

Статистическая обработка данных.
Средства обработки данных в Excel можно разделить на 2 типа инструментов:
- средства первичной обработки данных;
- средства анализа и прогнозирования.
К первой группе средств относятся инструменты обеспечения корректного ввода, хранения и обеспечения доступа к данным. При первичной обработке данные приводятся к стандартному виду, рассчитываются необходимые показатели, производится отбор нужных массивов данных.
Ко второй группе относятся инструменты обеспечивающие построение обобщений, заключений, оценок и прогнозов, основываясь на данных прошедших первичную обработку.
Многие данные формируются под воздействием факторов, не подлежащих контролю. В таких случаях говорят о случайной или стохастической зависимости. Такие ряды данных обрабатываются с помощью методов математической статистики. Статистическая обработка данных в Excel реализуется с помощью «Пакета анализа». Для его вызова выбираются пункты меню Сервис/Надстройки/Пакет анализа (Analysis ToolPak). В версии 2007 если на панели данные нужный пункт меню отсутствует, то на панели быстрого доступа выбираем пункт меню «Другие команды», далее слева на панели инструментов выбираем «Надстройки» и внизу окна напротив управления выбираем «Надстройки Excel» и нажимаем Перейти. В появившемся диалоговом окне выбираем «Пакет анализа», ждем, пока Excel выполнит установку выбранного компонента и отобразит его в виде дополнительного раздела Анализ на ленте Данные (отображается пунктом «Анализ данных»).
Надстройка «Пакет анализа».

Генерация случайных чисел - используется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью данной процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей.
Данное средство предлагает следующие законы:
Закон |
Характеристики |
Описание |
Равномерное |
Интервал (между) |
Возвращает равномерно распределенные значения на указанном интервале |
Нормальное |
Среднее, среднеквадратическое отклонение |
Рынки ценных бумаг для моделирования совокупности данных по росту индивидуумов |
Бернулли |
Вероятность наступления события |
Для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты |
Биноминальное |
Вероятность и число испытаний |
|
Пуассона |
Лямбда |
Интенсивность потока и моделирование систем массового обслуживания |
Дискретное |
Массив наблюдаемых значений и соответствующих вероятностей |
Построение ряда по имеющимся историческим данным |

Выборка (Sampling) – создание выборки из массива данных. Выборки бывают случайные и периодические.
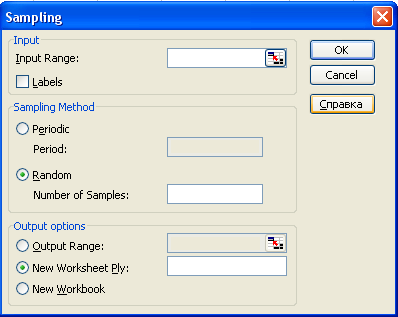
Например, анализ данных по кварталам или месяцам. Разбиение выборки на части для контроля прогнозных качеств и адекватности модели.
Описательная статистика – формирует статистический отчет по массиву данных.
Column1 |
|
|
|
Mean |
0.193073077 |
Standard Error |
0.043353697 |
Median |
0.1658375 |
Mode |
0 |
Standard Deviation |
0.221061346 |
Sample Variance |
0.048868119 |
Kurtosis |
-0.654263349 |
Skewness |
0.851519228 |
Range |
0.668325 |
Minimum |
0 |
Maximum |
0.668325 |
Sum |
5.0199 |
Count |
26 |
Confidence Level(95.0%) |
0.089288609 |
Гистограмма частот – рассчитывает частоты попадания данных в указанные интервалы и строит по ним диаграмму.