

Глава 1. Информационно-аналитические технологии анализа данных
1.1 Роль и место информационно-аналитических систем
Эффективное функционирование предприятий невозможно без оперативной, надежной, своевременной и достоверной информации, которая является основой процесса управления. Информационно-аналитические системы занимаются задачами, связанными с управлением информацией, что в свою очередь, включает в себя организацию и проведение сбора, хранения, обработку, передачу, анализ и предоставления информации.
Аналитические системы находятся на вершине иерархии информационных систем и охватывают задачи стратегического и тактического контуров управления [12].
В основании пирамиды иерархии информационных систем лежат автоматизированные системы управления технологическими процессами и транзакционные системы: ERP-системы, учетные и пр. Этот класс систем относится непосредственно к оперативному уровню управления. Промежуточным классом систем являются хранилища данных, включая слой ETL-инструментов. Они позволяют реализовать взаимосвязь оперативного и тактического контуров управления за счет возможности собрать единый и непротиворечивый массив данных из систем уровня оперативного управления. Концепция хранилища данных позволяет сформировать "единый источник истины", который обеспечивает дальнейшее использование информации для анализа и принятия решений.
Аналитические системы представляют собой автономные программные продукты, предназначенные для аналитической обработки управленческой информации, подготовки аналитической отчетности, экспертизы и анализа решений. Наиболее развитые из этих систем имеют средства информационного обмена и могут использоваться в качестве аналитических модулей корпоративных информационных систем. Информационно-аналитические системы используются в области финансового анализа, бизнес-планирования, маркетинга, прогнозирования, так же аналитические системы могут быть использованы в науке и выполнять функции сбора научных данных и информации об одном или более взаимосвязанных процессах.
1.2 Технологии извлечения данных
Последние годы характеризуются значительным ростом информатизации и компьютеризации различных коммерческих, производственных, государственных и других структур. Ключевым фактором их деятельности является оперативное принятие эффективных решений. Однако естественное стремление усовершенствовать процессы принятия решений нередко наталкивается на огромный объем и сложную структуру данных, содержащихся в разнообразных информационных системах.
Фактически базы данных выполняют функцию памяти, доступ пользователя к хранилищу данных обеспечивает только извлечение небольшой части из хранимой информации в ответ на четко задаваемые вопросы. Но когда мы имеем огромный поток информации, встает задача максимально целесообразно использовать эту информацию, чтобы извлечь спрятанное в данных знание с целью оптимизировать управление какими-либо процессами, улучшить деятельность организации. Можно было бы использовать армию аналитиков, статистиков, которые бы разбирались с этими данными, используя традиционные средства анализа данных. Не всегда получаемые аналитиками результаты являются объективными, поскольку люди руководствуются некоторыми соображениями, априорными представлениями об изучаемом предмете, что отражается на объективности получаемых результатов.
Методы «добычи» знаний (data mining) позволяют уменьшить остроту проблемы.[4] Используя продвинутые аналитические методы в области добычи знаний из исходных, “сырых”, данных, многие организации увеличивают прибыль, повышают производительность, сокращают затраты и увеличивают удовлетворенность клиентов. Они уже активно используются при анализе рынка, маркетинге, прогнозе фондовых котировок и других бизнес-приложениях. Но в первую очередь эти методы сегодня должны заинтересовать коммерческие предприятия, развертывающие проекты на основе информационных хранилищ данных (Data Warehousing).
Дадим сравнительную оценку возможностей анализа данных Человеком и компьютером. По оценке Дж. Неймана объем памяти мозга человека (число нейронов) составляет ~1020 бит. В то же время, физическое быстродействие отдельного биологического нейрона чрезвычайно низко по сравнению быстродействием современной вычислительной техники, оно на 8 порядков величины меньше быстродействия современного персонального компьютера и проигрывает суперкомпьютерам более десяти порядков величины. Соотношения объема и быстродействия памяти и определяют возможное использование искусственного интеллекта, систем KDD (Knowledge Discovery in Databases) – систем извлечения знаний из баз данных[12]. Однако ни одна программа принципиально не в состоянии сегодня, ни и в ближайшей перспективе учесть многообразия различных факторов, как ассоциативное мышление человека. Как постановщик задачи Человек принципиально превосходит возможности компьютера.
В то же время, если суметь направить усилия систем искусственного интеллекта (ИИ) по поиску нового знания, скрытых в данных закономерностей в жесткое русло, заданное человеком-аналитиком, гигантское преимущество компьютеров в быстродействии должно привести к качественному прорыву в достижении нового знания. Применение систем KDD требует известного искусства постановщика исследовательских задач, поскольку их решение в конечном итоге должно сочетаться с логикой его интуитивного анализа. Ключом к успешному применению методов KDD служит не просто выбор одного или нескольких алгоритмов KDD, а мастерство аналитика. Data Mining не исключает необходимости знания специфики предметной области и понимания самих данных или аналитических методов.
1.2.1 Data mining
Область Data Mining началась с семинара, проведенного Григорием Пятецким-Шапиро в 1989 году[14].
В 1993 году вышла первая рассылка «Knowledge Discovery Nuggets», а в 1994 году был создан один из первых сайтов по Data Mining.
Первоначально задача ставится следующим образом:
имеется достаточно крупная база данных;
предполагается, что в базе данных находятся некие «скрытые знания».
Необходимо разработать методы обнаружения знаний, скрытых в больших объёмах исходных «сырых» данных. В текущих условиях глобальной конкуренции именно найденные закономерности (знания) могут быть источником дополнительного конкурентного преимущества.
Что означает «скрытые знания»? Это должны быть обязательно знания:
ранее не известные — то есть такие знания, которые должны быть новыми (а не подтверждающими какие-то ранее полученные сведения);
нетривиальные — то есть такие, которые нельзя просто так увидеть (при непосредственном визуальном анализе данных или при вычислении простых статистических характеристик);
практически полезные — то есть такие знания, которые представляют ценность для исследователя или потребителя;
доступные для интерпретации — то есть такие знания, которые
легко представить в наглядной для пользователя форме и легко объяснить в терминах предметной области.
Эти требования во многом определяют суть методов Data mining и то, в каком виде и в каком соотношении в технологии Data mining используются системы управления базами данных, статистические методы анализа и методы искусственного интеллекта.
Методы Data mining имеет смысл применять только для достаточно больших баз данных. В каждой конкретной области исследований существует свой критерий достаточного размера базы данных.[38]
Развитие технологий баз данных сначала привело к созданию специализированного языка — языка запросов к базам данных. Для реляционных баз данных — это язык SQL, который предоставил широкие возможности для создания, изменения и извлечения хранимых данных. Затем возникла необходимость в получении аналитической информации (например, информации о деятельности предприятия за определённый период), и тут оказалось, что традиционные реляционные базы данных, хорошо приспособленные, например, для ведения оперативного учёта на предприятии, плохо приспособлены для проведения анализа. Это привело, в свою очередь, к созданию т. н. «хранилищ данных», сама структура которых наилучшим способом соответствует проведению всестороннего математического анализа
Задачи, решаемые методами Data Mining, принято разделять на описательные и предсказательные.[39]
В описательных задачах самое главное — это дать наглядное описание имеющихся скрытых закономерностей, в то время как в предсказательных задачах на первом плане стоит вопрос о предсказании для тех случаев, для которых данных ещё нет.
К описательным задачам относятся:
- поиск ассоциативных правил или паттернов (образцов);
- группировка объектов, кластерный анализ;
- построение регрессионной модели.
К предсказательным задачам относятся:
- классификация объектов (для заранее заданных классов);
- регрессионный анализ, анализ временных рядов.
Data mining — это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.[42]
1.2.2 KDD
Обнаружение знаний в базах данных(Knowledge discovery in databases) – аналитический процесс исследования человеком большого объема информации с привлечением средств автоматизированного исследования данных с целью обнаружения скрытых в данных структур или зависимостей. Предполагается полное или частичное отсутствие априорных представлений о характере скрытых структур и зависимостей.[14] KDD включает предварительное осмысление и неполную формулировку задачи (в терминах целевых переменных), преобразование данных к доступному для автоматизированного анализа формату и их предварительную обработку, обнаружение средствами автоматического исследования данных (data mining) скрытых структур или зависимостей, апробация обнаруженных моделей на новых, не использовавшихся для построения моделей данных и интерпретация человеком обнаруженных моделей.
Можно выделить следующие основные этапы исследования данных с помощью методов KDD:
Приведение данных к форме, пригодной для применения конкретных реализаций систем KDD. Для этого надо выработать четкий набор числовых или нечисловых параметров, характеризующих данную область. Выбор системы параметров производится человеком, хотя, значения параметров могут вычисляться автоматически. После выбора описывающих параметров данные могут быть представлены в виде прямоугольной таблицы, где каждая запись представляет собой отдельный объект или состояние объекта, а каждое поле – свойства или признаки всех исследуемых объектов. Практически все имеющиеся системы KDD работают только с подобными прямоугольными таблицами. Если же данные размещены в нескольких связанных между собой таблицах, то все равно необходимо привести их в прямоугольную форму
Полученная прямоугольная таблица пока еще является слишком сырым материалом для применения методов KDD, и входящие в нее данные необходимо предварительно обработать, так как они могут быть в разных форматах, могут быть неполными или избыточными. В случае избыточности данных необходимо ограничить количество полей. Некоторые поля являются неинформативными: почти все записи имеют одинаковое значение поля, или наоборот, количество записей приблизительно равно количеству значений этого поля. Наконец, полей может быть очень много, и если мы все их включим в исследование, то это сильно увеличит время счета, поскольку практически для всех методов KDD характерна сильная зависимость времени счета от количества параметров, поэтому необходимо выбрать самые значимые для исследования. Но существует не только избыточность полей, но и избыточность записей. Зачастую в системах при очень большом количестве записей их выбирают случайным образом или берут каждую n-ю запись таблицы. Конечно, количество записей сильно зависит от метода анализа, но практика показывает, что в основном записей должно быть не менее 30 и не более нескольких сотен тысяч. Во многих системах к данным предъявляют строгое требование: для каждой записи должно быть известно значение каждого поля. В этом случае приходится восполнять недостающие значения. Наиболее очевидным является заполнение отсутствующих значений средним значением. Также любая реальная база данных обычно содержит ошибки, очень неточно определенные значения, записи, соответствующие каким-то редким, исключительным ситуациям, и другие дефекты, которые могут резко понизить эффективность методов KDD, применяемых на следующих этапах анализа. Такие записи необходимо отбросить.
Идеальным случаем является случай, когда данные абсолютно не коррелируют друг с другом. Но на практике это практически неосуществимо. В случае сильной корреляции полей, можно взять одно из них. Рассмотрим пример прямоугольной таблицы для ценных бумаг:
Таблица 1.1 Пример таблицы ценных бумаг
Цена при открытии торгов |
Цена при закрытии |
Миним. цена за день |
Максим. цена за день |
В данном случае очевидна сильная корреляция полей. Поэтому вместо такой таблицы можно построить следующую:
Таблица 1.2 Пример таблицы ценных бумаг, с учетом корреляции
Среднее значение цены за день |
Изменение цены за день |
Еще
одним этапом подготовки данных является
их нормализация. Необходимо стараться
приближать данные к нормальному или
равномерному распределению. Часто
используют следующий способ нормализации:
пусть есть
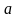 - среднее и
- среднее и
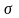 - дисперсия. Тогда
- дисперсия. Тогда
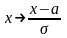 .
Часто такое преобразование проводят
перед подачей данных на вход нейросетей.
.
Часто такое преобразование проводят
перед подачей данных на вход нейросетей.
Замечание: если в таблице есть категориальная переменная (не числовая), которая, например, может принимать три значения, то можно вместо нее включить 3 новых переменных, которые будут принимать значение 1 для своего значения и 0 для всех остальных.
Третий этап – это применение методов KDD. Сценарии этого применения могут быть самыми различными и включать сложную комбинацию разных методов, особенно если используемые методы позволяют проанализировать данные с разных точек зрения. Собственно этот этап исследования и принято называть data mining.
Верификация и проверка получившихся результатов. Очень простой и часто используемый способ заключается в том, что все имеющиеся данные, которые мы собираемся анализировать, мы разбиваем на две группы. Как правило, одна из них – большего размера, другая – меньшего. На большей группе мы, применяя те или иные методы KDD, получаем модели, зависимости, все, что требуется в нашей задаче, а на меньшей группе данных мы их проверяем. И по разнице в точности между тестовой группой и группой, использованной для обучения, мы можем судить, насколько адекватна, статистически значима построенная модель.
последний этап – это интерпретация автоматически полученных знаний человеком в целях их использования для принятия решений, добавление получившихся правил и зависимостей в базы знаний и т.д.
Необходимо отметить, что работа с данными становится более эффективной, когда возможна интеграция следующих компонентов: визуализация, графический инструментарий, средства формирования запросов, оперативная аналитическая обработка, которые позволяют понять данные и интерпретировать результаты, и, наконец, сами алгоритмы, которые строят модели.
Одной из систем, которая объединяет в себе все перечисленные компоненты, является пакет PolyAlalyst компании «Megaputer Intelligence» (www.megaputer.ru),. В ее основу положена технология искусственного интеллекта Data Mining. При обработке исходных данных она позволяет обнаруживать многофакторные зависимости, которым придает затем вид функциональных выражений (класс функций в них практически произволен), можно также строить структурные и классификационные правила (по автоматически формируемым обучающим примерам). При этом анализу подвергаются исходные данные различных типов: действительные числа, логические и категориальные величины. Выводимые правила принимают вид либо функций, либо циклов, либо условных конструкций.
Система включает набор математических модулей, называемых Машинами исследований (Exploration engines),.[12] В последней версии программы 4.5, выпущенной компанией «Мегапьютер» в 2000 году имеется 10 машин исследований - это:
Поиск законов (FL - Find Laws) – эволюционное программирование
Поиск зависимостей (FD - Find Dependencies) – универсальный препроцессор
Классификация (CL - Classify) – на основе функции принадлежности
Деревья решений (DT - DecisionTree) – классификация на основе деревьев решений
Кластеризация (FC - Cluster) – многомерный кластеризатор
PolyNet Predictor (PN) – полиномиальная нейронная сеть
Множественная линейная регрессия (LR – Linear Regression)
Метод "ближайшего соседа" (MB) – гибрид алгоритма Nearest Neighbor и генетических алгоритмов
Basket Analysis (BA) – метод корзины покупателя
Общая статистика (SS – Summary Statistics) – модуль суммарной статистики
1.2.3 OLAP
OLAP (online analytical processing, аналитическая обработка в реальном времени) — технология обработки данных, заключающаяся в подготовке суммарной (агрегированной) информации на основе больших массивов данных, структурированных по многомерному принципу.
OLAP-структура, созданная из рабочих данных, называется OLAP-куб. Куб создаётся из соединения таблиц с применением схемы звезды или схемы снежинки. В центре схемы звезды находится таблица фактов, которая содержит ключевые факты, по которым делаются запросы[14]. Множественные таблицы с измерениями присоединены к таблице фактов. Эти таблицы показывают, как могут анализироваться агрегированные реляционные данные. Количество возможных агрегирований определяется количеством способов, которыми первоначальные данные могут быть иерархически отображены.
Например, все клиенты могут быть сгруппированы по городам или по регионам страны (Запад, Восток, Север и т. д.), таким образом, 50 городов, 8 регионов и 2 страны составят 3 уровня иерархии с 60 членами. Также клиенты могут быть объединены по отношению к продукции; если существуют 250 продуктов по 20 категориям, 3 группы продукции и 3 производственных подразделения, то количество агрегатов составит 16560. При добавлении измерений в схему количество возможных вариантов быстро достигает десятков миллионов и более.
OLAP-куб содержит в себе базовые данные и информацию об измерениях (агрегаты). Куб потенциально содержит всю информацию, которая может потребоваться для ответов на любые запросы. При огромном количестве агрегатов зачастую полный расчёт происходит только для некоторых измерений, для остальных же производится «по требованию».
Существуют три типа OLAP:
многомерная OLAP (Multidimensional OLAP — MOLAP);
реляционная OLAP (Relational OLAP — ROLAP);
гибридная OLAP (Hybrid OLAP — HOLAP).
MOLAP — это классическая форма OLAP, так что её часто называют просто OLAP. Она использует суммирующую БД, специальный вариант процессора пространственных БД и создаёт требуемую пространственную схему данных с сохранением как базовых данных, так и агрегатов. ROLAP работает напрямую с реляционным хранилищем, факты и таблицы с измерениями хранятся в реляционных таблицах, и для хранения агрегатов создаются дополнительные реляционные таблицы. HOLAP использует реляционные таблицы для хранения базовых данных и многомерные таблицы для агрегатов. Особым случаем ROLAP является ROLAP реального времени (Real-time ROLAP — R-ROLAP). В отличие от ROLAP в R-ROLAP для хранения агрегатов не создаются дополнительные реляционные таблицы, а агрегаты рассчитываются в момент запроса. При этом многомерный запрос к OLAP-системе автоматически преобразуется в SQL-запрос к реляционным данным.
Каждый тип хранения имеет определённые преимущества, хотя есть разногласия в их оценке у разных производителей. MOLAP лучше всего подходит для небольших наборов данных, он быстро рассчитывает агрегаты и возвращает ответы, но при этом генерируются огромные объёмы данных. ROLAP оценивается как более масштабируемое решение, использующее к тому же наименьшее возможное пространство. При этом скорость обработки значительно снижается. HOLAP находится посреди этих двух подходов, он достаточно хорошо масштабируется и быстро обрабатывается. Архитектура R-ROLAP позволяет производить многомерный анализ OLTP-данных в режиме реального времени.
Сложность в применении OLAP состоит в создании запросов, выборе базовых данных и разработке схемы, в результате чего большинство современных продуктов OLAP поставляются вместе с огромным количеством предварительно настроенных запросов. Другая проблема — в базовых данных. Они должны быть полными и непротиворечивыми.