

«Методы многокритериальной оптимизации при создании асу процессами»
Векторный показатель
эффективности работы системы
![]() позволяет
найти компромисс между требованием
удовлетворить противоречивым критериям
Wi,i=1,2,…,m.
Следует сразу оговориться, что найденное
таким образом решение не является
оптимальным в математическом смысле.
Это – компромисс, «одинаково неудобный
для всех». Рассмотрим некоторые из
методов решения задачи многокритериальной
оптимизации.
позволяет
найти компромисс между требованием
удовлетворить противоречивым критериям
Wi,i=1,2,…,m.
Следует сразу оговориться, что найденное
таким образом решение не является
оптимальным в математическом смысле.
Это – компромисс, «одинаково неудобный
для всех». Рассмотрим некоторые из
методов решения задачи многокритериальной
оптимизации.
1. Метод выделения главного показателя:
Производится переоценка показателей эффективности, один из них (W1) объявляется наиболее существенным, а остальные критерии (W2,W3,…,Wm) переводятся в разряд ограничений:
![]()
![]()
2. Свертывание показателей эффективности (Линейная свертка):
Вектор показателей (Wi,W2,…,Wm) заменяется одним осредненным. Для каждого компонента вектора показателей эффективности можно найти весовой коэффициент άi , позволяющий его нормировать:
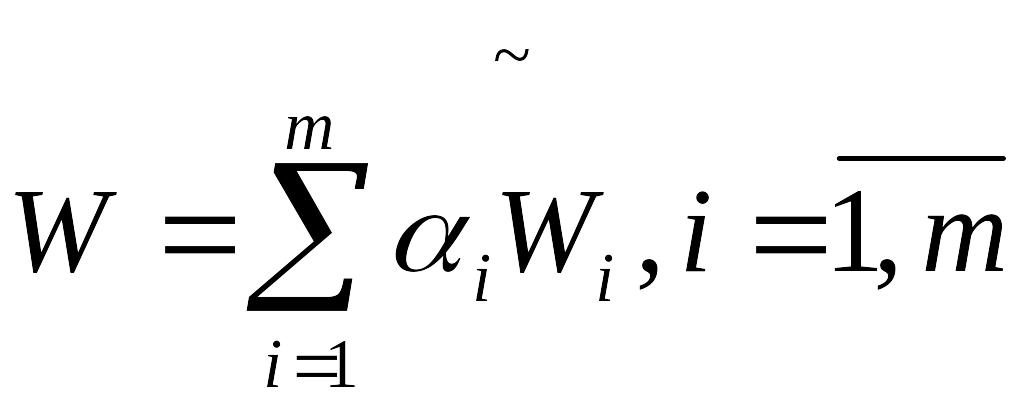
άi=1/(mWimax)
Таким образом, свертка будет изменяться в пределах 0≤W≤1.
Существуют и более сложные способы получения сверток: среднеквадратическое свертывание, минимаксное и т.д.
3. Последовательная оптимизация показателей с уступками:
1)Сначала устанавливаются предпочтения между всеми критериями:
W1├ W2├ …├Wm
2)Ищем
![]()
При
![]() заданные
экспертами оценки
заданные
экспертами оценки
3) Ищем
![]()
При
![]() заданные
экспертами оценки
заданные
экспертами оценки
W1=W1opt+ΔW1, ΔW1-величина уступки по показателю W1;
…
4) Ищем
![]()
При
![]() заданные
экспертами оценки
заданные
экспертами оценки
Wm-1=Wm-1opt+ΔWm-1, ΔWm-1-величина уступки по показателю Wm-1;
4. Построение множеств Парето (множеств несравнимых элементов):
Наиболее наглядно множества Парето используют для случая двух критериев (W1-W2.). Из множества различных методов, используемых для построения множеств Парето, воспользуемся методом прямоугольников:
В дальнейшем считаем, что показатели эффективности (W1,W2)→min.
Тогда: 1) Находим в пространстве критериев W1-W2 точки со значениями координат W1min-минимальный по критерию W1 вариант построения системы, и W2min-минимальный по критерию W2 вариант построения системы.
2)Проведем в указанных точках горизонтальную и вертикальную линии. Оставим для дальнейшего рассмотрения только точки, попавшие внутрь образовавшегося прямоугольника.
3)Две найденные точки принадлежат множеству Парето, удаляем их из рассмотрения и повторяем процедуру построения заново.
Каждый шаг процедуры позволяет находить 2 точки множества Парето.
Замечание: то, что на каждом шаге находятся две точки множества Парето связано с решением данной задачи на плоскости. Увеличение размерности задачи приводит к увеличению количества определяемых точек.
Окончательное решение о выборе оптимальной по многим критериям точки принимает эксперт.
Для выполнения лабораторной работы выберем два критерия: первый (W1)–величина суммы ряда, образуемого выборкой псевдослучайных величин.
![]()
Второй показатель эффективности связан с динамикой развития системы и вычисляется следующим образом:
На каждом шаге формирования выборки случайных чисел, начиная с 3-говычисляем оценку
![]() ,
,
И формируем оценку по формуле
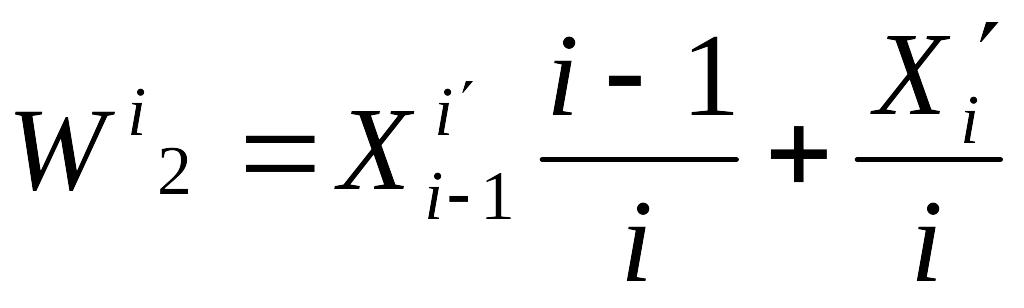
На последнем шаге формирования выборки (N=200, 250…) получаем один вариант построения системы (W1,W2)k, где k=1,2,…,20 –номер варианта построения системы.
Лекция №10, 11 – «Использование баз данных в САПР»
«Использование баз данных в САПР»
Распределенные базы данных невозможно рассматривать вне контекста более общей и более значимой темы распределенных информационных систем. Россия, в силу своего географического положения и размеров "обречена" на преимущественное использование распределенных систем. Это направление может успешно развиваться лишь при выполнении двух главных условий - адекватном развитии глобальной сетевой инфраструктуры и применении реальных технологий создания распределенных информационных систем.
Многие задачи "автоматизации в малом" или "автоматизации в среднем" уже решаются адекватными средствами на достаточно высоком технологическом уровне. Но вот задачи совершенно иного качества - задачи создания корпоративных информационных систем - нуждаются в осмыслении и анализе. Сложность нынешнего этапа во многом предопределена традиционализмом и инерционностью мышления, выражающейся в попытке переноса средств и решений локальной автоматизации в мир распределенных систем. Этот мир живет по своим законам, которые требуют иных технологий.
В большинстве же случаев преобладает стремление использовать знакомые, понятные, испробованные и поэтому родные средства для решения новых задач, принципиально отличающихся от того, чем приходилось заниматься раньше.
Поведение и мотивация разработчиков вполне понятны и оправданы. Ставится задача - построить информационную систему "клиент-сервер" на базе локальной сети с централизованной базой данных. Выбирается одна из популярных многопользовательских СУБД и какие-либо средства для быстрой разработки приложений. Наконец, создается сама система, представляющая собой комбинацию базы данных и обращающихся к ней приложений, в которых и реализована вся прикладная логика. Пока все это работает в ограниченном масштабе, все идет великолепно. Предположим, что организация, для которой выполнялась разработка, настолько выросла, что вновь возникшие задачи потребовали децентрализации хранения и обработки данных и, соответственно, развития информационной системы. Здесь и совершается ошибка. Подходы, хорошо зарекомендовавшие себя во вполне определенных условиях, автоматически переносятся в совершенно иную среду, с иными правилами жизнедеятельности. В результате система становится неработоспособной и должна быть создана заново, но уже с применением адекватных средств.
1. Распределенные базы данных
Под распределенной (Distributed DataBase - DDB) обычно подразумевают базу данных, включающую фрагменты из нескольких баз данных, которые располагаются на различных узлах сети компьютеров, и, возможно управляются различными СУБД. Распределенная база данных выглядит с точки зрения пользователей и прикладных программ как обычная локальная база данных. В этом смысле слово "распределенная" отражает способ организации базы данных, но не внешнюю ее характеристику. ("распределенность" базы данных невидима извне).
Лучшее определение распределенных баз данных (DDB) предложил Дэйт (C.J. Date). Он установил 12 свойств или качеств идеальной DDB:
Локальная автономия (local autonomy)
Независимость узлов (no reliance on central site)
Непрерывные операции (continuous operation)
Прозрачность расположения (location independence)
Прозрачная фрагментация (fragmentation independence)
Прозрачное тиражирование (replication independence)
Обработка распределенных запросов (distributed query processing)
Обработка распределенных транзакций (distributed transaction processing)
Независимость от оборудования (hardware independence)
Независимость от операционных систем (operationg system independence)
Прозрачность сети (network independence)
Независимость от баз данных (database independence)
Локальная автономия Это качество означает, что управление данными на каждом из узлов распределенной системы выполняется локально. База данных, расположенная на одном из узлов, является неотъемлемым компонентом распределенной системы. Будучи фрагментом общего пространства данных, она, в то же время функционирует как полноценная локальная база данных; управление ею выполняется локально и независимо от других узлов системы.
Независимость от центрального узла В идеальной системе все узлы равноправны и независимы, а расположенные на них базы являются равноправными поставщиками данных в общее пространство данных. База данных на каждом из узлов самодостаточна - она включает полный собственный словарь данных и полностью защищена от несанкционированного доступа.
Непрерывные операции Это качество можно трактовать как возможность непрерывного доступа к данным (известное "24 часа в сутки, семь дней в неделю") в рамках DDB вне зависимости от их расположения и вне зависимости от операций, выполняемых на локальных узлах. Это качество можно выразить лозунгом "данные доступны всегда, а операции над ними выполняются непрерывно".
Прозрачность расположения Это свойство означает полную прозрачность расположения данных. Пользователь, обращающийся к DDB, ничего не должен знать о реальном, физическом размещении данных в узлах информационной системы. Все операции над данными выполняются без учета их местонахождения. Транспортировка запросов к базам данных осуществляется встроенными системными средствами.
Прозрачная фрагментация Это свойство трактуется как возможность распределенного (то есть на различных узлах) размещения данных, логически представляющих собой единое целое. Существует фрагментация двух типов: горизонтальная и вертикальная. Первая означает хранение строк одной таблицы на различных узлах (фактически, хранение строк одной логической таблицы в нескольких идентичных физических таблицах на различных узлах). Вторая означает распределение столбцов логической таблицы по нескольким узлам. Рассмотрим пример, иллюстрирующий оба типа фрагментации. Имеется таблица employee (emp_id, emp_name, phone), определенная в базе данных на узле в Фениксе. Имеется точно такая же таблица, определенная в базе данных на узле в Денвере. Обе таблицы хранят информацию о сотрудниках компании. Кроме того, в базе данных на узле в Далласе определена таблица emp_salary (emp_id, salary). Тогда запрос "получить информацию о сотрудниках компании" может быть сформулирован так:
SELECT * FROM employee@phoenix, employee@denver ORDER BY emp_id
В то же время запрос "получить информацию о заработной плате сотрудников компании" будет выглядеть следующим образом:
SELECT employee.emp_id, emp_name, salary FROM employee@denver, employee@phoenix, emp_salary@dallas ORDER BY emp_id
Прозрачность тиражирования Тиражирование данных - это асинхронный (в общем случае) процесс переноса изменений объектов исходной базы данных в базы, расположенные на других узлах распределенной системы. В данном контексте прозрачность тиражирования означает возможность переноса изменений между базами данных средствами, невидимыми пользователю распределенной системы. Данное свойство означает, что тиражирование возможно и достигается внутрисистемными средствами.
Обработка распределенных запросов Это свойство DDB трактуется как возможность выполнения операций выборки над распределенной базой данных, сформулированных в рамках обычного запроса на языке SQL. То есть операцию выборки из DDB можно сформулировать с помощью тех же языковых средств, что и операцию над локальной базой данных. Например,
SELECT customer.name, customer.address, order.number, order.date FROM customer@london, order@paris WHERE customer.cust_number = order.cust_number
Обработка распределенных транзакций Это качество DDB можно трактовать как возможность выполнения операций обновления распределенной базы данных (INSERT, UPDATE, DELETE), не разрушающее целостность и согласованность данных. Эта цель достигается применением двухфазового или двухфазного протокола фиксации транзакций (two-phase commit protocol), ставшего фактическим стандартом обработки распределенных транзакций. Его применение гарантирует согласованное изменение данных на нескольких узлах в рамках распределенной (или, как ее еще называют, глобальной) транзакции.
Независимость от оборудования Это свойство означает, что в качестве узлов распределенной системы могут выступать компьютеры любых моделей и производителей - от мэйнфреймов до "персоналок".
Независимость от операционных систем Это качество вытекает из предыдущего и означает многообразие операционных систем, управляющих узлами распределенной системы.
Прозрачность сети Доступ к любым базам данных может осуществляться по сети. Спектр поддерживаемых конкретной СУБД сетевых протоколов не должен быть ограничением системы с распределенными базами данных. Данное качество формулируется максимально широко - в распределенной системе возможны любые сетевые протоколы.
Независимость от баз данных Это качество означает, что в распределенной системе могут мирно сосуществовать СУБД различных производителей, и возможны операции поиска и обновления в базах данных различных моделей и форматов.
Исходя из определения Дэйта, можно рассматривать DDB как слабосвязанную сетевую структуру, узлы которой представляют собой локальные базы данных. Локальные базы данных автономны, независимы и самоопределены; доступ к ним обеспечиваются СУБД, в общем случае от различных поставщиков. Связи между узлами - это потоки тиражируемых данных. Топология DDB варьируется в широком диапазоне - возможны варианты иерархии, структур типа "звезда" и т.д. В целом топология DDB определяется географией информационной системы и направленностью потоков тиражирования данных.
2. Архитектура "клиент-сервер"
Распределенные системы - это системы "клиент-сервер". Существует по меньшей мере три модели "клиент-сервер":
Модель доступа к удаленным данным (RDA-модель)
Модель сервера базы данных (DBS-модель)
Модель сервера приложений (AS-модель)
Первые две являются двухзвенными и не могут рассматриваться в качестве базовой модели распределенной системы (ниже будет показано, почему это так). Трехзвенная модель хороша тем, что в ней интерфейс с пользователем полностью независим от компонента обработки данных. Собственно, трехзвенной ее можно считать постольку, поскольку явно выделены:
Компонент интерфейса с пользователем
Компонент управления данными (и базами данных в том числе)
а между ними расположено программное обеспечение промежуточного слоя (middleware), выполняющее функции управления транзакциями и коммуникациями, транспортировки запросов, управления именами и множество других. Middleware - это ГЛАВНЫЙ компонент распределенных систем и, в частности, DDB-систем. Главная ошибка, которую мы совершаем на нынешнем этапе - полное игнорирование middleware и использование двухзвенных моделей "клиент-сервер" для реализации распределенных систем. Существует фундаментальное различие между технологией "SQL-клиент - SQL-сервер" и технологией продуктов класса middleware (например, менеджера распределенных транзакций Tuxedo System). В первом случае клиент явным образом запрашивает данные, зная структуру базы данных (имеет место так называемый data shipping, то есть "поставка данных" клиенту). Клиент передает СУБД SQL-запрос, в ответ получает данные. Имеет место жесткая связь типа "точка- точка", для реализации которой все СУБД используют закрытый SQL-канал (например, Oracle SQL*Net). Он строится двумя процессами: SQL/Net на компьютере - клиенте и SQL/Net на компьютере-сервере и порождается по инициативе клиента оператором CONNECT. Канал закрыт в том смысле, что невозможно, например, написать программу, которая будет шифровать SQL- запросы по специальному алгоритму (стандартные алгоритмы шифрования, используемые, например, в Oracle SQL*Net, вряд ли будут сертифицированы ФАПСИ).
В случае трехзвенной схемы клиент явно запрашивает один из сервисов (предоставляемых прикладным компонентом), передавая ему некоторое сообщение (например) и получает ответ также в виде сообщения. Клиент направляет запрос в информационную шину (которую строит Tuxedo System), ничего не зная о месте расположения сервиса. Имеет место так называемый function shipping (то есть "поставка функций" клиенту). Важно, что для Клиента база данных (в том числе и DDB) закрыта слоем Сервисов. Более того, он вообще ничего не знает о ее существовании, так как все операции над базой данных выполняются внутри сервисов.
Сравним два подхода. В первом случае мы имеем жесткую схему связи "точка-точка" с передачей открытых SQL-запросов и данных, исключающую возможность модификации и работающую только в синхронном режиме "запрос-ответ". Во втором случае определен гибкий механизм передачи сообщений между клиентами и серверами, позволяющий организовывать взаимодействие между ними многочисленными способами.
Таким образом, речь идет о двух принципиально разных подходах к построению информационных систем "клиент-сервер". Первый из них устарел и явно уходит в прошлое. Дело в том, что SQL (ставший фактическим стандартом общения с реляционными СУБД) был задуман и реализован как декларативный язык запросов, но отнюдь не как средство взаимодействия "клиент-сервер" (об этой технологии тогда речи не было). Только потом он был "притянут за уши" разработчиками СУБД в качестве такого средства. На волне успеха реляционных СУБД в последние годы появилось множество систем быстрой разработки приложений для реляционных баз данных (VisualBasic, PowerBuilder, SQL Windows, JAM и т.д.). Все они опирались на принцип генерации кода приложения на основе связывания элементов интерфейса с пользователем (форм, меню и т.д.) с таблицами баз данных. И если для быстрого создания несложных приложений с небольшим числом пользователей этот метод подходит как нельзя лучше, то для создания корпоративных распределенных информационных систем он абсолютно непригоден.
Для этих задач необходимо применение существенно более гибких систем класса middleware (Tuxedo System, Teknekron), которые и составляют предмет нашей профессиональной деятельности и базовый инструментарий при реализации больших проектов.
Сегодня можно считать, что распределенные базы данных - тема достаточно локальная и далеко не так актуальная, как архитектура распределенных систем. В DDB-технологии за последние 2-3 года не было каких-либо существенных новаций (за исключением, быть может, технологии тиражирования данных). Можно считать, что в этой сфере информатики все более или менее устоялось и каких-либо революционных шагов не предвидится. Более интересное направление (включающее DDB) - архитектура, проектирование и реализация распределенных информационных систем. "Горячие" темы в этом направлении - системы с трехзвенной архитектурой, продукты класса middleware, объектно-ориентированные средства разработки распределенных приложений в стандарте CORBA. Их активное применение будет доминировать в отечественной информатике в ближайшие 3-5 лет и станет технологической базой реальных интеграционных проектов.
Технологический взрыв в Intertet, создание и супербурное развитие Всемирной паутины, технология Java, неизбежно отразятся на организации инфраструктуры корпораций. Очевидные преимущества гипертекстовой организации данных (гибкость, открытость, простота развития и расширения) перед жесткими структурами реляционных баз данных, по своей природе плохо приспособленными для расширения, предопределяют использование HTML в качестве одного из основных средств создания информационного пространства компании. Подход, опирающийся на гипертексты, позволяет без особых проблем интегрировать уже существующие информационные массивы, хранящиеся в базах данных. То, что сейчас называют Intranet - это прообраз будущей корпоративной информационной системы.
Лекция №12, 13 – «Комплекс технических средств САПР»
«ТЕХНИЧЕСКОЕ ОБЕСПЕЧЕНИЕ САПР»
«Требования к ТО САПР»
Техническое обеспечение САПР включает в себя различные технические средства (hardware), используемые для выполнения автоматизированного проектирования, а именно ЭВМ, периферийные устройства, сетевое оборудование, а также оборудование некоторых вспомогательных систем (например, измерительных), поддерживающих проектирование.
Используемые в САПР технические средства должны обеспечивать:
1. выполнение всех необходимых проектных процедур, для которых имеется соответствующее ПО;
2. взаимодействие между проектировщиками и ЭВМ, поддержку интерактивного режима работы;
3. взаимодействие между членами коллектива, выполняющими работу над общим проектом.
Первое из этих требований выполняется при наличии в САПР вычислительных машин и систем с достаточными производительностью и емкостью памяти.
Второе требование относится к пользовательскому интерфейсу и выполняется за счет включения в САПР удобных средств ввода-вывода данных и прежде всего устройств обмена графической информацией.
Третье требование обусловливает объединение аппаратных средств САПР в вычислительную сеть. В результате общая структура ТО САПР представляет собой сеть узлов, связанных между собой средой передачи данных (рис.). Узлами (станциями данных) являются рабочие места проектировщиков, часто называемые автоматизированными рабочими местами (АРМ) или рабочими станцими (WS — Workstation), ими могут быть также большие ЭВМ (мейнфреймы), отдельные периферийные и измерительные устройства. Именно в АРМ должны быть средства для интерфейса проектировщика с ЭВМ. Что касается вычислительной мощности, то она может быть распределена между различными узлами вычислительной сети.
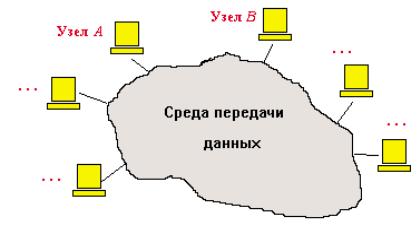
Рис. Структура технического обеспечения САПР
Среда передачи данных представлена каналами передачи данных, состоящими из линий связи и коммутационного оборудования.
В каждом узле можно выделить оконечное оборудование данных (ООД), выполняющее определенную работу по проектированию, и аппаратуру окончания канала данных (АКД), предназначенную для связи ООД со средой передачи данных. Например, в качестве ООД можно рассматривать персональный компьютер, а в качестве АКД — вставляемую в компьютер сетевую плату.
Канал передачи данных — средство двустороннего обмена данными, включающее в себя АКД и линию связи. Линией связи называют часть физической среды, используемую для распространения сигналов в определенном направлении, примерами линий связи могут служить коаксиальный кабель, витая пара проводов, волоконно-оптическая линия связи (ВОЛС). Близким является понятие канала (канала связи), под которым понимают средство односторонней передачи данных. Примером канала связи может быть полоса частот, выделенная одному передатчику при радиосвязи. В некоторой линии можно образовать несколько каналов связи, по каждому из которых передается своя информация. При этом говорят, что линия разделяется между несколькими каналами.
В САПР небольших проектных организаций, насчитывающих не более единиц-десятков компьютеров, которые размещены на малых расстояниях один от другого (например, в одной или нескольких соседних комнатах) объединяющая компьютеры сеть является локальной. Локальная вычислительная сеть (ЛВС или LAN — Local Area Network) имеет линию связи, к которой подключаются все узлы сети. При этом топология соединений узлов (рис.) может быть шинная (bus), кольцевая (ring), звездная (star). Протяженность линии и число подключаемых узлов в ЛВС ограничены.
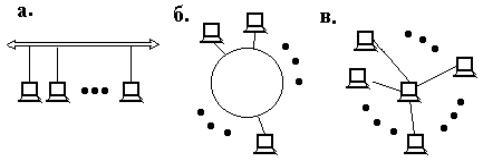
Рис. Варианты топологии локальных вычислительных сетей:
а) шинная; б) кольцевая; в) звездная
В более крупных по масштабам проектных организациях в сеть включены десятки-сотни и более компьютеров, относящихся к разным проектным и управленческим подразделениям и размещенных в помещениях одного или нескольких зданий. Такую сеть называют корпоративной. В ее структуре можно выделить ряд ЛВС, называемых подсетями, и средства связи ЛВС между собой. В эти средства входят коммутационные серверы (блоки взаимодействия подсетей). Если коммутационные серверы объединены отделенными от ЛВС подразделений каналами передачи данных, то они образуют новую подсеть, называемую опорной (или транспортной), а вся сеть оказывается иерархической структуры.
Если здания проектной организации удалены друг от друга на значительные расстояния (вплоть до их расположения в разных городах), то корпоративная сеть по своим масштабам становится территориальной сетью (WAN — Wide Area Network). В территориальной сети различают магистральные каналы передачи данных (магистральную сеть), имеющие значительную протяженность, и каналы передачи данных, связывающие ЛВС (или совокупность ЛВС отдельного здания или кампуса) с магистральной сетью и называемые абонентской линией или соединением «последней мили».
Обычно создание выделенной магистральной сети, т.е. сети, обслуживающей единственную организацию, обходится для нее слишком дорого. Поэтому чаще прибегают к услугам провайдера, т.е. организации, предоставляющей телекоммуникационные услуги многим пользователям. В этом случае внутри корпоративной сети связь на значительных расстояниях осуществляется через магистральную сеть общего пользования. В качестве такой сети можно использовать, например, городскую или междугородную телефонную сеть или территориальные сети передачи данных. Наиболее распространенной формой доступа к этим сетям в настоящее время является обращение к глобальной вычислительной сети Internet.
Для многих корпоративных сетей возможность выхода в Internet является желательной не только для обеспечения взаимосвязи удаленных сотрудников собственной организации, но и для получения других информационных услуг. Развитие виртуальных предприятий, работающих на основе CALS-технологий, с необходимостью подразумевает информационные обмены через территориальные сети, как правило, через Internet.
«АППАРАТУРА РАБОЧИХ МЕСТ В АВТОМАТИЗИРОВАННЫХ СИСТЕМАХ ПРОЕКТИРОВАНИЯ И УПРАВЛЕНИЯ»
В качестве средств обработки данных в современных САПР широко используют рабочие станции, серверы, персональные компьютеры. Большие ЭВМ и в том числе суперЭВМ обычно не применяют, так как они дороги и их отношение производительность/цена существенно ниже подобного показателя серверов и многих рабочих станций.
На базе рабочих станций или персональных компьютеров создают АРМ. Типичный состав устройств АРМ: ЭВМ с одним или несколькими микропроцессорами, оперативной и кэш-памятью и шинами, служащими для взаимной связи устройств; устройства ввода-вывода, включающие в себя, как минимум, клавиатуру, мышь, дисплей; дополнительно в состав АРМ могут входить принтер, сканер, плоттер (графопостроитель), дигитайзер и некоторые другие периферийные устройства.
Память ЭВМ обычно имеет иерархическую структуру. Поскольку в памяти большого объема трудно добиться одновременно высокой скорости записи и считывания данных, память делят на сверхбыстродействующую кэш-память малой емкости, основную оперативную память умеренного объема и сравнительно медленную внешнюю память большой емкости, причем, в свою очередь, кэш-память часто разделяют на кэш первого и второго уровней.
Например, в персональных компьютерах на процессорах Pentium III кэш первого уровня имеет по 16 Кбайт для данных и для адресов, он и кэш второго уровня емкостью 256 Кбайт встроены в процессорный кристалл, емкость оперативной памяти составляет десятки-сотни Мбайт.
Для связи наиболее быстродействующих устройств (процессора, оперативной и кэш-памяти, видеокарты) используется системная шина с пропускной способностью до одного-двух Гбайт/с. Кроме системной шины на материнской плате компьютера имеются шина расширения для подключения сетевого контроллера и быстрых внешних устройств (например, шина PCI с пропускной способностью 133 Мбайт/с) и шина медленных внешних устройств, таких как клавиатура, мышь, принтер и т.п.
Рабочие станции (workstation) по сравнению с персональными компьютерами представляют собой вычислительную систему, специализированную на выполнение определенных функций. Специализация обеспечивается как набором программ, так и аппаратно за счет использования дополнительных специализированных процессоров. Так, в САПР для машиностроения преимущественно применяют графические рабочие станции для выполнения процедур геометрического моделирования и машинной графики. Эта направленность требует мощного процессора, высокоскоростной шины, памяти достаточно большой емкости.
Высокая производительность процессора необходима по той причине, что графические операции (например, перемещения изображений, их повороты, удаление скрытых линий и др.) часто выполняются по отношению ко всем элементам изображения. Такими элементами в трехмерной 3D-графике при аппроксимации поверхностей полигональными сетками являются многоугольники, их число может превышать 104. С другой стороны, для удобства работы проектировщика в интерактивном режиме задержка при выполнении команд указанных выше операций не должна превышать нескольких секунд. Но поскольку каждая такая операция по отношению к каждому многоугольнику реализуется большим числом машинных команд требуемое быстродействие составляет десятки миллионов машинных операций в секунду. Такое быстродействие при приемлемой цене достигается применением наряду с основным универсальным процессором также дополнительных специализированных (графических) процессоров, в которых определенные графические операции реализуются аппаратно. В наиболее мощных рабочих станциях в качестве основных обычно используют высоко производительные микропроцессоры с сокращенной системой команд (с RISC-архитектурой), работающие под управлением одной из разновидностей операционной системы Unix. В менее мощных все чаще используют технологию Wintel (т.е. микропроцессоры Intel и операционные системы Windows). Графические процессоры выполняют такие операции, как, например, растеризация — представление изображения в растровой форме для ее визуализации, перемещение, вращение, масштабирование, удаление скрытых линий и т.п.
Типичные характеристики рабочих станций: несколько процессоров, десятки-сотни мегабайт оперативной и тысячи мегабайт внешней памяти, наличие кэш-памяти, системная шина со скоростями от сотен Мбайт/с до 1-2 Гбайт/с.
В зависимости от назначения существуют АРМ конструктора, АРМ технолога, АРМ руководителя проекта и т.п. Они могут различаться составом периферийных устройств, характеристиками ЭВМ.
Лекция №14, 15 – «Программное обеспечение САПР»
«Программное обеспечение САПР»
Появление компонентно-ориентированных технологий вызвано необходимостью повышения эффективности разработки сложных программных систем, являющихся в условиях использования корпоративных и глобальных вычислительных сетей распределенными системами. Компонентно-ориентированные технологии основаны на использовании предварительно разработанных готовых программных компонентов.
Компиляция программ из готовых компонентов — идея не новая. Уже первые шаги в области автоматизации программирования были связаны с созданием библиотек подпрограмм. Конечно, для объединения этих подпрограмм в конкретные прикладные программы требовалась ручная разработка значительной части программного кода на языках третьего поколения. Упрощение и ускорение разработки прикладного ПО достигается с помощью языков четвертого поколения (4GL), но имеющиеся системы на их основе являются специализированными и не претендуют на взаимодействие друг с другом.
Современные системы интеграции ПО построены на базе объектной методологии. Так, выше приведены примеры библиотек классов, применяя которые прикладные программисты могут создавать субклассы в соответствии с возможностями наследования, заложенными в используемые объектно-ориентированные языки программирования. При этом интероперабельность компонентов в сетевых технологиях достигается с помощью механизмов, подобных удаленному вызову процедур RPC. К библиотекам классов относятся MFC, библиотеки для доступа к реляционным БД (например, для встраивания в прикладную программу драйверов ODBC) и др.
Преимущества использования готовых компонентов обусловлены тщательной отработкой многократно используемых компонентов, их соответствием стандартам, использованием лучших из известных методов и алгоритмов.
В то же время в компонентах библиотек классов спецификации интерфейсов не отделены от собственно кода, следовательно, использование библиотек классов не профессиональными программистами проблематично. Именно стремление устранить этот недостаток привело к появлению CBD — компонентно-ориентированных технологий разработки ПО. Составными частями таких технологий являются унифицированные способы интеграции программного обеспечения.
Возможны два способа включения компонентов (модулей) в прикладную программу — модернизация (reenginering) или инкапсуляция (encapsulation или wrapping).
Модернизация требует знания содержимого компонента, интероперабельность достигается внесением изменений собственно в сам модуль. Такой способ можно назвать способом “белого ящика”.
Очевидно, что модернизация не может выполняться полностью автоматически, требуется участие профессионального программиста.
Инкапсуляция выполняется включением модуля в среду с помощью интерфейса — его внешнего окружения (оболочки — wrapper). При этом компонент рассматривается как “черный ящик”: спецификации, определяющие интерфейс, выделены из модуля, а детали внутреннего содержимого скрыты от пользователя. Обычно компоненты поставляются в готовом для использования виде скомпилированного двоичного кода. Обращения к модулю возможны только через его интерфейс. В спецификации интерфейса включаются необходимые для интероперабельности сведения о характеристиках модуля — модульная абстракция. В состав этих сведений могут входить описания всех входных и выходных для модуля данных (в том числе имеющихся в модуле интерактивных команд), структура командной строки для инициализации процедур, сведения о требуемых ресурсах.
Компонентно-ориентированные системы построены на основе инкапсуляции компонентов. В архитектуре этих систем можно выделить следующие части: 1) прикладная программа (клиент), создаваемая для удовлетворения возникшей текущей потребности; 2) посредник (брокер или менеджер), служащий для установления связи между взаимодействующими компонентами и для согласования их интерфейсных данных; 3) множество компонентов, состоящих каждый из программного модуля, реализующего некоторую полезную функцию, и оболочки (интерфейса). В спецификации интерфейса могут быть указаны характеристики модуля, реализуемые методы и связанные с модулем события (например, реакции на нажатие клавиш).
Собственно интерфейс представляет собой обращения к функциям модуля, называемым в СВD-технологиях методами. Эти обращения переводятся в двоичный код, что обеспечивает при их использовании независимость от языка программирования. Один и тот же модуль может реализовывать несколько разных функций, поэтому у него может быть несколько интерфейсов или методов. Каждый новый создаваемый интерфейс обеспечивает доступ к новой функции и не отменяет прежние возможно еще используемые интерфейсы. Схематично взаимодействие компонентов можно представить следующим образом. Клиент обращается с запросом на выполнение некоторой процедуры. Запрос направляется к посреднику. В посреднике имеется предварительно сформированный каталог (реестр или репозиторий) интерфейсов процедур с указанием компонентов-исполнителей. Посредник перенаправляет запрос соответствующему исполнителю. Исполнитель может запросить параметры процедуры. После выполнения процедуры полученные результаты возвращаются клиенту.
При этом пользователь оперирует удобными для его восприятия идентификаторами компонентов и интерфейсов, а с помощью каталога эти идентификаторы переводятся в указатели (ссылки), используемые аппаратно-программными средствами и которые однозначно определяют интерфейс в распределенной сети из многих компьютеров.
В большинстве случаев реализуется синхронный режим работы, подразумевающий приостановку процесса клиента после выдачи запроса до получения ответа. Наиболее популярными в настоящее время являются следующие CBD-технологии.
— OpenDoc — технология, основанная на спецификациях CORBA, разработанных в начале 90-х г.г. специально созданным консорциумом OMG, в который вошли представители ведущих компьютерных фирм. В OpenDoc реализуется технология распределенных вычислений на базе программ-посредников ORB.
— COM (Common Object Model) — технология, развиваемая корпорацией Microsoft на базе механизма OLE. Сетевой вариант этой технологии (для систем распределенных вычислений) известен под названием DCOM (Distributed COM). Объекты DCOM (в частности, объекты, которые можно вставлять в HTML-документы или к которым можно обращаться из Web-браузеров) известны под названием компонентов ActiveX. В СОМ/DCOM, как и в OpenDoc, можно использовать компоненты, написанные на разных объектно-ориентированных языках программирования. Но в отличие от OpenDoc в СОМ/DCOM остается естественная для Microsoft ориентация только на операционные системы Windows (реализация DCOM предусмотрена в ОС Windows NT 4.0). Технология ActiveX (прежнее название OLE Automation) обеспечивает интерфейс для управления объектами одного приложения из другого. В общем плане ActiveX — технология интеграции программного обеспечения фирмы Microsoft. Например, используя эту технологию, можно в среде VBA организовать доступ к объектам AutoCAD.
— JavaBeans — сравнительно новая технология, в которой используются компоненты, написанные на языке Java.
Развитие CBD-систем возможно в направлении дальнейшего упрощения программирования и, следовательно, сокращения сроков разработки ПО, однако это происходит за счет снижения степени универсальности соответствующих инструментальных средств. Такие более специализированные средства представляют собой группу компонентов, взаимосвязанных некоторым зависящим от приложения образом, и входят в системные среды САПР. В общем случае компоненты системной среды объединены в несколько сценариев (потоков процедур или маршрутов), в которых выделяются точки входа для вставки специфичных пользовательских фрагментов и расширений. Имеются возможности не только вставки новых фрагментов, но и замены исходных компонентов в потоках процедур на оригинальные с сохранением интерфейса. Собственно многие системы, основанные на применении языков четвертого поколения (4GL), относятся именно к таким системным средам, в которых последовательности инкапсулированных модулей образуются с помощью операторов 4GL.