

Лабораторна робота №2
Тема: Знайомство з GUI інтерфейсом бібліотеки data mining алгоритмів
Мета роботи: Ознайомитися і отримати навики роботи GUI інтерфейсом бібліотеки data mining алгоритмів Xelopes
Завдання: Отримати інформацію про дані з файлів transactarff і weather- nominal.arff і побудувати для них задачі пошуку асоціативних правил, кластеризації і класифікації
Загальні відомості
Вступ
Xelopes – вільно поширювана бібліотека, що забезпечує універсальну основу для стандартного доступу до алгоритмів data mining. Вона була розроблена німецькою компанією ProdSys в тісній співпраці з фахівцями російської фірми ZSoft. Для зручної роботи з бібліотекою з нею поставляється GUI інтерфейс GUI Xelopes, реалізований у вигляді окремого додатку. Він дозволяє виконувати наступні основні функції:
Завантажити дані представлені у вигляді текстового файлу формату arff і проглянути їх в табличному вигляді.
Отримати інформацію про атрибути даних (полях таблиці)
Отримати статичну інформацію про початкові дані:
Побудувати модель data mining.
Для асоціативних правил, дерев рішень і дейтограм візуалізувати побудовану модель.
Зберегти модель і застосувати її надалі. Розглянемо перераховані функції більш детально.
Завантаження і проглядання початкових даних
Для завантаження початкових даних необхідно відкрити діалог представлений на рис. 2.1. Це можна виконати або натисненням кнопки Open Mining Data на панелі інструментів або вибором пункту меню File | Open Mining Data. Крім того діалог відкривається при запуску програми.
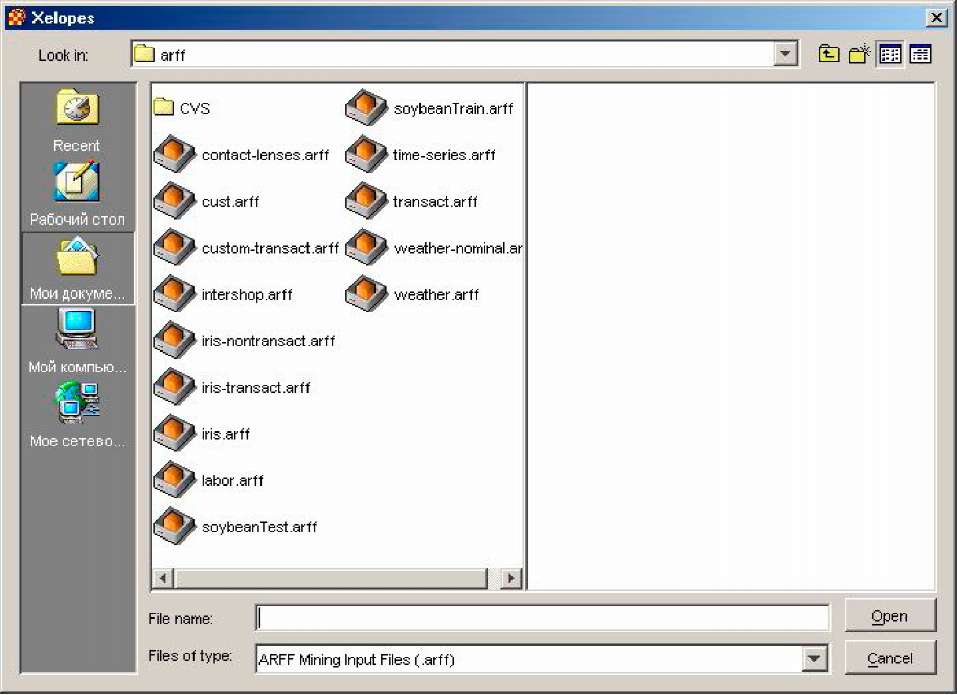
Рисунок 2.1 – Діалог завантаження початкових даних (в Ос Windows 2000)
Використовуючи даний діалог необхідно вибрати текстовий файл з даними, представленими у форматі arff. Натиснення на кнопку Open приведе до завантаження даних з вибраного файлу.
Після завантаження даних на панелі інструментів стають доступними наступні кнопки:
View Input Data – відображення початкових даних;
Display Data Description – отримання інформації про атрибути початкових даних;
Display Descriptive Statistics – отримання статистичної інформації про початкові дані;
Build Mining Model – генерація mining моделі для завантажених початкових даних.
Для проглядання початкових даних в табличному вигляді необхідно натискувати кнопку View Input Data на панелі інструментів або вибрати пункт меню File | View Data Source. При цьому відкривається вікно представлене на рис. 2.2. В заголовку вікна відображається повний шлях до файлу, з якого були завантажені дані. Дані представляються у вигляді таблиці, в якій рядки відповідають досліджуваним об'єктам, а колонки атрибутам, що характеризують їх. Над таблицею можна помітити інформацію про загальну кількість об'єктів (векторів) представлених в таблиці.
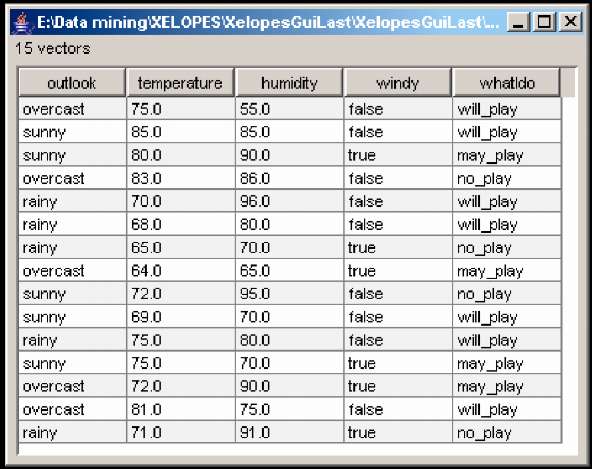
Рисунок 2.2 – Початкові дані в табличному вигляді
Інформація про атрибути даних
Інтерфейс GUI Xelopes дозволяє отримати докладну інформацію про атрибути завантажених даних. Для цього необхідно натискувати на кнопку Display Data Description на панелі інструментів. Інформація представляється в діалоговому вікні Variables (рис 2.3.). У верхній частині вікна виводиться назва даних (на малюнку це weather). В правій частині вікна представлений список атрибутів. В лівій частині інформація про вибраний атрибут залежно від його типу.

Рисунок 2.3 – Інформація про категоріальний атрибут
В Xelopes розрізняють два основні типи атрибутів: категоріальний і числовий. Залежно від типу міняється і інформація про атрибут. Для будь-якого атрибута виводиться його назва і тип.
Для категоріальних атрибутів (рис. 2.3) відображається інформація про значення (категорії), що приймаються ним: кількості (Number categories) і списку значень (Categories). Якщо кількість категорій не обмежена, то буде відзначений прапор unbounded categories.
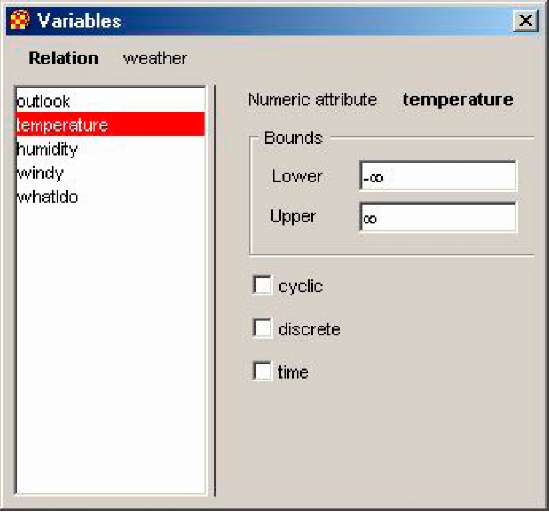
Рисунок 2.4 – Інформація про числовий атрибут
Для числових атрибутів (рис. 2.4) відображається інформація про найбільше (Upper) і якнайменше (Lower) значення. Крім того залежно від властивостей атрибута можуть бути встановлені наступні прапорці:
Cyclic – якщо значення атрибута циклічні (тобто може бути визначено поняття відстані)
Discrete – якщо значеннями атрибута є дискретні величини
Time – якщо атрибут є часом.
Статистична інформація про дані
Для отримання статистичної інформації про дані необхідно натискувати кнопку Display Descriptive Statistics на панелі інструментів або вибрати пункт меню File | Statistics. В діалоговому вікні Statistics (рис.2.5.), що відкрилося, необхідно виконати настройку інформації, що відображається.

Рисунок 2.5 – Діалог настройок представлення статистичної інформації за
початковими даними
Необхідно налагодити наступні параметри:
Тип інформації, що відображається
Атрибути, що відкладаються по осях X і У
Мірність інформації, що відображається: в 2-х або 3-х мірному просторі.
Після налагодження необхідних параметрів натисненням на кнопку ОК можна отримати статичну інформацію вибраного типу. Для настройок представлених на рис. 2.5 буде відкрито діалогове вікно з інформацією, зображене на рис. 2.6.
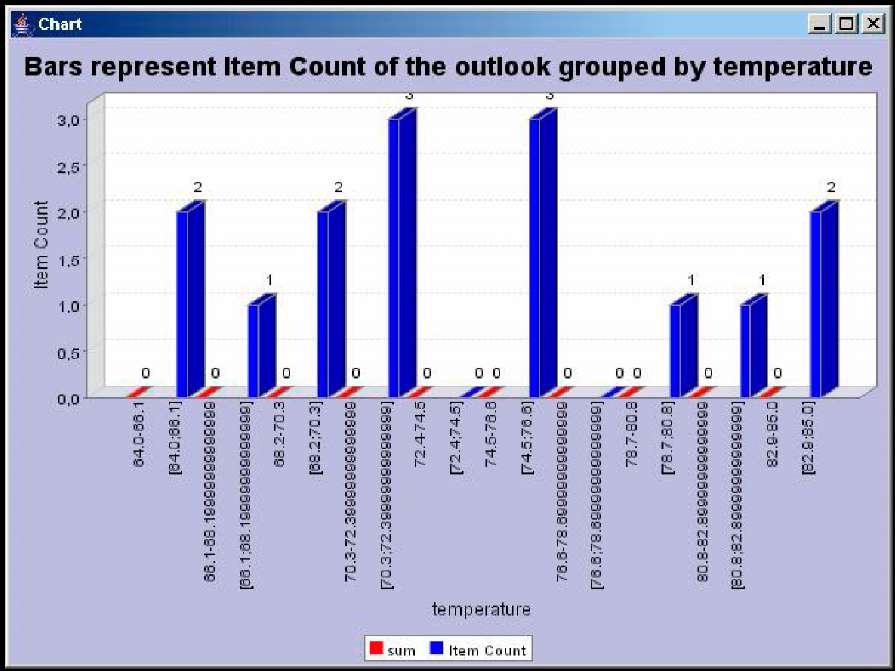
Рисунок 2.6 – Приклад статистичної інформації за початковими даними
Можна отримати наступні типи інформації:
Кількість об'єктів (Item Count)
Мінімальні (Minimal) і максимальні (Maximal) значення
Межа (Range) значень
Сума (Sum) значень
Середнє значення (Mean) ін.
Побудова mining моделі
В результаті застосування методів data mining повинна бути побудована mining модель. Для цього необхідно натискувати кнопку Build Mining Model на панелі інструментів або вибрати пункт меню Model | Build. В результаті відкриється діалогове вікно, що пропонує побудувати один з типів моделі для завантажених раніше даних (рис. 2.7).
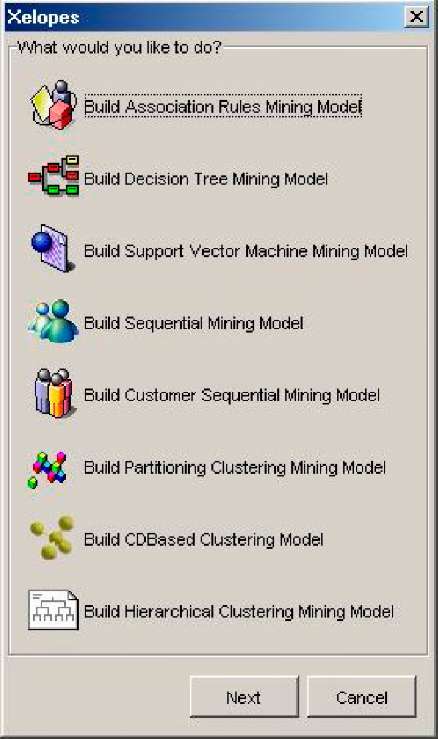
Рисунок 2.7 – Типи моделей, створюваних алгоритмами бібліотеки Xelopes
Для побудови доступні наступні моделі:
асоціативні правила (Association Rules Mining Model);
дерева рішень (Decision Tree Mining Model);
математична залежність, побудована методом SVM (Support Vector Machine Mining Model);
послідовності (Sequential Mining Model);
модель сиквенціального аналізу (Customer Sequential Mining Model);
розділювана кластерна модель (Partition Clustering Mining Model);
центрована кластерна модель (CDBased Clustering Mining Model);
ієрархічна кластерна модель (Hierarchical Clustering Mining Model).
Після вибору моделі, що будується, необхідно виконати: настройку процесу побудови і алгоритм побудови (рис. 2.8). Настройки процесу залежать від типу моделі, що будується, і виконуються на закладці Settings (Настройки).
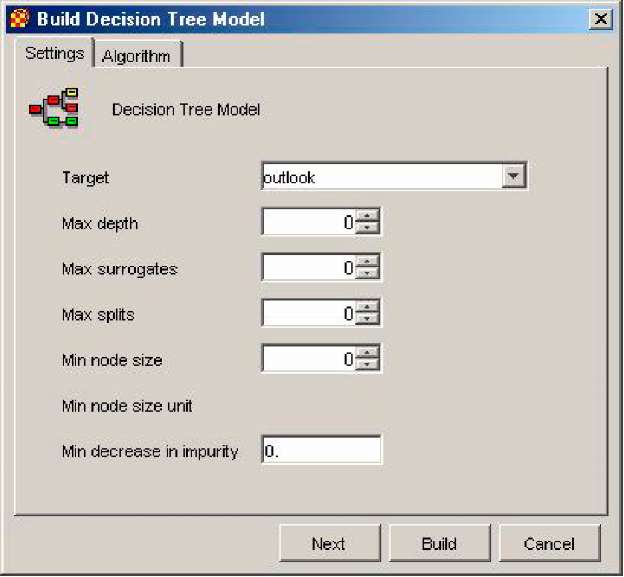
Рисунок 2.8 – Приклад настройок для побудови дерев рішень
Вибір алгоритму виконується на закладці Algorithm (алгоритм) (рис. 2.9). Список доступних для побудови моделі алгоритмів залежить від типу моделі. Крім того, для деяких алгоритмів необхідно виконати додаткову настройку. При їх виборі в полі Algorithm Parameters з'являються поля для визначення специфічних для алгоритму настройок.
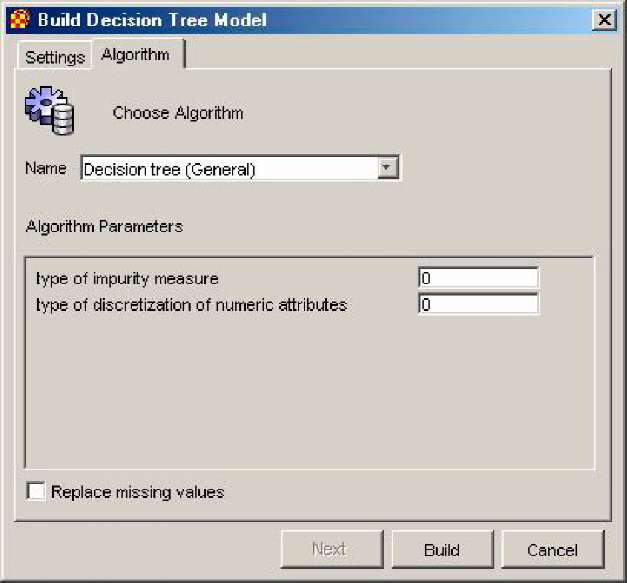
Рисунок 2.9 – Приклад настройок алгоритму побудови дерев рішень
Для побудови моделі після виконання настройок необхідно натискувати на кнопку Build в діалоговому вікні. Після завершення побудови моделі з'явиться діалогове вікно (рис. 2.10), що пропонуює виконати наступні дії:
Візуалізувати модель (Browse Model).
Застосувати модель (Apply Model).
Показати модель у вигляді PMML (View PMML Presentation).
Записати модель в PMML форматі (Save Model as PMML).
Для виконання перерахованих дій необхідно вибрати відповідну опцію і натискувати на кнопку Next. Крім того, після побудови моделі на панелі інструментів стають доступними відповідні кнопки.

Рисунок 2.10 – Дії виконувані з побудованою моделлю
В даній версії GUI Xelopes візуалізуються тільки три види моделей:
Асоціативні правила.
Дерева рішень
Ієрархічна кластерна модель у вигляді дейтограм.
Для решти моделей при спробі візуалізації відбувається відображення моделі у форматі PMML. Тобто для них дії Browse Model і View PMML Presentation матимуть однаковий результат.
Представлення моделі у форматі PMML
Для представлення моделі у форматі PMML необхідно натискувати кнопку View PMML Presentation на панелі інструментів або вибрати пункт меню Model | View PMML або вибрати опцію View PMML Presentation в діалоговому вікні, представленому на рис. 2.10. В результаті буде відкрито вікно, в якому буде представлена побудована модель у форматі PMML в текстовому вигляді (2.11).
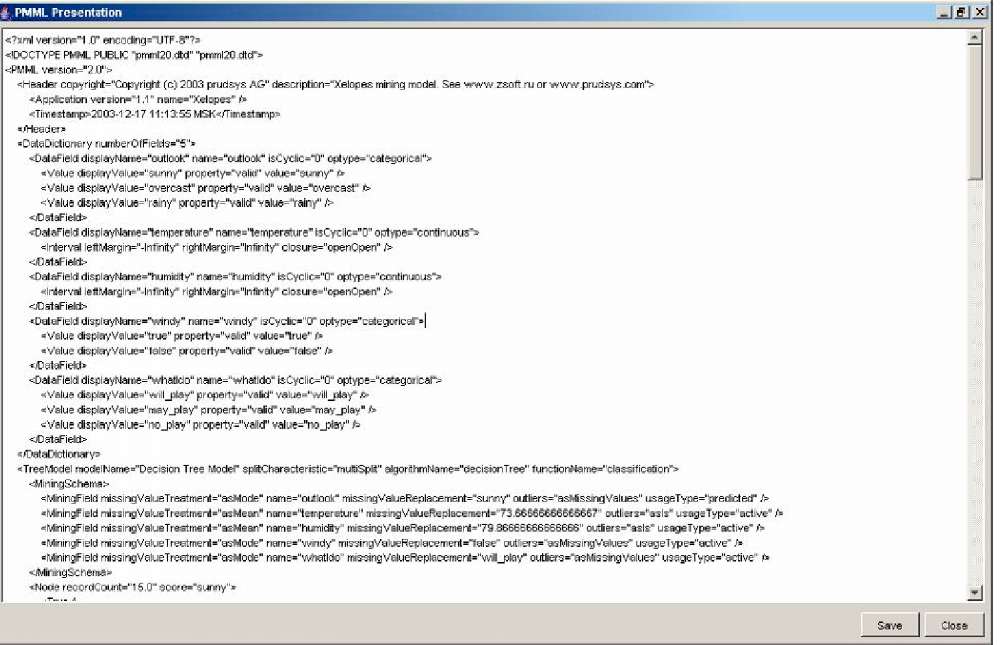
Рисунок 2.11 – Представлення моделі в PMML форматі
Представлену модель можна зберегти, натискуючи у відкритому вікні кнопку Save. Крім того, модель можна зберегти, натискуючи кнопку Save Model as PMML на панелі інструментів або вибравши пункт меню Model | Save або опцію Save Model as PMML в діалоговому вікні, представленому на рис. 2.10.
Застосування моделі
Модел,і що будуються для задач класифікації і регресії, використовуються для цілей передбачення на нових даних. Отже вони можуть бути застосовані до інших даних. Для цього необхідно натискувати кнопку Apply Model на панелі інструментів або вибравши пункт меню Model | Apply або опцію Apply Model в діалоговому вікні, представленому на рис. 2.10. В результаті буде запропоновано вибрати файл з новими даними, записаними у форматі arff (буде відкрито діалогове вікно, аналогічне представленому на рис. 2.1.). Після вибору файлу і застосування побудованої моделі буде відображено вікно, в якому нові дані будуть представлені в табличному вигляді (рис. 2.12).
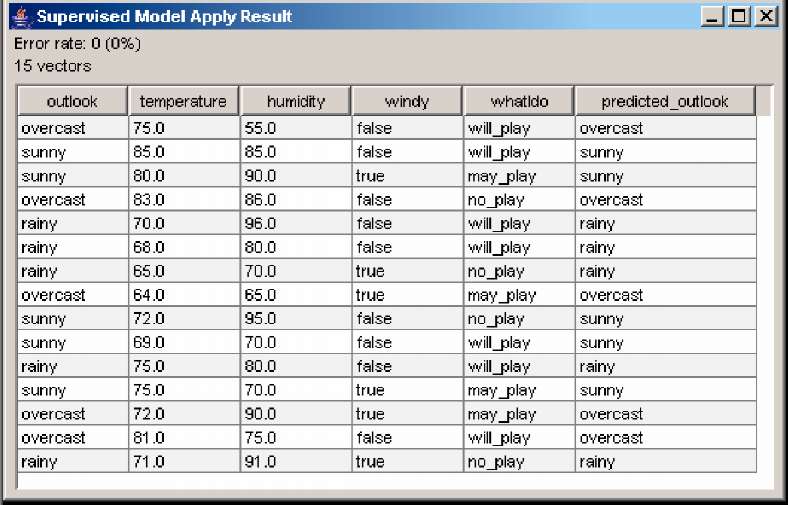
Рисунок 2.12 – Результат застосування моделі до нових даних
У вікні, що відкрилося, у вигляді таблиці будуть представлені класифіковані дані. Як видно, таблиця алогічна тій же, представлена на рис. 2.2. Різниця полягає в новій колонці predicted_* що описує результат класифікації (* – замінюється на атрибут класифікації). У вікні також виводиться інформація про ступінь помилки класифікації (Error rate).