

Одновременная многопотоковость.
Из-за проблемы масштабируемости SMP редко содержат более 8 процессоров. Однако при анализе эффективности работы процессора оказывается, что при выполнении большинства операций оказываются задействованными не все компоненты процессора (средняя загрузка порядка 30%). Разумно, если бы в программе были предусмотрены последовательности команд, выполняемые независимо друг от друга. Данная идея одновременной многопоточности (SMT) была предложена в 95 году Дином Турсаном и развита компанией Intel в виде гиперпоточности (НТ). При этом процессор дополняется средствами запоминания средствами потоков, специальными схемами контроля выполнения потоков и благодаря этому на активной стадии программы может находится несколько потоков команд. Число аппаратно-поддерживаемых потоков может быть равно 2, 4, 8 и более.
Многоядерность.
Технология многопоточности позволяет достичь многопроцессорности на логическом уровне. Дальнейшее повышение быстродействия лежит на пути совершенствования процессора. Более высокому быстродействию может способствовать возврат к «простым» процессорам с более низкой тактовой частотой и менее сложной логикой реализации. Фактически данных подход позволяет реализовать многоядерность.
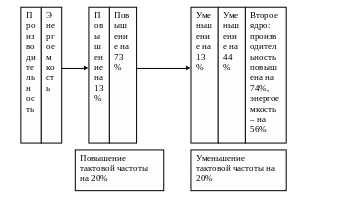
Архитектура многоядреного процессора практически соответствует архитектуре симметричного мультипроцессора.

Значимость этого подхода привела к новой формулировке закона Мура: каждые 18 месяцев количество ядер удваивается.
Потенциал производительности многопроцессорной техники может быть адекватно использован только при надлежащей разработке ПО, т.е. программы должны быть качественно распараллелены.
Системы с массовым параллелизмом.
Компьютеры этого типа представляют собой совокупность однородных вычислительных узлов, соединенных при помощи некоторой коммуникационной среды. Каждый узел обладает своей собственной памятью.
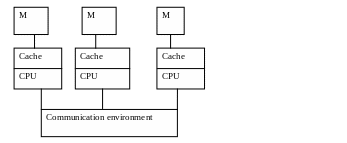
Каждый из узлов состоит из процессора, собственной ОП, коммуникационного оборудования и подсистемы ввода/вывода. Процессоры в этих системах имеют прямой доступ только к своей локальной памяти. Доступ к памяти других узлов реализуется при помощи механизма передачи сообщений (MPI). Подобная архитектура устраняет проблему когерентности кэш-памяти и проблему масштабирования, давая возможность неограниченного наращивания процессоров в системе. Для МРР-систем самой актуальной проблемой является эффективность коммуникационной среды. Различные производители использовали разные топологии связи. В Intel Paragon – двумерная прямоугольная сетка. В Cray – топология трехмерного тора. NСube – трехмерный гиперкуб. При обмене данными между процессорами, не являющимися ближайшими соседями, происходит трансляция данных через промежуточные узлы. Поэтому желательно, чтобы в узлах присутствовали аппаратные средства, освобождающие процессор от трансляции данных. В последнее время для этого используется иерархическая система высокоскоростных коммутаторов. Системы с распределенной памятью идеально подходят для выполнения независимых программ, поскольку каждая программа будет исполняться на своем узле. При разработке параллельных программ на МРР приходится учитывать более сложную структуру памяти, а именно трехуровневую. Первый – это кэш-память процессора, второй – локальная ОП данного узла, третий – ОП других узлов. При этом отсутствует доступ к данным, расположенным на других узлах. Обмен данными между узлами происходит значительно медленнее, чем обработка данных в ОП узлов.