

Содержание
[убрать]
1 Виды интеллектуальных систем
2 Литература
3 Ссылки
4 Примечания
Виды интеллектуальных систем[править | править исходный текст]
Интеллектуальная информационная система
Экспертная система
Расчётно-логические системы
Гибридная интеллектуальная система
Рефлекторная интеллектуальная система
К расчётно-логическим системам относят системы, способные решать управленческие и проектные задачи по декларативным описаниями условий. При этом пользователь имеет возможность контролировать в режиме диалога все стадии вычислительного процесса. Данные системы способны автоматически строить математическую модель задачи и автоматически синтезировать вычислительные алгоритмы по формулировке задачи. Эти свойства реализуются благодаря наличию базы знаний в виде функциональной семантической сети и компонентов дедуктивного вывода и планирования.
Рефлекторная система — это система, которая формирует вырабатываемые специальными алгоритмами ответные реакции на различные комбинации входных воздействий. Алгоритм обеспечивает выбор наиболее вероятной реакции интеллектуальной системы на множество входных воздействий, при известных вероятностяхвыбора реакции на каждое входное воздействие, а также на некоторые комбинации входных воздействий. Данная задача подобна той, которую реализуютнейросети[3].
По комбинации воздействий на рецепторы формируются числовые характеристики рефлекторов через промежуточный слой. Связи между слоями обеспечивают передачу некоторой величины (импульса), от элементов одного слоя, к элементам другого. Если суммарная величина (суммарный импульс) на входе некоторого элемента превосходит его пороговое значение, то он передает свое значение (свой импульс) на элементы следующего слоя. По сути, каждый из элементов является моделью нейрона[уточнить].
В отличие от перцептронов рефлекторный алгоритм напрямую рассчитывает адекватную входным воздействиям реакцию интеллектуальной системы. Адекватность реакции базируется на предположении, что законы несилового взаимодействия одинаковы на любых уровнях представления взаимодействующих систем: будь то живые или неживые объекты.
Рефлекторные программные системы применяются к следующим задачам: естественно-языковой доступ к базам данных; оценки инвестиционных предложений; оценки и прогнозирования влияния вредных веществ на здоровье населения; прогнозирования результатов спортивных игр[4].
3.14. Модели представления знаний
Важное место в теории искусственного интеллекта занимает проблема представления знаний, являющаяся, по мнению многих исследователей, ключевой. В общем виде модели представления знаний могут быть условно разделены на следующие классы:
1. Концептуальные модели используют эвристический метод, что позволяет при распознавании проблемы уменьшать время для ее предварительного анализа. Концептуальное описание не дает гарантии того, что метод может быть применен во всех соответствующих практических ситуациях. Практическое использование концептуальной модели влечет за собой необходимость преобразования ее в эмпирическую модель.
2. Эмпирические модели – это модели, как правило, описательного характера. Они могут варьировать от простого набора правил до полного описания.
3. Декларативные модели представления знаний основываются на предположении, что проблема представления некоей предметной области решается независимо от того, как эти знания потом будут использоваться. Поэтому модель как бы состоит из двух частей: статических описательных структур знаний и механизма вывода, оперирующего этими структурами и практически независимого от их содержательного наполнения. При этом в какой-то степени оказываются раздельными синтаксические и семантические аспекты знания, что является определенным достоинством указанных форм представления из-за возможности достижения их определенной универсальности. Эти модели представляют собой обычно множество утверждений. Предметная область представляется в виде синтаксического описания ее состояния. Вывод решений основывается в основном на процедурах поиска в пространстве состояний.
4. Процедурные модели представляют собой модели, в которых знания содержатся в процедурах небольших программ, которые определяют, как выполнять характерные действия. При этом можно не описывать все возможные состояния среды или объекта для реализации вывода. Достаточно хранить некоторые начальные состояния и процедуры, генерирующие необходимые описания ситуаций и действий.
При процедурном представлении знаний семантика заложена в описание элементов базы знаний, за счет чего повышается эффективность поиска решений. Статическая база знаний содержит только утверждения, приемлемые в данный момент, которые могут быть изменены или удалены. Общие знания и правила вывода представлены в виде специальных целенаправленных процедур, активизирующихся по мере надобности. Для повышения эффективности генерации вывода в систему добавляются знания о том, каким образом использовать накопленные знания для решения конкретной задачи.
Преимущества процедурных моделей: имеют большую эффективность механизмов вывода за счет введения дополнительных знаний, способны смоделировать практически любую модель представления знаний, имеют большую выразительную силу, которая проявляется в расширенной системе выводов.
Представление знаний в экспертных системах производится с помощью специально разработанных моделей.
1. Логические модели. Классическим механизмом представления знаний в системах является исчисление предикатов. Предикатом или логической функцией называется функция от любого числа аргументов, принимающая истинные значения 1 и 0. В исследованиях по искусственному интеллекту данная модель стала использоваться начиная с 50-х годов.
В системах, основанных на исчислении предикатов, знания представляются с помощью перевода утверждений об объектах некоторой предметной области в формулы логики предикатов и добавления их как аксиом в систему. Знания отображаются совокупностью таких формул, а получение новых знаний сводится к реализации процедур логического вывода. Однако действительность не укладывается в рамки классической логики, потому что человеческая логика, применяемая при работе с неструктурированными знаниями – это интеллектуальная модель с нечеткой структурой. При использовании нечеткой логики часто применяются два метода логического вывода: прямой и обратный метод.
Достоинство логических моделей:
– модель базируется на классическом аппарате математической логики, методы которой хорошо изучены и обоснованы;
– имеются достаточно эффективные процедуры вывода;
– база знаний предназначена для хранения большого количества аксиом, из которых по правилам вывода можно получать другие знания.
Основной недостаток: логики, адекватно отражающей человеческое мышление, еще не создано
2. Продукционные модели. Впервые были предложены Постом в 1943 г., применены в системах искусственного интеллекта в 1972 г. При исследовании процессов рассуждения и принятия решений человеком пришли к выводу, что человек в процессе работы использует продукционные правила. Правило продукций (англ. Production) – это правило вывода, порождающее правило.
Суть правила продукции для представления знаний состоит в том, что в левой части ставится в соответствие некоторое условие, а в правой части действие: если <перечень условия>[90], то <перечень действий>. Если это действие соответствует значению «истина», то выполняется действие, заданное в правой части продукции. В общем случае под условием понимается некоторое предложение, по которому осуществляется поиск в базе знаний, а под действием – действия, выполняемые при успешном исходе поиска.
Продукционные модели – это набор, правил вида «условия – действие», где условиями являются утверждения о содержимом некой базы данных, а действия представляют собой процедуры, которые могут изменять содержимое базы данных. Например: Если коэффициент соотношения заемных и собственных средств превышает единицу при низкой оборачиваемости, то финансовая автономность и устойчивость критическая.
Правила (в них выражены знания) и факты (их оценивают с помощью правил) являются основным структурным элементом систем искусственного интеллекта. Часто в практики управления правила выводятся эмпирически из совокупности фактов, а не путем математического анализа или алгоритмического решения. Такие правила называют эвристиками.
В продукционной модели база знаний состоит из набора правил. Программа, управляющая перебором правил – машина вывода, связывает знание воедино и выводит из последовательности знаний заключение.
В процессе обработки информации часто применяются два метода: прямой и обратный. В случае прямого подхода – метода сопоставления для поиска решений образцом служит левая часть продукционного правила – условие и задача решается в направлении от исходного состояния к целевому. В случае обратного подхода обработка информации осуществляется по методу генерации или выдвижения гипотезы[91] и ее проверки. Проверяются правые части продукционных правил с целью обнаружения в них искомого утверждения. Если такие продукционные правила существуют, то проверяется, удовлетворяет ли левая часть продукционного правила. Если да, то гипотеза подтверждается, если нет – отвергается.
В продукционных системах выделяют три основные компоненты:
– неструктурированная или структурированная БД;
– набор продукционных правил или продукций, каждая продукция состоит из двух частей:
a) условий (антецендент); в этой части определяются некоторые условия, которые должны выполняться в БД для того, чтобы были выполнены соответствующие действия;
b) действий (консеквент); эта часть содержит описание действий, которые должны быть совершены над БД в случае выполнения соответствующих условий. В простейших продукционных системах они только определяют, какие элементы следует добавить (или иногда удалить) в БД.
– интерпретатор, который последовательно определяет, какие продукции могут быть активированы в зависимости от условий, в них содержащихся; выбирает одно из применимых в данной ситуации правил продукций; выполняет действие из выбранной процедуры.
Продукционные модели близки к логическим моделям, но более наглядно отражают знания, поэтому являются наиболее распространенными средствами представления знаний. Чаще всего они применяются в промышленных экспертных системах, в качестве решателей или механизмов выводов.
Достоинства продукционных моделей:
– наглядность;
– высокая модульность – отдельные логические правила могут быть добавлены в базу знаний, удалены или изменены независимо от других, модульный принцип разработки систем позволяет автоматизировать их проектирование;
– легкость внесения дополнений и изменений;
– простота логического вывода.
Недостатки продукционных моделей:
– при большом количестве продукционных правил в базе знаний, изменение старого правила или добавления нового приводит к непредсказуемым побочным эффектам;
– затруднительна оценка целостного образа знаний, содержащего в системе.
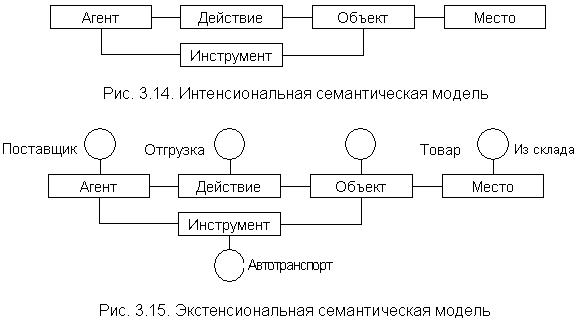
3. Семантические сети[92]. Способ представления знаний с помощью сетевых моделей наиболее близок к тому, как они представлены в текстах на естественном языке. В его основе лежит идея о том, что вся необходимая информация может быть описана как совокупность троек: объекты или понятия и бинарное отношение между ними.
Наиболее общей сетевой моделью представления знаний являются семантические сети, в которых узлы и связи представляют собой объекты или понятия и их отношения, таким образом, что можно выяснить их значение. Это связано с тем, что в данной модели имеются средства реализации всех характерных для знаний свойств: внутренней интерпретации, стуктурированности, семантической метрики[93] и активности. Впервые понятие семантических сетей было введено в 60-х годах для представления семантических связей между концепциями слов.
Семантические сети применительно к задачам проектирования структуры баз данных экспертных систем используются в сравнительно узком диапазоне – для отражения структуры понятий и структуры событий. Они представляют собой модель, основой которой является формализация знаний в виде ориентированных графов с помеченными дугами, которая позволяют структурировать имеющуюся информацию и знания. Вершины графа соответствуют конкретным объектам, а дуги, их соединяющие, отражают имеющиеся между ними отношения. Построение сети способствует осмыслению информации и знаний, поскольку позволяет установить противоречивые ситуации, недостаточность имеющейся информации и т.п.
В семантических сетях, используются следующие отношения:
– лингвистические, включающие в себя отношения типа «объект», «агент», «условие», «место», «инструмент», «цель», «время» и др.;
– атрибутивные, к которым относят форму, размер, цвет и т.д.;
– характеризации глаголов, т. е. род, время, наклонение, залог, число;
– логические, обеспечивающие выполнение операций для исчисления высказываний (дизъюнкция, конъюнкция, импликация, отрицание);
– квантифицированные, т. е. использующие кванторы общности и существования;
– теоретико-множественные, включающие понятия «элемент множества», «подмножество», «супермножество» и др.
Различают:
– интенсиональную семантическую сеть, которая описывает предметную область на обобщенном, концептуальном уровне;
– экстенсиональную семантическую сеть, в которой производится конкретизация и наполнение фактическими данными.
Статические базы знаний, представленные с помощью семантических сетей, могут быть объектом действий, производимых активными процессами. Стандартные операции включают в себя процессы поиска и сопоставления, с помощью которых определяется, представлена ли в семантической модели (и где именно) специфическая информация.
Достоинство семантической сети:
– описание объектов и событий производится на уровне очень близком к естественному языку;
– обеспечивается возможность соединения различных фрагментов сети;
– отношения между понятиями и событиями образуют небольшое, хорошо организованное множество;
– для каждой операции над данными или знаниями можно выделить некоторый участок сети, который охватывает необходимые в данном запросе характеристики;
– обеспечивается наглядность системы знаний, представленной графически:
– близость структуры сети, представляющей знания, семантической структуре фраз на естественном языке;
– соответствие сети современным представлениям об организации долговременной памяти человека.
Недостатки семантической сети:
– сетевая модель не дает ясного представления о структуре предметной области, поэтому формирование и модификация такой модели затруднительны;
– сетевые модели представляют собой пассивные структуры, для обработки которых необходим специальный аппарат формального вывода и планирования.
Семантические сети нашли применение в основном в системах обработки естественного языка, частично в вопросно-ответных системах, а также в системах искусственного видения. В последних семантические сети используются для хранения знаний о структуре, форме и свойствах физических объектов. В области обработки естественного языка с помощью семантических сетей представляют семантические знания, знания о мире, эпизодические знания (т.е. знания о пространственно-временных событиях и состояниях).
Пример: Поставщик отгрузил товар из склада автотранспортом. На рис. 3.14. представлена интенсиональная семантическая модель, а на рис. 3.15. – экстенсиональная семантическая сеть. Факты обозначены овалом, понятия и объекты прямоугольником.
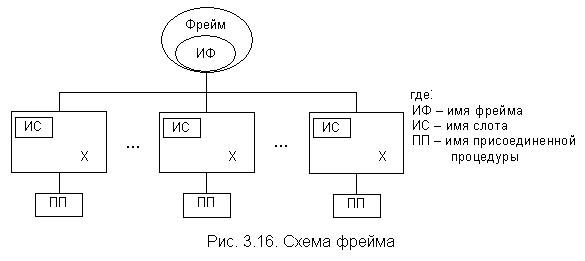
4. Фреймовые модели. Фреймы были впервые предложены в качестве аппарата для представления знаний М. Минским в 1975 г. Фреймовые модели представляют собой систематизированную в виде единой теории технологическую модель памяти человека и его сознания. Под фреймом понимают минимальные структуры информации, необходимые для представления класса объектов, явлений или процессов.
Фрейм можно представить в виде сети, состоящей из вершин и дуг (отношений), в которых нижние уровни фрейма заканчиваются слотами (переменными), которые заполняются конкретной информацией при вызове фрейма. Значением слота может быть любая информация: текст, числа, математические соотношения, программы, ссылки на другие фреймы. На заполнение слотов могут быть наложены ограничения, например цена не может быть отрицательной. Ниже приведены основные свойства фреймов.
– Наследование свойств. Все фреймы взаимосвязаны и образуют единую фреймовую структуру, поэтому достаточно просто производить композицию и декомпозицию информационных структур. Например: слот более низкого уровня указывает на слот более высокого уровня иерархии, откуда неявно наследуются (переносятся) значения аналогичных слотов, причем наследование свойств может быть частичным.
– Базовый тип. При эффективном использовании фреймовой системы, можно добиться быстрого понимания сущности данного предмета и его состояния, однако для запоминания различных позиций в виде фреймов необходимы большие объемы памяти. Поэтому только наиболее важные объекты данного предмета запоминаются в виде базовых фреймов, на основании которых строятся фреймы для новых состояний. При этом каждый фрейм содержит слот, оснащенный указателем подструктуры, который позволяет различным фреймам совместно использовать одинаковые части.
– Процесс сопоставления – процесс, в ходе которого проверяется правильность выбора фрейма, осуществляется в соответствии с текущей целью и информацией, содержащийся в данном фрейме. Фрейм содержит условия, ограничивающие значения слота, а цель используется для определения, какое из этих условий, имея отношение к данной ситуации, является существенным.
– Иерархическая структура, особенность которой заключается в том, что информация об атрибутах, которую содержит фрейм верхнего уровня, совместно используются всеми связанными с ним фреймами нижних уровней.
– Сети фреймов. Поиск фрейма, подобного предыдущему, осуществляется с использованием указателей различия. Поиск возможен благодаря соединению фреймов, описывающих объекты с небольшими различиями, с данными указателями и образованию сети подобных фреймов.
– Отношения «абстрактное – конкретное» и «целое – часть». Иерархическая структура фреймов основывается на отношениях «абстрактное – конкретное». На верхних уровнях расположены абстрактные объекты, на нижних уровнях – конкретные объекты. Объекты нижних уровней наследуют атрибуты объектов верхних уровней. Отношение «целое – часть» касается структурированных объектов и показывает, что объект нижнего уровня является частью объекта верхнего уровня. Наибольшее практическое применение получили отношения «абстрактное – конкретное».
Схема фрейма приведена на рис. 3.16. Теория фреймов послужила толчком к разработке языков представления знаний. Например, концепция объектно-ориентированного программирования в традиционных языках программирования использует понятия, близкие к фрейму. Модели фреймов имеют следующие достоинства:
– способность отображать концептуальную основу организации памяти человека;
– естественность и наглядность представления, модульность;
– поддержку возможности использования значений слотов по умолчанию.
– универсальность, так как позволяют отобразить все многообразие знаний.
В отличие от моделей других типов во фреймовых моделях более жесткая структура, которая называется протофреймом. Основной недостаток: отсутствие механизмов управления выводом, который частично устраняется при помощи присоединенных процедур, реализуемый силами пользователя системы.
В системах искусственного интеллекта могут использоваться одновременно несколько моделей представления знаний. Например, фрейм можно рассматривать как фрагмент семантической сети, предназначенной для описания объекта (ситуации) проблемной области со всей совокупностью присущих ему свойств. Значением некоторых слотов фрейма может быть продукция. В продукционных моделях используются некоторые элементы логических и сетевых моделей. Поэтому появляется возможность организовывать эффективные процедуры вывода и наглядное отображение знаний в виде сетей; отсутствие жестких ограничений позволяет изменять интерпретацию элементов продукции.
5. Нейронные сети. В настоящее время сформировалось новое научно-практическое направление – создание нейрокомпьютера, ЭВМ нового поколения, который способен к самоорганизации, обучению и имитирует некоторые способности человеческого мозга по обработке информации. Результатами явились представления знаний, основанные на массированной параллельной обработке, быстром поиске больших объемов информации и способности распознавать образцы. Технологии, направленные на достижение этих результатов относятся к нейронным вычислениямили искусственным нейронным сетям.
Интеллектуальные информационные системы проникают во все сферы нашей жизни, поэтому трудно провести строго классификацию направлений. Разработка интеллектуальных информационныхcucmeм или систем, основанных на знаниях. Это одно из главных направлений ИИ. Основной целью построения таких систем являются выявление, исследование и применение знаний высококвалифицированных экспертов для решения сложных задач, возникающих на практике. При построении систем, основанных на знаниях (СОЗ), используются знания, накопленные экспертами в виде конкретных правил решения тех или иных задач. Частным случаем СОЗ являются экспертные системы (ЭС). Разработка естественно-языковых интерфейсов и машинный перевод. Системы машинного перевода с одного естественного языка на другой обеспечивают быстроту и систематичность доступа к информации, оперативность и единообразие перевода больших потоков, как правило, научно-технических текстов. Системы машинного перевода строятся как интеллектуальные системы, поскольку в их основе лежат БЗ в определенной предметной области и сложные модели, обеспечивающие дополнительную трансляцию «исходный язык оригинала — язык смысла - язык перевода». Генерация и распознавание речи. Системы речевого общения создается в целях повышения скорости ввода информации в ЭВМДразгрузки зрения и рук, а также для реализации речевого общещш на значительном расстоянии. В таких системах под текстом поднимают фонемный текст (как слышится). Обработка визуальной информации. В этом научном направлении решаются задачи обработки, анализа и синтеза изображений. Задача обработки изображений связана с трансформированием графических образов, результатом которого являются новые изображения. В задаче анализа исходные изображения преобразуются в данные другого типа, например в текстовые описания. Обучение и самообучение. Эта актуальная область ИИ включает модели, методы и алгоритмы, ориентированные на автоматическое накопление и формирование знаний с использованием процедур анализа и обобщения данных. Распознавание образов. Это одно из самых ранних направлений ИИ, в котором распознавание объектов осуществляется на основании применения специального математического аппарата, обеспечивающего отнесение объектов к классам, а классы описываются совокупностями определенных значений признаков. Игры и машинное творчество. Машинное творчество охватывает сочинение компьютерной музыки, стихов, интеллектуальные системы для изобретения новых объектов. Создание интеллектуальных компьютерных игр является одним из самых развитых коммерческих направлений в сфере разработки программного обеспечения. Программное обеспечение систем ИИ. Инструментальные средства для разработки интеллектуальных систем включают специальные языки программирования, ориентированные на обработку символьной информации языки логического программирования, языки представления знаний, интегрированные программные среды, содержащие арсенал инструментальных средств для создания систем ИИ ,а также оболочки экспертных систем, которые позволяют создавать прикладные ЭС, не прибегая к программированию. Новые архитектуры компьютеров. Это направление связано с созданием компьютеров не фон-неймановской архитектуры, ориентированных на обработку символьной информации. ^ Интеллектуальные роботы. Создание интеллектуальных роботов составляет конечную цель робототехники.
Понятие системы с интеллектуальным интерфейсом.
Применение ИИ для усиления коммуникативных способностей информационных систем привело к появлению систем с интеллектуальным интерфейсом, среди которых можно выделить следующие типы. 1 ^ Интеллектуальные базы данных. Позволяют в отличие от традиционных БД обеспечивать выборку необходимой информации, не присутствующей в явном виде, а выводимой из совокупности хранимых данных. 2 ^ Естественно-языковой интерфейс. Применяется для доступа к интеллектуальным базам данных, контекстного поиска документальной текстовой информации, голосового ввода команд в системах управления, машинного перевода с иностранных языков. Для реализации ЕЯ-интерфейса необходимо решить проблемы морфологического, синтаксического и семантического анализа, а также задачу синтеза высказываний на естественном языке. 3 ^ Гипертекстовые системы. Используются для реализации поиска по ключевым словам в базах данных с текстовой информацией. Для более полного отражения различных смысловых отношений терминов требуется сложная семантическая организация ключевых слов. Решение этих задач осуществляется с помощью интеллектуальных гипертекстовых систем, в которых механизм поиска сначала работает с базой знаний ключевых слов, а затем — с самим текстом. 4 ^ Системы контекстной помощи. Относятся к классу систем распространения знаний. Такие системы являются, как правило, приложениями к документации. Системы контекстной помощи — частный случай гипертекстовых и ЕЯ-систем. В них пользователь описывает проблему, а система на основе дополнительного диалога конкретизирует ее и выполняет поиск относящихся к ситуации рекомендаций. 5 ^ Системы когнитивной графики. Ориентированы на общение с пользователем ИИС посредством графических образов, которые генерируются в соответствии с изменениями параметров моделируемых или наблюдаемых процессов. Когнитивная графика позволяет в наглядном и выразительном виде представить множество параметров, характеризующих изучаемое явление, освобождает пользователя от анализа тривиальных ситуаций, способствует быстрому освоению программных средств и повышению конкурентоспособности разрабатываемых ИИС.
^ Понятие самообучающейся системы.
Самообучающиеся интеллектуальные системы основаны на методах автоматической классификации ситуаций из реальной практики, или на методах обучения на примерах. Примеры реальных ситуаций составляют так называемую обучающую выборку, которая формируется в течение определенного исторического периода. Стратегия «обучения с учителем» предполагает задание специалистом для каждого примера значений признаков, показывающих его принадлежность к определенному классу ситуаций. При обучении «без учителя» система должна самостоятельно выделять классы ситуаций по степени близости значений классификационных признаков. В процессе обучения проводится автоматическое построение обобщающих правил или функций, описывающих принадлежность ситуаций к классам, которыми система впоследствии будет пользоваться при интерпретации незнакомых ситуаций. Построенные в соответствии с этими принципами самообучающиеся системы имеют следующие недостатки: • относительно низкую адекватность баз знаний возникающим реальным проблемам из-за неполноты и/или зашумленности обучающей выборки; • низкую степень объяснимости полученных результатов; • поверхностное описание проблемной области и узкую направленность применения из-за ограничений в размерности признакового пространства. ^ Индуктивные системы позволяют обобщать примеры на основе принципа индукции «от частного к общему». Процедура обобщения сводится к классификации примеров по значимым признакам. Алгоритм классификации примеров включает следующие основные шаги. 1 Выбор классификационного признака из множества заданных. 2 Разбиение множества примеров на подмножества по значению выбранного признака. 3 Проверка принадлежности каждого подмножества примеров одному из классов. 4 Проверка окончания процесса классификации. Если какое-то подмножество примеров принадлежит одному подклассу, т.е. у всех примеров этого подмножества совпадает значение классификационного признака, то процесс классификации заканчивается. 5 Для подмножеств примеров с несовпадающими значениями классификационных признаков процесс распознавания продолжается, начиная с первого шага. При этом каждое подмножество примеров становится классифицируемым множеством. ^ Нейронные сети представляют собой классический пример технологии, основанной на примерах. Нейронные сети — обобщенное название группы математических алгоритмов, обладающих способностью обучаться на примерах, «узнавая» впоследствии черты встреченных образцов и ситуаций. Нейронная сеть — это кибернетическая модель нервной системы, которая представляет собой совокупность большого числа сравнительно простых элементов — нейронов, топология соединения которых зависит от типа сети. Чтобы создать нейронную сеть для решения какой-либо конкретной задачи, следует выбрать способ соединения нейронов друг с другом и подобрать значения параметров межнейронных соединений. В системах, основанных на прецедентах, БЗ содержит описания конкретных ситуаций (прецеденты). Поиск решения осуществляется на основе аналогий и включает следующие этапы: • получение информации о текущей проблеме; • сопоставление полученной информации со значениями признаков прецедентов из базы знаний; • выбор прецедента из базы знаний, наиболее близкого к рассматриваемой проблеме; • адаптация выбранного прецедента к текущей проблеме; • проверка корректности каждого полученного решения; • занесение детальной информации о полученном решении вБЗ. Системы, основанные на прецедентах, применяются для распространения знаний и в системах контекстной помощи. ^ Информационные хранилища отличаются от интеллектуальных баз данных, тем, что представляют собой хранилища значимой информации, регулярно извлекаемой из оперативных баз данных. Хранилище данных — это предметно-ориентированное, интегрированное, привязанное ко времени, неизменяемое собрание данных, применяемых для поддержки процессов принятия управленческих решений. В хранилище данные интегрируются в целях удовлетворения требований предприятия в целом, а не отдельной функции бизнеса. Привязанность данных ко времени выражает их «историчность», т.е. атрибут времени всегда явно присутствует в структурах хранилища данных. Неизменяемость означает, что, попав однажды в хранилище, данные уже не изменяются в отличие от оперативных систем, где данные присутствуют только в последней версии, поэтому постоянно меняются.
^ Понятие адаптивной информационной системы.
Потребность в адаптивных информационных системах возникает в тех случаях, когда поддерживаемые ими проблемные области постоянно развиваются. В связи с этим адаптивные системы должны удовлетворять ряду специфических требований, а именно: • адекватно отражать знания проблемной области в каждый момент времени; • быть пригодными для легкой и быстрой реконструкции при изменении проблемной среды. Адаптивные свойства информационных систем обеспечиваются за счет интеллектуализации их архитектуры. В процессе разработки адаптивных информационных систем применяется оригинальное или типовое проектирование. Оригинальное проектирование предполагает разработку информационной системы с «чистого листа» на основе сформулированных требований. При типовом проектировании осуществляется адаптация типовых разработок к особенностям проблемной области. Для реализации этого подхода применяются инструментальные средства компонентного (сборочного) проектирования информационных систем (R/3, BAAN IV, Prodis и др.). Главное отличие подходов состоит в том, что при использовании CASE-технологии на основе репозитория при изменении проблемной области каждый раз выполняется генерация программного обеспечения, а при использовании сборочной технологии — конфигурирование программ и только в редких случаях — их переработка.
^ Понятие ЭС. Схема обобщенной ЭС.
В течение последних десятилетий в рамках исследований по искусственному интеллекту (ИИ) сформировалось самостоятельное направление - экспертные системы (ЭС) или инженерия знании. В задачу этого направления входят исследование и разработка программ (устройств), использующие знания и процедуры вывода для решения задач, являющихся трудными для людей-экспертов. Огромный интерес к ЭС со стороны пользователей вызван, по крайней мере, тремя причинами:
Во-первых, они ориентированы на решение широкого круга задач в неформализованных областях, на приложениях, которые до недавнего времени считались малодоступными для вычислительной техники.
Во-вторых, с помощью ЭС специалисты, не знающие программирования, могут самостоятельно разрабатывать интересующие их приложения, что позволяет резко расширить сферу использования вычислительной техники.
В-третьих, ЭС при решении практических задач достигают результатов, не уступающих, а иногда и превосходящих возможности людей-экспертов, не оснащенных ЭВМ.
Особенно
широкое распространение ЭС получили в
проектировании интегральных микросхем,
в поиске неисправностей, в военных
приложениях и автоматизации
программирования. Применение ЭС
позволяет: I) при проектировании
интегральных микросхем повысить (по
данным фирмы NEC) производительность
труда в 3-6 раз, при этом выполнение
некоторых операций ускоряется в 10-15
раз; 2) ускорить поиск неисправностей в
сложных устройствах в 5-10 раз; 3) повысить
производительность труда программистов
(по данным фирмы ТОSHIВА) в 5 раз; 4) при
профессиональной подготовке сократить
(без потери качества) в 8-12 раз затраты
на индивидуальную работу с обучаемыми.
В
последнее время ведутся разработки ЭС
для следующих приложений: раннее
предупреждение национальных и
международных конфликтов и поиск
компромиссных решений; принятие решений
в кризисных ситуациях; охрана правопорядка;
образование; медицина) планирование и
распределение ресурсов; система
организационного управления (кабинет
министров, муниципалитет, учреждение)
и т.д.
 ^ 6.
Назначение, особенности, структура ЭС.
Процесс решения задачи с помощью ЭС в
режиме консультации
Знания,
которыми обладает специалист в какой-либо
области (дисциплине), можно разделить
на формализованные (точные) и
неформализованные (неточные). Формализованные
знания формируются
в книгах и руководствах в виде общих и
строгих суждений. Неформализованные
знания, как
правило, не попадают в книги и руководства
в связи с их конкретностью, субъективностью
и приблизительностью. Знания этого рода
являются результатом обобщения
многолетнего опыта работы и интуиции
специалистов. В зависимости от того,
какие знания преобладают в той или иной
области (дисциплине), ее относят к
формализованным (если преобладают
точные знания) или к неформализованным
(если преобладают неточные знания)
описательным областям. Задачи, решаемые
на основе точных знаний, называют
формализованными, а задачи, решаемые с
помощью неточных знаний - неформализованными.
Традиционное программирование в качестве
основы для разработки программы
использует алгоритм, т.е. формализованное
значение. По мнению авторитетов, основной
задачей информатики является внедрение
ее методов в описательные науки
и дисциплины. На основании этого можно
утверждать, что исследования в области
ЭС занимают значительное место в
информатике.
К
неформализованным задачам относятся
те, которые обладают одной или несколькими
из следующих особенностей:
а)
алгоритмическое решение задачи неизвестно
(хотя, возможно, и существует) или не
может быть использовано из-за ограниченности
ресурсов ЭВМ (времени, памяти);
б)
задача не может быть определена в
числовой форме (требуется символьное
представление);
в)
цели задачи не могут быть выражены в
терминах точно определенной целевой
функции.
Экспертные
системы не отвергают и не заменяют
традиционного подхода к программированию,
они отличаются от традиционных программ
тем, что ориентированы на решение
неформализованных задач и обладают
следующими особенностями:
^ 6.
Назначение, особенности, структура ЭС.
Процесс решения задачи с помощью ЭС в
режиме консультации
Знания,
которыми обладает специалист в какой-либо
области (дисциплине), можно разделить
на формализованные (точные) и
неформализованные (неточные). Формализованные
знания формируются
в книгах и руководствах в виде общих и
строгих суждений. Неформализованные
знания, как
правило, не попадают в книги и руководства
в связи с их конкретностью, субъективностью
и приблизительностью. Знания этого рода
являются результатом обобщения
многолетнего опыта работы и интуиции
специалистов. В зависимости от того,
какие знания преобладают в той или иной
области (дисциплине), ее относят к
формализованным (если преобладают
точные знания) или к неформализованным
(если преобладают неточные знания)
описательным областям. Задачи, решаемые
на основе точных знаний, называют
формализованными, а задачи, решаемые с
помощью неточных знаний - неформализованными.
Традиционное программирование в качестве
основы для разработки программы
использует алгоритм, т.е. формализованное
значение. По мнению авторитетов, основной
задачей информатики является внедрение
ее методов в описательные науки
и дисциплины. На основании этого можно
утверждать, что исследования в области
ЭС занимают значительное место в
информатике.
К
неформализованным задачам относятся
те, которые обладают одной или несколькими
из следующих особенностей:
а)
алгоритмическое решение задачи неизвестно
(хотя, возможно, и существует) или не
может быть использовано из-за ограниченности
ресурсов ЭВМ (времени, памяти);
б)
задача не может быть определена в
числовой форме (требуется символьное
представление);
в)
цели задачи не могут быть выражены в
терминах точно определенной целевой
функции.
Экспертные
системы не отвергают и не заменяют
традиционного подхода к программированию,
они отличаются от традиционных программ
тем, что ориентированы на решение
неформализованных задач и обладают
следующими особенностями:
алгоритм решения не известен заранее, а строится самой ЭС с помощью символических рассуждений, базирующихся на эвристических приемах;
ясность полученных решений, т.е. система "осознает" в терминах пользователя, как она получила решение;
способность анализа и объяснения своих действий и знаний;
способность приобретения новых знаний от пользователя-эксперта, не знающего программирования, и изменения в соответствии с ними своего поведения (открытая система);
обеспечение "дружественного", как правило, естественно-языкового (ЕЯ) интерфейса с пользователем.
Об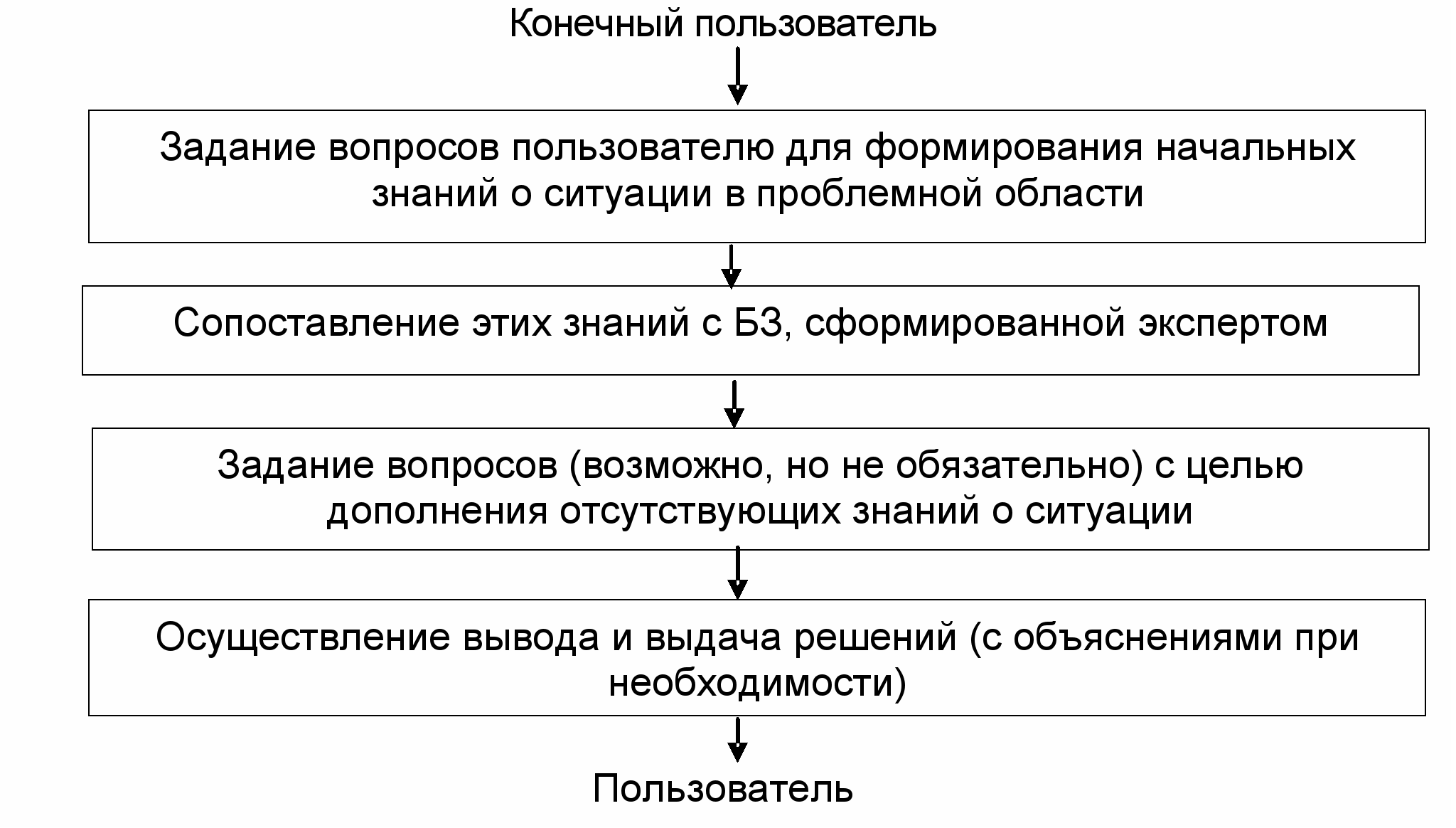 ычно
к ЭС относят системы,
основанные на знании, т.е.
системы, вычислительная возможность
которых является в первую очередь
следствием их наращиваемой базы знаний
(БЗ) и только во вторую очередь определяется
используемыми методами. Методы
инженерии знаний (методы
ЭС) в значительной степени инвариантны
тому, в каких областях они могут
применяться. Области применения ЭС
весьма разнообразны: военные приложения,
медицина, электроника, вычислительная
техника, геология, математика, космос,
сельское хозяйство, управление, финансы,
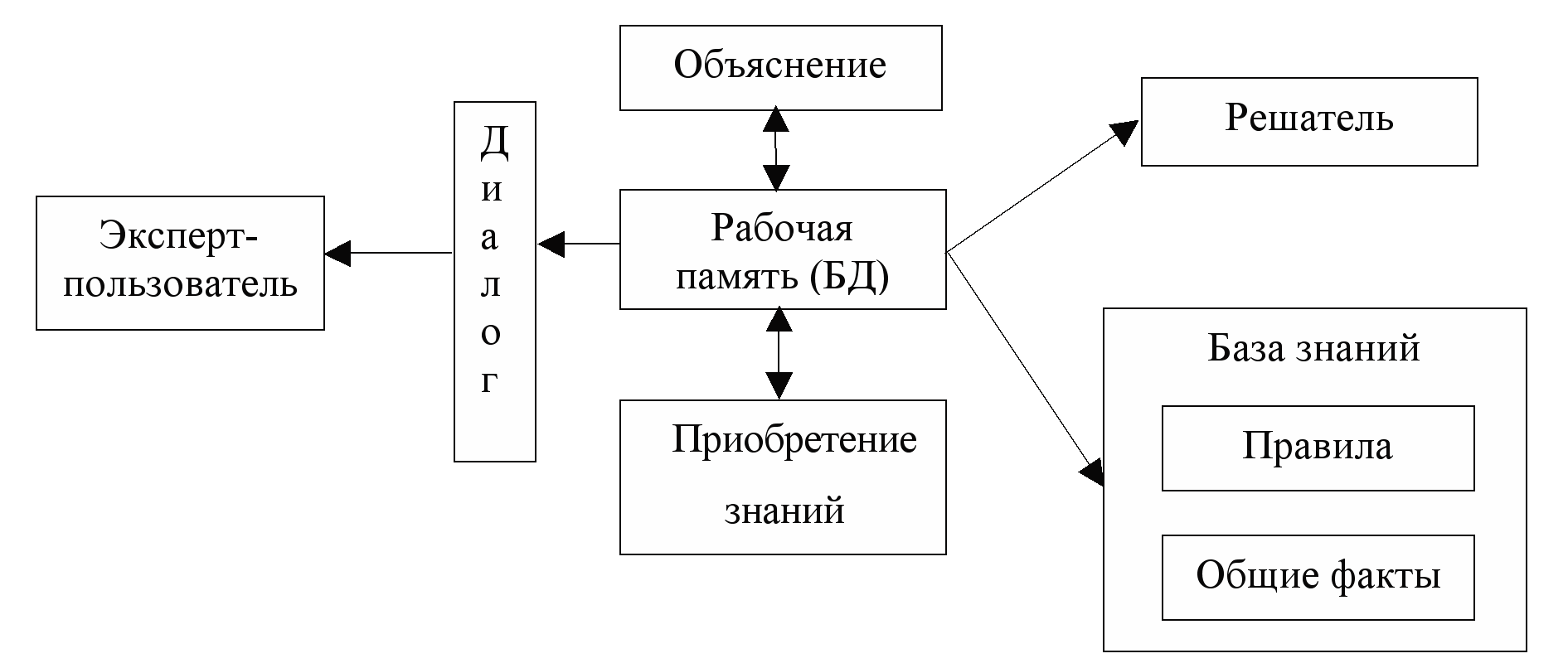
юриспруденция, и т.д. База
знаний в
ЭС предназначена для хранения долгосрочных
данных, описывающих рас-ю область (а не
текущих данных), и правил, описывающие
целесообразные преобразования данных
этой области.
Решатель, используя
исходные данные из БД и знания из БЗ,
формирует такую последовательность
правил, которые, будучи примененными к
исходным данным, приводят к решению
задачи.
^ Компонента
приобретения знаний автоматизирует
процесс наполнения ЭС знаниями,
осуществляемый пользователем-экспертом.
Объяснительная
компонента объясняет,
как система получила решение задачи
(или почему она не получила решения) и
какие знания при этом она использовала,
что облегчает эксперту тестирование
системы и повышает доверие пользователя
к полученному результату.
^ Диалоговая
компонента ориентирована дружелюбного
общения со всеми категориями пользователей,
как в ходе решения задач, так и приобретения
знаний, объяснения результатов работы.
В
разработке ЭС участвуют представители
следующих специальностей: эксперт в
той проблемной области, задачи которой
будет решать ЭС; инженер по знаниям
(когнитолог) - специалист по разработке
ЭС; программист - специалист по
разработке инструментальных средств.
Необходимо отметить, что отсутствие
среди участников разработки инженера
по знаниям (т.е. его замена программистом)
либо приводит к неудаче в процессе
создания ЭС, либо значительно удлиняет
его.
Эксперт определяет
знания (данные и правила), характеризующие
проблемную область, обеспечивает полноту
и правильность введения в ЭС
знаний.
^ Инженер
по знаниям помогает
эксперту выявить и структурировать
знания, необходимые для работы ЭС. Он
выбирает тот инструментарий, который
наиболее подходит для данной проблемной
области, и определяет способ представления
знаний в нем, выделяет и программирует
(традиционными средствами) стандартные
функции (типичные для данной проблемной
области), которые будут использоваться
в правилах, вводимых экспертом. Экспертная
система работает в двух режимах:
приобретения знаний и решения задач
(называемом также режимом консультации
или режимом использования ЭС).
^ В
режиме консультации общение
с ЭС осуществляет конечный пользователь,
которого интересует результат и (или)
способ получения решения. Пользователь
в зависимости от назначения ЭС может
не быть специалистом в данной проблемной
области, в этом случае он обращается к
ЭС за советом, не умея получить ответ
сам, или быть специалистом, в этом случае
он обращается к ЭС, чтобы либо ускорить
процесс получения результата, либо
возложить на ЭС рутинную работу. Термин
"пользователь" является многозначным,
так как кроме конечного пользователя
применять ЭС может и эксперт, и инженер
по знаниям, и программист. Поэтому, когда
хотят подчеркнуть, что речь идет о том,
для кого делалась ЭС, используют термин
"конечный пользователь".
В
режиме консультации данные о задаче
пользователя обрабатываются диалоговой
компонентой, которая выполняет следующие
действия: распределяет роли участников
(пользователя и ЭС) и организует их
взаимодействие в процессе кооперативного
решения задачи; преобразует данные
пользователя о задаче, представленные
на первичном для пользователя языке,
во внутренний язык системы; преобразует
сообщения системы, представленные на
внутреннем языке в сообщения на языке,
привычном для пользователя (обычно это
ограниченный естественный язык или
язык графики). В общем случае процесс
решения задачи с помощью ЭС в режиме
консультации может быть представлен в
виде схемы.
^ 7.
Классификация ЭС. Проблемная
область.
Экспертные
системы как любой сложный объект можно
определить только совокупностью
характеристик. Выделим следующие
характеристики ЭС:
А.
Назначение;
Б.
Проблемная область;
В.
Глубина анализа проблемной области;
Г.
Тип используемых методов и знаний;
Д.
Класс системы;
Е.
Стадия существования;
Ж.
Инструментальные средства.
Б. ^ Проблемная
область может
быть определена совокупностью параметров:
предметной областью и задачами, решаемыми
в предметной области, каждый из которых
может рассматриваться с точки зрения
как конечного пользователя, так и
разработчика ЭС.
С
точки зрения пользователя, предметную
область можно характеризовать описанием
области в терминах пользователя,
включающим наименование области,
перечень и взаимоотношение подобластей
и т.п., а задачи, решаемые существующими
ЭС, - их типом. Обычно выделяют следующие типы
задач:
ычно
к ЭС относят системы,
основанные на знании, т.е.
системы, вычислительная возможность
которых является в первую очередь
следствием их наращиваемой базы знаний
(БЗ) и только во вторую очередь определяется
используемыми методами. Методы
инженерии знаний (методы
ЭС) в значительной степени инвариантны
тому, в каких областях они могут
применяться. Области применения ЭС
весьма разнообразны: военные приложения,
медицина, электроника, вычислительная
техника, геология, математика, космос,
сельское хозяйство, управление, финансы,
юриспруденция, и т.д. База
знаний в
ЭС предназначена для хранения долгосрочных
данных, описывающих рас-ю область (а не
текущих данных), и правил, описывающие
целесообразные преобразования данных
этой области.
Решатель, используя
исходные данные из БД и знания из БЗ,
формирует такую последовательность
правил, которые, будучи примененными к
исходным данным, приводят к решению
задачи.
^ Компонента
приобретения знаний автоматизирует
процесс наполнения ЭС знаниями,
осуществляемый пользователем-экспертом.
Объяснительная
компонента объясняет,
как система получила решение задачи
(или почему она не получила решения) и
какие знания при этом она использовала,
что облегчает эксперту тестирование
системы и повышает доверие пользователя
к полученному результату.
^ Диалоговая
компонента ориентирована дружелюбного
общения со всеми категориями пользователей,
как в ходе решения задач, так и приобретения
знаний, объяснения результатов работы.
В
разработке ЭС участвуют представители
следующих специальностей: эксперт в
той проблемной области, задачи которой
будет решать ЭС; инженер по знаниям
(когнитолог) - специалист по разработке
ЭС; программист - специалист по
разработке инструментальных средств.
Необходимо отметить, что отсутствие
среди участников разработки инженера
по знаниям (т.е. его замена программистом)
либо приводит к неудаче в процессе
создания ЭС, либо значительно удлиняет
его.
Эксперт определяет
знания (данные и правила), характеризующие
проблемную область, обеспечивает полноту
и правильность введения в ЭС
знаний.
^ Инженер
по знаниям помогает
эксперту выявить и структурировать
знания, необходимые для работы ЭС. Он
выбирает тот инструментарий, который
наиболее подходит для данной проблемной
области, и определяет способ представления
знаний в нем, выделяет и программирует
(традиционными средствами) стандартные
функции (типичные для данной проблемной
области), которые будут использоваться
в правилах, вводимых экспертом. Экспертная
система работает в двух режимах:
приобретения знаний и решения задач
(называемом также режимом консультации
или режимом использования ЭС).
^ В
режиме консультации общение
с ЭС осуществляет конечный пользователь,
которого интересует результат и (или)
способ получения решения. Пользователь
в зависимости от назначения ЭС может
не быть специалистом в данной проблемной
области, в этом случае он обращается к
ЭС за советом, не умея получить ответ
сам, или быть специалистом, в этом случае
он обращается к ЭС, чтобы либо ускорить
процесс получения результата, либо
возложить на ЭС рутинную работу. Термин
"пользователь" является многозначным,
так как кроме конечного пользователя
применять ЭС может и эксперт, и инженер
по знаниям, и программист. Поэтому, когда
хотят подчеркнуть, что речь идет о том,
для кого делалась ЭС, используют термин
"конечный пользователь".
В
режиме консультации данные о задаче
пользователя обрабатываются диалоговой
компонентой, которая выполняет следующие
действия: распределяет роли участников
(пользователя и ЭС) и организует их
взаимодействие в процессе кооперативного
решения задачи; преобразует данные
пользователя о задаче, представленные
на первичном для пользователя языке,
во внутренний язык системы; преобразует
сообщения системы, представленные на
внутреннем языке в сообщения на языке,
привычном для пользователя (обычно это
ограниченный естественный язык или
язык графики). В общем случае процесс
решения задачи с помощью ЭС в режиме
консультации может быть представлен в
виде схемы.
^ 7.
Классификация ЭС. Проблемная
область.
Экспертные
системы как любой сложный объект можно
определить только совокупностью
характеристик. Выделим следующие
характеристики ЭС:
А.
Назначение;
Б.
Проблемная область;
В.
Глубина анализа проблемной области;
Г.
Тип используемых методов и знаний;
Д.
Класс системы;
Е.
Стадия существования;
Ж.
Инструментальные средства.
Б. ^ Проблемная
область может
быть определена совокупностью параметров:
предметной областью и задачами, решаемыми
в предметной области, каждый из которых
может рассматриваться с точки зрения
как конечного пользователя, так и
разработчика ЭС.
С
точки зрения пользователя, предметную
область можно характеризовать описанием
области в терминах пользователя,
включающим наименование области,
перечень и взаимоотношение подобластей
и т.п., а задачи, решаемые существующими
ЭС, - их типом. Обычно выделяют следующие типы
задач:
интерпретация символов или сигналов - составление смыслового описания по входным данным;
предсказание - определение последствий наблюдаемых ситуаций;
диагностика - определение состояния неисправностей, заболеваний по признакам (симптомам);
конструирование - разработка объекта с заданными свойствами при соблюдении установленных ограничений;
планирование - определение последовательности действий, приводящих к желаемому состоянию объекта;
слежение - наблюдение за изменяющимся состоянием объекта и сравнение его показателей с установленными или желаемыми;
управление - воздействие на объект для достижения желаемого поведения.
С
точки зрения разработчика целесообразно
выделять статические и динамические
предметные области. Предметная
область называется статической, если
описывающие ее исходные данные не
изменяются во времени (точнее
рассматриваются как не изменяющиеся
за время решения задачи). Решаемые
задачи, с точки зрения разработчика ЭС,
также можно разделить на статические
и динамические. Будем говорить, что ЭС
решает динамическую или статическуюзадач,
если процесс решения задачи изменяет
или не изменяет исходные данные о текущем
состоянии предметной области. Решаемые
задачи, кроме того, можно характеризовать
следующими аспектами: числом и сложностью
правил, используемых в задаче; связностью
правил; пространством поиска; количеством
активных агентов, изменяющих предметную
область; классом решаемых задач.
По
степени сложности выделяют
простые и сложные
правила,
К сложным
относят правила, текст знаний которых
на естественном языке занимает 1/3
страницы и больше. Правила, текст которых
занимает менее 1/3 страницы относят к
простым.
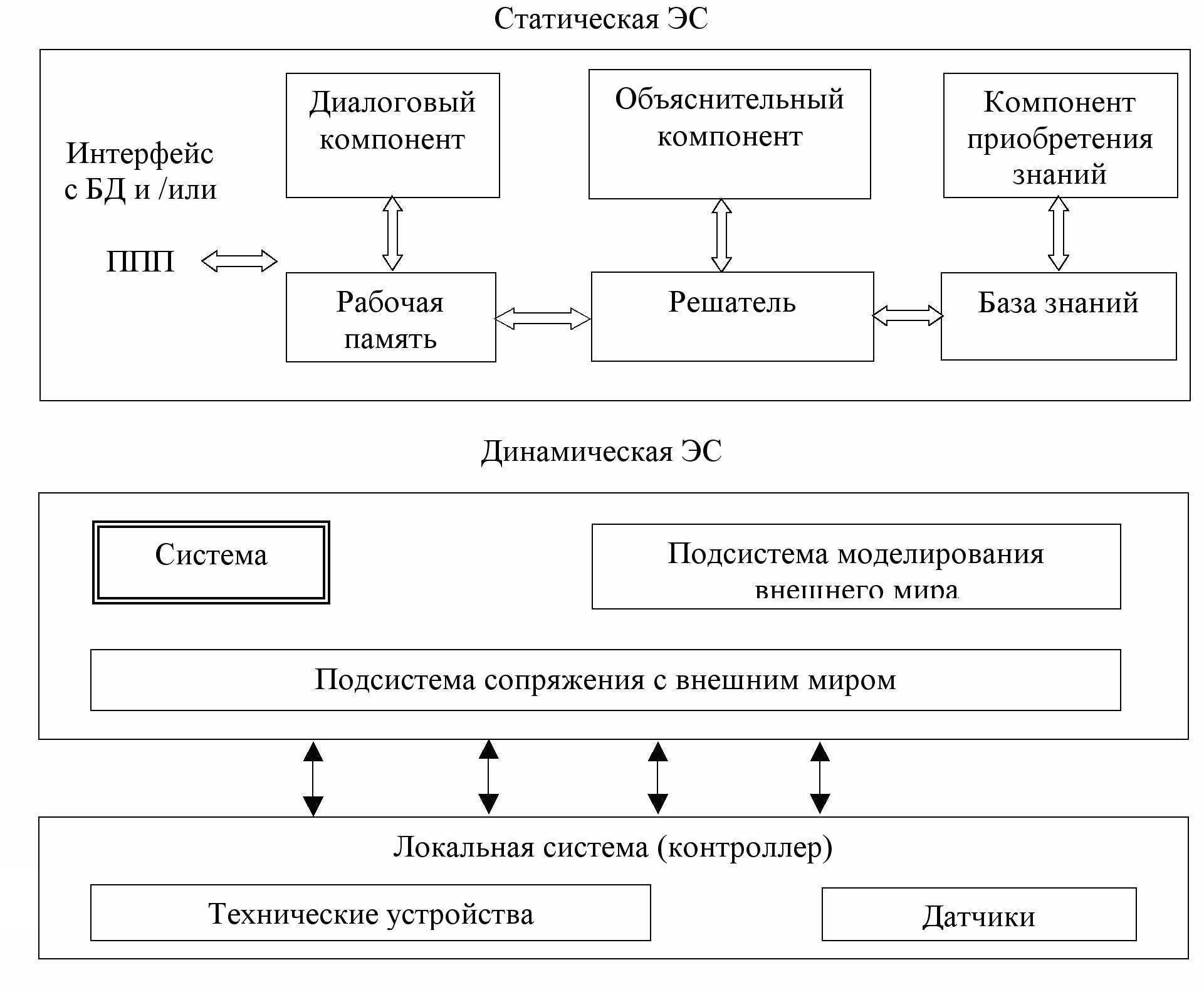
^ Классификация ЭС. По степени сложности структуры и типу используемых методов и знаний ЭС.
Экспертные системы как любой сложный объект можно определить только совокупностью характеристик. Выделим следующие характеристики ЭС: А. Назначение; Б. Проблемная область; В. Глубина анализа проблемной области; Г. Тип используемых методов и знаний; Д. Класс системы; Е. Стадия существования; Ж. Инструментальные средства. ^ 9. Выбор формализма для представления знаний. При проектировании ЭС перед разработчиками неизменно встает вопрос о выборе подходящего формализма для представления знаний. Решение этого вопроса является не только важнейшей стратегической задачей при разработке ЭС, но и достаточно сложной экспертной задачей. Рассмотрим некоторые предложения (или критерии) по выбору адекватного формализма для представления знаний. Поскольку процесс выбора является творческой задачей и на сегодня не существует исчерпывающих рекомендаций по ее решению, то зафиксируем некоторые экспертные знания по этому вопросу Ниже представлены 8 критериев (рекомендаций) по выбору модели представления знаний на основе учета базовых характеристик предметной области – понятийной структуры предметной области. Для удобства все критерии сформулированы как правила вида: “Если (условие), то (действие)”.
ЕСЛИ понятия простые И отношения между ними выражаются в языке исчисления предикатов И способ рассуждений дедуктивный, ТО целесообразно использовать логические модели.
ЕСЛИ понятия являются в основном простыми И есть небольшое число отношений на понятиях И способ рассуждений индуктивный, ТО целесообразно использовать индуктивные модели.
ЕСЛИ понятия устроены сложным образом И есть большое число отношений на понятиях И способ рассуждений – выдвижение гипотез, ТО целесообразно использовать сетевые модели.
ЕСЛИ понятия устроены сложным образом И есть небольшое число отношений на понятиях И способ рассуждений дедуктивный, ТО целесообразно использовать наследственно-конечные модели (типа тезаурусов).
ЕСЛИ понятия устроены сложным образом И большое число отношений на понятиях И способ рассуждений по аналогии или дедуктивный, ТО целесообразно использовать фреймовые модели.
ЕСЛИ понятия устроены простым образом И большое число отношений на понятиях И способ рассуждений дедуктивный, ТО целесообразно использовать продукционные модели.
ЕСЛИ понятия устроены сложным образом И структура многих понятий не ясна И способ рассуждений – выдвижение гипотез, ТО целесообразно использовать сетевые модели.
ЕСЛИ понятия устроены сложным образом И есть большое число отношений на понятиях И способ рассуждений индуктивный, ТО подходящий формализм отсутствует.
С точки зрения классификации знаний по “глубине” и “жесткости” можно также предложить некоторые критерии выбора модели представления знаний, сформулированные в виде следующих правил.
ЕСЛИ представляемые знания являются поверхностными И жесткими, ТО целесообразно использовать логические модели.
ЕСЛИ представляемые знания являются поверхностными И мягкими ИЛИ жесткими, ТО целесообразно использовать продукционные модели.
ЕСЛИ представляемые знания являются глубинными И мягкими ИЛИ жесткими, ТО целесообразно использовать модели в виде семантических сетей или фреймов (объектно-ориентированные модели).
^ 10. Технология разработки ЭС. Разработка (проектирование) ЭС существенно отличается от разработки обычного программного продукта. Опыт разработки ранних ЭС показал, что использование при разработке методологии, принятой в традиционном программировании, либо чрезмерно затягивает процесс создания ЭС, либо вообще приводит к отрицательному результату. Дело в том, что неформализованность задач, решаемых ЭС, отсутствие завершенной теории ЭС и методологии их разработки приводит к необходимости модифицировать их принципы и способы построения ЭС в ходе процесса разработки по мере того, как увеличивается знание разработчиков о проблемной области. Перед тем, как приступить к разработке ЭС, инженер по знаниям должен рассматривать вопрос, следует ли разрабатывать ЭС для данного приложения. В обобщенном виде ответ может быть таким: использовать ЭС следует тогда, когда разработка ЭС: 1) возможна, 2) оправдана и 3) методы инженерии знанийсоответствуют решаемой задаче. 1 Чтобы разработка ЭС была возможна (для данного приложения), необходимо одновременно выполнение по крайней мере следующих требований:
существуют эксперты в данной области, которые решают задачу значительно лучше, чем начинающие специалисты;
эксперты должны сходиться в оценке предлагаемого решения, иначе нельзя будет оценить качество разработанной ЭС;
эксперты должны уметь выразить на естественном языке (вербализовать) и объяснить используемые ими методы, в противном случае трудно рассчитывать на то, что знания экспертов будут "извлечены" и вложены в ЭС;
задача, возложенная на ЭС, требует только рассуждений, а не действий (если требуется действие, то необходимо объединять ЭС с роботами);
задача не должна быть слишком трудной, ее решение должно занимать у эксперта несколько часов, а не дней или недель;
задача, хотя и не должна быть выражена в формальном виде, но все же должна относиться к достаточно "понятной" и структурированной области, т.е. должны быть выделены основные понятия, отношения и известные (хотя бы эксперту) способы получения решения задач;
решение задачи не должно в значительной степени использовать "здравый смысл'" (т.е. широкий спектр общих сведений о мире и о способе его функционирования, которые знает и умеет использовать любой нормальный человек), т.к. подобные знания пока не удается (в достаточном количестве) вложить в системы искусственного интеллекта.
Использование ЭС в данном приложении может быть возможно, но не оправдано. 2 Применение ЭС может быть оправдано одним из следующих факторов:
решение задачи принесет значительных эффект, например, использование ЭС для поиска полезных ископаемых;
использование человека-эксперта невозможно либо из-за недостаточного количества экспертов, либо из-за необходимости выполнять экспертизу одновременно в различных местах;
при передаче информации эксперту происходит недопустимая потеря времени или информации;
при необходимости решать задачу в окружении враждебном для человека.
3 Приложение соответствует методам ЭС, если решаемая задача обладает совокупностью следующих характеристик:
может быть естественным образом решена посредством манипуляции символами (т.е. с помощью символьных рассуждений), а не с числами (как принято в математических методах и традиционных программах);
должна иметь эвристическую (не алгоритмическую) природу, т.е. ее решение должно сводиться к применению эвристических правил; задачи, которые могут быть гарантировано решены (с соблюдением заданных ограничений) с помощью некоторых формальных процедур, не подходит для применения ЭС;
должна быть достаточно сложной чтобы оправдать затраты на разработку ЭС, однако, не должна быть чрезмерно сложной (решение занимает у эксперта часы, а не недели), чтобы ЭС могла ее решить;
должна быть достаточно узкой, чтобы решаться методами инженерии знаний, и практически значимой.
В
выходе работ по созданию ЭС сложилась
определенная технология их разработки,
включающая шесть следующих этапов:
идентификация, концептуализация,
формализация, выполнение, тестирование,
опытная эксплуатация
 ^ 11.
Технология разработки ЭС. Этап
идентификации.
На
данном этапе идентифицируются
(определяются) задачи, которые подлежат
решению, выявляются цели разработки,
определяются участники процесса
проектирования и их роли (эксперты и
категории пользователей),
ресурсы.
Идентификация
задачи заключается в составлении
неформального (вербального) описания
решаемой задачи. В этом описании
указываются: общие характеристики
задачи; подзадачи, выделяемые внутри
данной задачи; ключевые понятия (объекты),
характеристики и отношения; входные
(выходные) данные; предположительный
вид решения; знания, релевантные решаемой
задачи; примеры (тесты) решения задачи.
Цель идентификации задачи - характеризовать
задачу и структуру поддерживающих ее
знаний и таким образом обеспечить
начальный импульс для развития БЗ. В
ходе идентификации задачи (задач)
необходимо ответить на следующие
вопросы:
^ 11.
Технология разработки ЭС. Этап
идентификации.
На
данном этапе идентифицируются
(определяются) задачи, которые подлежат
решению, выявляются цели разработки,
определяются участники процесса
проектирования и их роли (эксперты и
категории пользователей),
ресурсы.
Идентификация
задачи заключается в составлении
неформального (вербального) описания
решаемой задачи. В этом описании
указываются: общие характеристики
задачи; подзадачи, выделяемые внутри
данной задачи; ключевые понятия (объекты),
характеристики и отношения; входные
(выходные) данные; предположительный
вид решения; знания, релевантные решаемой
задачи; примеры (тесты) решения задачи.
Цель идентификации задачи - характеризовать
задачу и структуру поддерживающих ее
знаний и таким образом обеспечить
начальный импульс для развития БЗ. В
ходе идентификации задачи (задач)
необходимо ответить на следующие
вопросы:
какие задачи предлагается решать ЭС и как они могут быть охарактеризованы и определены;
на какие задачи разбивается каждая задача и какие данные они используют;
каковы основные понятия и взаимоотношения, используемые при формулировании и решении задачи;
какие знания релевантны решаемой задачи;
какие ситуации препятствуют решаемой задачи;
как эти препятствия будут влиять на ЭС.
Идентификация целей заключается в формулировании, в явном виде, целей построения ЭС. При этом важно отличать цели, ради которых создается ЭС, от задач, которые она должна решать Примерами возможных целей являются:
формализация неформальных знаний экспертов;
улучшение качества решений, принимаемых экспертом;
автоматизация рутинных аспектов работы эксперта (пользователя);
тиражирование знаний эксперта.
Определение участников и их ролей сводится к определению количества экспертов и инженеров по знаниям, а также форм их взаимоотношения. Обычно, в основном цикле разработки ЭС участвует не менее трех, четырех человек - один эксперт, один или два инженера по знаниям и один программист, привлекаемый для модификации и согласования инструментальных средств. К процессу разработки могут привлекаться и другие участники, группа экспертов с руководителем и др. Что касается формы взаимоотношения экспертов и инженеров, то применяются следующие формы: эксперт выполняет роль информирующего или учителя, а инженер роль ученика. Форма учитель-ученик больше соответствует реальности. В процессе идентификации задачи инженер и эксперт работают в тесном контакте. При проектировании ЭС типичными ресурсами являются: источники знаний, время разработки, вычислительные средства и объем финансирования. Для достижения успеха эксперт и инженер должны использовать все доступные им источники знаний.
18. Типы знаний в ЭС. Выделим восемь основных типов знаний по следующим признакам: 1) Базовые элементы, объекты реального мира. Они связаны с непосредственным восприятием, не требуют обсуждения и добавляются к нашей базе фактов в том виде, в котором они получены. 2) ^ Утверждения и определения. Они основаны на базовых элементах и заранее рассматриваются как достоверные. 3) Концепции. Они определяют собой перегруппировки или обобщения базовых объектов. Для построения каждой концепции используются свои приемы. 4) Отношения. Они выражают как элементарные свойства базовых элементов, так и отношения между концепциями. Кроме того, к свойствам отношений относятся их большее или меньшее правдоподобие, большая или меньшая связь с данной ситуацией. Еще раз отметим, что представление знаний в ЭС близко к моделям, используемым в БД. Таким путем построена реляционная (обобщенная) модель БД в некоторых ЭС. Пара понятий "свойство-значение" хорошо известна в семантических сетях; фреймы и скрипты являются не чем иным, как наиболее простыми бинарными отношениями. Некоторые ЭС в качестве базы фактов используют уже базы существующих данных. 5) ^ Теоремы и правила перезаписи. Они являются частными случаем продукционных правил с вполне определенными свойствами. Теоремы не представляют никакой пользы без экспертных правил их использования. Явное присутствие теорем ЭС представляет главное отличие от систем управления классическими базами данных (СУБД), в которых они либо отсутствуют, либо программируются. Модификация или добавление новых теорем является весьма трудоемкой, хотя и необходимой процедурой, так как нужно обеспечить хорошее структурированное управление БД и оптимизировать получение ответов. 6) ^ Алгоритмы решений. Они необходимы для выполнения определенных задач. Во всех случаях они связаны со знанием особого типа, поскольку определяемая ими последовательность действий оказывается оформленной в блок, в строго необходимом порядке в отличие от других типов знания, где элементы информации могут появляться и располагаться без связи друг с другом. Очевидно, что очень трудно работать с длинными процедурами, состоящими из большого числа различных действий. Использование чистых алгоритмов ограничено очень частными случаями, большая часть которых имеет дело с обработкой числовой информации. ЭВМ должна рассматривать и неалгоритмические ситуации. 7) ^ Стратегии и эвристика. Этот тип представляет врожденные или приобретенные правила поведения, которые позволяют в данной конкретной ситуации принять решение о необходимых действиях. Он использует информацию в порядке, обратном тому, в котором она была получена. Например, рассуждения типа: "Я знал, что это действие приводит к такому-то результату (информация типа в п.4), поэтому, если я хочу получить именно этот результат, я могу рассмотреть это действие''. Человек постоянно пользуется этим типом знаний при восприятии, формировании концепций, решении задач и формальных рассуждениях. Появление ЭС связано с необходимостью принятия в расчет именно этого фундаментального типа человеческих знаний. 8) Метазнание. Без сомнения оно присутствует на многих уровнях и представляет собой знание того, что известно и определяет значение коэффициента к этому знанию, важность элементарной информации по отношению ко всему множеству знаний. Кроме того, сюда же относятся вопросы организации каждого типа знаний и указаний, когда и как они могут быть использованы. Метазнание представляет собой любое знание о знании. Оно является фундаментальным понятием для систем, которые не только используют свою БЗ такой, как она есть, но и умеют на ее основе делать выводы, структурировать ее, абстрагировать, обобщать, а также решать, в каких случаях она может быть полезна. ^ 19. Методы представления знаний. Приведем краткий список наиболее распространенных методов представления знаний. Фундаментальное различие между ними состоит в простоте модификации знания. В таблице 2.2 они приведены в порядке от наиболее процедурного (наиболее застывшего, структурированного) до наиболеедекларативного (наиболее открытого, свободного, неупорядоченного). Такая классификация является несколько грубой, но правильно отражает идею. Методы представления знаний
Процедурные “закрытые” Декларативные “открытые”, “неупорядоченные” |
МЕТОДЫ |
|
^ 20. Отличия знаний от данных. Характерным признаком интеллектуальных систем является наличие знаний, необходимых для решения задач конкретной предметной области. При этом возникает естественный вопрос, что такое знания и чем они отличаются от обычных данных, обрабатываемых ЭВМ. Данными называют информацию фактического характера, описывающую объекты, процессы и явления предметной области, а также их свойства. В процессах компьютерной обработки данные проходят следующие этапы преобразований: •исходная форма существования данных (результаты наблюдений и измерений, таблицы, справочники, диаграммы, графики и т.д.); •представление на специальных языках описания данных, предназначенных для ввода и обработки исходных данных в ЭВМ; •базы данных на машинных носителях информации. Знания являются более сложной категорией информации по сравнению с данными. Знания описывают не только отдельные факты, но и взаимосвязи между ними, поэтому знания иногда называют структурированными данными. Знания могут быть получены на основе обработки эмпирических данных. Они представляют собой результат мыслительной деятельности человека, направленной на обобщение его опыта, полученного в результате практической деятельности. Для того чтобы наделить ИИС знаниями, их необходимо представить в определенной форме. Существуют два основных способа наделения знаниями программных систем. Первый - поместить знания в программу, написанную на обычном языке программирования. Такая система будет представлять собой единый программный код, в котором знания не вынесены в отдельную категорию. Несмотря на то, что основная задача будет решена, в этом случае трудно оценить роль знаний и понять, каким образом они используются в процессе решения задач. Нелегким делом являются модификация и сопровождение подобных программ, а проблема пополнения знаний может стать неразрешимой. Второй способ базируется на концепции баз данных и заключается в вынесении знаний в отдельную категорию, т.е. знания представляются в определенном формате и помещаются в БЗ. База знаний легко пополняется и модифицируется. Она является автономной частью интеллектуальной системы, хотя механизм логического вывода, реализованный в логическом блоке, а также средства ведения диалога накладывают определенные ограничения на структуру БЗ и операции с нею. В современных ИИС принят этот способ. Исследователями в области ИИ даются более конкретные определения знаний. «Знания - это закономерности предметной области (принципы, связи, законы), полученные в результате практической деятельности и профессионального опыта, позволяющие специалистам ставить и решать задачи в этой области». «Знания — это хорошо структурированные данные или данные о данных, или метаданные». «Знания - формализованная информация, на которую ссылаются или используют в процессе логического вывода». Существует множество классификаций знаний. Как правило, с помощью классификаций систематизируют знания конкретных предметных областей. На абстрактном уровне рассмотрения Можно говорить о признаках, по которым подразделяются знания, а не о классификациях. По своей природе знания можно разделить на декларативные и процедурные. Декларативные знания представляют собой описания фактов и явлений, фиксируют наличие или отсутствие таких фактов, а также включают описания основных связей и закономерностей, в которые эти факты и явления входят. Процедурные знания — это описания действий, которые возможны при манипулировании фактами и явлениями для достижения намеченных целей. Для описания знаний на абстрактном уровне разработаны специальные языки - языки описания знаний. Эти языки также делятся на языки процедурного типа и декларативного. Все языки описания знаний, ориентированные на использование традиционных компьютеров фон-неймановской архитектуры, являются языками процедурного типа. Разработка языков декларативного типа, удобных для представления знаний, является актуальной проблемой сегодняшнего дня. ^ 21. Логическая модель представления знаний. К типичным моделям представления знаний относятся логическая, продукционная, фреймовая и модель семантической сети Логическая модель основана на системе исчисления предикатов первого порядка. Знакомство с логикой предикатов начнем с исчисления высказываний. Высказыванием называется предложение, смысл которого можно выразить значениями: истина (Т) или ложь (Р). Например, предложения «лебедь белый» и «лебедь черный» будут высказываниями. Из простых высказываний можно составить более сложные: «лебедь белый или лебедь черный», «лебедь белый и лебедь черный», «если лебедь не белый, то лебедь черный». В свою очередь, сложные высказывания можно разделить на частичные, которые связаны между собой с помощью слов: и, или, не, если - то. Элементарными называются высказывания, которые нельзя разделить на части. Логика высказываний оперирует логическими связями между высказываниями, т. е. она решает вопросы типа: «Можно ли на основе высказывания А получить высказывание В?»; «Истинно ли В при истинности А?» и т.п. При этом семантика высказываний не имеет значения. Элементарные высказывания рассматриваются как переменные логического типа, над которыми разрешены следующие логические операции: ¬ отрицание {унарная операция); конъюнкция (логическое умножение); v дизъюнкция (логическое сложение); → импликация (если — то); ↔ эквивалентность. Операция импликации должна удовлетворять следующим требованиям. 1 Значение результата импликации зависит от двух операндов. 2 Если первый операнд (А) - истинный, то значение результата совпадает со значением второго операнда (В). 3 Операция импликации не коммутативна. 4 Результат импликации совпадает с результатом выражения ¬А vВ. ^ 22. Представление знаний правилами продукций. Продукционная модель в силу своей простоты получила наиболее широкое распространение. В этой модели знания представляются в виде совокупности правил типа «ЕСЛИ - ТО». Системы обработки знаний, использующие такое представление, получили название продукционных систем. В состав экспертной системы продукционного типа входят база правил, база фактических данных (рабочая память) и интерпретатор правил, реализующий определенный механизм логического вывода. Любое продукционное правило, содержащееся в БЗ, состоит из двух частей: антецедента и консеквента. Антецедент представляет собой посылку правила (условную часть) и состоит из элементарных предложений, соединенных логическими связками И, ИЛИ. Консеквент (заключение) включает одно или несколько предложений, которые выражают либо некоторый факт, либо указание на определенное действие, подлежащее исполнению. Продукционные правила принято записывать в виде АНТЕЦЕДЕНТ → КОНСЕКВЕНТ. Примеры продукционных правил: ЕСЛИ «двигатель не заводится» И «стартер двигателя не работает», ТО «неполадки в системе электропитания стартера»; ЕСЛИ «животное имеет перья», ТО «животное — птица». Антецеденты и консеквенты правил формируются из атрибутов и значений, например: ^ Атрибут Значени�� Двигатель Не аводится Стартер двигателя Не работает Животное Имеет ерья Животное Птица Любое правило состоит из одной (или нескольких) пары атрибут — значение. В рабочей памяти продукционной системы хранятся пары атрибут — значение, истинность которых установлена в процессе решения конкретной задачи к некоторому текущему моменту времени. Содержимое рабочей памяти изменяется в процессе решения задачи. Это происходит по мере срабатывания правил. Правило срабатывает, если при сопоставлении фактов, содержащихся в рабочей памяти, с антецедентом анализируемого правила имеет место совпадение, при этом заключение сработавшего правила заносится в рабочую память. Поэтому в процессе логического вывода объем фактов в рабочей памяти, как правило, увеличивается (уменьшаться он может в том случае, если действие какого-нибудь правила состоит в удалении фактов из рабочей памяти). В процессе логического вывода каждое правило из базы правил может сработать только один раз. При описании реальных знаний конкретной предметной области может оказаться недостаточным представление фактов с помощью пар атрибут—значение.Более широкие возможности имеет способ описания с помощью триплетов объект—атрибут—значение. В этом случае отдельная сущность предметной области рассматривается как объект, а данные, хранящиеся в рабочей памяти, показывают значения, которые принимают атрибуты этого объекта. Примеры триплетов: собака — кличка - Граф; собака — порода - ризеншнауцер; собака — окрас — черный. Одним из преимуществ такого представления знаний является уточнение контекста, в котором применяются правила. Например, правило, относящееся к объекту «собака», должно быть применимо для собак с любыми кличками, всех пород и окрасок. С введением триплетов правила из базы правил могут срабатывать более одного раза в процессе одного логического вывода, поскольку одно правило может применяться к различным экземплярам объекта (но не более одного раза к каждому экземпляру). Существуют два типа продукционных систем — с прямыми и обратными выводами. ^ Прямые выводы реализуют стратегию «от фактов к заключениям». При обратных выводах выдвигаются гипотезы вероятных заключений, которые могут быть подтверждены или опровергнуты на основании фактов, поступающих в рабочую память. Существуют также системы с двунаправленными выводами. Основные достоинства продукционных систем связаны с простотой представления знаний и организации логического вывода. К недостаткам систем продукций можно отнести следующие: • отличие от структур знаний, свойственных человеку; • неясность взаимных отношений правил; • сложность оценки целостного образа знаний; • низкая эффективность обработки знаний. При разработке небольших систем (десятки правил) проявляются в основном положительные стороны систем продукций, однако при увеличении объема знаний более заметными становятся слабые стороны. ^ 23. Объектно – ориентированное представление знаний фреймами. Фреймовая модель представления знаний основана на теории фреймов М. Минского, которая представляет собой систематизированную психологическую модель памяти человека и его сознания. Эта теория имеет весьма абстрактный характер, поэтому только на ее основе невозможно создание конкретных языков представления знаний. Фреймом называется структура данных для представления некоторого концептуального объекта. Фрейм имеет имя, служащее для идентификации описываемого им понятия, и содержит ряд описаний — слотов, с помощью которых определяются основные структурные элементы этого понятия. За слотами следуют шпации, в которые помещают данные, представляющие текущие значения слотов. Слот может содержать не только конкретное значение, но также имя процедуры, позволяющей вычислить это значение по заданному алгоритму. Например, слот с именем возраст может содержать имя процедуры, которая вычисляет возраст человека по дате рождения, записанной в другом слоте, и текущей дате Совокупность данных предметной области может быть представлена множеством взаимосвязанных фреймов, образующих единую фреймовую систему, в которой объединяются декларативные и процедурные знания. Такая система имеет, как правило, иерархическую структуру, в которой фреймы соединены друг с другом с помощью родо-видовых связей. На верхнем уровне иерархии находится фрейм, содержащий наиболее общую информацию, истинную для всех остальных фреймов. Фреймы обладают способностью наследовать значения характеристик своих родителей. Например, фреймАФРИКАНСКИЙ_СЛОН наследует от фрейма СЛОН значение характеристики цвет=«серый». Значение характеристики в дочернем фрейме может отличаться от родительского, например, значением данного слота для фрейма АЗИАТСКИЙ_СЛОН является цвет=«коричневый». В общем случае структура данных фрейма может содержать более широкий набор информации, в который входят следующие атрибуты. ^ Имя фрейма. Оно служит для идентификации фрейма в системе и должно быть уникальным. Фрейм представляет собой совокупность слотов, число которых может быть произвольным. Число слотов в каждом фрейме устанавливается проектировщиком системы, при этом часть слотов определяется самой системой для выполнения специфических функций (системные слоты), примерами которых являются: слот-указатель родителя данного фрейма (18-А), слот-указатель дочерних фреймов, слот для ввода имени пользователя, слот для ввода даты определения фрейма, слот для ввода даты изменения фрейма и т.д. ^ Имя слота. Оно должно быть уникальным в пределах фрейма. Обычно имя слота представляет собой идентификатор, который наделен определенной семантикой. В качестве имени слота может выступать произвольный текст. Например, <Имя слота> = Главный герой романа Ф. М. Достоевского «Идиот», <Значение слота>= Князь Мышкин. Имена системных слотов обычно зарезервированы, в различных системах они могут иметь различные значения. Примеры имен системных слотов: IS-А, НАSРАRТ,и т.д. Системные слоты служат для редактирования базы знаний и управления выводом во фреймовой системе. ^ Указатели наследования. Они показывают, какую информацию об атрибутах слотов из фрейма верхнего уровня наследуют слоты с аналогичными именами в данном фрейме. Указатели наследования характерны для фреймовых систем иерархического типа, основанных на отношениях типа «абстрактное — конкретное». В конкретных системах указатели наследования могут быть организованы различными способами и иметь разные обозначения: U(Unique) - значение слота не наследуется; S(Same) — значение слота наследуется; R(Range) - значения слота должны находиться в пределах интервала значений, указанных в одноименном слоте родительского фрейма; О(Override) — при отсутствии значения в текущем слоте оно наследуется из фрейма верхнего уровня, однако в случае определения значения текущего слота оно может быть уникальным. Этот тип указателя выполняет одновременно функции указателей U и S. ^ Указатель типа данных. Он показывает тип значения слота. Наиболее употребляемые типьг frате — указатель на фрейм; геа1 — вещественное число;integer — целое число; Ьоо1еап — логический тип; text - фрагмент текста; list - список; tаblе — таблица; ехрressoп — выражение; lisp — связанная процедура и т.д. Значение слота. Оно должно соответствовать указанному типу данных и условию наследования. Демоны. Демоном называется процедура, автоматически запускаемая при выполнении некоторого условия. Демоны автоматически запускаются при обращении к соответствующему слоту. Типы демонов связаны с условием запуска процедуры. Демон с условием IF-NEEDED запускается, если в момент обращения к слоту его значение не было установлено. Демон типа if-ADDED запускается при попытке изменения значения слота. Демон IF-REMOVEDзапускается при попытке удаления значения слота. Возможны также другие типы демонов. Демон является разновидностью связанной процедуры. ^ Присоединенная процедура. В качестве значения слота может использоваться процедура, называемая служебной в языке Лисп или методом в языках объектно-ориентированного программирования. Присоединенная процедура запускается по сообщению, переданному из другого фрейма. Демоны и присоединенные процедуры являются процедурными знаниями, объединенными вместе с декларативными в единую систему. Эти процедурные знания являются средствами управления выводом во фреймовых системах, причем с их помощью можно реализовать любой механизм вывода. Представление таких знаний и заполнение ими интеллектуальных систем - весьма нелегкое дело, которое требует дополнительных затрат труда и времени разработчиков ИИС. Поэтому проектирование фреймовых систем выполняется, как правило, специалистами, имеющими высокий уровень квалификации в области искусственного интеллекта.
Перцептро́н, или персептрон[nb 1] (англ. perceptron от лат. perceptio — восприятие; нем. perzeptron) —математическая и компьютерная модель восприятия информации мозгом (кибернетическая модель мозга), предложенная Фрэнком Розенблаттом в 1957 году и реализованная в виде электронной машины «Марк-1»[nb 2] в 1960 году. Перцептрон стал одной из первых моделей нейросетей, а «Марк-1» — первым в мире нейрокомпьютером. Несмотря на свою простоту, перцептрон способен обучаться и решать довольно сложные задачи. Основная математическая задача, с которой он справляется, — это линейное разделение любых нелинейных множеств, так называемое обеспечение линейной сепарабельности.
Перцептрон состоит из трёх типов элементов, а именно: поступающие от сенсоров сигналы передаютсяассоциативным элементам, а затем реагирующим элементам. Таким образом, перцептроны позволяют создать набор «ассоциаций» между входными стимулами и необходимой реакцией на выходе. В биологическом плане это соответствует преобразованию, например, зрительной информации в физиологический ответ от двигательныхнейронов. Согласно современной терминологии, перцептроны могут быть классифицированы как искусственные нейронные сети:
с одним скрытым слоем;[nb 3]
с пороговой передаточной функцией;
с прямым распространением сигнала.
На фоне роста популярности нейронных сетей, в 1969 году вышла книга Марвина Минского и Сеймура Паперта, которая показала принципиальные ограничения перцептронов. Это привело к смещению интереса исследователей искусственного интеллекта в противоположную от нейросетей область символьных вычислений.[nb 4] Кроме того, из-за сложности математического анализа перцептронов, а также отсутствия общепринятой терминологии, возникли различные неточности и заблуждения.
Впоследствии интерес к нейросетям, и в частности, работам Розенблатта, возобновился. Так, например, сейчас стремительно развивается биокомпьютинг, который в своей теоретической основе вычислений, в том числе, базируется на нейронных сетях, а перцептрон воспроизводят на основе бактериородопсин-содержащих пленок.
самоорганизующиеся карты или сеть Кохонена. Такой класс многослойных нейронных сетей, как правило, обучается без учителя и успешно применяется в задачах распознавания. Сети такого класса способны выявлять новизну во входных данных: если после обучения сеть встретится с набором данных, непохожим ни на один из известных образцов, то она не сможет классифицировать такой набор и тем самым выявит его новизну. Сеть Кохонена имеет всего два слоя: входной и выходной, составленный из радиальных элементов.
Метод коррекции ошибки — метод обучения перцептрона, предложенный Фрэнком Розенблаттом. Представляет собой такой метод обучения, при котором вес связи не изменяется до тех пор, пока текущая реакция перцептрона остается правильной. При появлении неправильной реакции вес изменяется на единицу, а знак (+/-) определяется противоположным от знака ошибки.