

Назначение систем аналитической обработки данных
Системы аналитической обработки решают задачи анализа ранее накопленной информации в целях ориентировки служб и персонала в процессе управления банком, в связи с чем подобные системы часто называют системами поддержки принятия решений. В зарубежной литературе они получили название Decision Support System (DSS).
Система принятия решений позволяет на основе накопленных данных получить показатели, определяющие закономерности развития банка и эффективность его работы. В частности на систему аналитической обработки данных может быть возложено решение следующих задач:
получение консолидированной отчетности многофилиального банка и проверка ее полноты и корректности;
проведение группировки статей баланса, расчет экономических нормативов и аналитических коэффициентов (например, по методу CAMEL);
определение рейтинга банка;
анализ динамики основных показателей, выявление тенденций и прогнозирование состояния банка;
анализ степени влияния тех или иных факторов на состояние банка;
выработка рекомендаций по оптимизации банковского баланса.
Основные особенности систем аналитической обработки информации заключаются в следующем:/35/
анализ может быть затребован в любой момент;
в зависимости от цели анализа может меняться не только форма, но и содержание аналитического отчета;
в качестве исходного материала могут использоваться не только данные бухгалтерского учета, но и другие данные, в том числе внешние по отношению к банку.
В качестве инструмента создания аналитических банковских систем используют программные продукты, реализующие технологии создания многомерных массивов данных – так называемые OLAP (On-Line Analytical Processing) приложения и позволяющие проводить интеллектуальный анализ информации.
Архитектура систем аналитической обработки данных

Рис. 1 Архитектура системы многомерного интеллектуального анализа данных
Термин OLAP был введен в 1993 году коллективом в составе: E.F. Codd, S.B. Codd и C.T. Salley в статье “Providing OLAP (On-Line Analytical Processing) to user-analysts: An IT man-date.” в которой впервые было дано формальное определение OLAP-технологии и описаны основные правила OLAP. В последствии эти правила получили название двенадцати правил Кодда.
Таблица 2 Двенадцать правил Кодда
№ |
Правило |
Пояснения |
|
|
Многомерная модель (Multidimensional model) |
Данные для пользователя должны быть представлены в многомерной парадигме |
|
|
Прозрачность от сервера (Transparency of the server) |
Пользователь не обязан знать, что он использует базу данных OLAP |
|
|
Доступность (Accessibility) |
Для поддержки запросов программное средство должно выбирать самый лучший источник данных |
|
|
Постоянность характеристик производительности (Stable access performance) |
Производительность должна быть одинаковой, независимо от числа используемых измерений |
|
|
Архитектура клиент/сервер (Client server architecture) |
Программные средства должны работать в архитектуре клиент/сервер |
|
|
Общность измерений (Generic Dimensionality) |
Все измерения должны быть равноправными; не может быть”крена” в сторону какого-то одного измерения |
|
|
Управление разреженными данными (Management of data sparsity) |
Нулевые (null) значения должны храниться эффективно |
|
|
Наличие многих пользователей (Multi-user) |
Программные средства должны поддерживать более одного пользователя |
|
|
Операции с измерениями (Operation on dimension) |
Правила агрегации единообразно и согласованно применяются ко всем измерениям |
|
|
Интуитивное манипулирование данными (Intuitive manipulation of data) |
Пользовательские представления данных должны содержать все необходимое для того, что бы он не прибегал к использованию меню и других сложных элементов интерфейса |
|
|
Гибкое позиционирование и отчетность (Flexible posting and editing) |
Пользователи должны иметь возможность представлять данные в любой удобной для них форме |
|
|
Множественность измерений и уровней (Multiple dimensions and levels) |
Модель не должна иметь ограничений на число измерений и уровней агрегации |
Сегодня универсальным критерием определения OLAP как инструмента является тест FASMI (Fast Analysis of Shared Multidimensional Information — быстрый анализ разделяемой многомерной информации). Каждая из составляющих этой аббревиатуры имеет важный смысл, определяя характеристики современной OLAP-системы/19/:
Fast (быстрая) — обеспечивает ответ на запрос пользователя в среднем за пять секунд; при этом большинство запросов обрабатываются в пределах одной секунды, а самые долгие — в пределах 20 секунд. Как показывает практика, пользователь начинает сомневаться в успешности запроса, если он занимает более 30 секунд;
Analysis (аналитическая) — выполняет необходимый логический и статистический анализ и обеспечивать сохранение результатов в виде, доступном для конечного пользователя;
Shared (разделяемая) — предоставляет широкие возможности разграничения доступа к данным и одновременную работу многих пользователей;
Multidimensional (многомерная) — обеспечивает концептуально многомерное представление данных, включая полную поддержку множественных иерархий;
Information (информация) — мощность различных OLAP-систем характеризуется количеством обрабатываемых входных данных: передовые OLAP-решения могут оперировать, по крайней мере, в тысячу раз большим количеством данных по сравнению с самыми маломощными. При выборе OLAP-инструмента также следует учитывать целый ряд факторов, включая дублирование данных, требуемую оперативную память, использование дискового пространства, эксплуатационные показатели, интеграцию с информационными хранилищами и т.п.
OLAP системы обладают средствами предоставления пользователю агрегатных данных для различных выборок из исходного набора в удобном для восприятия и анализа виде. Как правило, такие агрегатные функции образуют многомерный набор данных (называемый гиперкубом или метакубом), оси которого содержат параметры, а ячейки — зависящие от них агрегатные данные. Вдоль каждой оси данные могут быть организованы в виде иерархии, представляющей различные уровни их детализации. Благодаря такой модели данных пользователи могут формулировать сложные запросы, генерировать отчеты, получать подмножества данных.
Предположим, имеется некоторый массив данных характеризующий деятельность банка.
Таблица 3 Массив показателей деятельности банка
Филиал |
Вид услуги |
Отчетный период |
Полученный доход |
Филиал 1 |
РКО |
январь |
102 |
Филиал 1 |
РКО |
Февраль |
203 |
Филиал 1 |
РКО |
Март |
180 |
Филиал 1 |
РКО |
Апрель |
320 |
Филиал 1 |
Кредиты |
январь |
490 |
Филиал 1 |
Кредиты |
Февраль |
370 |
Филиал 1 |
Ценные бумаги |
Февраль |
300 |
Филиал 1 |
Ценные бумаги |
Март |
180 |
Филиал 2 |
Кредиты |
январь |
203 |
Филиал 2 |
Кредиты |
Февраль |
180 |
Филиал 2 |
Кредиты |
Март |
320 |
Филиал 2 |
Кредиты |
Апрель |
490 |
Филиал 2 |
РКО |
Февраль |
203 |
Филиал 2 |
РКО |
Март |
180 |
Филиал 2 |
Ценные бумаги |
Март |
180 |
Филиал 2 |
Ценные бумаги |
Апрель |
203 |
В представленной таблице "Филиал", "Вид услуги", "Отчетный период" являются атрибутами, а "Полученный доход" - числовым значением, анализ которого необходимо провести. Посмотрев на таблицу, можно заметить, что ее легко перевести в три измерения: по одной из осей отложим филиалы, по другой – виды услуг, по третьей – отчетные периоды. А значениями в этом трехмерном массиве будет соответствующий полученный доход.
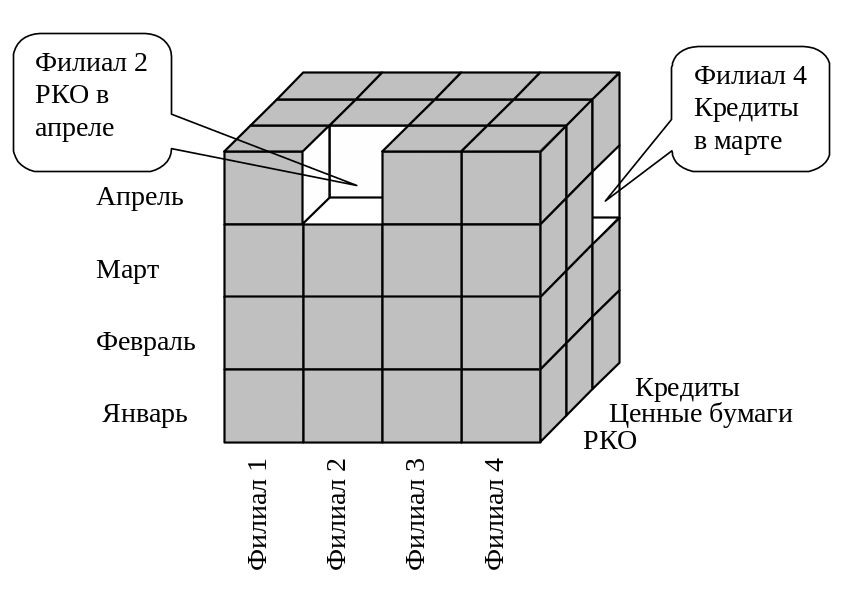
Рис. 2 Трехмерный массив данных
Такой трехмерный массив в терминах OLAP и называется кубом. На самом деле такой массив далеко не всегда является кубом: у настоящего куба количество элементов во всех измерениях должно быть одинаковым, а у кубов OLAP такого ограничения нет. Тем не менее, термин "куб" является общепринятым. Куб OLAP совсем не обязательно должен быть трехмерным. Он может быть и двух-, и многомерным - в зависимости от решаемой задачи. Профессиональные OLAP-продукты позволяют проводить анализ до 20 измерений. Более простые настольные приложения поддерживают порядка 5-6 измерений.
Измерения OLAP-кубов состоят из так называемых меток или членов (members). Например, измерение "Филиал" состоит из меток "Филиал 1", "Филиал 2", "Филиал 3" и так далее.
Условие заполнения всех ячеек куба не является обязательным: если нет информации об объемах доходов полученных в январе филиалом 4 от операций с ценными бумагами, значение в соответствующей ячейке просто не будет определено.
Куб данных сам по себе для анализа не пригоден. В процессе анализа из многомерного куба извлекают обычные двумерные таблицы. Эта операция называется "разрезанием" куба по требуемым для анализа меткам. В результате получаются обычные двумерные массивы.
Полученные в результате «срезов» данные могут быть подвергнуты анализу с использованием различных методик. В настоящее время выделяют статистические и интеллектуальные методы.
Аналитические задачи, решаемые статистическими методами, можно разделить на следующие классы:
Горизонтальный (временной) анализ - анализ некоторого показателя в рассматриваемый период в сравнении с предыдущим периодом.
Вертикальный (структурный) анализ - анализ влияния каждой позиции показателей на итоговый показатель.
Трендовый анализ и прогноз - анализ поведения некоторого показателя во времени и выявление основных тенденций изменения этого показателя, не зависящих от случайных факторов. На основе выявленных тенденций производится прогнозирование, т. е. формируются возможные значения исследуемого показателя в будущем.
Анализ относительных показателей - выявление наличия и характера взаимосвязи нескольких показателей, каждый из которых характеризует исследуемый объект, а также оценки и интерпретации таких взаимосвязей.
Сравнительный (пространственный) анализ - выявление закономерностей в некоторых показателях, полученных для различных подразделений, а также сравнение показателей конкретной исследуемой организации с аналогичными показателями других организаций, со средними данными, например по отрасли.
Факторный анализ - анализ влияния отдельных факторов (или причин) на результирующий показатель. Различают прямой факторный анализ, когда некоторый результирующий показатель дробят на составные части, и обратный (синтетический) анализ, когда отдельные элементы (исходные показатели) соединяют в общий результативный (синтетический) показатель.
Интеллектуальный анализ данных (ИАД или data mining) представляет собой новое направление в области информационных систем, ориентированное на решение задач поддержки принятия решений на основе количественных и качественных исследований сверхбольших массивов разнородных ретроспективных данных.
В настоящее время ИАД использует достижения многих разделов современной математики. Выделяют четыре группы методов анализа данных.
Первая группа средств ИАД охватывает методы статистической обработки данных, которые можно разделить на четыре взаимосвязанных раздела:
Предварительный анализ природы статистических данных (проверка гипотез стационарности, нормальности, независимости, однородности, оценка вида функции распределения и ее параметров).
Выявление связей и закономерностей (линейный и нелинейный регрессионный анализ, корреляционный анализ).
Многомерный статистический анализ (линейный и нелинейный дискриминантный анализ, кластер-анализ, компонентный анализ, факторный анализ).