

1) Вручную:
нажатием клавиш Ctrl+Break;
выполнением команды Run | Break;
щелчком по кнопке Break на панели инструментов Debug;
2) Автоматически:
при генерации необрабатываемой ошибки;
при выполнении выражения, вызывающего останов. Это выражение определяется в окне Add Watch(Добавление контрольного значения);
при достижении строки, в которой содержится точка останова. Точка останова (Breakpoint) определяет оператор или набор условий, при выполнении которых Visual Basic автоматически останавливает программу и переходит в режим прерывания, не исполняя строку, содержащую точку останова;
встретился оператор Stop. При его выполнении происходит переход в режим прерывания.
После внесения необходимых изменений можно возобновить выполнение программы с той строки, которая вызвала прерывание. Для этого нужно выполнить команду меню Run | Continue или воспользоваться одноименной кнопкой на панели инструментов Debug.
В режиме прерывания можно указать оператор, до которого следует выполнить программу, после чего вновь остановиться. Для этого нужно поместить курсор на нужном операторе и выполнить команду Debug | Run To Cursor(Выполнить до текущей позиции). Такой прием позволит "перепрыгивать" через не интересующие Вас фрагменты кода.
Отлаживая программу или экспериментируя с ней, Вы можете выделить любой оператор в текущей процедуре и, выполнив команду Debug | Set Next Statement (Задать следующую инструкцию), продолжить выполнение с указанного оператора, пропустив тем самым определенный фрагмент кода. Эта команда полезна в том случае, когда нужно вернуться к предыдущему оператору и проверить, как работает эта же часть программы при других значениях свойств или переменных.
Выбрав команду Debug | Show Next Statement (Показать следующую инструкцию), Вы узнаете, какая строка будет выполнена следующей, - Visual Basic поместит на нее курсор.
Самостоятельная работа № 33
Контроллеры ввода-вывода
Подсоединение периферийных устройств, таких как манипулятор "мышь", внешние модемы, сканеры, цифровые фотокамеры, принтеры и т. п., к персональному компьютеру производится через специальные интерфейсы, называемые портами ввода/вывода. До недавнего времени подобные порты выполнялись в виде отдельных плат расширения. Современные системные платы, как правило, содержат все необходимые интерфейсы. Спецификации PC98 и PC99 предполагают постепенный отказ от их применения в пользу универсальной последовательной шины USB.
Взаимодействие периферийного устройства с ПК происходит через интерфейс, определяющий, в частности, тип и "род" соединителя (розетка или вилка, "мама" или "папа"), уровни и длительности электрических сигналов, протоколы обмена.
Стандартные последовательный и параллельный интерфейсы часто называют портами ввода/вывода. Порт называют последовательным, когда информационные биты передаются последовательно один за другим, и параллельным, когда несколько бит данных передаются одновременно. Параллельный порт обычно используется для подключения принтера, последовательный - для других периферийных устройств. Для связи портативных компьютеров с настольными используется беспроводный инфракрасный порт . В качестве последовательного стандартного интерфейса используется разновидность RS-232C (Recommended Standard) - EIA-232D (Electrical Industry Association), а в качестве параллельного - Centronics.
Для подключения джойстика или музыкальных инструментов служит специальный игровой адаптер - Game/MIDI Adapter. Если несколько контроллеров (последовательного и параллельного портов, приводов флоппи- и жестких дисков) конструктивно выполнены на отдельной плате, она называется многофункциональной платой ввода/вывода (Multi I/O Card) или просто мультикартой. Применение мультикарт было характерно для 386 и 486-х компьютеров. Более поздние ПК содержат все необходимые порты на материнской плате (за исключением игрового, расположенного на звуковой плате).
Самостоятельная работа № 34
Структура внешних ЗУ
Устройства внешней памяти или, иначе, внешние запоминающие устройствавесьма разнообразны. Их можно классифицировать по целому ряду признаков: по виду носителя, типу конструкции, по принципу записи и считывания информации, методу доступа и т.д.Один из возможных вариантов классификации ВЗУ приведен на рис. 2.6.
Внешние запоминающие устройства (ВЗУ) – это электромеханические запоминающие устройства, которые характеризуются большим объемом хранимой информации и низким (по сравнению с электронной памятью) быстродействием. К ВЗУ относятся накопители на магнитной ленте (НМЛ), накопители на гибких магнитных дисках (НГМД), накопители на жестких магнитных дисках (НЖМД), накопители на оптических дисках (НОД) и др.

Рис. 2.6.Классификация ВЗУ
Носитель информации – это материальный объект, способный хранить информацию. Например, в первых ЭВМ носителями информации являлись бумажные ленты и карты, на которых были пробиты (перфорированы) отверстия.
При магнитной записи информации с помощью записывающей головки происходит изменение магнитной индукции носителя. Носитель изготавливают из ферромагнитного материала. Располагается носитель на подложке, в качестве которой может выступать пластмассовая пленка, металлические или стеклянные диски.
Ток, протекающий по обмотке записывающей головки, создает в сердечнике (магнитопроводе) магнитный поток. Через узкий зазор в сердечнике магнитный поток намагничивает носитель в одном из двух направлений, что зависит от направления протекающего по обмотке тока. Разные направления намагниченности носителя соответствуют логическому нулю или логической единице. Таким образом, записывающая головка – это маленькие электромагниты, которые своим электромагнитным полем изменяют ориентацию магнитных доменов в носителе в зависимости от полярности протекающего в обмотке тока.
При считывании информации с ленты или диска движущийся намагниченный носитель индуцирует в считывающей головке электродвижущую силу. Полярность возникающего на обмотке напряжения зависит от направления намагниченности носителя.
Накопители на магнитных дисках включают в себя ряд систем:
ü элекромеханический привод, обеспечивающий вращение диска;
ü блок магнитных головок для чтения и записи;
ü системы установки (позиционирования) магнитных головок в нужное для записи или чтения положение;
ü электронный блок управления и кодирования сигналов.
Дискета – гибкий пластиковый диск с нанесенным на обе стороны магнитным покрытием, заключенный в достаточно твердый пластиковый конверт для предохранения от механических повреждений. Информация на диск наносится вдоль концентрических окружностей (рис. 2.7) – дорожек.
Каждая дорожка разбита на несколько секторов (обычно 18) – минимально возможных адресуемых участков. Стандартная емкость сектора – 512 байт.
Самостоятельная работа № 35
Сравнительный анализ интерфейсов
Борьба интерфейсов подключения периферийных устройств ввода/вывода и хранения информации началась, когда перед компьютером замаячила перспектива стать персональным, т. е. доступным и ориентированным на приложения, невзыскательные к ресурсам и скорости исполнения. SCSI всегда был более дорогой альтернативой IDE хотя бы в силу своей декларируемой производительности. Благодаря то ли цене, то ли действиям производителей готовых систем, то ли общественному мнению или всему сразу областью применения SCSI постепенно стали считаться исключительно серверы высокого уровня и специализированные рабочие станции. Более того, громкие анонсы новых протоколов передачи данных создали представление, что EIDE является не только более дешевым, но и не уступающим SCSI по скорости решением. Ниже пойдет речь о родовых различиях двух интерфейсов и их "профессиональной" пригодности в современных задачах широкого спектра.
PIO и Bus Master
Существует два механизма передачи данных адаптером от устройства хранения информации в системную шину: процессорный, или программируемый ввод/вывод (PIO) и ввод/вывод с использованием способности самого устройства захватывать шину, управлять ею и загружать данные непосредственно в системную память (Bus Master DMA).
Первый, классический способ приема данных от устройства состоит в том, что процессор выполняет команду чтения порта, считывает байт или слово данных в свой регистр, после чего переписывает его в память, затем повторяет эту процедуру до тех пор, пока вся необходимая информация не будет считана из устройства в память. Типичным примером реализации PIO являются IDE-контроллеры, практически без изменений прожившие с нами последнее десятилетие. При работе IDE-контроллера процессор отвечает за передачу данных, в это время выполнение других его функций приостанавливается. Проблема в том, что, кроме общения с периферийными устройствами хранения данных, CPU должен осуществлять множество других действий. В многозадачных операционных системах особенно накладно использовать процессор исключительно для операций ввода/вывода. Поэтому контроллеры внешних устройств стали наделяться возможностями, замещающими функции процессора. В стандарт интерфейса ввода/вывода Enhanced IDE, помимо расширения класса обслуживаемых устройств (жесткие диски, CD-ROM, магнитооптические и ZIP-накопители и т. д.) и увеличения их количества до четырех -- по два на каждом из двух возможных каналов, была внесена функция управления системной шиной. Процессор программирует контроллер EIDE, указывая ему, откуда он должен взять данные и куда в память их положить. Затем контроллер захватывает управление шинами PCI и памяти и выполняет операции по считыванию данных с жесткого диска или CD-ROM непосредственно в память в режиме прямого доступа (DMA -- Direct Memory Access). При таком способе обмена данными процессор свободен после выдачи команд контроллеру EIDE и занимается другими задачами.
Тем не менее, даже наделенный свойством управления шиной интерфейс EIDE сохранил свой главный недостаток, будучи по своей природе однозадачным. EIDE хорош для операционных систем, таких, как DOS и ранняя Windows, которые сами являются однозадачными, так как он в состоянии выставить в определенный момент времени ровно один запрос ввода/вывода. Многозадачные среды, такие, как OS/2, NT, Windows 95 или NetWare, не только упростили работу с приложениями, но и сделали очевидным преимущество применения контроллеров, обслуживающих множественные запросы к данным. А это под силу только SCSI.
Что же касается EIDE, то, недорогой и ограниченный в применении, он только некоторыми чертами отдаленно напоминает своего более развитого соперника. Функция Bus Master наделяет интерфейс EIDE SCSI-подобными свойствами. Само расширение интерфейса IDE до двух независимых (что тоже неочевидно) каналов, обслуживающих одновременно выполнение двух запросов к двум из четырех устройств, вносит некоторый параллелизм и дает определенный выигрыш в производительности. Однако это далеко не то же самое, что запустить семь параллельных запросов к устройствам на одном контроллере SCSI! Характерно, что реализация одновременного обслуживания двух запросов к устройствам на двух независимых каналах EIDE, заложенная в основу интерфейса, до недавнего времени имела некоторую поддержку под Windows 95 только для контроллеров Intel PIIX. В других случаях операционная система не могла обращаться более чем к одному устройству EIDE в каждый момент времени, что, конечно же, сказывалось на производительности системы в целом, особенно при наличии медленных (по сравнению с жесткими дисками) устройств вроде приводов CD-ROM или стримеров. Можно надеяться, что со стандартизацией интерфейсных чипов и улучшением программной поддержки со стороны операционных систем EIDE сможет обеспечивать и одновременный поканальный доступ к устройствам, и эффективное управление системной шиной, но ему все равно будет далеко до возможностей SCSI.
Многозадачность
Важнейшей характеристикой производительности используемых в PC контроллеров ввода/вывода является способность к одновременной обработке данных нескольких приложений. В компьютере много устройств, несоответствие скоростей которых составляет несколько порядков. Процессор мощностью в сотни MIPS, в течение десятков миллисекунд ожидающий отработки запроса ввода/вывода, подобен Ferrari, вздумавшему полетать по проселкам Фастовского района. Десять лет назад процессору нужно было 100 мс для формирования запроса ввода/вывода к одному диску, отработка запроса занимала также около 100 мс. Сегодня на запрос требуется 1 мс, на отработку же инструкции уходит порядка 10 мс. В однозадачной среде 9 мс, или 90% времени, составляет время ожидания. В многозадачной среде вместо ожидания отработки инструкции процессор переключается на другую задачу, генерирует новый запрос и т. д. Одновременная обработка различных инструкций многократно повышает производительность дисковой подсистемы. Контроллер Enhanced IDE по-прежнему работает только с одним устройством ввода/вывода в каждый момент времени. Отсутствие механизма параллельной обработки нескольких потоков данных и реальной поддержки операций ввода/вывода в режиме DMA без участия центрального процессора -- основной бич дисковой EIDE-подсистемы и ее "черная метка". В действительности не подвергается сомнению преимущество SCSI перед EIDE -- иначе почему в высокоуровневых системах и серверах баз данных сплошь используется только SCSI? Вопрос состоит в том, имеет ли смысл применение SCSI-устройств в настольных компьютерах, типичным приложением для которых является работа в Internet. Ответ -- однозначно. Причин несколько, но самыми весомыми являются две. Во-первых, SCSI -- это интерфейс, реализующий множественные одновременные запросы к устройствам на одной шине. Во-вторых, SCSI реально обеспечивает управление шиной в режиме Bus Master с минимальной нагрузкой на центральный процессор. Когда жесткий диск и CD-ROM подсоединены к одному интерфейсу SCSI, медленное позиционирование головок привода компакт-дисков не сказывается на быстродействии операций с жестким диском, поскольку устройство SCSI отключается от шины, пока не наступает готовность к передаче данных. Сколько бы ни было на шине SCSI-устройств, активизация, или подсоединение к шине каждого из них, производится самим устройством только при передаче данных. Поскольку поток информации с жесткого диска измеряется несколькими мегабайтами в секунду (и для отдельно взятых дисков EIDE и SCSI с одинаковыми механическими характеристиками идентичен), то даже относительно недорогого контроллера Ultra SCSI с пропускной способностью до 20 MBps достаточно для обеспечения полноценной параллельной работы двух-трех накопителей SCSI на одной шине. Необходимость в более дорогом контроллере Ultra/Ultra2 Wide SCSI с его запасом производительности в 40/80 MBps может возникнуть разве что при интенсивной обработке мультимедийной информации.
Если способность к отключению от шины заметно повышает эффективность SCSI-систем с несколькими устройствами хранения данных, то другая особенность относится к оптимизации запросов к информации, расположенной на одном накопителе. Электроника передовых жестких дисков SCSI, как, например, технология Serpentine в дисках Western Digital Enterprise, реализует так называемую управляемую очередь команд, когда порядок выполнения инструкций и последовательность перемещения головок оптимизируются самим накопителем.
Многозадачность в настольных системах
Если аргументы в пользу SCSI в противовес EIDE в многопользовательских средах обычно не вызывают возражений, то в отношении "одноместных" настольных PC обсуждение многозадачности и смысла применения SCSI обычно прекращается под натиском ценовых аргументов сторонников "экономичных" решений.
Рассмотрим типичный набор действий владельца PC при работе с современными приложениями. Пользователи настольных систем под управлением Windows 9х попадают в многозадачную среду сразу после нажатия кнопки Power. За то время, пока система приходит в готовность, успевают стартовать несколько системных приложений, открываются окна и т.д. Далее просвещенный пользователь начинает свою работу с сеанса посещения Сети. Как правило, устанавливается коммутируемое соединение по модему с Internet-провайдером запуском программы удаленного доступа. После этого проверяется почта и загружается броузер. Для просмотра файлов, подшитых к сообщениям, запускаются: Word для чтения пресс-релиза, Adobe Acrobat для знакомства с эскизом рекламы, WinZip для распаковки чужих прайс-листов и Excel для их прочтения, при этом что-то сохраняется на диск. За какие-то пару минут запущенными оказываются с десяток задач. Таким образом, сложно отстаивать аргумент, что рядовой пользователь настольного ПК работает в однозадачной среде.
Апологеты истинной многозадачности считают подобный расклад примером "псевдомногозадачной" последовательной работы с приложениями в многооконном интерфейсе -- с одним приложением в одном окне в один момент времени. В качестве контрпримера достаточно вспомнить, сколько времени скачивались очередной Service Pack или драйверы к видеокарте. При этом вы, наверняка, делали что-то еще, пребывая в ясном и активном уме. Обилие интересной и, что характерно, объемной информации в Сети (графика, видео, аудио) позволяет с толком заполнить любой промежуток времени, запустив несколько копий броузера. Это ли не многозадачность? Такие условия работы типичны сегодня для многих настольных PC, подавляющее большинство которых оснащены накопителями EIDE, плохо пригодными к одновременной работе с приложениями различной природы, в отличие от SCSI-систем. Почему-то считается, что оптимизация операций ввода/вывода данных свойственна только мэйнфреймам и рабочим станциям. Тем не менее технологии ввода/вывода данных -- узкое место всех без исключения PC, а с изменением состава типичных современных приложений и увеличением объема получаемой и преобразуемой информации проблема охватывает и персональные системы.
Анатомия заблуждения
Вообще говоря, главной задачей PC является обработка данных. Применение в качестве хранилища информации жесткого диска -- механического в своей основе устройства -- является сильным тормозящим фактором. Поэтому во всех ОС часть системной памяти резервируется под кэш, в котором располагаются "наиболее часто используемые" данные, что позволяет обойтись без повторного обращения за ними к жесткому диску. Потому инвестиции в системную память благотворно сказываются на ускорении работы компьютера. Больше памяти -- больше кэш -- реже приходится обращаться к диску. Тем не менее невозможно разместить в оперативной памяти всю необходимую информацию, поэтому в дополнение к кэшу в операционных системах организуется файл подкачки (swap file) на жестком диске, куда сбрасываются данные неактивных приложений. Нетрудно догадаться, что swap file -- одно из самых посещаемых мест на диске. Чем быстрее при этом работает жесткий диск, тем меньше времени уходит на приведение компьютера в полностью боеспособное состояние. Так что скоростной диск -- еще одна хорошая инвестиция в PC. А лучше -- два скоростных диска, отдельно для приложений и часто изменяемых данных.
Броузеры также кэшируют информацию из Web и сохраняют ее на диске, благодаря чему ускоряется повторная загрузка страниц. Таким образом, кэш броузера -- еще одна "горячая точка". Да мало ли разных файлов формируется на диске при комплексной работе с PC во время просмотра, записи, печати, редактирования содержимого Web-страниц -- спул-файл печати, файл сканированного или захваченного образа и т. д. Все это в конечном счете -- операции ввода/вывода, замкнутые на одно из самых медленных устройств PC -- жесткий диск. Большая часть современных PC снабжена одним жестким диском EIDE и одним накопителем CD-ROM, которые хорошо если подсоединены к разным каналам. Часто из копеечной экономии их подключают к разъемам одного и того же кабеля. Как было сказано, основная проблема интерфейса EIDE -- это возможность обработки ровно одного запроса ввода/вывода в каждый момент времени, и пока выполнение одной системной команды не закончится, любое устройство остается недосягаемым для остальных операций. Если учесть, что типичное время только позиционирования головок привода CD-ROM составляет сотни миллисекунд, то разнести два устройства по разным каналам IDE -- это уже большое благо. Накопители EIDE, к сожалению, далеко не такие быстрые, как может показаться после чтения анонсов. Несмотря на примелькавшиеся цифры 33 MBps или 66 MBps, таких показателей не достигает даже внутренняя пиковая скорость работы жесткого диска. Что касается реалий, то хорошо, если при чтении непрерывно записанных файлов устойчивая скорость передачи составит около 10 MBps, а вообще говоря, с учетом времени позиционирования головок средняя скорость потока данных с диска обычно не превышает одного-двух мегабайт в секунду. При этом все обращения к диску производятся последовательно. Представьте, что вы надеялись совместить в системе с одним диском EIDE запись содержимого жесткого диска (поток чтения) на CD-R (поток записи) с блужданием по Сети (поток кэширования на диск) и редактированием текстового документа (поток записи в файл подкачки), используя два последних занятия для заполнения паузы. В условиях последовательного выполнения команд ввода/вывода в неконтролируемом порядке сохранить непрерывность потока записи на CD-R малореально, и быстро понять это помогут несколько испорченных заготовок. Еще одним большим заблуждением в отношении EIDE является то, что наименование Ultra DMA свидетельствует о работе устройства в режиме управления шиной и прямого доступа к памяти (DMA), и ресурсы центрального процессора автоматически перераспределяются для работы с другими приложениями. В действительности в большинстве PC устройства Ultra DMA как работали много лет назад, так и продолжают работать в режиме программного ввода/вывода под управлением процессора (PIO), делая нереальным эффективное совмещение нескольких видов деятельности. Для реализации функции DMA производителям (сборщикам) компьютеров нужны особые драйверы устройств Bus Master, установка и наладка которых нередко оказывается непростым делом. Виноватыми могут быть и разработчики драйверов, и производители EIDE-устройств, но кому интересны отговорки? Функция Bus Master, поддерживаемая контроллером SCSI, позволяет уменьшить нагрузку на центральный процессор и его участие в передаче данных, высвобождая вычислительные ресурсы для прочих ресурсоемких задач. Даже для простейших контроллеров SCSI типичная загрузка процессора при копировании большого файла будет ниже, чем при использовании жесткого диска EIDE.
В двух словах
Скорость передачи данных отдельно взятым устройством -- не единственный показатель, формирующий представления о современном PC. Реализация многозадачности -- гораздо более эффективный способ справиться с потоками данных, обрабатываемых современными приложениями, и ликвидировать разницу между производительностью быстрых процессоров и пропускной способностью периферии. Передача управления системной шиной самим устройствам ввода/вывода -- шаг к избавлению процессора от рутинных, пожирающих ресурсы операций пересылки данных. Enhanced IDE в роли заменителя SCSI смотрится сносно только с прикрепленным ценником. Время идет, адаптеры SCSI тоже дешевеют. Новое поколение высокоинтегрированных чипов и материнских плат со встроенной поддержкой SCSI предоставляет экономичную альтернативу дорогостоящим решениям SCSI.
Дисководы EIDE и SCSI внешне похожи, но работают по-разному.Чтобы помочь вам сделать правильный выбор, мы ответим на вопросы об этих двух технологиях. Еще совсем недавно выбор жесткого диска или дисковода CD-ROM не представлял сложной задачи. Просто потому, что большого выбора практически не было. Когда вы покупали новую систему, она, как правило, укомплектовывалась жестким диском с интерфейсом IDE, если только вы специально не просили установить диск SCSI. Впрочем, без необходимости (например, для файл-сервера или мощной рабочей станции) никто и не стал бы просить об этом, потому что SCSI-устройства были гораздо дороже накопителей с интерфейсом IDE. В настоящее время возможности интерфейса IDE расширились, он превратился в Enhanced IDE (EIDE), а SCSI стал доступнее по цене, так что появился реальный выбор. EIDE и SCSI -- это две основные шинные технологии для подключения к системе жесткого диска или накопителя CD-ROM. Интерфейс EIDE шире распространен, поскольку он (так уж исторически сложилось) дешевле и его проще конфигурировать. Однако SCSI, вообще говоря, работает быстрее, является более гибким и допускает большие возможности расширения. Прежде чем решить, каким путем идти (или довериться в этом вопросе продавцу ПК), вам нужно познакомиться с особенностями каждой технологии. Из сети America Online и других сетевых служб были взяты вопросы об EIDE и SCSI. В поисках ответов на них и в процессе тестирования в нашей лаборатории новейших систем мы узнали много удивительного о том, как работают эти технологии, и в том числе о том, как они не работают.
В.: Что такое EIDE?
О.: Приготовьтесь отведать кушанье из компьютерных аббревиатур. Интерфейс IDE (Integrated Drive Electronics) появился в середине 80-х годов в качестве недорогого способа подключения к ПК одного или двух жестких дисков. Программная и аппаратная части интерфейса IDE были разработаны так, чтобы обеспечивалась совместимость с дисковым контроллером машины PC AT производства корпорации IBM. Позже Институтом ANSI был принят соответствующий стандарт на интерфейс под названием AT Attachment (ATA). В большинстве случаев сокращения IDE и ATA обозначают один и тот же стандарт, однако IDE употребляется чаще. Ну, вы все еще голодны? Тогда следующая аббревиатура -- Enhanced IDE (EIDE). Этот стандарт объединяет в себе четыре важных функции, позволяющие интерфейсу IDE приблизиться к более совершенному SCSI (речь о котором пойдет дальше).
Во-первых, внесенные в спецификацию ATA улучшения (она получила имя ATA-2) позволили превзойти максимальную скорость передачи данных интерфейса IDE. Некоторые производители жестких дисков, среди которых компании Quantum и Seagate, для обозначения своих высокопроизводительных изделий применяют термин Fast ATA. Во-вторых, стандарт ATA Packet Interface (ATAPI) позволяет подключать к интерфейсу EIDE не только жесткие диски, но и другие устройства. В-третьих, системы с интерфейсом EIDE имеют новую BIOS, реализующую доступ к НЖМД объемом более 528 Мбайт, что с обычным IDE-адаптером было невозможно.
И, наконец, в-четвертых, EIDE-системы могут содержать до двух контроллеров (каналов), к каждому из которых можно подключить по паре периферийных устройств. Обычно первичный контроллер используется для одного или двух НЖМД, а вторичный обслуживает такие устройства, как накопители на магнитной ленте или дисководы CD-ROM. Вся периферия должна находиться внутри ПК. Очень важно помнить следующее: если продавец упоминает в своей речи термин EIDE, это означает, что он имеет в виду аппаратный интерфейс IDE, поддерживающий одно или несколько из вышеперечисленных нововведений, но совсем не обязательно все четыре. Выяснить точно, какие именно функции EIDE имеет ваш интерфейс, бывает нелегко. Неопределенные стандарты и отсутствие универсальной терминологии еще более усугубляют эту проблему. Путаницу вносят также спецификации продукта и основной BIOS, по которым порой бывает невозможно выяснить, какие режимы поддерживаются. Например, вполне вероятно, что EIDE-плата ISA (Industry Standard Architecture) будет работать с большими жесткими дисками и накопителями ATAPI, однако медленная шина ISA не позволит обеспечить высокую скорость передачи данных, присущую этим дисководам. Разработчик первой спецификации IDE, компания Western Digital, чтобы избежать подобных неясностей, продвигает программу введения логотипа EIDE.
Самостоятельная работа № 36
Запоминающие устройства: назначение и основные характеристики
Запоминающее устройство — носитель информации, предназначенный для записи и хранения данных. В основе работы запоминающего устройства может лежать любой физический эффект, обеспечивающий приведение системы к двум или более устойчивым состояниям.
Основные характеристики ЗУ • информационная емкость; • быстродействие; • время хранения информации. 1. Информационная емкость N – число бит памяти в накопителе ЗУ; 2. Число слов ЗУ n – число адресов слов в накопителе ЗУ; 3. Разрядность m – число разрядов в накопителе ЗУ; 4. Число циклов перепрограммирования NcY – число циклов запись-стирание, при которой ЗУ работоспособно; 5. Потребляемая мощность в установившемся режиме Pcc; 6. Потребляемая мощность в режиме хранения Pccs; 7. Время хранения tsG .
Самостоятельная работа № 37, 38, 39
Виды адресации
Одной из важнейших архитектурных характеристик МП является перечень возможных способов обращения к памяти или видов адресации. Возможности МП по адресации существенны с двух точек зрения.
Во-первых, большой объем памяти требует большой длины адреса, так как n-разрядный адрес позволяет обращаться к памяти емкостью 2n слов. Типовые 8-разрядные слова МП дают возможность непосредственно обращаться только к 256 ячейкам памяти, что явно недостаточно. Если учесть, что обращение к памяти является наиболее часто встречающейся операцией, то очевидно, что эффективность использования МП во многом определяется способами адресации к памяти большого объема при малой разрядности МП.
Во-вторых, для удобства программирования желательно иметь простую систему формирования адресов данных при работе с массивами, таблицами и указателями. Рассмотрим способы решения этих проблем.
Если адресное поле в команде является ограниченным и недостаточным для непосредственного обращения к любой ячейке памяти, то память в таких случаях разбивают на страницы, где страницей считается 2n ячеек памяти.
Для согласования адресного поля команды малой разрядности с памятью большого объема (для решения “страничной” проблемы) в МП применяются различные виды адресации:
Прямая адресация к текущей странице. При такой адресации программный счетчик разбивается на два поля; старшие разряды указывают номер страницы, а младшие - адрес ячейки на странице. В адресном поле команды размещается адрес ячейки на странице, а адрес страницы должен быть установлен каким-то другим способом, например с помощью специальной команды.
Прямая адресация с использованием страничного регистра. В МП должен быть предусмотрен программно доступный страничный регистр, загружаемый специальной командой. Этот регистр добавляет к адресному полю команды несколько разрядов, необходимых для адресации ко всей памяти.
Прямая адресация с использованием двойных слов. Для увеличения длины адресного поля команды под адрес отводится дополнительное слово (а если нужно, то и два).
Адресация относительно программного счетчика. Адресное поле команды рассматривается как целое со знаком, которое складывается с содержимым программного счетчика для формирования исполнительного адреса. Такой способ относительной адресации создает плавающую страницу и упрощает перемещение программ в памяти.
Адресация относительно индексного регистра. Исполнительный адрес образуется суммированием содержимого индексного регистра и адресного поля команды, рассматриваемого как целое со знаком. Индексный регистр загружается специальными командами.
Косвенная адресация. При косвенной адресации в адресном поле команды указывается адрес на текущей странице, по которому хранится исполнительный адрес. В поле команды при этом требуется дополнительный разряд - признак косвенной адресации. Исполнительный адрес может храниться не в ячейке памяти, а в регистре общего назначения. В этом случае косвенная адресация называется регистровой.
Самостоятельная работа № 40
Классификация многомашинных ВС
Классификация определяется набором признаков, которые характеризуют внутренние параметры объектов классификации. При этом выбираются наиболее важные признаки, определяющие внешние параметры этих объектов.
В том случае, когда объектами классификации являются вычислительные системы (ВС), задача классификации усложняется из-за многообразия областей применения ВС и, следовательно, многообразия видов ВС, поскольку ВС являются специализированными в соответствии с классом решаемых задач.
Однако есть два фактора, которые надо принимать во внимание какие бы виды ВС не рассматривались. Это
- какие задачи должны решаться с помощью ВС,
- какие понадобятся вычислительные средства и как они должны быть взаимосвязаны, чтобы требуемые задачи можно было решить за заданное время(или в другой постановке – определяется время, необходимое для решения требуемых задач на выбранных вычислительных средствах).
Решаемые задачи весьма условно можно разделить по характеру взаимодействия между частями задачи (вычислительными процессами) на: сильно связанные и с ослабленными связями.
Вычислительные средства, предназначенные для решения отмеченных выше задач, назовем соответственно:
- многопроцессорными вычислительными системами (МПВС),
- многомашинными вычислительными системами (ММВС).
Состав вычислительных средств и связи между этими средствами – это основные классификационные признаки, характеризующие любую техническую структуру, в том числе и ВС, поскольку вычислительная система является технической структурой.
Что касается используемых далее терминов, то среди возможных синонимов выбираются, во-первых, русские, если они есть (например,многомашинные, а не мультикомпьютерные), во-вторых, наиболее простые (например, коммутатор, а не средства коммутации иликоммуникационная сеть).
Классификация ВС по основным признакам, характеризующим структуру этих технических объектов, приведена в таблице 1. В таблицу включены дополнительные признаки, отражающие особенности организации памяти, передачи данных, управления и конструктивной реализации ВС.
Классификация многомашинной ВС
Признак классификации |
|
Многомашинная ВС |
|
Состав структуры |
ВМ (ЭВМ, МПВС), EM, I/O, SW |
Вид связи между элементами структуры (вид коммутатора) |
Шинные (многошинный SW и др.) или линковые ( SW с регулярными связями и др. ) |
Организация памяти |
Распределенная память |
Способ передачи данных |
Параллельно-последовательный (ослабленная связь) |
Приемник передаваемых данных |
Кэш-память или оперативная память |
Инициатор передачи данных |
Процесс-последователь или процесс-предшественник |
Операционная система (ОС), управление |
Копии ОС и общая надстройка,
смешанное |
Пространственное размещение элементов структуры |
В одном блоке, в одной стойке и т.д. (в одном помещении) |
Самостоятельная работа № 41
Организация вычислений в вычислительных системах
Распределённая ОС, динамически и автоматически распределяя работы по различным машинам системы для обработки, заставляет набор сетевых машин обрабатывать информацию параллельно. Пользователь распределённой ОС, вообще говоря, не имеет сведений о том, на какой машине выполняется его работа.[1]
Распределённая ОС существует как единая операционная система в масштабах вычислительной системы. Каждый компьютер сети, работающей под управлением распределённой ОС, выполняет часть функций этой глобальной ОС. Распределённая ОС объединяет все компьютеры сети в том смысле, что они работают в тесной кооперации друг с другом для эффективного использования всех ресурсов компьютерной сети.
В результате сетевая ОС может рассматриваться как набор операционных систем отдельных компьютеров, составляющих сеть. На разных компьютерах сети могут выполняться одинаковые или разные ОС. Например, на всех компьютерах сети может работать одна и та же ОС UNIX. Более реалистичным вариантом является сеть, в которой работают разные ОС, например, часть компьютеров работает под управлением UNIX, часть — под управлением NetWare, а остальные — под управлением Windows NT и Windows 98. Все эти операционные системы функционируют независимо друг от друга в том смысле, что каждая из них принимает независимые решения о создании и завершении своих собственных процессов и управлении локальными ресурсами. Но в любом случае операционные системы компьютеров, работающих в сети, должны включать взаимно согласованный набор коммуникационных протоколов для организации взаимодействия процессов, выполняющихся на разных компьютерах сети, и разделения ресурсов этих компьютеров между пользователями сети.
Если операционная система отдельного компьютера позволяет ему работать в сети, и может предоставлять свои ресурсы в общее пользование и/или использовать ресурсы других компьютеров сети, то такая операционная система отдельного компьютера также называется сетевой ОС.
Таким образом, термин «сетевая операционная система» используется в двух значениях: как совокупность ОС всех компьютеров сети и как операционная система отдельного компьютера, способного работать в сети. Из этого определения следует, что такие операционные системы, как, например, Windows NT, NetWare, Solaris, HP-UX, являются сетевыми, поскольку все они обладают средствами, которые позволяют их пользователям работать в сети.
Самостоятельная работа № 42
Перспективные развития современных ЭВМ
Основу любого процессора составляет полупроводниковый вентильный элемент -- транзистор. Принцип работы его известен из школьного курса физики. Транзистор позволяет управлять электрическим сопротивлением проводника при помощи электрического тока, проходящего через базу (биполярный транзистор), или электрического напряжения, подаваемого на затвор (полевой транзистор). Если ввести обратную связь, то есть подать часть выходного сигнала транзистора на его вход, то можно заставить прибор работать в двух стабильных состояниях, которые соответствуют логическим 0 и 1.
На основе двух транзисторов можно создать ячейку, информационная емкость которой будет равна 1 биту. Восемь таких ячеек имеют информационную емкость, равную одному байту. Легко подсчитать, сколько транзисторов должны иметь микросхемы, способные хранить и обрабатывать информацию в сотни мегабайт. Причем для корректной работы схемы все транзисторы должны работать синхронно.
А вот здесь начинаются ограничения. Электрон -- носитель электрического заряда и, как следствие, основной переносчик информации, хоть и является с точки зрения квантовой физики частицей легкой, все-таки имеет некоторую массу, а следовательно и инерционность. Его нельзя мгновенно остановить или мгновенно привести в движение. Скорость одного конкретного электрона неизвестна. Можно говорить только об общих статистических закономерностях поведения некоторой достаточно большой группы электронов. А большая группа -- это еще большая масса, для разгона или остановки которой нужно время и энергия.
При движении любой заряженной частицы возникает электромагнитное поле. На создание этого поля также расходуется энергия, которая в конечном счете приводит к нагреванию кристалла, что тоже грозит неприятностями. Волновые и резонансные свойства проводников на высоких частотах -- отдельный вопрос, которого касаться не будем. Поэтому существуют различные проекты по созданию транзистора без электрона, о которых мы поговорим позднее.
Ну а пока потребность в более быстрых, дешевых и универсальных процессорах вынуждает производителей постоянно наращивать число транзисторов в них. Однако этот процесс не бесконечен. Поддерживать экспоненциальный рост этого числа, предсказанный Гордоном Муром в 1973 году, становится все труднее. Специалисты утверждают, что этот закон перестанет действовать, как только затворы транзисторов, регулирующие потоки информации в чипе, станут соизмеримыми с длиной волны электрона(в кремнии, на котором сейчас строится производство, это порядка 10 нанометров). И произойдет это где-то между 2010 и 2020 годами. По мере приближения к физическому пределу архитектура компьютеров становится все более изощренной, возрастает стоимость проектирования, изготовления и тестирования чипов. Таким образом, этап эволюционного развития рано или позно сменится революционными изменениями.
В результате гонки наращивания производительности возникает множество проблем. Наиболее острая из них - перегрев в сверхплотной упаковке, вызванный существенно меньшей площадью теплоотдачи. Концентрация энергии в современных микропроцессорах чрезвычайно высока. Нынешние стратегии рассеяния образующегося тепла, такие как снижение питающего напряжения или избирательная активация только нужных частей в микроцепях малоэффективны, если не применять активного охлаждения.
С уменьшением размеров транзисторов стали тоньше и изолирующие слои, а значит, снизилась и их надежность, поскольку электроны могут проникать через тенкие изоляторы(туннельный эффект). Данную проблему можно решить снижением управляющего напряжения, но лишь до определенных пределов.
Технология SOI(Silicon On Insulator) уменьшила емкость соединений и улучшила характеристики транзисторов. Это позволило снизить управляющее напряжения, но возросла и стоимость изготовления, увеличился процент брака, снизилась устойчивость всей системы к ошибкам. Альтернативное направление - переход на арсенид галлия, который позволяет получить более быстрые тарнзисторы N-типа, однако, к сожалению, столь же важные транзисторы P-типа получаются более медленными, если не использовать высокоэнергетические уровни, что делает их непригодными для массового производства. Поэтому кремниевая технология должна пережить еще несколько поколений процессоров.
Еще одна проблема заключается в том, что со снижением размеров уменьшается скорость срабатывания транзисторов и перестает соответствовать скорости распространения сигнала по внутрисхемным соединениям. Более тонкие проводники, соединяющие транзисторы, имеют и более высокое сопротивление, а значит и - неприемлимо высокую задержку распространения сигнала. С каждым новым поколением процессоров пропускная способность межэлементных соединений падала, поскольку возрастали сопротивление и емкость. Эта проблема была отчасти решена путем использования многослойных соединений. Например, у процессора Pentium 4 семь слоев разводки цепей, причем каждый имеет собственный рисунок и расположен внутри изолирующего материала. В нем оставляют "окна", которые заполняют металлом(медью), формируя электрические соединения между слоями. Микропроцессор при этом делится на блоки, что ограничивает сигналы локалбными маштабами блока и снижает задержки. Толстые проводники с малой задержкой сигнала соединяют компоненты, далеко отстоящие друг от друга, а тонкие - соседние компоненты.
В качестве материала межсоединений медь окончательно и бесповоротно придет на смену алюминию, так как у нее ниже удельное сопротивление. Однако она подвержена диффузии в кремнии, что потребует изоляции медных соединений. Возможно, на смену диоксиду кремния придет какой-нибудь иной изоляционный материал, например, синтезированный на основе обычного стекла, что позволит снизить емкость межсоединений. Более решительным шагом может стать использование в качестве межсоединений сверхпроводящих материалов, но пока не найдено такого материала, который показал бы нужные свойства в условиях температуры и тока, характерных для интегральных схем. Другой подход - применение оптических внутрисхемных соединений, хотя здесь вступабт в силу ограничения по размерам (волокна не должны быть тоньше длины волны света, который они передают), к тому же требуется преобразование световых импульсов в электрические и наоборот, что может серьезно снизить общую производительность. Перспективными в данном направлении представляются результаты, полученные британскими учеными: оперируя на атомном уровне, они смогли сделать некоторые области кремниевой подложки светоизлучающими. Обычные светоизлучающие устройства встроить в кремниевые чипы невозможно, но если для передачи данных использовать "естественный" свет подложки, это позволит передавать сигналы быстрее и сделает чипы еще более миниатюрными.
На сегодняшний день основное условие повышения производительности процессоров - методы параллелизма. Как известно, микропроцессор обрабатывает последовательность инструкций(команд), составляющих ту или иную программу. Если организовать параллельное(то есть одновременное) выполнение инструкций, общая производительность существенно вырастет. Решается проблема параллелизма методами конвейеризации вычислений, применением суперскалярной архитектуры и предсказанием ветвлений.
Конвейеризация - процесс, посредством которого различные фазы обработки накладываются по времени одна на другую. Это означает разбиение инструкций на отдельные операции и исполнение получившихся микроинструкций различными элементами процессора. Однако разбиение инструкций и контроль за исполнением каждого шага усложняет управляющие цепи и требует на каждом шаге памяти для временного хранения промежуточных данных (конвейерные регистры).
Дальнейшее развитие этой идеи - суперскалярная архитектура, позволяющая выполнять ряд инструкций параллельно. Для этого часть транзисторов используется в качестве "дублеров" отдельных частей процессора.
Ветвление инструкций подразумевает исполнение той части программы(ветви), которая не следует непосредственно за последней исполненой инструкцией. Переход на ту или иную ветвь может быть безусловным (выполняется всегда) или условным(в зависимости от некоторого условия).
Теперь попробуем посмотреть по какому пути пойдет развитие архитектуры ЭВМ в ближайшем будущем.
Суперскалярная архитектура
Суперскалярные процессоры конца 90-х годов могли исполнять до 4-6 инструкций за один машинный цикл. На практике они выполняют в среднем 1,5 инструкции за такт. "Продвинутые" суперскалярные процессоры (Advanced superscalar) смогут выполнять от 16 до 32 инструкций за такт. Чем это обернется на практике, пока сказать трудно, но и для "суперскалярной" архитектуры существенным ограничением является поток обрабатываемых данных.
В общем виде "продвинутая" суперскалярная архитектура состоит из 24-48 высокооптимизированных конвейерных блоков(например, блоков, выполняющих операции с плавающей точкой или обрабатывающих целые числа). Как и в простых суперскалярных архитектурах, каждый блок получает свою собственную "резервацию" - временное место хранения, где накапливается очередь инструкций, выполняемых данным блоком.
Для сокращения доступа к памяти предполагается использовать наряду с обычным кешем так называемый "трассирующий" кеш, который объединяет логически смежные блоки в физически смежные хранилища.
Более совершенное предсказание ветвлений - еще одна задача ближайшего будущего, и она тесно связана с предсказанием адресации: процессор попытается предсказать адреса ячеек памяти, которые будут затребованы последующими инструкциями, и вызвать их содержимое заранее. Для того чтобы чнизить эффет задержки сигналов в соединениях, предполагается сгруппировать их в кластеры.
Суперспекулятивная архитектура
Эта архитектура подразумевает предсказание как ветвлений, так и данных. Это означает, что предсказываются адреса ячеек памяти и хранящиеся в них величины. Один из способов достичь этого - пошаговое предсказание: обнаружив постоянное приращение в величинах данных и адресах памяти(шаги), можно "догадаться" о будущих величинах, используемых вычислениях(такое может происходить в циклах или матрицах).
Основное преимущество таких архитектур в том, что они не требуют изменений в компиляторах, да и программный код должен выполняться быстрее. Они должны выполнять по 10 инструкций за один машинный такт. С другой стороны, дизайн процессора в этом случае более сложный, и то, что он не делится на блоки, может вызвать проблемы с задержкой сигналов.
Трассирующая архитектура
В обычных архитектурах иснтрукция представляет собой исполняемую единицу. В трассирующих процессорах исполняемая единица - "трасса" - последовательность инструкций. Каждый маршрут передается своему суперскалярному процессорному элементу, апоминающему суперскалярный микропроцессор и имеющему собственный набор локальных и глобальных регистров, что обеспечивает как внутримаршрутный, так и межмаршрутный параллелизм.
Применение трассирующих процессоров способствует решению проблемы задержек сигналов в межсоединениях, однако требует соответствующего кеша, что увеличивает его архитектурную сложность. Более того, это никак не решает проблему увеличения скорости обращения к памяти.
IRAM
Буква 'I' здесь означает 'intelligent'. Возможно, это один из наиболее радикальных шагов в области архитектуры, направленный на ускорение доступа к памяти и снижения энергопотребления. Согласно IRAM большая яасть RAM перемещается непосредственно на чип, исключая необходимость в кеше. Низкое энергопотребление означает, что данная архитектурабольше всего подходит для мобильных компьютеров. Однако тот факт, что максимальное количество памяти, которое можно перенести на чип, составляет всего 96 Мбайт, лишает эту архитектуру надежд на широкое использование.
Квантовая архитектура
В основе квантовых вычислений лежит атом - мельчайшая единица вещества. Квантовые вычисления принципиально отличаются от традиционных, так как на атомном уровне в силу вступают законы квантовой физики. Один из них - закон суперпозиции: квант может находиться в двух состояниях одновременно. Обычно бит может иметь значение либо 1, либо 0, а квантовы бит(qubit) может быть еденицей и нулем одновременно.
Атом - "удобное" хранилище информационных битов: его электроны могут занимать лишь ограниченное число дискретных энергетических уровней. Так, атом высокого энергетического уровня мог бы служить логической единицей, а низкого - логическим нулем. Очевидным недостатком здесь является нестабильность атома, поскольку он легко меняет энергетический уровень в зависимости от внешних условий.
Поскольку управлять энергетическим уровнем одного атома нереально, предполагается использовать длинные молекулы (цепи из миллиардов атомов) таким образом, чтобы величину их содержимого можно было менять путем бомбардировки первого атома в цепи лазерным лучем. Длинные молекулы тоже весьма нестабильны, и их надо хранить при сверхнизкой температуре. Да и сбор данных требует весьма сложного оборудования, так что до массового производства подобных систем еще далеко.
Нейроархитектура
Для решения некоторых задач требуется создание эффективной системы искусственного интеллекта, которая могла бы обрабатывать информацию, не затрачивая много вычислительных ресурсов. Мозг и нервная система живых организмов позволяют решать задачи упраления и эффективно обрабатывать сенсорную информацию, а это огромный плюс для создаваемых вычислительных систем. Именно это послужило предпосылкой создания искусственных вычислительных систем на базе нейронных систем живого мира.
Создание компьютера на основе неронных систем живого мира базируется на теории перцептронов, разработчиком которой был Розенблатт. Он предложил понятие перцептрона - искусственной нейронной сети, которая может обучаться распознаванием образов.
Перспективность создания компьютеров по теории Розенблатта состоит в том, что структуры, имеющие свойства мозга и нервной системы, имеют ряд особенностей, которые помогают при решении сложных задач: 1. Параллельность обработки информации. 2. Способность к обучению. 3. Способность к автоматической классификации. 4. Высокая надежнлсть. 5. Ассоциативность.
Нейрокомпьютеры(биокомпьютерф) - это совершенно новый тип вычислительной техники. Их можно строить на базе нейрочипов, которые функционально ориентированы на конкретный алгоритм, на решение конкретной задачи. Для решения задач разного типа требуется нейронная сеть разной топологии(топология - специальное расположение вершин, в данном случае нейрочипов и пути их соединения).
Нейронные вычисления отличаются от классических представлением и обработкой информации. Любая задача ставиться как поиск соответствия между множествами входных и выходных данных, представляемых в виде векторов n-мерного пространства, принадлежащего некоторой предметной области. Входные вектора подаются на входные нейроны, а выходная реакция снимается с выходов элементов нейронной сети. При этом вычислительные процессы представляют собой параллельные взаимодействия между нейронами через нейронные связи и преобразование данных в нейронах. Соответствие между входными воздействиями и выходной реакцией устанавливается через процедуру обучения, которая определяется для каждой модели нейронных сетей отдельно. Возможность обучения нейронных сетей является важнейшей особенностью нейросетевого подхода к построению систем обработки информации.
Самостоятельная работа №43
Изучение классификации вычислительных сетей
Для классификации компьютерных сетей используются различные признаки, но чаще всего сети делят на типы по территориальному признаку. В связи с этим выделяют локальные, глобальные и городские сети.
К локальным сетям — Local Area Networks (LAN) — относят сети компьютеров, сооединенные на небольшой территории (в радиусе не более 1-2 км). Из-за малых расстояний в локальных сетях используются дорогие высококачественные линии связи, которые позволяют достигать высоких скоростей обмена данными (более 100 Мбит/с). В связи с этим услуги, предоставляемые локальными сетями, отличаются широким разнообразием и обычно предусматривают реализацию в режиме on-line.
Глобальные сети — Wide Area Networks (WAN) — объединяют территориально рассредоточенные компьютеры, которые могут находиться в различных городах и странах. Поэтому в глобальных сетях часто используются уже существующие линии связи, предназначенные совсем для других целей (телефонные и телеграфные каналы). Из-за низких скоростей таких линий связи в глобальных сетях (десятки килобит в секунду) набор предоставляемых услуг обычно ограничивается передачей файлов, преимущественно не в оперативном, а в фоновом режиме с использованием электронной почты. Для устойчивой передачи дискретных данных по некачественным линиям связи применяются методы и оборудование, существенно отличающиеся от таковых для локальных сетей. Как правило, здесь применяются сложные процедуры контроля и восстановления данных, так как наиболее типичный режим передачи данных по территориальному каналу связи связан со значительными искажениями сигналов.
Городские сети (или сети мегаполисов) — Metropolitan Area Networks (MAN) — занимают промежуточное положение и включают в себя черты локальных и глобальных сетей. Они используют цифровые магистральные линии связи, часто оптоволоконные, и предназначены для связи локальных сетей в масштабах города и соединения локальных сетей с глобальными. Развитие технологии сетей мегаполисов осуществлялось местными телефонными компаниями.
Рассмотрим основные отличия локальных сетей от глобальных (однако в последнее время эти отличия становятся менее заметными).
Протяженность, качество и способ прокладки линий связи. Локальные вычислительные сети отличаются от глобальных сетей небольшим расстоянием между узлами сети. Это делает возможным использование в локальных сетях качественных линий связи: коаксиального кабеля, витой пары, оптоволоконного кабеля, которые не всегда доступны на больших расстояниях, свойственных глобальным сетям. В глобальных сетях часто применяются уже существующие линии связи (телеграфные или телефонные), а в локальных сетях они прокладываются заново.
Сложность методов передачи и оборудования. В условиях низкой надежности физических каналов в глобальных сетях требуются более сложные, чем в локальных сетях, методы передачи данных и соответствующее оборудование. Так, в глобальных сетях широко применяются модуляция, асинхронные методы, сложные методы контрольного суммирования, квитирование и повторные передачи искаженных кадров. С другой стороны, качественные линии связи в локальных сетях позволили упростить процедуры передачи данных за счет применения немодулированных сигналов и отказа от обязательного подтверждения получения пакета.
Скорость обмена данными. Одним из главных отличий локальных сетей от глобальных является наличие высокоскоростных каналов обмена данными между компьютерами (10 и 100 Мбит/с). Для глобальных сетей типичны гораздо более низкие скорости передачи данных — 56 и 64 Кбит/с и только на магистральных каналах — до 2 Мбит/с.
Разнообразие услуг. Локальные сети предоставляют, как правило, широкий набор услуг — это различные виды услуг файловой службы, печати, услуги службы передачи факсимильных сообщений, услуги баз данных, электронная почта и другие. Глобальные сети в основном предоставляют почтовые и иногда файловые услуги с ограниченными возможностями.
Оперативность выполнения запросов. Время прохождения пакета через локальную сеть обычно составляет несколько миллисекунд, время же его передачи через глобальную сеть может достигать нескольких секунд. Низкая скорость передачи данных в глобальных сетях затрудняет реализацию служб для режима on-line, который является обычным для локальных сетей.
Разделение каналов. В локальных сетях каналы связи используются, как правило, совместно сразу несколькими узлами сети, а в глобальных сетях — индивидуально.
Использование метода коммутации пакетов. Важной особенностью локальных сетей является неравномерное распределение нагрузки (пульсирующий трафик). Из-за этой особенности трафика в локальных сетях для связи узлов применяется метод коммутации пакетов, который для пульсирующего трафика оказывается гораздо более эффективным, чем традиционный для глобальных сетей метод коммутации каналов.
Масштабируемость. Локальные сети обладают плохой масштабируемостью из-за жесткости базовых топологий, определяющих способ подключения станций и длину линии. При использовании многих базовых топологий характеристики сети резко ухудшаются при достижении определенного предела по количеству узлов или протяженности линий связи. Глобальным же сетям характернахорошая масштабируемость, так как они изначально разрабатывались в расчете на работу с произвольными топологиями.
В настоящее время в мире локальных и глобальных сетей явно наметилось движение навстречу друг другу, которое уже сегодня привело к значительному взаимопроникновению технологий локальных и глобальных сетей.
Одним из проявлений этого сближения является появление сетей масштаба большого города (MAN), занимающих промежуточное положение между локальными и глобальными сетями. При достаточно больших расстояниях между узлами они обладают качественными линиями связи и высокими скоростями обмена, даже более высокими, чем в классических локальных сетях.
Сближение в методах передачи данных происходит на платформе оптической цифровой (немодулированной) передачи данных по оптоволоконным линиям связи. Из-за резкого улучшения качества каналов связи в глобальных сетях начали отказываться от сложных и избыточных процедур обеспечения корректности передачи данных. В результате скорости передачи данных в уже существующих коммерческих глобальных сетях нового поколения приближаются к традиционным скоростям локальных сетей (в сетях frame relay 2 Мбит/с), а в глобальных сетях ATM - 622 Мбит/с.
В локальных сетях в последнее время уделяется такое же большое внимание методам обеспечения защиты информации от несанкционированного доступа, как и в глобальных сетях. Такое внимание обусловлено тем, что локальные сети перестали быть изолированными, чаще всего они имеют выход в глобальные сети. При этом часто используются те же методы — шифрование данных, аутентификация пользователей, возведение защитных барьеров, предохраняющих от проникновения в сеть извне.
И, наконец, появляются новые технологии, изначально предназначенные для обоих видов сетей. Наиболее ярким представителем нового поколения технологий является технология ATM, которая может служить основой не только локальных и глобальных компьютерных сетей, но и телефонных сетей, а также широковещательных видеосетей, объединяя все существующие типы трафика в одной транспортной сети.
Еще одним популярным способом классификации сетей является их классификация по масштабу производственного подразделения, в пределах которого действует сеть. Различают сети отделов, сети кампусов и корпоративные сети.
Сети отделов — это сети, которые используются сравнительно небольшой группой сотрудников, работающих в одном отделе предприятия. Эти сотрудники решают некоторые общие задачи. Сети отделов обычно не разделяются на подсети и являются однородными (одна сетевая технология и сетевая ОС).
Существует и другой тип сетей — сети рабочих групп. К таким сетям относят совсем небольшие сети, включающие до 10-20 компьютеров. Характеристики рабочих групп практически не отличаются сетей отделов, однако простота сети и однородность здесь проявляются в наибольшей степени.
Сети кампусов - сети любых предприятий и организаций, которые объединяют множество сетей различных отделов одного предприятия в пределах отдельного здания или в пределах одной территории, покрывающей площадь несколько квадратных километров. Глобальные соединения в сетях кампусов не используются. Важной службой, предоставляемой сетями кампусов, стал доступ к корпоративным базам данных независимо от того, на каких типах компьютеров они располагаются.
В этих сетях возникают проблемы интеграции неоднородного аппаратного и программного обеспечения.
Корпоративные сети называют также сетями масштаба предприятия. Эти сети объединяют большое количество компьютеров на всех территориях отдельного предприятия. Они могут покрывать город, регион и даже континент. Расстояния между сетями отдельных территорий могут оказаться такими, что становится необходимым использование глобальных связей. Для соединения удаленных локальных сетей и отдельных компьютеров в корпоративной сети применяются разнообразные телекоммуникационные средства, в том числе телефонные каналы, радиоканалы, спутниковая связь.
Непременным атрибутом такой сложной и крупномасштабной сети является высокая степень гетерогенности. В корпоративной сети обязательно используются различные типы компьютеров — отмэйнфреймов до ПК, несколько типов операционных систем и множество различных приложений.
Самостоятельная работа № 44
Принципы построения локальных вычислительных сетей
Обмен информацией в ЛВС осуществляется согласно определенным правилам. Такие правила именуются протоколами. Разные протоколы описывают различные стороны одного и того же типа связи. Взятые вместе, они образуют стек протокола. Компьютеры, входящие в Локальную Вычислительную сеть, можно соединить между собой разными способами.
Можно выделить четыре основных топологии:
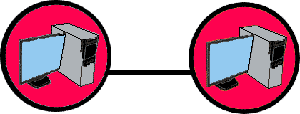
1) Первая и самая простая топология сети – это сеть типа «Точка - Точка». При такой организации, сеть состоит из двух компьютеров, непосредственно подключенных друг к другу. Достоинством такой организации сети является простота и относительная дешевизна, недостатком же является то, что соединить таким образом можно всего два компьютера.
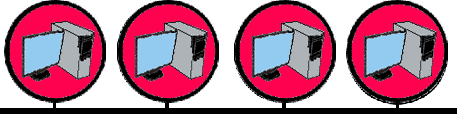
2) Вторая топология сети – это сеть типа «Шина». При такой организации, сеть состоит из нескольких компьютеров, каждый из которых подключен к общей для сети шине передачи данных. В роли шины может выступать коаксиальный кабель. Главным недостатком такой организации является то, что при обрыве шины все узлы сети теряют связь. Если необходимо подключить еще один узел в сеть, то на время монтажных работ связь также будет утеряна
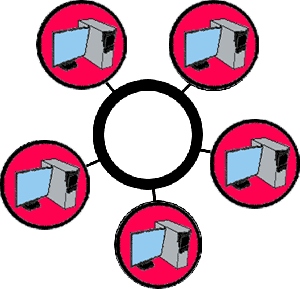
3) Третья топология сети – это сеть типа «Кольцо». При такой организации, сеть состоит из нескольких компьютеров, каждый из которых подключен к кабелю, замкнутому в кольцо. Сигнал передается по кольцу в одном направлении и проходит от компьютера к компьютеру. При этом компьютер, получивший сигнал от соседней машины, усиливает его и передает дальше по кольцу. Это происходит до тех пор, пока сигнал не дойдет до компьютера, которому он адресован. Недостатком такого способа является то, что если хотя бы один из компьютеров перестанет работать, прекращает функционировать вся сеть, да и время передачи сигнала до неоходимой машины заметно увеличивается по сравнению с остальными способами соединения компьютеров в сеть.
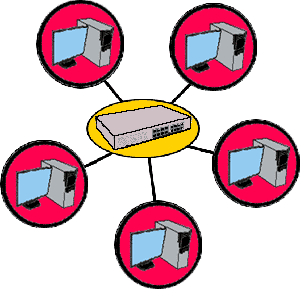
4) Четвертая топология сети – это сеть типа «Звезда». При такой организации, сеть состоит из нескольких компьютеров, каждый из которых подключен к одному и тому же центральному устройству. Такое устройство получило название HUB. Главный недостаток данной топологии заключается в том, что при выходе из строя HUBa остальные узлы теряют связь. Основным достоинством такого соединения является возможность подключать новые узлы к сети не прерывая работу остальных узлов. Из-за этого важного преимущества этого типа сети перед другими, а также из-за относительно низкой себестоимости, такая организация сети является самой распространённой.
Самостоятельная работа № 45
Правила построения вычислительных сетей
Программные и аппаратные компоненты вычислительной сети Вычислительная сеть (далее сеть) - сложная система программных и аппаратных компонентов, взаимосвязанных друг с другом. Среди аппаратных средств можно выделить компьютеры и коммуникационное оборудование. Программные компоненты состоят из операционных систем и сетевых приложений. В настоящее время в сети используются компьютеры различных типов и классов с различными характеристиками. Это основа любой вычислительной сети. Компьютеры, их характеристики определяют возможности вычислительной сети. Но в последнее время и коммуникационное оборудование (кабельные системы, повторители, мосты, маршрутизаторы и др.) стало играть не менее важную роль. Некоторые из этих устройств, учитывая их сложность, стоимость и другие характеристики, можно назвать компьютерами, решающими сугубо специфические задачи по обеспечению работоспособности сетей. ДЛЯ эффективной работы сетей используются специальные операционные системы (ОС), которые, в отличие от персональных операционных систем, предназначены для решения специальных задач по управлению работой сети компьютеров. Это сетевые операционные системы. Сетевые ОС устанавливаются на специально выделенные компьютеры. Cetesbie приложения - это прикладные программные комплексы, которые расширяют возможности сетевых ОС. Среди них можно выделить почтовые программы, системы коллективной работы, сетевые базы данных и др. В процессе развития сетевых ОС некоторые функции сетевых приложений становятся обычными функциями ОС. Все устройства, подключаемые к сети, можно разделить на три функциональные группы: рабочие станции; серверы сети; коммуникационные узлы. Рабочая станция (workstation) - это персональный компьютер, подключенный к сети, на котором пользователь сети выполняет свою работу. Каждая рабочая станция обрабатывает свои локальные файлы и использует свою операционную систему. Но при этом пользователю доступны ресурсы сети. Можно выделить три типа рабочих станций: рабочая станция с локальным диском, бездисковая рабочая станция, удаленная рабочая станция. На рабочей станции с диском (жестким или гибким) операционная система загружается с этого локального диска. Для бездисковой станции операционная система загружается с диска файлового сервера. Такая возможность обеспечивается специальной микросхемой, устанавливаемой на сетевом адаптере бездисковой станции. Удаленная рабочая станция - это станция, которая подключается к локальной сети через телекоммуникационные каналы связи (например, с помощью телефонной сети). Сервер сети (server) - это компьютер, подключенный к сети и предоставляющий пользователям сети определенные услуги, например хранение данных общего пользования, печать заданий, обработку запроса к СУБД, удаленную обработку заданий и т. д. По выполняемым функциям можно выделить следующие группы серверов. Файловый сервер (file server) - компьютер, хранящий данные пользователей сети и обеспечивающий доступ пользователей к этим данным. Как правило, этот компьютер имеет большой объем дискового пространства. Файловый сервер обеспечивает одновременный доступ пользователей к общим данным., Файловый сервер выполняет следующие функций: хранение данных; архивирование данных; согласование изменений данных, выполняемых разными пользователями; передачу данных. Сервер баз данных - компьютер, выполняющий функции хранения, обработки и управления файлами баз данных (БД). Сервер баз данных выполняет следующие функции: хранение баз данных, поддержку их целостности, полноты, актуальности; прием и обработку запросов к базам данных, а также пересылку результатов обработки на рабочую станцию; обеспечение авторизированного доступа к базам данных, поддержку системы ведения и учета пользователей, разграничение доступа пользователей; согласование изменений данных, выполняемых разными пользователями; поддержку распределенных баз данных, взаимодействие с другими серверами баз данных, расположенными в другом месте. Сервер прикладных программ (application server) - компьютер, который используется для выполнения прикладных программ пользователей. Коммуникационный сервер (communications server) - устройство или компьютер, который предоставляет пользователям локальной сети прозрачный доступ к своим последовательным портам ввода/вывода. С помощью коммуникационного сервера можно создать разделяемый модем, подключив его к одному из портов сервера. Пользователь, подключившись к коммуникационному серверу, может работать с таким модемом так же, как если бы модем был подключен непосредственно к рабочей станции. Сервер доступа (access server) - это выделенный компьютер, позволяющий выполнять удаленную обработку заданий. Программы, инициируемые с удаленной рабочей станции, выполняются на этом сервере. От удаленной рабочей станции принимаются команды, введенные пользователем с клавиатуры, а возвращаются результаты выполнения задания. Факс-сервер (fax server) - устройство или компьютер, который выполняет рассылку и прием факсимильных сообщений для пользователей локальной сети. Сервер резервного копирования данных (back up server) - устройство или компьютер, который решает задачи создания, хранения и восстановления копий данных, расположенных на файловых серверах и рабочих станциях. В качестве такого сервера может использоваться один из файловых серверов сети. Следует отметить, что все перечисленные типы серверов могут функционировать на одном выделенном для этих целей компьютере. К коммуникационным узлам сети относятся следующие устройства: повторители; коммутаторы (мосты); маршрутизаторы; шлюзы. Протяженность сети, расстояние между станциями в первую очередь определяются физическими характеристиками передающей среды (коаксиального кабеля, витой пары и т. д.). При передаче данных в любой среде происходит затухание сигнала, что и приводит к ограничению расстояния. Чтобы преодолеть это ограничение и расширить сеть, устанавливают специальные устройства - повторители, мосты и коммутаторы. Часть сети, в которую не входит устройство расширения, принято называть сегментом сети. Повторитель (repeater) - устройство, усиливающее или регенерирующее пришедший на него сигнал. Повторитель, приняв пакет из одного сегмента, передает его во все остальные. При этом повторитель не выполняет развязку присоединенных к нему сегментов. В каждый момент времени во всех связанных повторителем сегментах поддерживается обмен данными только между двумя станциями. Коммутатор (switch), или мост (bridge) - это устройство, которое, как и повторитель, позволяет объединять несколько сегментов. В отличие от повторителя, мост выполняет развязку присоединенных к нему сегментов, то есть одновременно поддерживает несколько процессов обмена данными для каждой пары станций разных сегментов. Маршрутизатор (router) - устройство, соединяющее сети одного или разных типов по одному протоколу обмена данными. Маршрутизатор анализирует адрес назначения и направляет данные по оптимально выбранному маршруту. Шлюз (gateway) - это устройство, позволяющее организовать обмен данными между разными сетевыми объектами, использующими разные протоколы обмена данными.
Основные требования, предъявляемые к современным вычислительным сетям Вычислительная сеть создается для обеспечения потенциального доступа к любому ресурсу сети для любого пользователя сети. Качество доступа к ресурсу как глобальная характеристика функционирования сети может быть описана многими показателями, выбор которых зависит от задач, стоящих перед вычислительной сетью.
Среди основных показателей можно выделить следующие: производительность; надежность; управляемость; расширяемость; прозрачность.