

Построение дерева решений.
Для выделенных регионов построим дерево решений.
Выборка для данного анализа находится в файле Дерево решений.xls. От исходной выборки она отличается только тем, что для каждого региона отмечен класс, определенный на этапе кластерного анализа. Также в выборке остались только те признаки, которые были использованы в кластерном анализе для построения правил. Такими признаками являются: «Бахчевые культуры», «Картофель», «Молоко и молочные продукты», «Рыба и рыбопродукты», «Фрукты и ягоды», «Хлебные продукты» и «Яйца и яйцепродукты».
Основные продукты, потребляемые в регионах, являются входными данными, классы – выходными данными, название региона является информационным.
Построим дерево решений по 49 регионам и только по тем признакам, которые были выбраны в кластерном анализе, используя настройки по умолчанию, то есть минимальное количество примеров в узле, при котором будет создан новый равно 2 и процент доверия равен 20. В результате получилось следующее дерево решений (рис. 20).
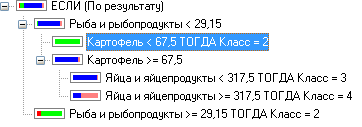
Рис. 20. Дерево решений
В данном случае для разбиения на классы используются 4 правила (рис. 21):
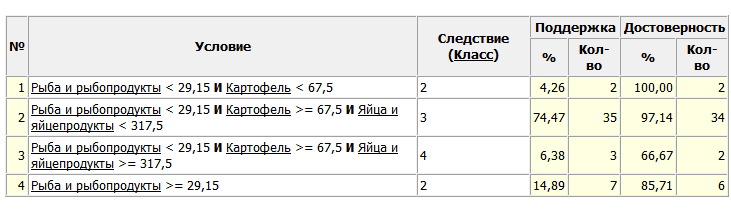
Рис. 21. Таблица правил для дерева решений
Но таблица сопряженности (рис. 22) показала, что при классифицировании возникли 3 ошибки классификации.
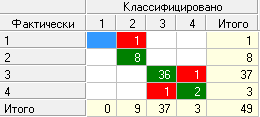
Рис. 22. Таблица сопряженности
Таблица 2. Ошибки классификации
Регион |
Классифицирован |
Фактический класс |
Чукотский АО |
2 |
1 |
Вологодская область |
4 |
3 |
Ставропольский край |
3 |
4 |
Изменяя параметры построения деревьев решений, попытаемся исправить ошибки распознавания.
Изменение процента доверия при неизменном минимальном количестве примеров в узле привел только к увеличению ошибок классификации. Увеличение минимального количества примеров в узле также привело к увеличению количества ошибок классификации. Уменьшив минимальное количество примеров в узле до 1, получили классификацию с одной ошибкой. Чтобы убрать эту ошибку увеличили процент доверия до 40%, увеличив таким образом количество правил. В результате получили безошибочную классификацию (рис. 23).
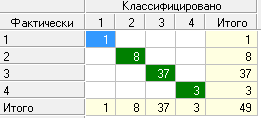
Рис. 23. Таблица сопряженности
Дерево решений выглядит следующим образом (рис. 24):

Рис. 24. Дерево решений
Строится данное дерево по следующим правилам:
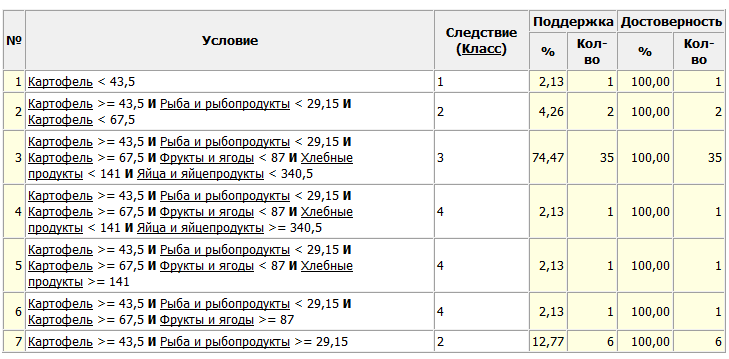
Рис. 25. Таблица правил для дерева решений
Из проведенного анализа можно сделать вывод, что при увеличении количества правил, улучшается качество распознавания. Правила для дерева решений показали, что для правильной классификации достаточно 5 признаков. Признак «Бахчевые культуры» в данных правилах не используется. Уберем его из выборки.
Нейросетевой анализ данных на основе обучения с учителем.
Для данного анализа будет использоваться выборка, полученная на предыдущем шаге. Данную выборку можно найти в файле Нейросетевой анализ.xls.
Выберем структуру нейронной сети. В качестве входных полей выберем основные продукты, потребляемые в регионах, в качестве выходного параметра – класс. Название региона будет информационным полем.
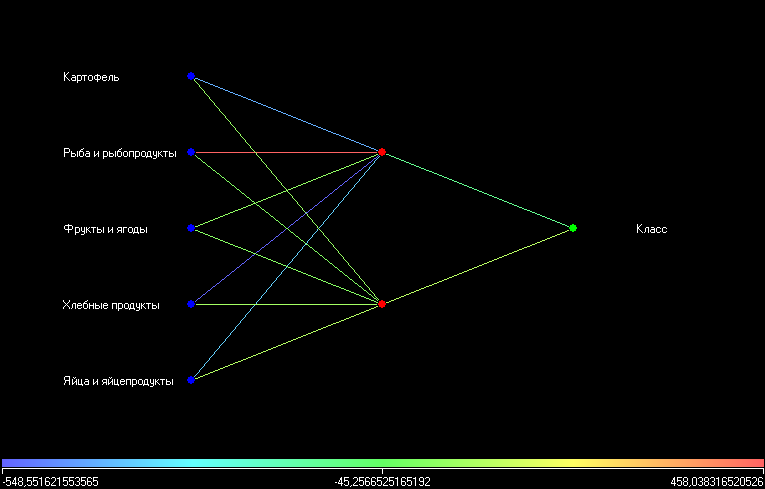
Рис. 26. Нейросеть [5х2х1]
В полученной нейронной сети (рис. 26) один скрытый слой с двумя нейронами. Обучение производилось со значением ошибки 0,005 и количеством эпох 10000.
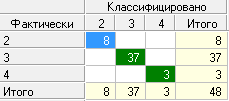
Рис. 27. Таблица сопряженности
Таблица сопряженности (рис. 27) показала, что все объекты были классифицированы без ошибок. Данное значение было достигнуто только при удалении из обучающей выборки класса с одним регионом, то есть класса с Чукотским АО. Причиной этого является слишком большое различие в значениях параметров, класс отстоит от остальных на большом расстоянии.