

Laboratory work #4 (nn2)

Alyuda NeuroIntelligence is full - packed with proven techniques for neural network design and optimization. It is designed to help you gain the maximum productivity in preprocessing data, find efficient network architecture, analyze performance and apply the network to new data.
NeuroIntelligence supports all stages of neural network application. It can be used to:
analyze and preprocess datasets,
find the best neural network architecture,
test and optimize the selected network,
apply the network to solve your problem.
The fastest way to create and use a new neural network is the following:
Step |
How To |
Load input dataset |
Click Open on the main toolbar |
Select target column |
Use Target drop-down list on the Analysis toolbar. |
Design network |
Click Architecture Search on the main toolbar (or manually select number of hidden layers and units in the Design window) |
Train network |
Click Train on the main toolbar |
Query network |
Click Manual Query, Query Dataset or Load Query File on the main toolbar. |
W ORK
ORK
Proper preparation of your data sets is the most important step in working with neural networks. Having a neural network with well-prepared data will lead to impressive results. Unprepared data usually lead to failure in applying neural network. Firstly, right amount of data needed. If your historical data have a small number of cases, the neural network will not have enough information about your problem to train correctly. It is recommended to have at least several hundred records in your data set. Too much data may increase training time of a neural network and even deteriorate network performance. The right amount of data hugely depends on problem and its complexity. Secondly, data shouldn't be self-contradictory. You need to remove self-contradictory data or add more inputs to make your data consistent. Add more inputs to let network differentiate between self-contradictory records or remove records that are self-contradictory. For example, if you need to predict a bankruptcy for a number of companies and among these companies you have two with almost equal size, capacity factor, burden rate, credit worthiness, etc., but in one case you have a bankrupt conclusion and in another case non-bankrupt. Neural network won't be able to find a difference. You need to add one more factor, that can distinguish these companies, or you need to remove both cases from the dataset to improve the network performance. Thirdly, inputs should have maximum influence on target. You need to add ALL parameters that pre-determine your target significantly and remove ALL parameters that have no (or almost no) influence on your target. The better you do this task the better results will be. Forthly, your data shouldn't have missing values or outliers. You need to remove or substitute with approximated values your missing data or outliers. The more missing values and outliers you have in your data the worse your results will be. Fifthly, your data should well present your problem environment. You need to include as much variants of previous cases as possible into your data. The more different variants you have the more confident will be network in performing on new data. Dataset should contain at least several cases for each category in each categorical column and different categories should be well-presented in different combinations. For example, if you predict bankruptcy and your data contains a lot of records for companies that weren't bankrupted and only a couple of bankrupts your neural network will be poor in predicting bankrupts. For most problems it's recommended to maintain at least 10 to 1 ratio between different categories.
So,
Right amount of data;
No self-contradictions;
Maximum influence of inputs;
No missing values or outliers;
Data should well present your problem environment.


For convenience we will use Examples attached with Aluyda
(C:\Program Files (x86)\Alyuda NeuroIntelligence\EXAMPLES\)
You will find attached following examples:
CreditApproval
EmployeeRetention
GasConsumption
Irises
MedicalDecisionSupport
RealEstate
SalesForecasting
StockPrediction
Wine
We will work with CreditApproval
To start working with Alyuda NeuroIntelligence you need to open an input dataset.
Note: Alyuda NeuroIntelligence works with Excel files as well as with ASCII text data files with delimiter-separated values. Note: NeuroIntelligence automatically analyzes the file structure of the text file and detects typical data layouts, separators and delimiters. For special cases you can explicitly specify the file structure in Data Analysis options.
T o
open input dataset, click Open
button on the main toolbar or select File
> Open
Dataset
from the menu.
o
open input dataset, click Open
button on the main toolbar or select File
> Open
Dataset
from the menu.

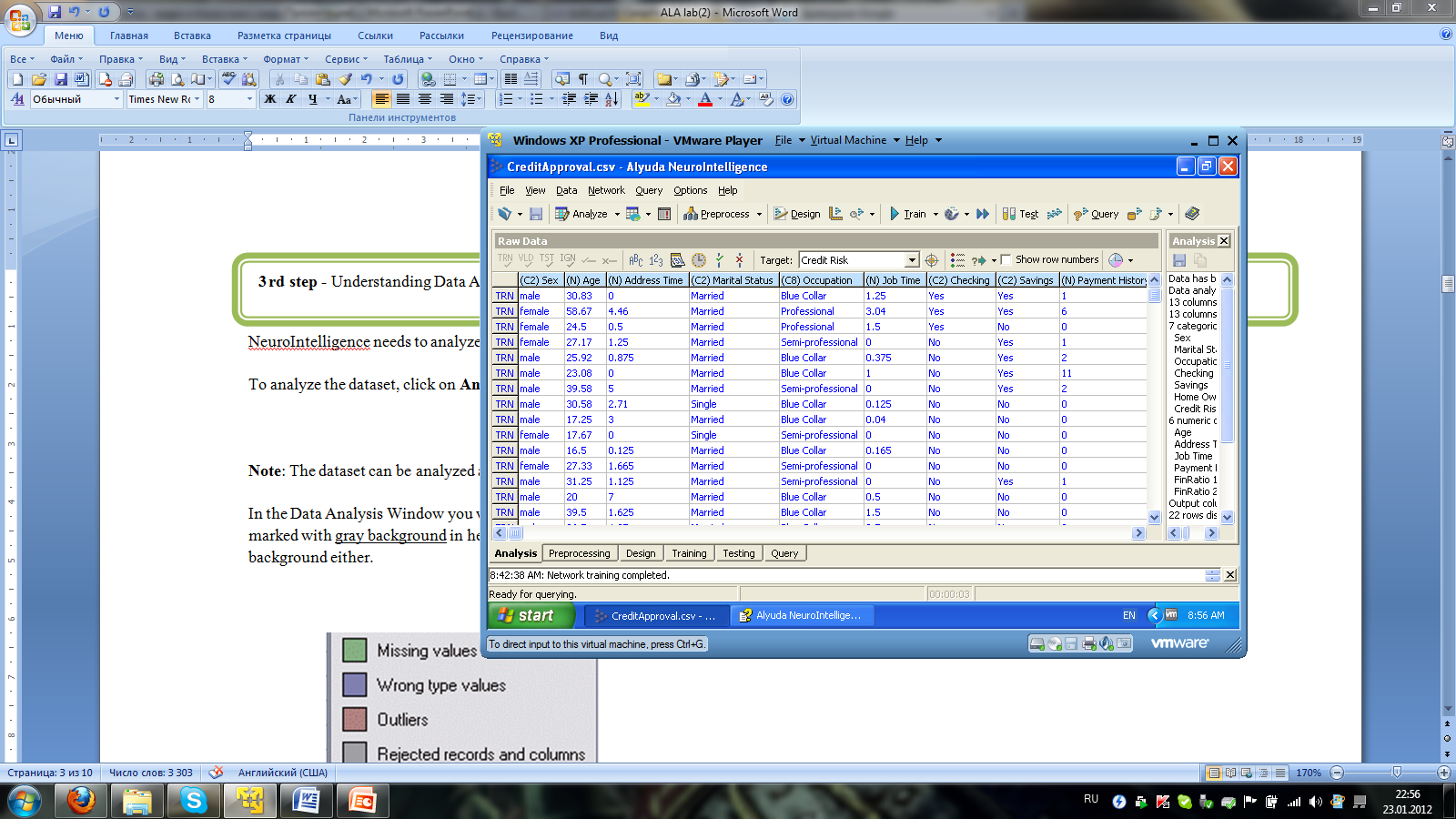
NeuroIntelligence needs to analyze your dataset to define column parameters and detect data anomalies.
To analyze the dataset, click on Analyze button of the main toolbar.
 Note:
The dataset can be analyzed automatically after opening (see
Preferences for more details)
In the Data Analysis Window
you will see a data-grid filled with your data. All columns and
records unsuitable for use with neural network are marked with gray
background
in headers and gray text color. Additionally missing, wrong type
values and outliers are marked with different background either.
Note:
The dataset can be analyzed automatically after opening (see
Preferences for more details)
In the Data Analysis Window
you will see a data-grid filled with your data. All columns and
records unsuitable for use with neural network are marked with gray
background
in headers and gray text color. Additionally missing, wrong type
values and outliers are marked with different background either.
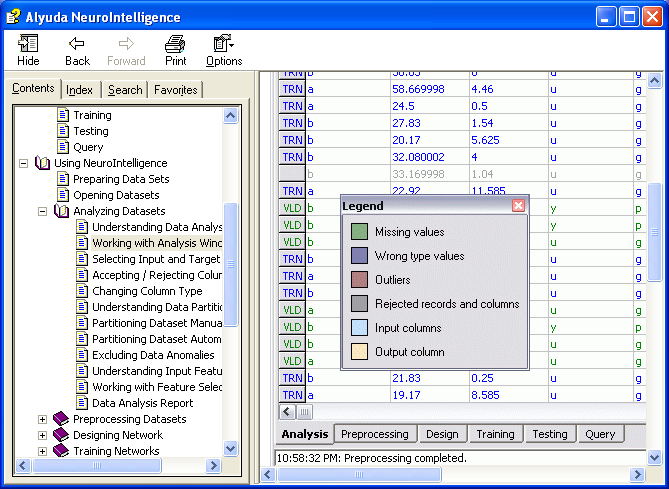
Note:
You can change the rules of data analysis in Data Analysis Options.
(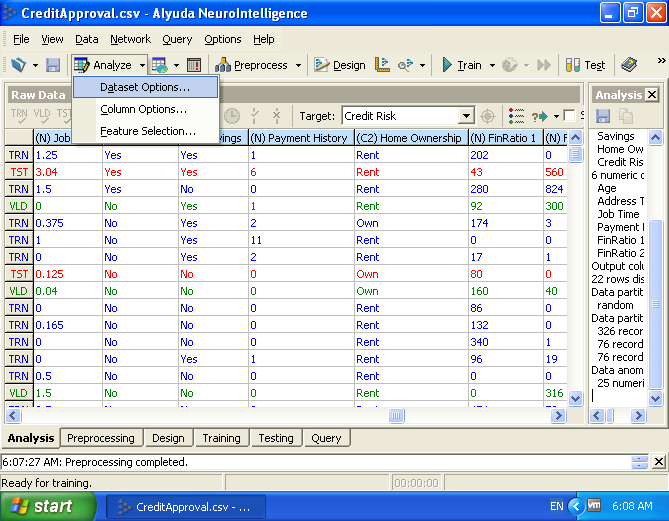 )
)
