

Правила
Альтернативой использованию ограничения CHECK является создание объекта типа Rule для ограничения значений, которые можно поместить или изменить в колонке. Rule-объект аналогичен Default-объекту в том, что он создаётся отдельно от таблицы и не удаляется при удалении таблицы. Следует также выполнить привязку Rule-объекта к колонке или к определённому пользователем типу – в данном случае – с помощью системной хранимой процедуры sp_bindrule. И, подобно Default-объекту, Rule-объекты включены в SQL Server для обратной совместимости с предыдущими версиями. Использование ограничения CHECK является предпочтительным методом ограничения значений колонок, но Rule-объекты полезно использовать, когда одно правило нужно использовать для нескольких колонок или определенных пользователем типов.
Создание Rule-объекта с помощью t-sql
В качестве примера мы создадим Rule-объект, который выполняет ту же функцию, что и ограничение CHECK, созданное ранее. Правило использует имя переменной @price для ссылки на колонку price таблицы items. Имя переменной должно начинаться с символа «@», а имя можете выбрать произвольно. Сначала создадим данное правило и затем выполним его привязку к колонке:
CREATE RULE price_rule AS
(@price >= .01 AND @price <= 500.00)
GO
sp_bindrule 'price_rule', 'items.price', 'futureonly'
GO
Для отмены привязки правила и его удаления используется следующий оператор:
sp_unbindrule 'items.price'
GO
DROP RULE price_rule
GO
Для процедур sp_bindrule и sp_unbindrule указываются те же параметры, что и для процедур sp_bindefault и sp_unbindefault. Каждая колонка или определённый пользователем тип может иметь только одно правило, хотя можно одновременно присвоить одной колонке или определённому пользователем типу правило и одно или несколько ограничений CHECK. Если это сделано, то SQL Server будет применять правило и все ограничения к данным таблицы при их вставке или обновлении.
Лекция 06: Создание и использование индексов Что такое индекс?
Индекс – это вспомогательная структура данных, используемая системой SQL Server для доступа к данным. В зависимости от типа индекса он хранится вместе с данными или отдельно от данных. Независимо от типа все индексы действуют одинаковым в своей основе способом.
В системах без индексов весь поиск данных должен выполняться путём сканирования таблиц. При сканировании таблиц приходится читать все данные и сравнивать их с запрашиваемыми данными. Обычно стараются обойтись без сканирования таблиц – из-за количества операций ввода-вывода, которое для этого требуется: сканирование больших таблиц может занимать длительный период времени и требовать использования большого количества системных ресурсов. Используя индекс, можно кардинально снизить количество операций ввода-вывода, ускорив доступ к данным и освободив системные ресурсы для других операций.
Индекс базы данных организован в виде структуры B-дерева. Каждая страница индекса называется индексной страницей, или узлом индекса. Структура индекса начинается на верхнем уровне с корневого узла. Корневой узел соответствует началу индекса: это первые данные, к которым осуществляется доступ при поиске данных. Корневой узел содержит ряд строк индекса. Эти строки содержат значение ключа и указатель на определённую индексную страницу, которая называется узлом-ветвью (рис. 6.1). Эта конфигурация необходима, поскольку в случае таблицы данных среднего масштаба индекс состоит из тысяч или миллионов индексных страниц. Начав поиск с корневого узла и перемещаясь по узлам индекса, SQL Server может постепенно «приближаться» к нужным данным.
Если использовать в качестве аналога книгу, то индекс действует следующим образом: предположим, что началом индекса (алфавитного указателя) является страница, где указаны номера страниц для статей индекса на букву «a», «b», «c» и т.д. Затем предположим, что эти страницы содержат номера страниц для статей в диапазонах aa-ab, ас-ad, ae-af и т.д., а соответствующие страницы – номера страниц для записей в диапазонах aaa-aab, aас-aad, aae-aaf и т.д. При подобной организации можно быстро найти то, что нужно, с использованием относительно небольшого количества операций поиска. Такая структура аналогична индексу таблицы базы данных, когда первой страницей является корневой узел.
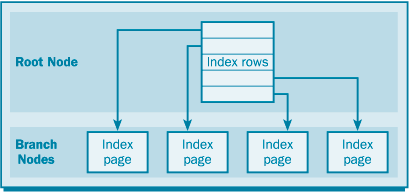
рис. 6.1. Корневой узел и узлы-ветви
Как и корневой узел, каждый узел-ветвь содержит ряд индексных строк в структуре индексной страницы. Каждая индексная строка указывает на другой узел-ветвь или на узел-лист (конечный узел) (рис. 6.2). Узел-лист является последним уровнем индекса. В отличие от корневого узла каждый узел-ветвь содержит также связанный список узлов-ветвей того же уровня. Иными словами, узел «знает» о смежных узлах и об узлах более низкого уровня.
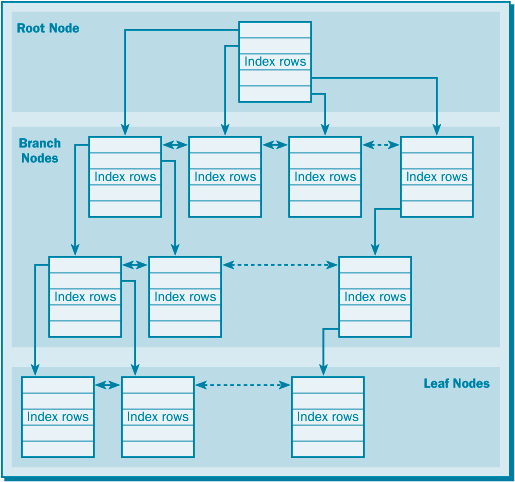
рис. 6.2. Дерево поиска с узлами-ветвями и узлами-листьями
Как следует из названия «B-дерево», узлы-ветви разветвляются от корневого узла в древовидной форме. Каждая группа узлов-ветвей одного уровня в древовидной структуре называется уровнем индекса (рис. 6.3). Количество операций ввода-вывода, которое требуется для достижения узлов-листьев (узлов самого нижнего уровня дерева), зависит от количества уровней индекса. Если таблица базы данных содержит лишь небольшое количество данных, то корневой узел может указывать непосредственно узлы-листья, и тогда для индекса вообще не требуется никаких узлов-ветвей (маловероятная ситуация).

рис. 6.3. Уровни индекса
В некластеризованном индексе узел-лист содержит значение ключа, а также идентификатор строки (Row ID), указывающий нужную строку в таблице, или ключ кластеризованного индекса, если имеется также кластеризованный индекс по этой таблице. А в кластеризованном индексе в узле-листе находятся сами данные. Количество строк в узле-листе зависит от размера индексных записей, а в случае кластеризованного индекса – от размера данных.
Row ID – это указатель, который автоматически формируется системой SQL Server из идентификатора файла (File ID), номера страницы и номера строки данных. Используя Row ID, вы можно считывать данные с помощью всего лишь одной дополнительной операции ввода-вывода. Поскольку вы знаете, какую страницу нужно считывать, а SQL Server «знает», где эта страница находится, то она считывается в память с помощью единственного запроса ввода-вывода. Именно простота этого процесса определяет эффективность использования индексов для считывания данных и обеспечивает столь значительное повышение производительности.
Поскольку индекс создаётся в отсортированном порядке, любые изменения в данных могут приводить к дополнительной нагрузке на систему. Например, если вставка приводит к созданию новой строки индекса, которую нужно поместить в узел-лист, который уже заполнен до конца, то SQL Server должен создать место для новой строки индекса. Он выполняет эту задачу, перемещая приблизительно половину строк узла-листа на другую страницу. Это перемещение данных называется расщеплением страницы. Расщепление страницы на одном уровне дерева может приводить к каскадным расщеплениям на более высоких уровнях. Расщепления страниц можно избежать путём соответствующей настройки коэффициента заполнения.