

Міністерство освіти і науки України
Національний університет водного господарства та природокористування
Кафедра електротехніки і автоматики
Лабораторна робота № 27
з курсу “Алгоритмізація і програмування”
для студентів спеціальності
“Автоматизоване управління технологічними процесами”
Рекомендовано до друку методичною комісією факультету прикладної математики та комп’ютерно-інтегрованих систем
Протокол № ___від ________2006р.
Рівне 2006
Лабораторна робота № 27 “Розробка баз даних у середовищі програмування C++ Builder” з курсу “Алгоритмізація і програмування” для студентів спеціальності “Автоматизоване управління технологічними процесами” /
В.Й. Пастушенко, А.М. Стеценко, В.Ю. Кірпічніков, – Рівне: НУВГП, 2006 – XX с.
Відповідальний за випуск – зав. кафедри електротехніки та автоматики, професор, академік УЕАН Б.О. Баховець.
Робота 27. Розробка баз даних у середовищі програмування C++ Builder
27.1 Мета роботи
Навчитися створювати бази даних, використовуючи засоби середовища C++ Builder 6.0.
27.2 Теоретичні відомості
1. Бази даних
1.1 Принципи побудови баз даних
Завжди, коли виникає потреба маніпулювати великими масивами даних, використовуються бази даних.
База даних — це перш за все набір таблиць, хоча у базу даних можуть входити також процедури і ряд інших об'єктів. Таблицю можна уявляти собі як звичайну двовимірну таблицю з характеристиками (атрибутами) якоїсь безлічі об'єктів. Таблиця має ім'я — ідентифікатор, по якому на неї можна послатися. У табл. 1.1 наведений приклад фрагмента подібної таблиці з ім'ям Pers, яка містить відомості про співробітників деякої організації. Ця таблиця буде надалі використовуватися як приклад по роботі з базами даних.
Таблиця 1.1. Приклад таблиці даних про співробітників Pers
Номер |
Відділ |
Прізвище |
Ім'я |
По батькові |
Рік народ-ження |
Стать |
Характе-ристика |
Фотографія |
Num |
Dep |
Fam |
Nam |
Par |
Year_b |
Sex |
Charact |
Photo |
1 |
Бухгалтерія |
Іванов |
Іван |
Іванович |
1950 |
м |
... |
... |
2 |
Цех 1 |
Петров |
Петро |
Петрович |
1960 |
м |
... |
... |
3 |
Цех 2 |
Сидорів |
Сидір |
Сидорович |
1955 |
м |
... |
... |
4 |
Цех 1 |
Іванова |
Ірина |
Іванівна |
1961 |
ж |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
Стовпці таблиці відповідають тим або іншим характеристикам об'єктів — полям. Кожне поле характеризується ім'ям і типом даних, що зберігаються. Ім'я поля — це ідентифікатор, що використовується в різних програмах для маніпуляції даними. Він будується за тими ж правилами, що і будь-який ідентифікатор, тобто пишеться латинськими буквами, складається з одного слова тощо. Таким чином, ім'я — це не те, що відображається на екрані або у звіті у заголовку стовпця, а ідентифікатор, що відповідає цьому заголовку. Наприклад, у таблиці 1.1 введені для наступних посилань імена полів Num, Dep, Fam, Nam, Par, Year_b, Sex, Charact, Photo, що відповідають зазначеним у ній заголовкам полів.
Тип поля характеризує тип даних, що зберігаються в полі даних. Це можуть бути рядки, числа, булеві значення, великі тексти (наприклад, характеристики співробітників), зображення (фотографії співробітників) і т.п.
Кожний рядок таблиці відповідає одному з об'єктів. Він називається записом і містить значення всіх полів, що характеризують даний об'єкт.
При побудові таблиць баз даних важливо забезпечувати несуперечність інформації. Звичайно це робиться введенням ключових полів, що забезпечують унікальність кожного запису. Ключовим може бути одне або кілька полів. У наведеному вище прикладі можна було б зробити ключовими сукупність полів Fam, Nam і Par. Але у цьому випадку не можна було б заносити в таблицю відомості про співробітників, у яких збігаються прізвище, ім'я та по батькові. Тому в таблицю введене перше поле Num — номер, яке можна зробити ключовим, що забезпечує унікальність кожного запису.
При роботі з таблицею користувач або програма як би ковзає курсором по записах. У кожний момент часу є деякий поточний запис, з якого і ведеться робота. Записи в таблиці бази даних фізично можуть розташовуватися без будь-якого порядку, просто у послідовності їхнього введення (появи нових співробітників). Але, коли дані таблиці представляються користувачу, вони повинні бути впорядковані. Користувач може хотіти переглядати записи про співробітників, впорядковані за алфавітом, розсортованими по відділах або по мірі наростання року народження тощо. Для впорядкування даних використовується поняття індексу. Індекс показує, у якій послідовності бажано переглядати таблицю. Він є як би посередником між користувачем і таблицею (див. мал. 1.1).
Курсор ковзає по індексу, а індекс вказує на той або інший запис таблиці. Для користувача таблиця виглядає впорядкованою, причому він може перемінити індекс, і послідовність записів, що переглядаються, зміниться. Але в дійсності це не пов'язане з якоюсь перебудовою самої таблиці і з фізичним переміщенням у ній записів. Міняється тільки індекс, тобто послідовність посилань на записи.
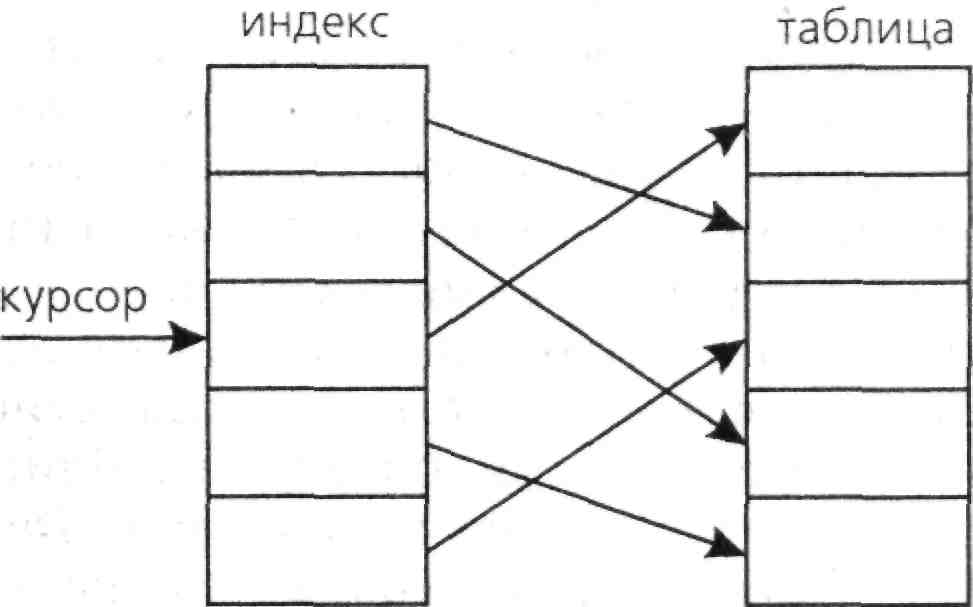
Рис. 1.1 Схема переміщення курсору по індексу
Індекси можуть бути первинними і вторинними. Наприклад, первинним індексом можуть служити поля, визначені при створенні бази даних як ключові. А вторинні індекси можуть створюватися з інших полів як у процесі створення самої бази даних, так і пізніше в процесі роботи з нею. Вторинним індексам привласнюються імена – ідентифікатори - , за якими їх можна використовувати.
Якщо індекс містить у собі кілька полів, то впорядкування бази даних спочатку здійснюється по першому полю, а для записів, що мають однакові значення першого поля - по другому і т.д. Наприклад, базу даних персоналу можна індексувати по відділах, а усередині кожного відділу - за алфавітом.
База даних звичайно містить не одну, а безліч таблиць. Наприклад, база даних про деяку організацію може містити таблицю наявних у ній підрозділів з характеристикою кожного з них. Приклад такої таблиці з ім'ям Dep, що буде використовуватися надалі, наведений у таблиці 1.2. Імена полів цієї таблиці, які надалі будемо використовувати: Dep і Proisv.
Таблиця 1.2. Приклад таблиці даних про підрозділи Dep
Відділ |
Тип |
Dep |
Proisv |
Бухгалтерія |
керування |
Цех 1 |
виробництво |
Цех 2 |
виробництво |
Окремі таблиці, звичайно, корисні, але набагато більше інформації можна витягти саме із сукупності таблиць. Наприклад, користувачеві може знадобитися довідатися загальну кількість співробітників, які працюють у виробничих цехах. Але жодна з наведених вище таблиць не допоможе відповісти на це питання, оскільки в таблиці Pers відсутні відомості про типи відділів, а в таблиці Dep - про співробітників. Для отримання відповідей на подібні запити необхідно розглядати сукупності зв'язних таблиць.
У зв'язних таблицях звичайно одна виступає як головна, а інша або декілька інших — як допоміжні, керовані головною. У цьому випадку взаємодія таблиць ілюструється малюнком 1.2. Головна і допоміжна таблиці зв'язуються одна з одною ключем. Як ключ можуть виступати якісь поля, які є присутніми в обох таблицях. Наприклад, у наведених раніше таблицях головною може бути таблиця Dep, допоміжною – Pers, а зв'язуватися вони можуть за полем Dep, яке присутнє в обох таблицях. Курсор ковзає по індексу головної таблиці. Кожному запису в головній таблиці ключ ставить у відповідність в загальному випадку безліч записів допоміжної таблиці. Так у прикладі кожному запису головної таблиці Dep відповідають ті записи допоміжної таблиці Pers, у яких ключове поле Dep з назвою відділу збігається з назвою відділу у поточному записі головної таблиці. Інакше кажучи, якщо в поточному записі головної таблиці в полі Dep написана «Бухгалтерія», то в допоміжній таблиці Pers виділяються всі записи співробітників бухгалтерії.
Створюють бази даних і обробляють запити до них системи керування базами даних — СКБД. Відома безліч СКБД, що різняться своїми можливостями або володіють приблизно рівними можливостями і конкурують одна з одною: Paradox, dBase, Microsoft Acсess, FoxPro, Oracle, InterBase, Sybase і багато інших.
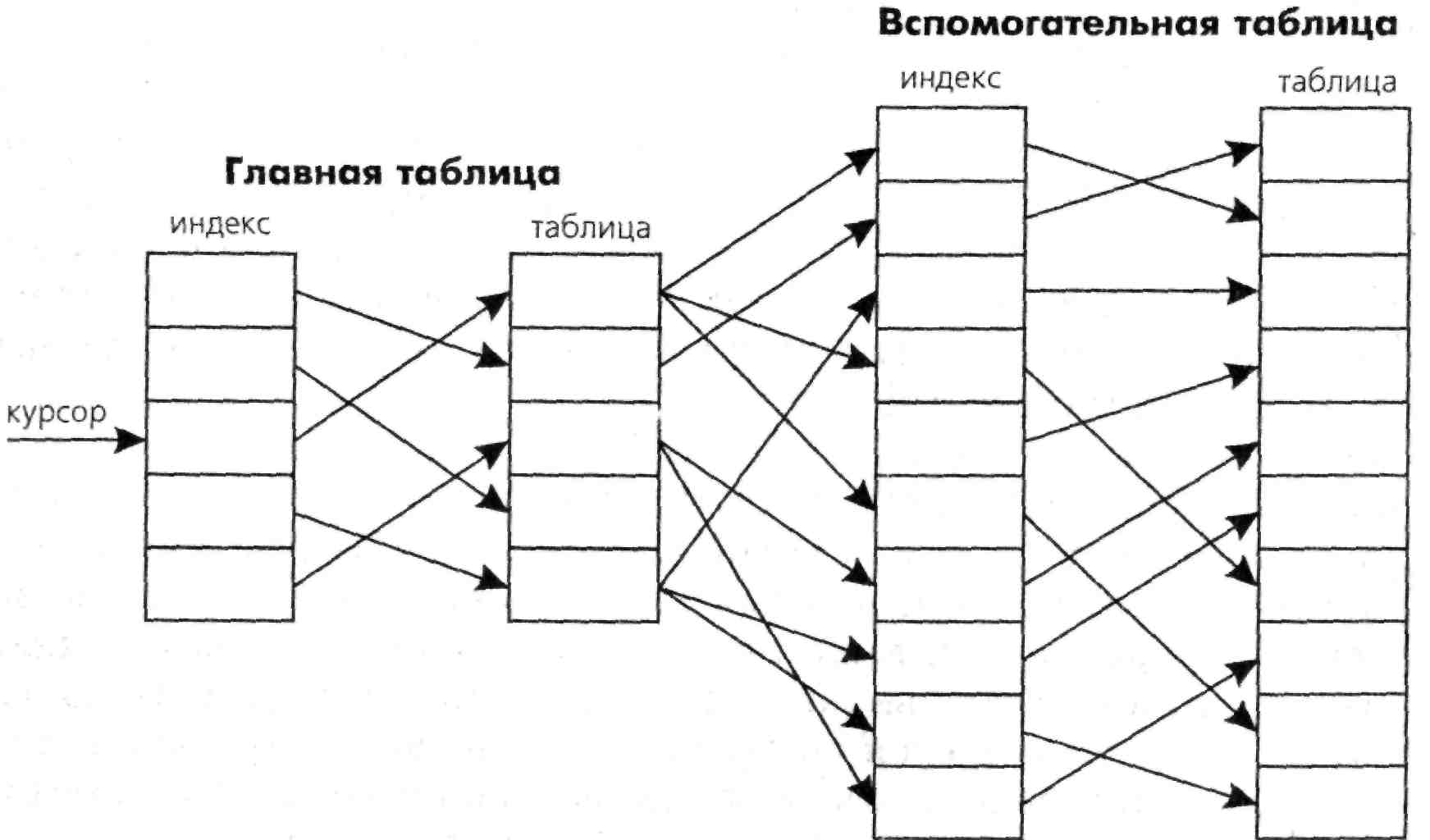
Рис. 1.2 Схема взаємодії головної і допоміжної таблиці
Різні СКБД по-різному організують і зберігають бази даних. Наприклад, Paradox і dBase використовують для кожної таблиці окремий файл. У цьому випадку база даних - це каталог, у якому зберігаються файли таблиць. В Microsoft Access і в InterBase кілька таблиць зберігаються як один файл. У цьому випадку база даних - це ім'я файлу зі шляхом доступу до нього. Системи типу клієнт/сервер, такі, як сервери Sybase або Microsoft SQL, зберігають всі дані на окремому комп'ютері і спілкуються з клієнтом за допомогою спеціальної мови – SQL.
Оскільки конкретні властивості баз даних дуже різноманітні, користувачеві було б дуже важко працювати, якби він повинен був вказувати у своїй програмі всі ці каталоги, файли, сервери і т.п. Та й програму часто доводилося б переробляти при зміні, наприклад, структури каталогів і при переході з одного комп'ютера на іншій. Щоб вирішити цю проблему, використовують псевдоніми баз даних. Псевдонім (alias) містить всю інформацію, необхідну для забезпечення доступу до бази даних. Ця інформація повідомляється тільки один раз при створенні псевдоніма. А програма для зв'язку з базою даних використовує псевдонім. У цьому випадку програмі байдуже, де фізично розташована та або інша база даних, а часто байдужа і для СКБД, що створила і обслуговує цю базу даних. При зміні системи каталогів, сервера тощо нічого у програмі переробляти не треба. Досить, щоб адміністратор бази даних увів відповідну інформацію у псевдонім.
При роботі з базами даних часто використовується кешування усіх змін. Це означає, що всі зміни даних, вставка нових записів, знищення існуючих записів, тобто всі маніпуляції з даними, проведені користувачем, спочатку виконуються не в самій базі даних, а запам'ятовуються в пам'яті у тимчасовій, віртуальній таблиці. І тільки по особливій команді після всіх перевірок правильності внесених у таблицю даних користувачеві надається можливість або зафіксувати всі ці зміни в базі даних, або відмовитися від цього і повернутися до того стану, який був до початку редагування.
Фіксація змін у базі даних здійснюється за допомогою транзакцій. Це сукупність команд, що змінюють базу даних. Впродовж транзакції користувач може щось змінювати в даних, але це тільки видимість. У дійсності всі зміни зберігаються в пам'яті. І користувачеві надається можливість завершити транзакцію або внесенням всієї зміни в реальну базу даних, або відмовою від цього з поверненням до того стану, який був до початку транзакції.