

ВСТУП
Широкий спектр досліджень у різних галузях науки – у соціології, економіці, медицині, біології, криміналістиці й ін. заснований на використанні методів математичної статистики й комп'ютерних програм, об'єднаних єдиним поняттям «аналіз даних». Застосування аналізу даних у кожній області має відповідні особливості, зв'язані зі структурою інформації, змістом завдань і інтерпретацією результатів. Дані методичні вказівки містять методику застосування аналізу даних в області соціології.
Для проведення аналізу масиву даних соціологи використовують велике число різних математичних методів, що дозволяють повно й всебічно аналізувати зібрану інформацію. У сучасній соціології для цієї мети активно застосовуються комп'ютерні програми математико-статистичної обробки даних.
Стандартні статистичні методи обробки даних включені до складу електронних таблиць, таких як Excel, Lotus 1-2-3, Quattropro, і в математичні пакети загального призначення, наприклад Mathсad. Але набагато більшими можливостями мають спеціалізовані статистичні пакети, що дозволяють застосовувати найсучасніші методи математичної статистики для обробки даних. За офіційним даними Міжнародного статистичного інституту, число статистичних програмних продуктів наближається до тисячі [4]. Серед них є професійні статистичні пакети, призначені для користувачів, добре знайомих з методами математичної статистики, і є пакети, з якими можуть працювати фахівці, що не мають глибокої математичної підготовки; є пакети вітчизняні й створені закордонними програмістами; різняться програмні продукти й за ціною.
Серед програмних засобів даного типу можна виділити вузькоспеціалізовані пакети, у першу чергу статистичні - Statistica, SPSS, STADIA, STATGRAPHICS, які мають великий набір статистичних функцій: факторний аналіз, регресійний аналіз, кластерный аналіз, багатомірний аналіз, критерії згоди і ін. Дані програмні продукти звичайно містять і засоби для візуальної інтерпретації отриманих результатів: різні графіки, діаграми, вистава даних на географічній карті.
При аналізі даних користувачеві статистичного програмного пакета доводиться виконувати обчислення широкого спектра статистик, передавати й перетворювати дані для їхнього аналізу, а також представляти отримані результати в наочному виді. Тому при виборі того або іншого статистичного пакета, для порівняння пакетів, необхідно насамперед звертати увагу на такі характеристики, як:
- зручність керування даними (експорт/імпорт даних, їхня реструктуризація);
- статистична різноманітність (кількість статистичних модулів);
- графічні можливості (наявність вбудованого графічного редактора, можливість показу окремих елементів графіка, можливості експорту графіків).
Крім того, велике значення має зручність роботи з пакетом, легкість його освоєння (наявність вбудованої системи допомоги, посібника користувача, ступінь зручності керування даними, результатами обчислень, таблицями й графіками), а також швидкість добутку обчислень.
Часто соціологічні колективи використовують у роботі не один, а кілька пакетів: введення даних, їхня первинна обробка, лінійне й парне розподіли виконуються, приміром, у програмі "Vortex" (досить популярні також " Статистик-Консультант", "Мезозавр", "Эвриста" і "Статэксперт"), а при необхідності провести багатомірний аналіз дані переносяться в SPSS або в пакет Statistica, залежно від т процедури, що де цікавлять, краще прописані.
При підготовці учбово-методичного посібника використані загальновідомі, але не завжди доступні російському читачеві навчальні посібники по статистичному аналізі, такі як курс эконометрического аналізу Гріна [1], настільна книга по статистичній методології за редакцією Армингера, Клогга, Собела (G. Arminger, C. Clogg, M. E. Sobel) [2], об'ємистий підручник по прикладному статистичному аналізі С. А. Айвазяна й В. С. Мхиторяна [3], підручник Ю. Н. Толстовой [4].
У посібнику розглядаються переважно методи, представлені пакетом програм по обробці й статистичному аналізу соціологічних даних: Statistical Package for Social Science (SPSS). Він містить усі основні розділи аналізу даних і в багатьох закордонних і вітчизняних університетах є базовим при підготовці студентів гуманітарних факультетів. Посібник містить докладні покрокові інструкції з виконання команд, необхідних для одержання статистичної інформації.
Даний посібник надасть допомогу студентам спеціальностей «соціологія» і «соціальна робота» при роботі з SPSS: в обліку й організації вихідних даних, у виборі найбільш адекватного методу дослідження, в обчисленні статистичних показників, у проведенні більш глибокого аналізу даних і інтерпретації результатів досліджень.
Наш посібник включає лише ключові моменти практичного аналізу даних з використанням програми статистичної обробки інформації SPSS.
МОДУЛЬ 1. Теоретико-методологічні основи роботи із програмою SPSS
1 Загальна характеристика програми SPSS
SPSS - одна з найстарших систем статистичного аналізу й керування даними, продукт фірми SPSS Inc. (Statistical Products and Service Solution - Статистичні продукти й сервісні розв'язки), сьогодні SPSS є одним з лідерів серед універсальних статистичних пакетів.
Системні вимоги. Для роботи базової системи потрібен процесор 386 (рекомендується процесор 486/33Мгц), 4 Мб пам'яті (рекомендується 8 Мб), Windows 3.1 або старше, 20 Мб простору на диску.
Структура пакета
Пакет містить у собі команди визначення даних, перетворення даних, команди вибору об'єктів. У ньому реалізовані наступні методи статистичної обробки інформації:
сумарні статистики по окремих змінних;
частоти, сумарні статистики й графіки для довільного числа змінних;
побудова N-Мірних таблиць спряженості й одержання заходів зв'язки;
середні, стандартні відхилення й суми по групах;
дисперсійний аналіз і множинні порівняння;
кореляційний аналіз;
дискриминантный аналіз;
однофакторний дисперсійний аналіз;
обшая лінійна модель дисперсійного аналізу (GLM);
факторний аналіз;
кластерный аналіз;
ієрархічний кластерный аналіз;
ієрархічна балка-лінійний аналіз;
багатомірний дисперсійний аналіз;
непараметричні тести;
множинна регресія;
методи оптимального шкалирования;
і інш.
Крім того, пакет дозволяє одержувати різноманітні графіки – столбиковые й кругові, ящичковые діаграми, поля розсіювання й гистограммы й ін.
Інтерфейс. Пакет SPSS побудований як традиційна база даних: нагромадження масиву інформації, його формалізація й вистава результатів статистичної обробки масиву у вигляді звіту. Але тому що пакет призначений для виконання спеціалізованої функції - обробки результатів опитувань - він має структурну відмінність від традиційних баз даних, виражене в принципах формалізації масиву, що накопляється, вихідної інформації, принципах статистичної обробки й вистави результатів інформації.
Але зовнішніх відмінностей інтерфейсу від традиційних баз даних або електронних таблиць (MS Access, MS Excel і т.п.) ні, що значно спрощує перше знайомство з пакетом і дозволяє досить швидко почати процедуру введення або імпорту даних, крім того, пакет включає довідник і глосарій статистичних термінів.
Одна з нових особливостей SSPS - використання довгих імен файлів, що дозволяє трохи спростити ідентифікацію величезної кількості створюваних при роботі файлів.
Робота в пакеті SPSS здійснюється з використанням наступних типів вікон:
Вікно додатка SPSS. Це вікно включає головне меню системи, використовуване для операцій з файлами, вибору статистичних процедур і т.д., і інструментальну панель для швидкого доступу до деяких часто використовуваних функцій пакета.
Вікно висновку (output). Результати роботи в пакеті (описові статистики, таблиці спряженості, кореляційні матриці) виводяться в цім вікні. Уміст вікна можна редагувати й зберігати у файлі для наступного використання.
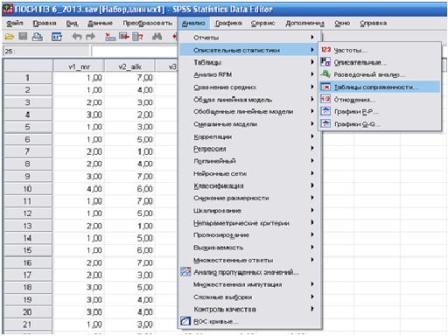
Вікно Редактора Даних (Data Editor). У цім вікні відображається вміст поточного файлу даних (мал.1.5). За допомогою Редактора Даних можна створювати нові файли даних або змінювати старі. Вікно відкривається автоматично при запуску SPSS.
Вікно "Каруселі Графіків" (Chart Carousel) призначене для висновку графіків, створених у пакеті. Графіки можна переглядати, коректувати, зберігати й видаляти.
Вікно Графіка (Chart), у якім можна змінити кольору, шрифти графіка, повернути осі, змінити тип.
Вікно Синтаксису (Syntax) для введення й редагування командних рядків. Команди в пакеті генеруються з використанням діалогових вікон, але використання командної мови дозволяє редагувати команди й зберігати у файл для використання в наступних сеансах.

Формат вихідних даних. Нагромадження результатів опитування в даному пакеті ведеться в редакторі SPSS Data Editor (мал. 1.5), дані зберігаються у форматі цього редактора (*.sav). Кожному спостереженню в таблиці відповідає певний рядок, а кожної змінної - певний стовпець. Припустимі наступні формати даних: речовинне число з фіксованою крапкою, речовинне число із плаваючою крапкою, дата й час, грошовий формат, текстової формат, також у користувача є можливість побудувати свій формат. Якщо дані відсутні, наприклад, респондент із якої-небудь причини не відповістив на поставлене запитання, то використовується конструкція Missing Values.
Структура пакета. SPSS являє собою модульну систему. Вартість повного комплекту модулів може обчислюватися тисячами доларів, але якщо потрібні базові функції, можна скористатися базовою системою SPSS Base. У базову систему закладені всі функції роботи з даними, усі основні статистичні процедури, від описових статистик і таблиць спряженості до факторного й кластерного аналізу.
Експорт і імпорт даних. Масив даних для обробки може бути експортований з текстового файлу, з файлу формату MS Excel, Lotus 1-2-3 або перенесений через буфер обміну.
Висновок результатів обробки. Результат статистичної обробки представляється в окремім вікні SPSS Output Navigator, який улаштований так само, як стандартний Провідник системи Windows, базові статистики виводяться в лівій частині вікна, а повна інформація - у правій.

SPSS Output Navigator представляє результати обробки або у вигляді таблиць, або у вигляді графіків (діаграм). У рамках однієї форми SPSS Output Navigator можливе розміщення всіх матеріалів - результатів статистичної обробки вихідного масиву. Якщо нажати праву клавішу миші, попередньо вказавши на відображувану в Navigator діаграму, можна потрапити в редактор діаграм Chart Editor.
Крім вставки графіків і діаграм з буфера обміну Windows можна експортувати їх у векторній формі як файли .wmf, .cgm і .eps, а також у растровому форматі як файли .bmp, tiff і pict. Також можна експортувати частина зображення й задавати коефіцієнт відносного подовження. Таким чином, можна вбудовувати графіки й діаграми SPSS в інше Windows-Додаток, але не навпаки.
Графічні можливості. Пакет має величезні можливості побудови графіків. У засобі Charts Carousel цієї програми виводяться всі типи можливих діаграм і графіків. Будувати їх можна по черзі або клацанням миші вибираючи ім'я потрібного графіка в прокручиваемом блоці Carousel. Діалогове вікно запитує специфікацію списку незалежних змінних і будь-яких факторних змінних. Після цього можна вибрати різні варіанти: прямокутні діаграми з викидами (box-and-whisker), деревоподібні діаграми (stem-and-leaf), графіки нормального розподілу й графіки розкиду крапок.
Стандартні засоби містять у собі стовпчасті діаграми, зафарбовані графіки, кругові діаграми, графіки мінімальних/максимальних значень, діаграми дисперсій і дисперсійні матриці (з перекриттям ліній регресії або без), а також гистограммы. Більш спеціалізовані графіки - це стовпчасті діаграми помилок, графіки контролю якості й графіки тимчасових рядів, наприклад, коррелограммы й автокоррелограммы.
Одержавши діаграму або графік, за допомогою кнопки Edit можна перейти у вікно редагування. У ньому виводиться новий інструментальний комплект, що дозволяє змінювати кольори графіка/діаграми, додавати лінії й типи зафарбування, міняти формати осей, лінії сітки й інші характеристики. Команда Annotation, дозволяє вводити текст, але лише в жорстко задані позиції.
До багатьом діаграмам і графікам можна додати тіні й різні тривимірні ефекти.
Донедавна більшим недоліком системи SPSS була відсутність його російськомовної версії. Сьогодні інтерфейс системи й документація повністю перекладені на російську мову.
2 Схема організації даних, вікна spss
Перш ніж приступитися до опису роботи з пакетом, необхідно розглянути списки вхідних (файлів даних) і вихідних файлів (створюваних пакетом у процесі його роботи).
До вхідних даних у системі SPSS ставляться:
Вихідні дані статистичних спостережень. Вони можуть бути представлені у вигляді системного Spss-Файлу даних, у вигляді Ascii-Файлу, файлу, одержуваного в електронних таблицях (EXCEL, QUATTRO) у вигляді файлів баз даних і ін.
Природно, серед цих видів даних найбільш зручні для роботи системні дані SPSS. Вони містять не тільки самі дані й імена змінних, але і їх розширені імена й мітки значень, а також інформацію про коди невизначених значень. Починаючи з 8-й версії SPSS, зберігається також інформація про неальтернативних змінних.
Імена файлів емпіричних даних SPSS мають розширення .sav. Безпосереднє введення даних і перегляд інформації в таких файлах в SPSS здійснюється через вікно редагування даних (SPSS for Windows Data Editor).
Дані, отримані з діалогів. Команди, запущені з меню, викликають діалогові вікна, які дозволяють призначити параметри й змінні для програм обробки даних.
Файли синтаксису, що містять завдання для пакета спеціалізованою мовою пакета. Використання в аналізі винятково діалогових вікон зручно тільки для новачка. Досвідчений фахівець пише справжні програми перетворення даних. Ці програми дозволяють у будь-який момент відтворити проведені розрахунки, виявити помилку перетворення даних. Вони легко модифікуються для розв'язку інших завдань.
Імена файлів із програмами мовою пакета мають розширення .sps. При необхідності ці файли можна зберігати для подальшої роботи.
Для створення програм мовою SPSS в SPSS передбачене вікно синтаксису (SYNTAX).
До вихідних даних ставляться:
Файли результатів, що містять таблиці, текстові результати, графіки, розрахунків, що мають імена з розширенням .SPO. За замовчуванням файлам результатів даються імена: OUTPUT.SPO. Для перегляду цих файлів використовується вікно навігатора висновку (OUTPUT). Частина вікна навігатора висновку відведена для дерева видачі, що полегшує перегляд результатів розрахунків.
Файли, які надалі можуть являти собою також вхідну інформацію.
Перетворені дані вхідного файлу даних спостережень (з расширением.sav), файл синтаксису (.sps) – також можуть стати вихідними даними.
Слід помітити, що крім зазначених вікон у пакеті можуть відкриватися й інші вікна, пов'язані з переглядом і редагуванням графіків, переглядом і редагуванням таблиць, написанням програм мовою більш низького рівня, чому мова синтаксису (Scripts).
Керування роботою пакета
Керування роботою пакета відбувається в основному через меню, при цьому дотримуються стандарти системи WINDOWS. Кожне вікно має своє меню, багато команд меню доступні з різних вікон. Основні команди меню SPSS:
FILE – Забезпечує доступ до файлів даних, до вихідних файлів і програмам перетворення даних. З файлами даних зв'язуються вікна. Якщо поточне вікно відповідає даним спостережень, то команда FILE обслуговує збереження й заміну даних. Якщо вікно містить файл синтаксису (SYNTAX) або видачі результатів рахунку (OUTPUT), то забезпечується обробка файлу синтаксису або видачі.
EDIT – Забезпечує редагування командних файлів, вихідних файлів і файлів даних статистичних спостережень і ін.
DATA – Забезпечує операції над даними, такі як, сортування, злиття різних файлів даних, агрегування, організацію подвыборки з даних. Ця команда є тільки в меню вікна редактора даних.
TRANSFORM – Забезпечує перетворення даних. Ця команда також є тільки в меню вікна редактора даних.
STATISTICS – Команда забезпечує доступ і реалізацію методів аналізу даних; починаючи з 9-й версії SPSS вона замінена на команду ANALISIS.
GRAPHS – Графічна вистава даних.
UTILITIES – Обслуговуючі програми.
WINDOOW – Забезпечує перемикання вікон.
HELP – Містить довідкову інформацію.
Наведені команди - далеко не повний опис меню, а лише найбільш використовувана його частина.
3 Можливості програми SPSS по обробці кількісної соціологічної інформації
Звичайно, збираючи дані, дослідник керується певними гіпотезами. Інформація ставиться до вибраних предмета й темі дослідження, але нерідко вона являє собою сирий матеріал, у якім необхідно вивчити структуру показників, що характеризують об'єкти, а також виявити однорідні групи об'єктів. Корисно представити цю інформацію в геометричному просторі, лаконічно відбити її особливості в класифікації об'єктів і змінних. Така робота створює передумови до створення типологий об'єктів і формуванню «соціального простору», у якім позначені відстані між об'єктами спостереження, що дозволяє наочно представити властивості об'єктів.
Наочна статистика
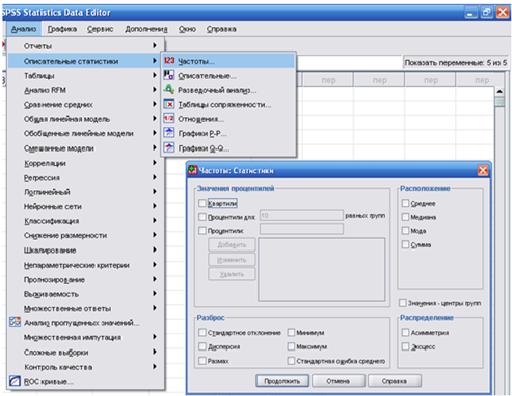
Дані опції дозволяють одержати описові статистики вибірки. Ліворуч праворуч, починаючи із другого стовпця: N – обсяг вибірки; мінімальне значення; максимальне значення; середнє значення; стандартне відхилення (синонім поняття «среднеквадратическое відхилення»). Перше й друге гнізда нижнього рядка вказують на число значень, придатних для розрахунків, що не є викидами й пропущеними значеннями).
Вибіркові таблиці – «Прості таблиці»
Тут надаються можливості по постачанню вибірки більшим набором різних характеристик.
Після клацання на рядку («Прості таблиці») відповідного списку, що розкривається, з'явиться вікон, натискання в якім на кнопку «Статистика…» викликає на екран друге вікно, що містить великий список статистичних понять (медіана, мода, середні, среднеквадратическое відхилення, процентили, варіативність, мінімальне й максимальне значення і т.д.) з них користувач може вибрати потрібні, які згодом будуть відбиті в таблиці.
Засоби порівняння
Тут розташовуються критерії для порівняння середнього, різні варіанти t-критерію Стьюдента для однієї вибірки (порівняння середнього значення з якимось числом, що задається); для двох незалежних вибірок (порівняння їх середніх). У результаті чого у файлі результатів будуть дані показник t-критерію, рівень статистичної значимості, стандартна помилка, значення довірчого інтервалу і т.д.
Кореляція
Тут розташовуються опції, призначені для проведення кореляційного аналізу.

Дисперсійний аналіз
За допомогою дисперсійного аналізу досліджують вплив однієї або декількох незалежних змінних на одну залежну змінну (одномірний аналіз) або на трохи залежних змінні (багатомірний аналіз). У звичайному випадку незалежні змінні ухвалюють тільки дискретні значення (і ставляться до номінальної або порядковій шкалі); у цій ситуації також говорять про факторний аналіз. Якщо ж незалежні змінні належать до интервальной шкалі або до шкали відносин, то їх називають ковариациями, а відповідний аналіз – ковариационным.
У рамках дисперсійного аналізу SPSS пропонує безліч можливостей.
Необхідно відзначити, що в принципі дисперсійний аналіз може виконуватися в рамках двох підходів:
за допомогою традиційного «класичного» методу по Фишеру;
за допомогою нового методу «узагальненої лінійної моделі».
Перший підхід зводиться до розкладання по методу найменших квадратів; в однофакторному випадку сукупна дисперсія всіх спостережуваних значень розкладається на дисперсію усередині окремих груп і дисперсію між групами. В основі узагальненої лінійної моделі напроти, лежить, кореляційний або регресійний аналіз.
Факторний аналіз
Ідея методу полягає в стиску матриці ознак у матрицю з меншим числом змінн інформацію, що зберігає майже ту ж саму, що й вихідна матриця. В основі моделей факторного аналізу лежить гіпотеза, що спостережувані змінні є непрямими проявами невеликого числа схованих (латентних) факторів. Хоча таку ідею можна приписати багатьом методам аналізу даних, звичайно під моделлю факторного аналізу розуміють вистава вихідних змінних у вигляді лінійної комбінації факторів.
Кластерный аналіз
Якщо процедура факторного аналізу стискає в мале число кількісних змінних дані, описані кількісними змінними, то кластерный аналіз стискає дані в класифікацію об'єктів. Синонімами терміна «кластерный аналіз» є «автоматична класифікація об'єктів без учителя» і «таксономія».
Якщо дані розуміти як крапки в признаковом просторі, то завдання кластерного аналізу формулюється як виділення «згущень крапок», розбивка сукупності на однорідні підмножини об'єктів.
При проведенні кластерного аналізу звичайно визначають відстань на безлічі об'єктів; алгоритми кластерного аналізу формулюють у термінах цих відстаней. Заходів близькості й відстаней між об'єктами існує безліч, їх вибирають залежно від мети дослідження. Зокрема, евклидово відстань краще використовувати для кількісних змінних, відстань хі-квадрат – для дослідження частотних таблиць, є безліч заходів для бінарних змінних.
Кластерный аналіз є описовою процедурою, він не дозволяє зробити ніяких статистичних висновків, але дає можливість провести своєрідну розвідку – вивчити «структуру сукупності».
Багатомірне шкалування
Завдання багатомірного шкалирования полягає в побудові змінних на основі наявних відстаней між об'єктами. Зокрема, якщо нам дані відстані між містами, програма багатомірного шкалирования повинна відновити систему координат ( з точністю до повороту й одиниці довжини) і приписати координати кожному місту так, щоб зрительно карта й зображення міст у цій системі координат збіглися. Близькість може визначатися не тільки відстанню в кілометрах, але й іншими показниками, такими як розміри міграційних потоків між містами, інтенсивність телефонних дзвінків, а також відстанями в багатомірному признаковом просторі. В останньому випадку завдання побудови такої системи координат близька до завдання, розв'язуваного факторних аналізом: стиску даних, опису їх невеликим числом змінних.
Нерідко потрібно також наочна вистава властивостей об'єктів. У цьому випадку корисно додати координати змінним, розташувавши змінні в геометричному просторі. З технічної точки зору це всього лише транспонування матриці даних. У соціальних дослідженнях методом багатомірного шкалирования створюють зоровий образ «соціального простору» об'єктів спостереження або властивостей. Для такого образа найбільш прийнятне створення двовимірного простору.
Основна ідея методу полягає в приписуванні кожному об'єкту значень координат так, щоб матриця евклідових відстаней між об'єктами в цих координатах, помножена на константу виявилася близька до матриці відстаней між об'єктами, певної з яких-небудь міркувань раніше. Метод досить трудомісткий і розрахований на аналіз даних, що мають невелике число об'єктів.
Таблиці спряженості
В SPSS є велика кількість різноманітних процедур, за допомогою яких можна зробити аналіз зв'язку між двома змінними. Зв'язок між неметричними змінними, тобто змінн, що ставляться до номінальної шкалу або до порядкової шкали з не дуже більшою кількістю категорій, найкраще представити у формі таблиць спряженості. Для цієї мети в SPSS перевіряється, чи їсти значима відмінність між спостережуваними й очікуваними частотами. Крім того, існує можливість розрахунків різних заходів зв'язаності.
Більш ретельно досліджувати існування залежності дозволяє обчислення значень очікуваних частот. Ще одну можливість виявлення існування залежності між змінними дає обчислення залишків. Ці залишки є показником того, наскільки сильно спостережувані й очікувані частоти відхиляються друг від друга.