

Вопрос №1
Базы данных (БД) — это организованный набор фактов в определенной предметной области. БД — это информация, упорядоченная в виде набора элементов, записей одинаковой структуры. Для обработки записей используются специальные программы, позволяющие их упорядочить, делать выборки по указанному правилу. Базы данных относятся к компьютерной технологии хранения, поиска и сортировки информации.
БД — это совокупность взаимосвязанных данных при предельно малой избыточности, допускающей их оптимальное использование в определённых областях человеческой деятельности. БД, в зависимости от способа представления данных и отношений между ними, могут иметь реляционную (таблицы связаны между собой), сетевую или иерархическую структуры. На эффективность БД с той или иной структурой влияют условия её применения. Данные в БД организованы, как правило, в виде таблиц. Табличный способ отображения информации широко используется в документах и отчётах, поскольку он удобен и позволяет наглядно представлять различного рода данные.
Пример простейшей базы данных в виде таблицы:
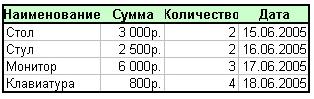
В БД может храниться миллионы записей. В любое время можно найти запись, которая необходима в данный момент. Результатом поиска информации в приведенной БД могут быть названия, суммы, количество, даты. В базах данных можно проводить сортировку информации и вывод её на печать, удаление старой и вставка новой информации, просматривать БД целиком или по частям. С числами в таблицах можно проводить обычные математические операции. Фамилии людей и названия предметов можно упорядочить по алфавиту.
Программное обеспечение для управления и поддержки работоспособности БД называют системой управления базами данных (СУБД). СУБД осуществляют ввод, проверку, систематизацию, поиск и обработку данных, распечатку их в виде отчётов.
Среди множества СУБД наиболее часто используются пакеты программ dBASE разных версий, FoxBase +, FoxPro, Fox Soft Ware, Clipper, совместимые с dBASE по системе команд и файлам.
Например, БД, созданная в одной СУБД, может использоваться в другой совместимой с ней СУБД, имеющей формат файлов dBASE (*.dbf). Однако есть иные СУБД, например PARADOX и RBase, несовместимые с dBASE. Кроме СУБД для DOS, существуют СУБД, работающие в среде Windows, например Access, MS Works и др.
В основе БД лежит представление данных в виде таблиц. Основными понятиями в СУБД являются поля и записи. В полях содержатся данные. Поле характеризуется длиной. Совокупность всех полей в строке называется записью.
Структуру простейшей базы данных можно рассматривать как прямоугольную таблицу, состоящую из вертикальных столбцов и горизонтальных строк. Вертикальные столбцы принято называть полями, а горизонтальные строки — записями. Единицей хранимой информации является горизонтальная строка-запись, которая хранит информацию, например, об одном сотруднике фирмы. Каждая запись представляет собой совокупность полей.
Вопрос №2
Выделяют три основные категории пользователей баз данных: разработчики, администраторы баз данных и собственно пользователи.
В обязанности разработчика входит: • проектирование и разработка базы данных; • проектирование структуры базы данных в соответствии с установленными требованиями; • оценка требований необходимой памяти; • формулирование модификаций структуры базы данных; • передача этой информации администратору базы данных (инструкция администратору), а также создание иных инструктивных документов (инструкции оператору, пользователю и т.п.); • установка мер по защите базы данных в процессе её разработки и эксплуатации и др.
Администрирование базами данных осуществляется лицом, управляющим этой системой. Такое лицо называется администратором базы данных (АБД).
Если база данных большая, эти обязанности могут выполнять несколько человек (группа) – администраторов БД.
В обязанности администратора могут входить: • инсталляция БД и обновление версий СУБД; • распределение дисковой памяти и планирование требований системы к памяти; • создание структур памяти в базе данных (табличных пространств); • создание первичных объектов (таблиц, индексов); • модификация структуры базы данных; • отслеживание и оптимизация производительности базы данных; • соблюдение лицензионных соглашений; • зачисление пользователей и поддержание защиты системы; • управление и отслеживание доступа пользователей к базе данных; • планирование резервного копирования и восстановления; • поддержание архивных данных на устройствах хранения информации; • осуществление резервного копирования и восстановления.
В некоторых случаях база данных должна также иметь одного или нескольких сотрудников службы безопасности, которые, главным образом, отвечают за регистрацию новых пользователей, управление и отслеживание доступа пользователей к базе данных, и защиту базы данных.
Пользователи базы данных и схемы Каждая база данных включает список имен пользователей. Чтобы получить доступ к базе данных, пользователь должен соединиться с базой данных, предоставив своё имя, которое включает собственно имя (логин) и пароль. Такая структура предназначена для предотвращения несанкционированного доступа к БД.
При первоначальном создании (включении) пользователя в БД ему можно определить некоторое табличное пространство (например, заданное по умолчанию), в котором будут создаваться объекты пользователя. Пользователю может быть определён объём памяти, который он может использовать в табличном пространстве. Другой способ создания пользователя БД подразумевает предоставление пользователю определённой роли.
Для удаления (исключения) пользователя из базы данных удаляют его учётную запись из словаря базы данных. Если пользователь владел некоторыми объектами базы данных, то их можно последовательно удалить, или автоматически уничтожить все объекты, связанные с учётной записью пользователя.
Вопрос №3
Типология БД
Классификация баз и банков данных может производиться по различным признакам (относящимся к разным компонентам и сторонам функционирования БнД), среди которых выделяют следующие.
По форме представляемой информации выделяют:
· фактографические,
· документальные,
· мультимедийные, в той или иной степени соответствующие цифровой, символьной и другим (не цифровой и не символьной) формам представления информации в вычислительной среде.
К последним можно отнести картографические, видео, аудио, графические и другие БД.
По типу хранимой (не мультимедийной) информации выделяют:
· фактографические,
· документальные,
· лексикографические БД.
Лексикографические базы – классификаторы, кодификаторы, словари основ слов, тезаурусы, рубрикаторы и т.д., обычно используемые в качестве справочных совместно с документальными или фактографическими БД.
Документальные базы по уровню представления информации подразделяются на: полнотекстовые (так называемые «первичные» документы), библиографические и реферативные («вторичные» документы, отражающие на адресном и содержательном уровне первичный документ).
По типу используемой модели данных выделяют три классических класса БД:
· иерархические,
· сетевые,
· реляционные.
Развитие технологий обработки данных привело к появлению постреляционных, объектно-ориентированных, многомерных БД, в той или иной степени соответствующих трём упомянутым классическим моделям.
По топологии хранения данных различают локальные и распределённые БД.
По типологии доступа и характеру использования хранимой информации БД могут быть разделены на специализированные и интегрированные[1].
По функциональному назначению (характеру решаемых с помощью БД задач и, соответственно, характеру использования данных) выделяют операционные и справочно-информационные БД.
К последним можно отнести ретроспективные БД (электронные каталоги библиотек, БД статистической информации и т.д.), используемые для информационной поддержки основной деятельности, и не предполагающие внесение изменений в существующие записи, например, по результатам этой деятельности. Операционные БД предназначены для управления различными технологическими процессами. В этом случае данные не только извлекаются из БД, но и изменяются (в том числе добавляются), в том числе в результате этого использования.
По сфере возможного применения различают универсальные и специализированные (или проблемно-ориентированные) системы.
По степени доступности выделяют общедоступные и БД с ограниченным доступом пользователей. В последнем случае говорят об управляемом доступе, индивидуально определяющем не только набор доступных данных, но и характер операций которые доступны пользователю.
Представленная классификация не является полной и исчерпывающей. Она в большей степени отражает исторически сложившееся состояние дел в сфере деятельности, связанной с разработкой и применением БД.
Вопрос №4
Система управления базами данных (СУБД) - это программное обеспечение, с помощью которого пользователи могут определять, создавать и поддерживать базу данных, а также осуществлять к ней контролируемый доступ.
В реляционных базах данных (БД самого распространенного типа) данные хранятся в таблицах. На первый взгляд, эти таблицы подобны электронным таблицам Excel, поскольку они тоже состоят из строк и столбцов. Столбцы называются полями (fields) и содержат данные определенного типа. Строки именуютсязаписями (records). В одной строке хранится один набор данных, описывающих определенный объект. Например, если в таблице хранятся данные о клиентах, она может содержать поля для имени, адреса, города, почтового индекса, номера телефона и т.д. Для каждого клиента будет создана отдельная запись.
Таблицы – не единственный тип объектов, из которых состоят базы данных. Помимо таблиц, существуютформы, отчеты и запросы.
Формы (forms) применяются для добавления новых данных и изменения уже существующих. Формы облегчают добавление и редактирование информации, а также позволяют контролировать тип водимых данных и избегать при вводе ряда ошибок.
Для отображения данных в удобном для чтения виде используются отчеты (reports). Ознакомиться со всей информацией, хранящейся в таблице, сложно по той причине, что текст не умещается в полях целиком. Существует возможность включать в отчет не все данные, а только некоторые, что значительно повышает удобство использования.
Для вывода в отчеты определенных данных применяются запросы (queries). Использование запросов похоже на процесс поиска, – задаются конкретные критерии отбора, на основе которых база данных формирует и возвращает отчет. Например, если база данных содержит информацию о телефонных номерах, то можно запросить вывести в отчете только те телефоны, которые относятся к конкретному адресу, или только те, которые относятся к конкретной фамилии, или начинающиеся с определенных цифр и т.п. Запросы записываются на языке SQL (Structured Query Language — язык структурированных запросов).
В основе реляционных баз данных лежит понятие связей (отношений, relationships). Они позволяют разработчикам связывать несколько таблиц в базе посредством общих данных. При помощи взаимосвязей разработчики баз данных моделируют таблицы, отражающие взаимодействие объектов в реальности.
Понять принцип работы связей проще всего на примере. Пусть для хранения информации о продажах компании применяется электронная таблица Excel. Со временем в таблице накапливаются сотни записей. Многие из них соответствуют покупкам, совершенным одними и теми же клиентами. Проблема состоит в том, что при совершении повторной покупки информация об адресе клиента снова сохраняется. Со временем некоторые клиенты переезжают. Их новые адреса вводятся в электронную таблицу, но во всех прошлых записях остается прежний адрес. Существует вероятность, что рано или поздно кто-то случайно использует для отправки товара неверный адрес. Обновление адресов становится довольно непростой задачей из-за их невероятного количества. В Excel нет средств, позволяющих устранить эту проблему.
При формировании базы данных логичнее отделить все записи о клиентах от записей, относящихся к совершенным ими покупкам. В этом случае в одной таблице будет храниться информация о покупках, а в другой – о клиентах. В таблице клиентов каждому будет соответствовать только одна запись. При переезде клиента потребуется обновить только одну соответствующую ему запись, а не все записи о его покупках. В таблице, содержащей записи о покупках, вместо перечисления всей информации о покупателе будет указануникальный идентификатор (в нашем примере поле идентификатора названо cust_ID), соответствующий определенной записи в таблице клиентов. Такие связи между таблицами и позволяют создавать реляционные базы данных.
Обе таблицы содержат поле cust_ID. В таблице клиентов поле cust_ID включает уникальные идентификаторы, называемые также первичными ключами (primary key). У каждой записи в таблице всегда существует свой идентификатор, который не повторяется, благодаря чему, в таблице обеспечен порядок, предполагающий корректное обновление, удаление и добавление данных.
В таблице покупок одно и то же значение cust_ID, напротив, может повторяться больше одного раза — в зависимости от того, сколько покупок совершил тот или иной клиент. Когда первичный ключ одной таблицы применяется в качестве поля другой, он называется внешним ключом. При использовании внешних ключей между таблицами образуются связи (relationships). Они позволяют избавиться от избыточной (дублирующей информации) и сохранить целостность данных.
В приведенном примере таблицы являются достаточно простыми. Например, в порядке вещей будет использование третьей таблицы для хранения информации о товаре (инвентарная таблица) с полемproduct_ID, добавляемым в таблицу покупок в качестве внешнего ключа.
|
Рис. 45. Схема данных. |
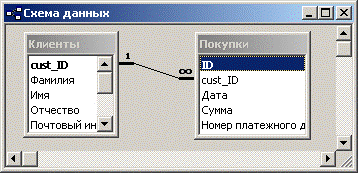
На рисунке 45 показана взаимосвязь между двумя таблицами, описанными в этом примере. Линия между таблицами обозначает существование связи. Число 1, расположенное слева, означает, что в таблице Клиенты параметр cust_ID является уникальным, а знак бесконечности, находящийся справа, указывает, что в таблице Покупки одно и то же значение параметра cust_ID может повторяться сколько угодно. Такое отношение называется "один-ко-многим".
Возможности связей между таблицами не ограничены уменьшением избыточности данных. Они также позволяют создать SQL-запрос, извлекающий данные из обеих таблиц на основе определенного критерия. Например, можно создать запрос, выводящий имена и фамилии всех клиентов, совершивших покупки на сумму, превышающую некоторое пороговое значение. Формы, предназначенные для записи сразу в несколько таблиц, тоже функционируют на основе связей.
Модель реляционной СУБД была разработана в 70-80 годы XX века. К реляционным СУБД относится целый ряд программных продуктов, среди них Microsoft Access из пакета Microsoft Office, MySQL или более мощные системы промышленного уровня, таких как Microsoft SQL Server или Oracle.
В последнее время активно развивается и другая модель представления баз данных – объектная. Реляционная модель акцентирует свое внимание на структуре и связях сущностей, объектная - на их свойствах и поведении.
Архитектура СУБД
СУБД должна предоставлять доступ к данным любым пользователям, включая и тех, которые практически не имеют и (или) не хотят иметь представления о:
физическом размещении в памяти данных и их описаний;
механизмах поиска запрашиваемых данных;
проблемах, возникающих при одновременном запросе одних и тех же данных многими пользователями (прикладными программами);
способах обеспечения защиты данных от некорректных обновлений и (или) несанкционированного доступа;
поддержании баз данных в актуальном состоянии
и множестве других функций СУБД.
При выполнении основных из этих функций СУБД должна использовать различные описания данных. А как создавать эти описания?
Естественно, что проект базы данных надо начинать с анализа предметной области и выявления требований к ней отдельных пользователей (сотрудников организации, для которых создается база данных). Подробнее этот процесс будет рассмотрен ниже, а здесь отметим, что проектирование обычно поручается человеку (группе лиц) – администратору базы данных (АБД). Им может быть как специально выделенный сотрудник организации, так и будущий пользователь базы данных, достаточно хорошо знакомый с машинной обработкой данных.
Объединяя частные представления о содержимом базы данных, полученные в результате опроса пользователей, и свои представления о данных, которые могут потребоваться в будущих приложениях, АБД сначала создает обобщенное неформальное описание создаваемой базы данных. Это описание, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств, понятных всем людям, работающих над проектированием базы данных, называютинфологической моделью данных.
Такая человеко-ориентированная модель полностью независима от физических параметров среды хранения данных. В конце концов этой средой может быть память человека, а не ЭВМ. Поэтому инфологическая модель не должна изменяться до тех пор, пока какие-то изменения в реальном мире не потребуют изменения в ней некоторого определения, чтобы эта модель продолжала отражать предметную область.
Остальные модели, показанные на рис. 1.3, являются компьютеро-ориентированными. С их помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по физической модели данных.
Так как указанный доступ осуществляется с помощью конкретной СУБД, то модели должны быть описаны на языке описания данных этой СУБД. Такое описание, создаваемое АБД по инфологической модели данных, называют даталогической моделью данных.
Трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ. АБД может при необходимости переписать хранимые данные на другие носители информации и (или) реорганизовать их физическую структуру, изменив лишь физическую модель данных. АБД может подключить к системе любое число новых пользователей (новых приложений), дополнив, если надо, даталогическую модель. Указанные изменения физической и даталогической моделей не будут замечены существующими пользователями системы (окажутся "прозрачными" для них), так же как не будут замечены и новые пользователи. Следовательно, независимость данных обеспечивает возможность развития системы баз данных без разрушения существующих приложений.
Вопрос №5
Модели данных
Ядром любой базы данных является модель данных. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных - это совокупность структур данных и операций их обработки. Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную.
Иерархическая модель представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое по структуре дерево (граф).
К основным понятиям иерархической структуры относятся уровень, узел и связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину, не подчиненную никакой другой вершине и находящуюся на самом верхнем - первом уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т. д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один иерархический путь от корневой записи.
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
Реляционная модель данных объекты и связи между ними представляет в виде таблиц, при этом связи тоже рассматриваются как объекты. Все строки, составляющие таблицу в реляционной базе данных, должны иметь первичный ключ. Все современные средства СУБД поддерживают реляционную модель данных.
Эта модель характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
1. Каждый элемент таблицы соответствует одному элементу данных.
2. Все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип и длину.
3. Каждый столбец имеет уникальное имя.
4. Одинаковые строки в таблице отсутствуют;
5. Порядок следования строк и столбцов может быть произвольным.
Вопрос №6
Иерархическая модель данных — логическая модель данных в виде древовидной структуры, представляющая собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое дерево (граф). Данная модель характеризуется такими параметрами, как уровни, узлы, связи. Принцип работы модели таков, что несколько узлов более низкого уровня соединяется при помощи связи с одним узлом более высокого уровня. Узел — информационная модель элемента, находящегося на данном уровне иерархии.
К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь.
Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей.
К каждой записи базы данных существует только один (иерархический) путь от корневой записи.
Каждому узлу структуры соответствует один сегмент, представляющий собой поименованный линейный кортеж полей данных. Каждому сегменту (кроме S1-корневого) соответствует один входной и несколько выходных сегментов. Каждый сегмент структуры лежит на единственном иерархическом пути, начинающемся от корневого сегмента.
Следует отметить, что в настоящее время не разрабатываются СУБД, поддерживающие на концептуальном уровне только иерархические модели. Как правило, использующие иерархический подход системы, допускают связывание древовидных структур между собой и/или установление связей внутри них. Это приводит к сетевым даталогическим моделям СУБД.
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных.
Атрибут (элемент данных) - наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем.
Запись - именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи - конкретная запись с конкретным значением элементов
Групповое отношение - иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) - подчиненными. Иерархическая база данных может хранить только такие древовидные структуры.
Операции над данными
ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
УДАЛИТЬ некоторую запись и все подчиненные ей записи.
ИЗВЛЕЧЬ:
- извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей
- извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева) В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 1 тысячи руб.)
Как видим, все операции изменения применяются только к одной "текущей" записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название "навигационного".
Ограничения целостности
Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Как уже отмечалось, не обеспечивается автоматическое поддержание соответствия парных записей, входящих в разлные иерархии.
Недостатки
К основным недостаткам иерархических моделей следует отнести: неэффективность, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. Также недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Иерархические СУБД быстро прошли пик популярности, которая обусловливалась их ранним появлением на рынке. Затем их недостатки сделали их неконкурентоспособными, и в настоящее время иерархическая модель представляет исключительно исторический интерес.
Пример модели
Рассмотрим следующую модель данных предприятия (смотреть рисунок ниже): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры : заказчик - контракты с ним - сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (рис. (b)).
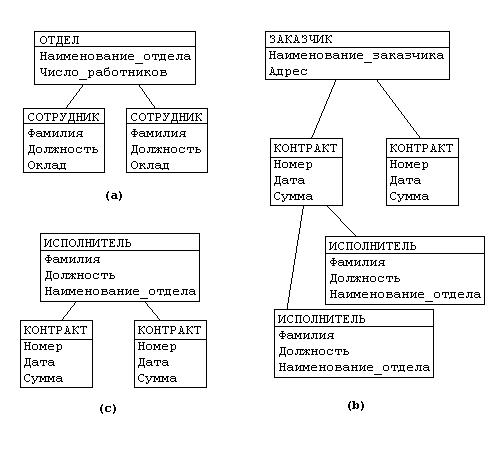
Из этого примера видны недостатки иерархических БД:
Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ - дочерней (рис. (c)). Таким образом, мы опять вынуждены дублировать информацию.
Вопрос №7
Сетевая модель данных - это логическая модель данных, представляющая их сетевыми структурами типов записей и связанные отношениями мощности один-к-одному или один-ко-многим. В отличие от реляционной модели, связи в ней моделируются наборами, которые реализуются с помощью указателей. Сетевые модели данных являются расширенной версиейиерархической модели, однако основным отличием является то, что в сетевых моделях данных имеются указатели в обоих направлениях, которые соединяют родственную информацию. Сетевую модель можно представить как граф узлами, которого является запись, а ребрами - набор. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД. Поэтому имена и направление связей должны идентифицироваться при описании БД.