

2.2.3. Выделение факторов, влияющих на успешность профессиональной деятельности
Поэтому следующий этап профессиографической работы -определение факторов, у которых только одна или несколько частей шкалы значений связаны с продуктивностью. Для этого необходимо разделить выборку на наиболее успешных и наименее успешных сотрудников. А затем узнать, есть ли у них статистически значимые различия в значениях данных факторов.
В самом простом случае критерием для разделения выборки на «успешных» и «неуспешных» будет средняя величина по показателю успешности. Однако такое деление является довольно грубым: лица, получившие близкие оценки по успешности, могут оказаться в противоположных группах, а лица, заметно различающиеся по оценкам успешности, - в одной и той же группе. Это может исказить результаты сопоставления групп, или, по край-,ней мере, сделать различия между группами менее заметными. I Чтобы избежать этого, мы выделили группы «успешных» и «неуспешных» специалистов более строго, включая в первую из них только тех, чьи значения превышают среднюю величину не менее чем на 0,5 стандартного отклонения, а во вторую группу -только тех, чьи значения не менее чем на 0,5 ниже средней величины. При этом все, кто оказывается в зоне средних величин, М± 0,5 σ, выпадают из дальнейших сопоставлений. Группа «успешных» составляется из сотрудников, имеющих показатели более М+0,5 σ по всем блокам методики ГОЛ (групповая оценка личности). «Неуспешные» - это сотрудники, имеющие по всем блокам показатели менее М-0,5 σ.
Выделение наиболее и наименее успешных проводится отдельно в каждой группе. Это является следствием ограничений методики ГОЛ, т. к. при групповой оценке личности сравнение степени успешности членов разных групп возможно лишь через ранговые показатели сотрудников в своих группах. Аналогично разделение проводится по социометрическим критериям: способность руководить; вклад в работу группы; референтность; эмоциональная привлекательность. Из всех возможных критериев сопоставления данных по алгоритмам, предложенным Е. В. Сидоренхо (49), наиболее подходящим был признан критерий φ* -угловое преобразование Фишера.
Если выборки сопоставляются по каким-либо количественно измеренным показателям, встает проблема выявления той точки распределения, которая может использоваться как критическая при разделении всех испытуемых на тех, у кого «есть эффект» и тех, у кого «нет эффекта».
В принципе, точку, по которой мы разделили бы группу на подгруппы, где есть эффект и нет эффекта, можно выбрать достаточно произвольно. Нас может интересовать любой эффект и, следовательно, мы можем разделить обе выборки на две части в любой точке, лишь бы это имело какой-то смысл.
Для того, чтобы максимально повысить мощность критерия φ*, нужно, однако, выбрать точку, в которой различия между двумя сопоставляемыми группами являются наибольшими. Точнее всего мы сможем сделать это с помощью критерия X (Колмогорова-Смирнова), позволяющего обнаружить точку максимального расхождения между двумя выборками.
Возможность сочетания критериев (φ* и λ описана Е. В. Гублером (18) и Е. В. Сидоренко (49).
В качестве примера рассмотрим анализ распределения показателей по фактору М (16-ти факторный личностный опросник Р. Кеттелла) у наиболее и наименее успешных сотрудников оформительских отделов таможни (60).
Точка максимального расхождения между двумя распределениями находится по следующему алгоритму:
Занести в таблицу наименования разрядов и соответствующие им эмпирические частоты, полученные в распределении 1 (первый столбец) и в распределении 2 (второй столбец).
Подсчитать эмпирические частности по каждому разряду для распределения 1 по формуле: φ*э = φjэ/n1,
где фэ - эмпирическая частота в данном разряде;
n1 - количество наблюдений в выборке.
Занести эмпирические частости распределения 1 в третий столбец.
3. Подсчитать эмпирические частости по каждому разряду для распределения 2 по формуле: φ*э = φэ/n2,
где φэ - эмпирическая частота в данном разряде;
n2 - количество наблюдений в выборке.
Занести эмпирические частости распределения 2 в четвертый столбец таблицы.
Подсчитать накопленные эмпирические частости для распределения 1 по формуле:
Sφ*j = S φj-l + φ*j,
где: S φ*j-1 - частость, накопленная в предыдущих разрядах,
j - порядковый номер разряда,
φ*j-1 - частость данного разряда. Полученные результаты записать в пятый столбец.
Подсчитать накопленные эмпирические частости для распределения 2 по той же формуле и записать результат в шестой столбец.
Подсчитать разности между накопленными частостями по каждому разряду. Записать в седьмой столбец абсолютные величины разностей без их знака. Обозначить их как d.
Определить по седьмому столбцу наибольшую абсолютную величину разности d max.
В результате диагностики личностных характеристик наиболее и наименее успешных сотрудников оформительских отделов таможни мы получили следующее распределение показателей по фактору М (16-ти факторный личностный опросник Р. Кеттелла)
Стеновые значения |
от 3 до 4 |
5 |
6 |
7 |
8 |
9 |
10 |
Кол-во значений у успешных |
10 |
15 |
16 |
22 |
12 |
19 |
5 |
Кол-во значений у неуспешных |
25 |
21 |
24 |
21 |
8 |
10 |
8 |
Преобразуем данные в таблицу следующего вида:
Стеновые значения |
Эмпирические частоты |
Эмпирические частости |
Накопленные эмпирические частости |
Разность |
|||
|
успешные |
не успешные |
(1) |
(2) |
(3) |
(4) |
(3-4) |
от 3 до 4 |
10 |
25 |
0. 101 |
0. 214 |
0. 101 |
0. 214 |
-0. 11267 |
5 |
15 |
21 |
0. 152 |
0,179 |
0. 253 |
0. 393 |
-0. 14064 |
6 |
16 |
24 |
0. 162 |
0,205 |
0. 414 |
0,598 |
-0. 18415 |
7 |
22 |
21 |
0. 222 |
0. 179 |
0. 636 |
0. 778 |
-0,14141 |
8 |
12 |
8 |
0. 121 |
0. 068 |
0,758 |
0,846 |
-0,08858 |
9 |
19 |
10 |
0. 192 |
0. 086 |
0. 949 |
0. 932 |
0. 017871 |
10 |
5 |
8 |
0. 051 |
0. 068 |
1 |
1 |
0 |
ИТОГО |
99 |
117 |
|
|
|
|
|
d max оказывается накопленной во второй категории показателей.
Сформулируем статистические гипотезы:
Н0: Доля наименее успешных сотрудников, получивших низкие показатели по фактору М (личностный опросник Кеттелла) не значимо выше, чем доля наиболее успешных работников.
Н1: Доля наименее успешных сотрудников, получивших низкие показатели по фактору М (личностный опросник Кеттелла) , значимо выше, чем доля наиболее успешных работников.
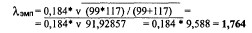
По таблице (49) р = 0,00408
Ответ: принимаем Н1.
Иными словами, более успешных работников характеризуют более высокие показатели по фактору М (личностный опросникКеттелла).
Результат такого анализа - составление профессиограммы определенной должностной или профессиональной категории персонала. В качестве примера в Приложении 2 представлен вариант профессиограммы сотрудника отдела таможенного оформления (с анализом факторов, не линейно влияющих на эффективность трудовой деятельности), разработанный А. П. Галентовым (40).