 удовлетворяют неравенству abs(ri) < r*. Такие объясняющие переменные несущественно коррелируют с объясняемой переменной.
2. Из оставшихся переменных объясняющей признается такая переменная Хh, для которой |rh| = max{ri}, поскольку Хh является носителем наибольшего количества информации об объясняемой переменной.
3. Из множества потенциальных объясняющих переменных исключаются все элементы, у которых коэффициенты корреляции в строке h матрицы корреляции удовлетворяют неравенству rhi > r*, поскольку эти переменные слишком сильно коррелируют с объясняющей переменной, и, следовательно, только воспроизводят представляемую ею информацию.
Пункты 1 - 3 повторяются вплоть до момента опустошения множества потенциальных объясняющих переменных.
Метод показателей информационной емкости
Данный метод сводится к выбору таких объясняющих переменных, которые сильно коррелированы с объясняемой переменной, и одновременно, слабо коррелированы между собой. В качестве исходных значений в данном методе рассматриваются вектор R0 и матрица R.
Рассматриваются все комбинации потенциальных объясняющих переменных, общее количество которых составляет
L = 2т-1 (2.8)
где m – число потенциальных объясняющих переменных
Для каждой комбинации потенциальных объясняющих переменных рассчитываются индивидуальные и интегральные показатели информационной емкости.
Индивидуальные показатели информационной емкости в рамках конкретной комбинации рассчитываются по формуле
![]() (2.9)
(2.9)
где l - номер переменной,
ml — количество переменных в рассматриваемой комбинации.
Интегральные показатели информационной емкости потенциальных объясняющих переменных рассчитываются по формуле
![]() (2.10)
(2.10)
Индивидуальные и интегральные показатели информационной емкости нормируются в интервале [0; 1]. Их значения оказываются тем больше, чем сильнее объясняющие переменные коррелируют с объясняемой переменной и чем слабее они коррелируют между собой.
В качестве объясняющих выбирается такая комбинация переменных, которой соответствует максимальное значение интегрального показателя информационной емкости, т.е
![]() . (2.11)
. (2.11)
См. дополнительно литературу:[9, с. 15 - 33]; [10]; [11].