

Модель передачи сообщений
Основные особенности данного подхода:
Программа порождает несколько задач.
Каждой задаче присваивается свой уникальный идентификатор.
Взаимодействие осуществляется посредством отправки и приема сообщений.
Новые задачи могут создаваться во время выполнения параллельной программы, несколько задач могут выполняться на одном процессоре.
Модель параллелизма данных
Основные особенности данного подхода:
Одна операция применяется к множеству элементов структуры данных. Программа содержит последовательность таких операций.
"Зернистость" вычислений мала.
Программист должен указать транслятору, как данные следует распределить между задачами.
Модель общей памяти
В модели общей (разделяемой) памяти задачи обращаются к общей памяти, имея общее адресное пространство и выполняя операции считывания/записи. Управление доступом к памяти осуществляется с помощью разных механизмов, таких, например, как семафоры. В рамках этой модели не требуется описывать обмен данными между задачами в явном виде. Это упрощает программирование. Вместе с тем особое внимание приходится уделять соблюдению детерминизма, таким явлениям, как "гонки за данными" и т. д.
Законы Амдала
Законы Амдала составляют теоретическую основу оценок достижимой производительности параллельных программ. Они сформулированы для некоторой идеализированной модели параллельных вычислений, в которой, например, не учитывается латентность (конечное время передачи данных) коммуникационной среды и т. д.
1-й закон
Производительность вычислительной системы, состоящей из связанных между собой устройств, определяется самым медленным компонентом.
2-й закон
Пусть
время выполнения алгоритма на
последовательной машине ![]() ,
причем
,
причем ![]() -
время выполнения последовательной
части алгоритма, а
-
время выполнения последовательной
части алгоритма, а ![]() -
параллельной. Тогда при выполнении той
же программы на идеальной параллельной
машине, содержащей
-
параллельной. Тогда при выполнении той
же программы на идеальной параллельной
машине, содержащей ![]() процессорных
элементов коэффициент
ускорения:
процессорных
элементов коэффициент
ускорения:
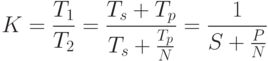
где ![]() и
и ![]() -
относительные доли последовательной
и параллельной частей
-
относительные доли последовательной
и параллельной частей
![]() .
Графическое представление закона Амдала
дано на рис.
1.8.
.
Графическое представление закона Амдала
дано на рис.
1.8.
3-й закон
Пусть
система состоит из
простых
одинаковых процессорных
элементов,
тогда при любом режиме работы ![]()
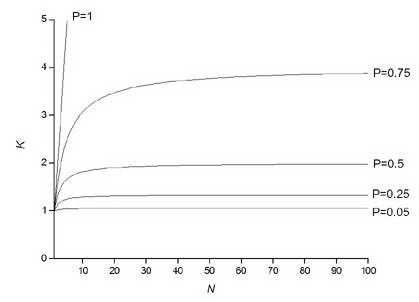
Рис. 1.8. Зависимость ускорения от доли параллельного кода и числа процессоров в законе Амдала
Стандарты mpi
Message Passing Interface (MPI, интерфейс передачи сообщений) — программный интерфейс (API) для передачи информации, который позволяет обмениваться сообщениями между процессами, выполняющими одну задачу. Разработан Уильямом Гроуппом, Эвином Ласком (англ.) и другими.
В MPI 1.1 (опубликован 12 июня 1995 года, первая реализация появилась в 2002 году) поддерживаются следующие функции:
передача и получение сообщений между отдельными процессами;
коллективные взаимодействия процессов;
взаимодействия в группах процессов;
реализация топологий процессов;
В MPI 2.0 (опубликован 18 июля 1997 года) дополнительно поддерживаются следующие функции:
динамическое порождение процессов и управление процессами;
односторонние коммуникации (Get/Put);
параллельный ввод и вывод;
расширенные коллективные операции (процессы могут выполнять коллективные операции не только внутри одного коммуникатора, но и в рамках нескольких коммуникаторов).
Сообщения
Сообщение содержит пересылаемые данные и служебную информацию. Для того, чтобы передать сообщение, необходимо указать:
ранг процесса-отправителя сообщения;
адрес, по которому размещаются пересылаемые данные процесса-отправителя;
тип пересылаемых данных;
количество данных;
ранг процесса, который должен получить сообщение;
адрес, по которому должны быть размещены данные процессом-получателем.
тег сообщения;
идентификатор коммуникатора, описывающего область взаимодействия, внутри которой происходит обмен.
Тег - это задаваемое пользователем целое число от 0 до 32767, которое играет роль идентификатора сообщения и позволяет различать сообщения, приходящие от одного процесса. Теги могут использоваться и для соблюдения определенного порядка приема сообщений.
Прием сообщения начинается с подготовки буфера достаточного размера. В этот буфер записываются принимаемые данные. Операция отправки или приема сообщения считается завершенной, если программа может вновь использовать буферы сообщений.
Основные понятия mpi
Коммуникатор представляет собой структуру, содержащую либо все процессы, исполняющиеся в рамках данного приложения, либо их подмножество. Процессы, принадлежащие одному и тому же коммуникатору, наделяются общим контекстом обмена. Операции обмена возможны только между процессами, связанными с общим контекстом, то есть, принадлежащие одному и тому же коммуникатору (рис. 3.1). Каждому коммуникатору присваивается идентификатор. В MPI есть несколько стандартных коммуникаторов:
MPI_COMM_WORLD - включает все процессы параллельной программы;
MPI_COMM_SELF - включает только данный процесс;
MPI_COMM_NULL - пустой коммуникатор, не содержит ни одного процесса.
В MPI имеются процедуры, позволяющие создавать новые коммуникаторы, содержащие подмножества процессов.
Ранг процесса представляет собой уникальный числовой идентификатор, назначаемый процессу в том или ином коммуникаторе. Ранги в разных коммуникаторах назначаются независимо и имеют целое значение от 0 до число_процессов - 1 (рис. 3.2).
Тег (маркер) сообщения - это уникальный числовой идентификатор, который назначается сообщению и позволяет различать сообщения, если в этом есть необходимость. Если тег не требуется, вместо него можно использовать "джокер" MPI_ANY_TAG.
Инициализация
Подключение к MPI
int MPI_Init(int *argc, char **argv)
MPI_INIT(IERR)
Аргументы argc и argv требуются только в программах на C, где они задают количество аргументов командной строки запуска программы и вектор этих аргументов. Данный вызов предшествует всем прочим вызовам подпрограмм MPI.
Завершение работы с MPI
p>int MPI_Finalize()
MPI_FINALIZE(IERR)
После вызова данной подпрограммы нельзя вызывать подпрограммы MPI. MPI_FINALIZE должны вызывать все процессы перед завершением своей работы.
Определение размера области взаимодействия
p>int MPI_Comm_size(MPI_Comm comm, int *size)
MPI_COMM_SIZE(COMM., SIZE, IERR)
Входные параметры:
comm - коммуникатор.
Выходные параметры:
size - количество процессов в области взаимодействия.
Определение ранга процесса
int MPI_Comm_rank(MPI_Comm comm, int *rank)
MPI_COMM_RANK(COMM, RANK, IERR)
Входные параметры:
comm- коммуникатор.
Выходные параметры:
rank - ранг процесса в области взаимодействия.